GPT-5的评价两极分化,实测下来表现还飘忽不定,推测可能跟"路由"功能有关;但一旦切到GPT-5 Pro模式、强制拉满最强功能,那是真的让人眼前一亮------它大概率就是目前市面上的最强模型了。
实测结果如下:
1、看图求解数独
只需要1分钟10s中,完美解决数独问题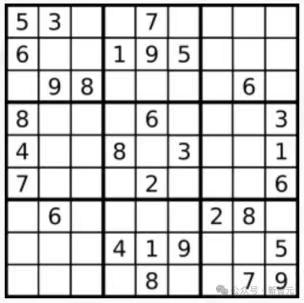

2、 比大小变体
比较9.9和9.11已经有了变体形式,通过求解方程来进一步测试模型的推理和计算能力。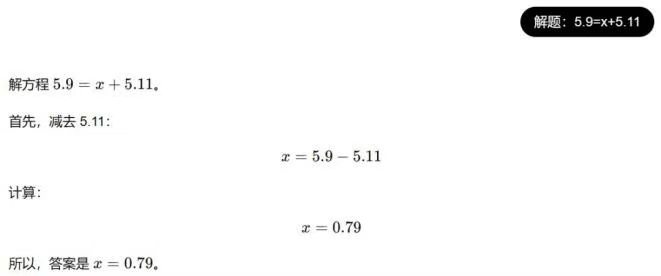
网友们也都玩出了花!
有人在实测后认为GPT-5 Pro确实是一个顶级模型,是最优秀的。
OpenAI在Pro版本上取得了巨大的进步!
Peter进行了12次测试。
结论是:没有任何其他模型能够匹敌,无论是OpenAI、Google、xAI还是Anthropic的模型。
所有这些测试都只用了 1-3 次尝试,输出结果确实非常出色。
沃顿商学院CS教授EthanMollick惊叹道,自己全程没有输出一行代码,就让GPT-5做出一个建筑生成器。
只需要重复一句话------改进它,就实现了如下的效果。
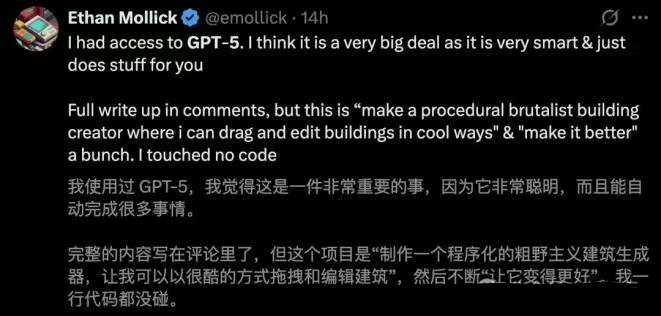
指南基于官方团队与早期测试者(如Cursor)的实践经验,总结了在不同场景下提升GPT-5输出质量的提示策略,涵盖智能体主动性调控、上下文收集优化、Responses API 的高效利用,以及在前端/全栈开发中的最佳实践。
OpenAI表示他们从规划到执行,尽可能的最大化编码性能。
比如前端开发,GPT-5 在训练中具备了出色的基准审美品味,同时拥有严谨的实现能力。
对于新应用,OpenAI建议使用以下框架和包,以最大程度地发挥该模型在前端方面的能力:
框架:Next.js(TypeScript)、React、HTML
样式/UI:Tailwind CSS,shadcn/ui,Radix 主题
图标:Material Symbols、Heroicons、Lucide
动画: Motion
字体:San Serif、Inter、Geist、Mona Sans、IBM Plex Sans、Manrope
并且网友们也整了一套GPT-5的提示词范例。比如
1.深度推理与问题解决(Deep Reasoning & Problem-Solving)
先把问题拆解成清晰步骤,再输出答案,减少推理错误。
2.先批评再定稿模式(Critique Before Final Mode)
先完成初稿,再让GPT-5批评并修改,提升质量。
3.角色+目标+约束(Role + Objective + Constraints)
设定身份、目标和严格约束,让输出更贴合需求。
4.逐步加深(Progressive Deepening)
先给高层概述,再逐步深入细节,避免一次性信息过载。
现在OpenAI已经把GPT-5之前的所有模型都放了出来。
快去看看你的ChatGPT里是否已经有了。也可通过以下方式三步对接gpt-5-pro模型:
三步对接gpt-5-pro
通过以下三步,可基于Go AI官方平台 快速完成gpt-5-pro模型的对接,全程兼容主流协议,无需复杂改造。
第一步:准备对接前置条件
对接前需完成3项基础准备,确保后续请求能正常发起。
- 获取Go AI的Key
前往Go AI平台注册账号。 - 确认gpt-5-pro模型ID
因Go API兼容多模型,需先通过平台客服(邮箱:1614284665@qq.com 或微信客服)确认gpt-5-pro的正式模型ID(如"gpt-5-pro",需与平台提供的ID完全一致,避免请求失败)。 - 准备请求工具/环境
选择常用的请求方式,如命令行工具(curl)、编程语言(Python、JavaScript等),确保环境能正常发起HTTPS POST请求。
第二步:构建API请求(核心参数配置)
Go API完全兼容OpenAI协议,需按要求配置Header 和Body参数,核心是确保必需参数不缺失。
1. 配置Header参数(3个必需项)
Header用于指定请求格式、鉴权信息,参数如下:
Content-Type:固定为application/json,表示请求体为JSON格式。Accept:固定为application/json,表示接受JSON格式的响应。Authorization:格式为Bearer {``{YOUR_API_KEY}},将{``{YOUR_API_KEY}}替换为第一步获取的Go API Key。
2. 配置Body参数(4个必需项+可选项)
Body需包含模型选择、对话内容、工具配置等核心信息,其中model、messages、tools、tool_choice为必需项,其他为可选优化项:
| 参数 | 类型 | 说明 |
|---|---|---|
model |
string | 填入第一步确认的gpt-5-pro模型ID(如"gpt-5-pro") |
messages |
arrayobj | 对话历史列表,每个对象含role(角色,如"user"代表用户)和content(对话内容) |
tools |
arraystring | 模型可调用的工具列表,目前仅支持函数,无特殊需求时填空数组[] |
tool_choice |
object | 控制工具调用,无工具时固定为{"type": "none"} |
temperature |
integer | 可选,0-2之间,值越高输出越随机(如0.8),越低越确定(如0.2) |
max_tokens |
integer | 可选,生成内容的最大token数,需满足"输入+输出token≤模型上下文长度" |
第三步:发送请求与处理响应
通过工具/代码发送请求,解析返回结果,同时处理常见问题。
1. 示例代码(2种常用方式)
方式1:curl命令(快速测试)
直接在命令行执行,替换{``{YOUR_API_KEY}}和{``{gpt-5-pro-model-id}}:
bash
curl --location --request POST 'https://api.goaigc.vip/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer {{YOUR_API_KEY}}' \
--data-raw '{
"model": "{{gpt-5-pro-model-id}}",
"messages": [
{
"role": "user",
"content": "请介绍gpt-5-pro的核心优势"
}
],
"tools": [],
"tool_choice": {"type": "none"},
"stream": false,
"temperature": 0.6,
"max_tokens": 500
}'方式2:Python代码(可集成到项目)
需先安装requests库(pip install requests),代码中替换API Key和模型ID:
python
import requests
import json
# 1. 基础配置
BASE_URL = "https://api.goaigc.vip/v1/chat/completions"
API_KEY = "{{YOUR_API_KEY}}"
MODEL_ID = "{{gpt-5-pro-model-id}}"
# 2. 请求头
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
# 3. 请求体
payload = {
"model": MODEL_ID,
"messages": [{"role": "user", "content": "请介绍gpt-5-pro的核心优势"}],
"tools": [],
"tool_choice": {"type": "none"},
"stream": False,
"temperature": 0.6,
"max_tokens": 500
}
# 4. 发送请求并解析响应
try:
response = requests.post(BASE_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status() # 捕获HTTP错误
result = response.json()
# 提取模型回复内容
assistant_reply = result["choices"][0]["message"]["content"]
print("gpt-5-pro回复:", assistant_reply)
# 查看token消耗(可选)
token_usage = result["usage"]
print("Token消耗:", f"请求{token_usage['prompt_tokens']}个,响应{token_usage['completion_tokens']}个,总计{token_usage['total_tokens']}个")
except Exception as e:
print("请求失败:", str(e))2. 响应结果解析
成功请求后会返回JSON格式响应,核心字段说明如下:
id:请求唯一标识,用于问题排查。choices[0].message:模型回复内容,role为"assistant",content为具体回复文本。finish_reason:回复结束原因,"stop"表示正常结束,"length"表示因max_tokens限制截断(需增大该参数)。usage:token消耗统计,用于成本核算。
3. 常见问题处理
- 鉴权失败:检查
Authorization格式是否正确(需带"Bearer "前缀),API Key是否过期(可联系客服核实)。 - 模型不存在:确认
model参数是否与平台提供的gpt-5-pro模型ID一致(需区分大小写)。 - 请求超时:可开启
stream=false(非流式响应),或联系客服优化全球中继节点。