本文根据9月25日云栖大会--《通义基于MaxCompute进行大模型数据管理及处理》演讲整理而成,演讲信息如下:
演讲人:曾剑元 通义实验室系统研发总监
主要内容:
AI数据的特点,跟传统大数据的区别
通义实验室为什么基MaxCompute来构建我们的数据平台
通义实验室的大模型的数据平台架构
AI数据区别于传统数据的三个特点
第一个特点是数据组织的无标准。像传统大数据基本上是一个大宽表,在大宽表之上,通过SQL来进行ETL就能解决绝大多数问题。但AI数据组织是没有标准的。 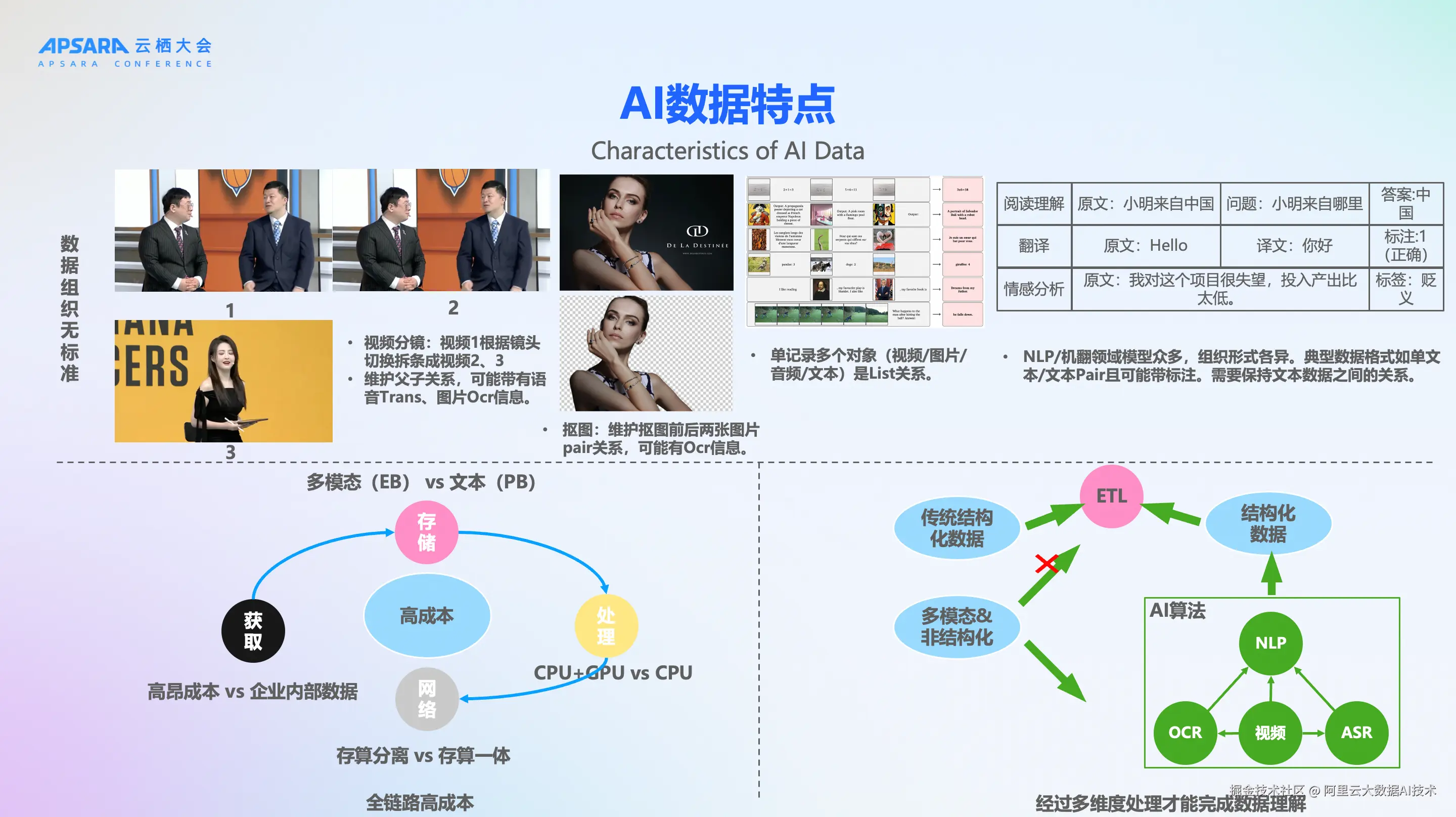
举四个例子。第一个是视频,视频在处理之前,一般都要进行拆条,拆解成子视频,比如说定长拆条,或者通过关键帧,或者通过场景来拆条。拆完以后,这一条记录要保存父视频和子视频的关系,同时这个视频里面可能还有音轨、标题、字幕等等一些信息。
第二个例子就是用于抠图场景的图片数据,需要维护这个图片的映射关系。
第三个例子是一个多轮对话的例子。这个多轮对话里面,可能单条记录要包含多个模态信息,文本、视频、音频等等,他们之间是一个list关系。
第四个例子就是文本,数据组织形式更加复杂,不同的场景还是不一样的。需要在单条记录里就能涵盖这些所有的AI数据的组织,这些例子可以看出来AI数据组织是没有标准的。
第二个特点是AI数据相对于传统的数据来说成本比较高,从数据的获取角度,需要去做大量的人工标注,还有获取有版权的数据,相对于企业内部的结构化数据成本非常高。还有数据存储也需要消耗较大的成本,多模态数据跟传统数据的存储成本差异是显而易见的。第三个是数据处理,除了CPU以外还需要GPU的处理。最后是网络,多模态数据一般分散存储在各个地域的对象存储引擎里,计算引擎也是分散在各处,在处理、训练的时候,就需要去跨地域的进行拖拉数据。所以全链路成本就比较高。
第三个特点就是理解成本也比较高。传统数据简单进行ETL就能够完全理解。但是在AI数据这方面,理解就比较复杂。以视频为例,至少包含视觉、音频、文本三方面的信息。
文本需要一些文本的模型去进行理解;视觉信息我们需要去抽帧,抽完帧以后通过一些OCR的手段来去识别文本,然后再进行理解;音频需要提取音轨然后通过ASR的手段提取文本,最后再进行一些处理。
所以相较于传统大数据,AI数据还是有很多不同。
基于MaxCompute来构建数据处理平台
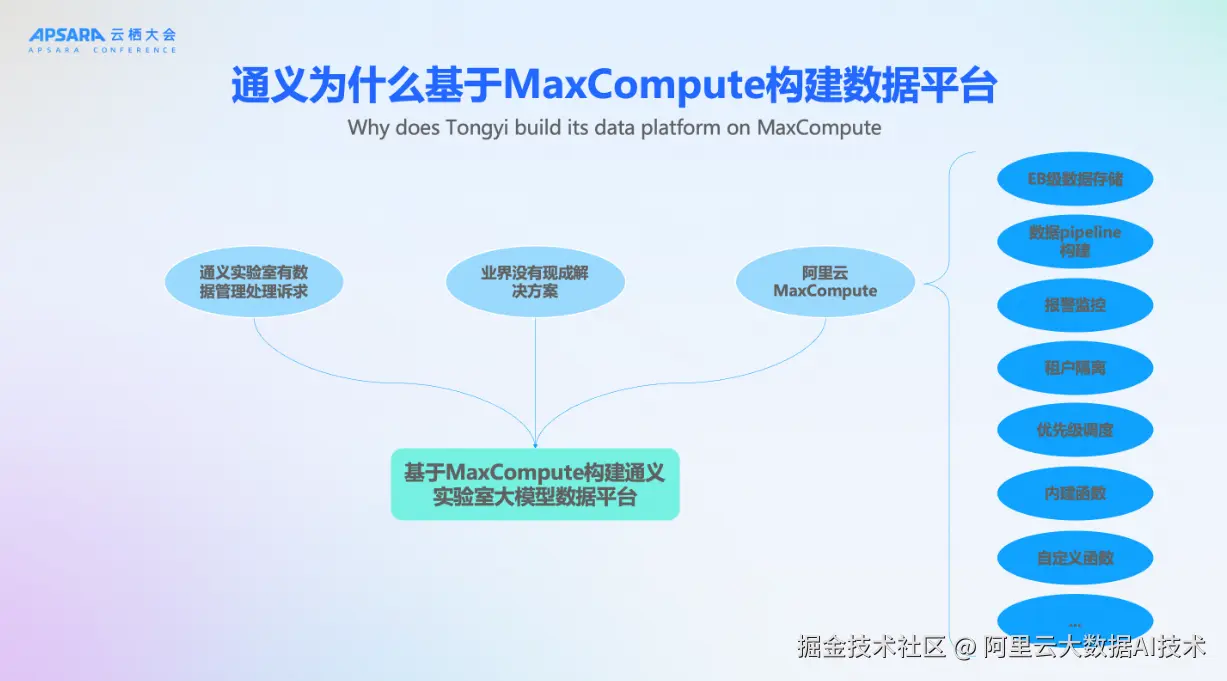 为什么通义实验室要基于MaxCompute来构建数据平台?首先,通义实验室有数据统一管理及处理的诉求。通义实验室有通义千问、通义万相以及多个领域模型。数据需要进行统一管理,只有统一管理才能更高效的流转。
为什么通义实验室要基于MaxCompute来构建数据平台?首先,通义实验室有数据统一管理及处理的诉求。通义实验室有通义千问、通义万相以及多个领域模型。数据需要进行统一管理,只有统一管理才能更高效的流转。
通义实验室是在2020年去开始构建这个数据平台。当时通义实验室的各个算法团队还在孵化阶段,业界当时没有成熟的解决方案。但是通义对AI数据的管理、处理的诉求是非常明确的,阿里云MaxCompute能够满足通义实验室的需求,比如支持EB级的数据存储,可以基于DataWorks构建数据处理pipeline,海量丰富的内建UDF,也支持用各种语言python、java等开发我们自己的自定义函数。
在这样的背景下,我们选择基于MaxCompute来构建了通义实验室的大模型数据平台。  这个是通义实验室大模型数据平台的基本架构。首先我们的外部数据包含了采购的数据,人工标注的数据,还有一些公开可下载的数据。
这个是通义实验室大模型数据平台的基本架构。首先我们的外部数据包含了采购的数据,人工标注的数据,还有一些公开可下载的数据。
拿到这些数据以后,第一步操作就是基于MaxCompute平台进行标准化。执行标准化了以后,那么所有的通义实验室的算法同学来看到这个数据,不需要过多的理解就能知道数据的含义。通过这样的方式加速提升了数据的流动效率。
在标准化之后,我们构建了一个数据集市,这个数据集市上面有一些比较原始的数据,也有一些高质量的数据。数据集市之上,就是基于MaxCompute去构建的数据处理的pipeline。
首先我们沉淀了海量的算子,比如说Minhash去重算子,语种识别的算子等等。在这各种算子之上,我们再构建了各种的处理的pipeline,包括千问的网页处理的pipeline, 还有图片处理的pipeline等。
在数据处理之后,这个数据往往不能够直接去用到千万和万相的训练中,因为处理完以后的数据,我们需要保障其满足一定质量要求。所以我们构建了一个清洗-训练-评测的数据飞轮,去不断寻找最优的清洗策略,最终数据质量达到一定标准后以后,会把这个数据提供给通义千问和通义万相,这个数据也会沉淀下来到我们的数据集市。
以上就是通义实验室的数据管理及处理解决方案,用于提供通义千万和通义万相的训练数据。