1 栈的基本操作(固定容量)

1. 定义栈的结构
cpp
#define MAXSIZE 100 // 定义栈的最大容量
typedef int ElemType; // 定义栈中元素的类型,这里假设为 int
typedef struct {
ElemType data[MAXSIZE]; // 用数组存储栈元素
int top; // 栈顶指针,初始为 -1,表示栈空
} SqStack;结构体定义的作用
cpp
typedef struct {
ElemType data[MAXSIZE]; // 用数组存储栈元素
int top; // 栈顶指针,初始为 -1,表示栈空
} SqStack;这段结构体定义的作用是创建一个栈(顺序栈)的数据结构模型,用于规范栈的存储方式和基本属性。我们来详细拆解它的作用:
1. 定义栈的存储结构
-
ElemType data[MAXSIZE]:这是一个数组,用于实际存储栈中的元素。ElemType是提前定义的元素类型(这里是int),方便后续修改栈存储的数据类型(比如改成float或自定义结构体)。MAXSIZE是栈的最大容量,定义了栈最多能存储多少个元素。
-
int top:这是栈顶指针,用于标记栈顶元素的位置,是栈操作的核心标记:- 初始值为
-1,表示栈为空(没有元素)。 - 当有元素入栈时,
top加 1;元素出栈时,top减 1。 - 通过
top的值可以判断栈的状态:top == -1表示栈空,top == MAXSIZE - 1表示栈满。
- 初始值为
2. 通过 typedef 简化使用
-
typedef关键字将这个结构体起了一个别名SqStack(Sequential Stack,顺序栈)。 -
之后可以直接用
SqStack来定义栈变量,而不需要每次都写struct {...},例如:cppSqStack stack; // 定义一个栈变量,比写 struct {...} stack 更简洁
3. 封装栈的属性
这个结构体将栈的存储空间(data 数组) 和状态标记(top 指针) 封装在一起,形成一个完整的栈对象。这样做的好处是:
- 操作栈时可以直接通过结构体变量访问这两个核心属性(例如
stack.top、stack.data[i])。 - 使代码逻辑更清晰,一看就知道这是一个栈结构,包含存储元素的空间和栈顶标记。
总结
简单说,这个结构体的作用就是为栈这种数据结构制定一个 "模板" ,规定了栈应该如何存储数据、如何标记状态,并且通过 typedef 简化了这个模板的使用。后续对栈的所有操作(入栈、出栈、取栈顶元素等),都是基于这个结构体来实现的。
2. 初始化栈(InitStack(&S))
cpp
// 初始化栈
void InitStack(SqStack *S) {
S->top = -1; // 将栈顶指针置为 -1,栈空
}解释 :初始化时,把栈顶指针 top 设为 -1,表示栈里还没有元素,这样后续入栈操作可以从数组下标 0 开始存储元素。
(SqStack *S)
(SqStack *S) 表示函数 InitStack 的参数,它的含义是:声明一个指向 SqStack 类型结构体的指针变量 S。
我们来详细拆解:
-
SqStack:这是我们之前通过typedef定义的结构体别名(表示 "顺序栈"),代表栈的数据结构类型。 -
*:这是指针符号,说明S是一个指针变量,它存储的是内存地址,而不是实际的结构体数据。 -
S:是这个指针变量的名称,用于在函数内部访问它指向的结构体。
为什么要用指针作为参数?
在 InitStack 函数中,我们的目的是初始化一个栈 (将栈顶指针 top 设为 -1)。由于 C 语言的函数参数传递是 "值传递"(即函数内部会复制一份参数),如果直接传结构体变量(SqStack S),函数内部修改的只是复制的临时变量,不会影响外部的原变量。
而传递指针(SqStack *S)时,函数内部可以通过指针直接访问和修改原结构体变量的内存空间,这样初始化操作才能真正生效。
例如,在主函数中这样调用:
cpp
SqStack stack; // 定义一个栈结构体变量
InitStack(&stack); // &stack 表示取 stack 的地址,传给指针参数 S此时函数内部的 S->top = -1 等价于 (*S).top = -1,实际修改的是外部 stack 变量的 top 成员。
简单说,(SqStack *S) 的作用是:让函数能够 "找到" 并修改外部定义的栈结构体变量,确保初始化操作能真正作用于目标栈。
3. 销毁栈(DestroyStack(&S))
对于顺序栈,因为是用数组(静态分配内存)实现的,内存是由系统自动管理的,所以销毁操作比较简单,只需将栈顶指针置为 -1 即可,相当于逻辑上销毁。
cpp
// 销毁栈
void DestroyStack(SqStack *S) {
S->top = -1; // 栈顶指针置为 -1,栈空,逻辑上销毁
}解释 :由于数组是在栈结构定义时静态分配的内存,不需要我们手动释放,所以将 top 设为 -1,让栈回到初始的空状态,就完成了销毁操作。
4. 判断栈是否为空(StackEmpty(S))
cpp
// 判断栈是否为空
int StackEmpty(SqStack S) {
if (S.top == -1) {
return 1; // 栈空,返回 1
} else {
return 0; // 栈非空,返回 0
}
}解释 :根据栈顶指针 top 的值来判断。如果 top == -1,说明栈里没有元素,返回 1 表示栈空;否则返回 0 表示栈非空。
5. 获取栈的长度(StackLength(S))
cpp
// 获取栈的长度
int StackLength(SqStack S) {
return S.top + 1; // 栈顶指针 + 1 就是栈中元素的个数
}解释 :因为栈顶指针 top 从 -1 开始,每入栈一个元素,top 就加 1。所以栈中元素的个数就是 top + 1,直接返回这个值即可。
6. 获取栈顶元素(GetTop(S, &e))
cpp
// 获取栈顶元素
int GetTop(SqStack S, ElemType *e) {
if (S.top == -1) {
return 0; // 栈空,获取失败
}
*e = S.data[S.top]; // 将栈顶元素赋值给 e
return 1; // 获取成功
}解释 :首先判断栈是否为空,如果为空,返回 0 表示获取失败。如果栈非空,栈顶元素是数组中 top 下标对应的元素,将其赋值给 e,返回 1 表示获取成功。
7. 入栈(Push(&S, e))
cpp
// 入栈
int Push(SqStack *S, ElemType e) {
if (S->top == MAXSIZE - 1) {
return 0; // 栈满,入栈失败
}
S->top++; // 栈顶指针上移
S->data[S->top] = e; // 将元素 e 放入栈顶
return 1; // 入栈成功
}解释 :先判断栈是否已满(top == MAXSIZE - 1),如果已满,返回 0 表示入栈失败。如果栈未满,先将栈顶指针 top 加 1,然后把要入栈的元素 e 放到新的栈顶位置,返回 1 表示入栈成功。
8. 出栈(Pop(&S, &e))
cpp
// 出栈
int Pop(SqStack *S, ElemType *e) {
if (S->top == -1) {
return 0; // 栈空,出栈失败
}
*e = S->data[S->top]; // 将栈顶元素赋值给 e
S->top--; // 栈顶指针下移
return 1; // 出栈成功
}解释 :首先判断栈是否为空,若为空,返回 0 表示出栈失败。若栈非空,先把栈顶元素(top 下标对应的元素)赋值给 e,然后将栈顶指针 top 减 1,返回 1 表示出栈成功。
9. 遍历栈(StackTraverse(S, visit()))
cpp
// 遍历栈的函数,这里假设 visit 是打印元素的函数
void visit(ElemType e) {
printf("%d ", e);
}
// 遍历栈
void StackTraverse(SqStack S, void (*visit)(ElemType)) {
int i;
for (i = 0; i <= S.top; i++) {
visit(S.data[i]); // 调用 visit 函数处理每个元素
}
printf("\n");
}解释 :从栈底(数组下标 0)到栈顶(数组下标 top)依次调用 visit 函数处理每个元素。这里的 visit 函数可以根据需求自定义,比如打印元素、对元素进行某种计算等。示例中 visit 函数是打印元素。
测试代码
下面是一个简单的测试代码,来验证这些操作:
cpp
#include <stdio.h>
int main() {
SqStack S;
ElemType e;
// 初始化栈
InitStack(&S);
printf("栈是否为空:%d\n", StackEmpty(S));
// 入栈
Push(&S, 1);
Push(&S, 2);
Push(&S, 3);
printf("栈的长度:%d\n", StackLength(S));
// 获取栈顶元素
GetTop(S, &e);
printf("栈顶元素:%d\n", e);
// 遍历栈
printf("遍历栈:");
StackTraverse(S, visit);
// 出栈
Pop(&S, &e);
printf("出栈元素:%d\n", e);
printf("出栈后遍历栈:");
StackTraverse(S, visit);
// 销毁栈
DestroyStack(&S);
printf("销毁后栈是否为空:%d\n", StackEmpty(S));
return 0;
}输出结果:
plaintext
bash
栈是否为空:1
栈的长度:3
栈顶元素:3
遍历栈:1 2 3
出栈元素:3
出栈后遍历栈:1 2
销毁后栈是否为空:12 栈的基本操作(可动态扩展容量)
这是可动态扩展容量的顺序栈的结构定义,和之前固定容量的顺序栈相比,它能在栈满时自动增加存储空间。我们来详细解释并实现其基础操作。
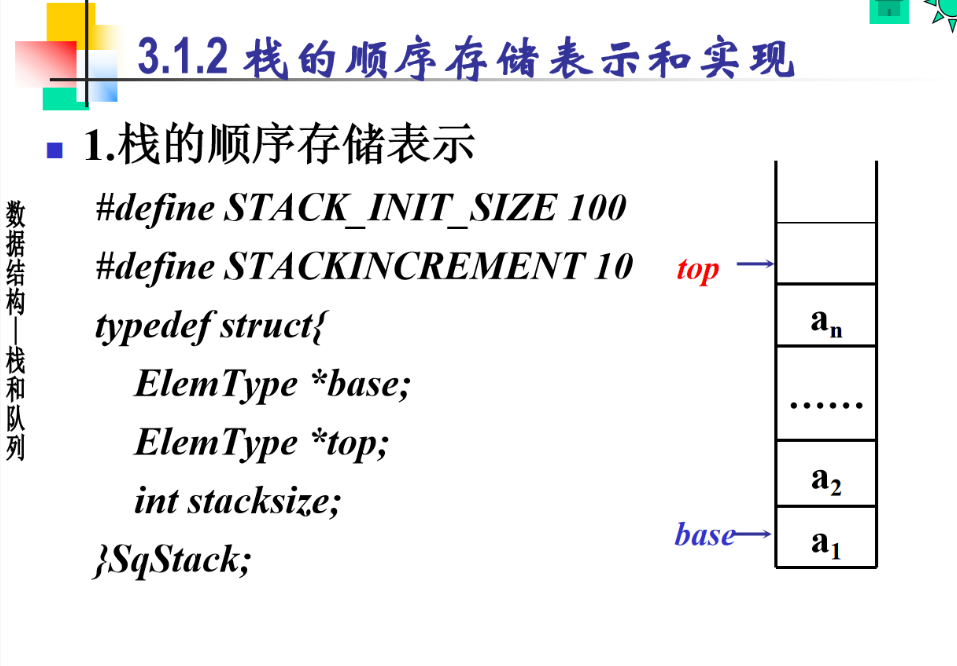
1. 定义栈的结构
cpp
#define STACK_INIT_SIZE 100 // 栈的初始容量
#define STACKINCREMENT 10 // 栈容量的增量
typedef int ElemType; // 定义栈中元素的类型,这里假设为 int
typedef struct {
ElemType *base; // 栈底指针,指向栈的起始位置
ElemType *top; // 栈顶指针,指向栈顶元素的下一个位置
int stacksize; // 当前栈的容量
} SqStack;2. 初始化栈(InitStack)
cpp
// 初始化栈
int InitStack(SqStack *S) {
// 分配初始容量的内存
S->base = (ElemType *)malloc(STACK_INIT_SIZE * sizeof(ElemType));
if (!S->base) {
return 0; // 内存分配失败
}
S->top = S->base; // 栈顶指针初始时与栈底指针重合,栈空
S->stacksize = STACK_INIT_SIZE; // 设置初始栈容量
return 1; // 初始化成功
}解释 :为栈分配初始容量的内存,栈底指针 base 指向分配内存的起始位置,栈顶指针 top 初始时和 base 重合,表示栈空,同时设置好初始的栈容量 stacksize。
S->base = (ElemType *)malloc(STACK_INIT_SIZE * sizeof(ElemType));
这句代码是在 C 语言中为栈分配初始内存空间的关键操作,我们一步步拆解它的含义:
cpp
S->base = (ElemType *)malloc(STACK_INIT_SIZE * sizeof(ElemType));1. 从右往左看:malloc(...)
malloc是 C 语言的内存分配函数,作用是向计算机申请一块内存空间。- 括号里的
STACK_INIT_SIZE * sizeof(ElemType)是要申请的内存大小(单位:字节):STACK_INIT_SIZE是我们定义的宏(初始容量,比如 100),表示栈一开始能存多少个元素。sizeof(ElemType)计算一个ElemType类型(这里是int)占用的字节数(比如int通常是 4 字节)。- 两者相乘就是:总字节数 = 元素个数 × 单个元素大小(例如 100 × 4 = 400 字节)。
2. 中间部分:(ElemType *)
- 这是强制类型转换 ,因为
malloc函数返回的是void *类型(通用指针,不明确指向哪种数据类型)。 - 我们需要把它转换成
ElemType *类型(指向ElemType类型的指针),这样才能和左边的S->base匹配。
3. 左边部分:S->base = ...
S是指向SqStack结构体的指针(之前定义的栈结构)。->是指针访问结构体成员的运算符,S->base表示访问S指向的结构体中的base成员(栈底指针)。- 整个赋值的意思是:把刚才申请的内存空间的起始地址,存到栈的
base指针里 ,让base指向这块内存的开头。
通俗理解
这句话就像:
- 告诉计算机:"我需要一块能装下 100 个
int类型数据的空间"(计算大小)。 - 计算机分配好空间后,返回这个空间的 "门牌号"(内存地址)。
- 我们把这个 "门牌号" 记到栈的
base成员里(以后就通过base找到这块空间)。
为什么要这样做?
- 栈需要一块连续的内存来存储元素,
malloc就是用来申请这块内存的。 base指针记录内存的起始位置,以后所有元素的存储、访问都从这个位置开始。- 如果申请失败(比如内存不足),
malloc会返回NULL,所以后面通常会判断是否申请成功。
例如,如果 ElemType 是 int(4 字节),STACK_INIT_SIZE 是 100,那么这句代码会申请 400 字节的内存,并让 base 指向这块内存的开头。
3. 销毁栈(DestroyStack)
cpp
// 销毁栈
void DestroyStack(SqStack *S) {
if (S->base) {
free(S->base); // 释放栈的内存
S->base = NULL;
S->top = NULL;
S->stacksize = 0;
}
}解释 :如果栈底指针 base 不为空,说明有分配的内存,将其释放,并把相关指针置空,栈容量设为 0。
4. 判断栈是否为空(StackEmpty)
cpp
// 判断栈是否为空
int StackEmpty(SqStack S) {
return S.top == S.base; // 栈顶指针和栈底指针重合则栈空
}解释 :当栈顶指针 top 和栈底指针 base 重合时,说明栈中没有元素,返回 1 表示栈空,否则返回 0。
5. 获取栈的长度(StackLength)
cpp
// 获取栈的长度
int StackLength(SqStack S) {
return S.top - S.base; // 栈顶指针与栈底指针的差值就是元素个数
}解释 :由于栈顶指针 top 指向栈顶元素的下一个位置,栈底指针 base 指向栈的起始位置,两者的差值就是栈中元素的个数。
6. 获取栈顶元素(GetTop)
cpp
// 获取栈顶元素
int GetTop(SqStack S, ElemType *e) {
if (S.top == S.base) {
return 0; // 栈空,获取失败
}
*e = *(S.top - 1); // 栈顶元素是栈顶指针的前一个位置的元素
return 1; // 获取成功
}解释 :先判断栈是否为空,若为空则获取失败。若栈非空,栈顶元素在栈顶指针 top 的前一个位置,将其赋值给 e,获取成功。
为什么这里不需要用指针 *S
在这个 GetTop 函数中,参数使用 SqStack S(结构体变量)而不是 SqStack *S(结构体指针),是因为这个函数只需要读取栈的内容,不需要修改栈本身。
我们详细解释为什么这里不需要用指针 *S:
1. 先明确 SqStack S 和 SqStack *S 的区别
SqStack S:函数参数是结构体变量的副本 。调用函数时,会把原栈的所有数据(base、top、stacksize)复制一份到S中。SqStack *S:函数参数是指向结构体的指针。调用函数时,只传递原栈的内存地址,不复制数据,通过地址直接操作原栈。
2. GetTop 函数的需求:只 "读" 不 "改"
GetTop 的作用是获取栈顶元素的值,流程是:
- 判断栈是否为空(只需读取
S.top和S.base的值)。 - 如果非空,读取栈顶元素的值(
*(S.top - 1)),并通过*e传出。
整个过程中,不需要修改栈的任何成员 (base、top、stacksize 都保持不变)。因此,即使使用副本 S,也能完成任务 ------ 因为我们只需要读取副本中的数据,不需要影响原栈。
3. 如果用 *S 会怎样?
如果写成 int GetTop(SqStack *S, ElemType *e),也能实现功能,代码会变成:
cpp
int GetTop(SqStack *S, ElemType *e) {
if (S->top == S->base) { // 用 -> 访问指针指向的结构体成员
return 0;
}
*e = *(S->top - 1);
return 1;
}这样写也是正确的,只是相比之下:
- 用
SqStack S更符合 "只读不修改" 的语义,代码更易理解。 - 用
SqStack *S虽然也能运行,但会给人一种 "可能要修改栈" 的暗示(实际上并没有)。
总结
函数参数用不用指针(*),核心看是否需要修改原变量:
- 如果需要修改原栈(如
InitStack、Push、Pop),必须用指针*S,否则修改的只是副本,原栈不会变化。 - 如果只需要读取栈的数据(如
GetTop、StackEmpty、StackLength),可以不用指针,直接传结构体变量的副本即可。
GetTop 属于 "只读" 操作,因此不需要用 *S。
7. 入栈(Push)
cpp
// 入栈
int Push(SqStack *S, ElemType e) {
// 栈满,需要扩展容量
if (S->top - S->base >= S->stacksize) {
ElemType *newBase = (ElemType *)realloc(S->base, (S->stacksize + STACKINCREMENT) * sizeof(ElemType));
if (!newBase) {
return 0; // 内存重新分配失败
}
S->base = newBase;
S->top = S->base + S->stacksize; // 调整栈顶指针
S->stacksize += STACKINCREMENT; // 增加栈容量
}
*(S->top) = e; // 存入元素
S->top++; // 栈顶指针上移
return 1; // 入栈成功
}解释 :先判断栈是否已满,若已满则重新分配更大的内存,调整栈底指针、栈顶指针和栈容量。然后将元素存入栈顶指针 top 指向的位置,栈顶指针上移。
ElemType *newBase = (ElemType *)realloc(S->base, (S->stacksize + STACKINCREMENT) * sizeof(ElemType));
这行代码主要用于在栈满时对栈所占用的内存空间进行动态扩容,下面详细解释其各部分的含义:
从右往左看
1. (S->stacksize + STACKINCREMENT) * sizeof(ElemType)
S->stacksize:S是指向SqStack结构体的指针,->是指针访问结构体成员的运算符,S->stacksize表示获取当前栈的容量大小,即当前栈最多能容纳的元素个数。STACKINCREMENT:这是一个通过#define定义的宏,代表每次栈容量需要增加的数量, 比如定义为10,就表示每次扩容增加10个元素的存储容量。sizeof(ElemType):sizeof是 C 语言的操作符,用于计算数据类型ElemType所占用的字节数,ElemType是栈中元素的数据类型,在这里被定义为int,通常情况下int类型占用 4 个字节。
三者相乘,得到的结果就是需要重新分配的内存空间的总字节数,也就是扩容后栈总共需要的内存大小。比如原来栈容量 S->stacksize 为 100,STACKINCREMENT 为 10,ElemType 是 int,那么这里计算出的总字节数就是 (100 + 10) * 4 = 440 字节。
2. realloc(S->base, ...)
realloc是 C 语言中的内存重新分配函数,它有两个参数。- 第一个参数
S->base是原来已分配内存块的起始地址,也就是当前栈所占用内存空间的起始位置。realloc函数会根据第二个参数指定的新的内存大小,对原来由S->base指向的内存块进行调整。调整的方式有以下几种情况:- 如果新的内存大小比原来小,
realloc会截断原来的内存块,并返回截断后内存块的起始地址。 - 如果新的内存大小比原来大,并且原来的内存块后面有足够的连续空闲内存空间,
realloc会在原来内存块的基础上直接扩展,然后返回扩展后内存块的起始地址。 - 如果新的内存大小比原来大,但是原来内存块后面没有足够的连续空闲内存空间,
realloc会在其他合适的内存位置重新分配一块满足新大小要求的内存块,然后把原来内存块中的数据复制到新的内存块中,释放原来的内存块,最后返回新内存块的起始地址。
- 如果新的内存大小比原来小,
realloc函数执行成功时,返回重新分配后的内存块的起始地址;如果执行失败(比如内存不足无法分配足够的空间),则返回NULL。
中间部分
(ElemType *) 是强制类型转换操作符,因为 realloc 函数返回的是 void * 类型(通用指针类型,可以指向任何类型的数据),而我们需要将其转换为 ElemType * 类型,也就是指向栈中元素类型的指针,这样才能将其赋值给 newBase。
左边部分
ElemType *newBase = ... 表示定义一个指向 ElemType 类型的指针变量 newBase,然后将 realloc 函数返回的地址赋值给 newBase,通过这个指针,后续就可以访问扩容后的栈内存空间。
简单来说,这行代码的作用就是在栈满时,重新分配一块更大的内存空间用于存储栈中的元素,并且通过 newBase 指针指向这块新的内存空间,以便后续对栈进行操作。
8. 出栈(Pop)
cpp
// 出栈
int Pop(SqStack *S, ElemType *e) {
if (S->top == S->base) {
return 0; // 栈空,出栈失败
}
S->top--; // 栈顶指针下移
*e = *(S->top); // 将栈顶元素赋值给 e
return 1; // 出栈成功
}解释 :先判断栈是否为空,若为空则出栈失败。若栈非空,栈顶指针下移,将此时栈顶指针指向的元素赋值给 e,出栈成功。
【和链表不同,s->top 为什么不是 s->top = s -> top -> next而是能够直接--】
在栈的实现中,s->top-- 这种操作方式与链表的 s->top = s->top->next 不同,核心原因是顺序栈和链表栈的存储结构本质不同。
我们来详细对比理解:
1. 顺序栈的存储本质:连续的数组空间
顺序栈(用数组实现的栈)的本质是一块连续的内存空间(数组),栈的所有元素在内存中是紧挨着存放的。例如:
数组索引:0 1 2 3 ... (连续的下标)
元素值: a b c d ... (连续存储)在这种结构中:
top本质是数组的下标(或指向数组元素的指针),用于标记栈顶元素的位置。- 由于数组下标是连续递增的(0→1→2→...),栈顶指针的移动只需要通过
++或--操作即可完成。
出栈时:
- 原来的
top指向栈顶元素的下一个位置(如指向索引 4,栈顶元素在索引 3)。 - 执行
s->top--后,top就指向了原来的栈顶元素(索引 3),相当于完成了栈顶的 "下移"。
2. 链表栈的存储本质:离散的节点 + 指针连接
链表栈的元素是分散存储在内存中的节点 ,每个节点通过 next 指针连接到下一个节点,内存中不一定连续:
节点1:值a → next→ 节点2:值b → next→ 节点3:值c → ...(离散存储)在这种结构中:
top是指向头节点的指针,每个节点的位置在内存中是随机的,没有连续的下标。- 要移动栈顶,必须通过节点的
next指针(s->top = s->top->next),才能找到下一个节点的位置。
3. 核心区别总结
| 类型 | 存储方式 | top 的本质 |
移动栈顶的方式 | 原因 |
|---|---|---|---|---|
| 顺序栈 | 连续数组 | 数组下标 / 连续指针 | top++/top-- |
元素连续存储,下标递增 |
| 链表栈 | 离散节点 + 指针 | 指向头节点的指针 | top = top->next |
元素离散存储,靠指针连接 |
简单说:顺序栈因为元素在内存中 "挨在一起",所以栈顶指针的移动像 "走连续的台阶",用 -- 就能完成;而链表栈的元素 "散落各处",必须通过 next 指针才能找到下一个位置,就像 "跳格子" 需要知道下一格的位置一样。
9. 遍历栈(StackTraverse)
cpp
// 遍历栈的函数,这里假设 visit 是打印元素的函数
void visit(ElemType e) {
printf("%d ", e);
}
// 遍历栈
void StackTraverse(SqStack S, void (*visit)(ElemType)) {
ElemType *p = S.base;
while (p < S.top) {
visit(*p); // 调用 visit 函数处理每个元素
p++;
}
printf("\n");
}解释 :从栈底指针 base 开始,到栈顶指针 top 结束,依次调用 visit 函数处理每个元素。示例中 visit 函数是打印元素。
测试代码
cpp
#include <stdio.h>
#include <stdlib.h>
int main() {
SqStack S;
ElemType e;
// 初始化栈
if (!InitStack(&S)) {
printf("栈初始化失败\n");
return 1;
}
printf("栈是否为空:%d\n", StackEmpty(S));
// 入栈
Push(&S, 1);
Push(&S, 2);
Push(&S, 3);
printf("栈的长度:%d\n", StackLength(S));
// 获取栈顶元素
if (GetTop(S, &e)) {
printf("栈顶元素:%d\n", e);
} else {
printf("获取栈顶元素失败\n");
}
// 遍历栈
printf("遍历栈:");
StackTraverse(S, visit);
// 出栈
if (Pop(&S, &e)) {
printf("出栈元素:%d\n", e);
} else {
printf("出栈失败\n");
}
printf("出栈后遍历栈:");
StackTraverse(S, visit);
// 销毁栈
DestroyStack(&S);
printf("销毁后栈是否为空:%d\n", StackEmpty(S));
return 0;
}输出结果:
plaintext
bash
栈是否为空:1
栈的长度:3
栈顶元素:3
遍历栈:1 2 3
出栈元素:3
出栈后遍历栈:1 2
销毁后栈是否为空:1这种可动态扩展容量的顺序栈,能更好地适应元素个数不确定的情况,避免了固定容量顺序栈可能出现的提前栈满或内存浪费的问题。