📖标题:Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
🌐来源:arXiv, 2601.03211v1
🌟摘要
在企业搜索中,由于获取标记数据的困难,大规模构建高质量的数据集仍然是一个核心挑战。为了应对这一挑战,我们提出了一种有效的方法来微调小型语言模型 (SLM) 以实现准确的相关性标记,从而能够与最先进的大型语言模型 (LLM) 相比,高通量、特定领域的标记相当甚至更好。为了克服企业领域缺乏高质量和可访问的数据集,我们的方法利用了合成数据的生成。具体来说,我们使用 LLM 从种子文档中合成真实的企业查询,应用 BM25 来检索硬否定,并使用教师 LLM 分配相关性分数。然后将生成的数据集提炼成一个 SLM,产生一个紧凑的相关标签器。我们在由训练有素的人工注释者注释的 923 个企业查询-文档对组成的高质量基准上评估我们的方法,并表明蒸馏的 SLM 与人类判断的一致性与教师 LLM 相当或更好。此外,我们的微调标记器显着提高了吞吐量,实现了 17 倍的增加,同时成本也提高了 19 倍。这种方法为企业规模的检索应用程序实现了可扩展且具有成本效益的相关性标记,支持现实世界环境中的快速离线评估和迭代。
🛎️文章简介
🔸研究问题:如何通过小型语言模型(SLM)的微调技术实现高效的企业搜索相关性标注?
🔸主要贡献:论文提出了一种基于合成数据生成流程的SLM微调方法,使其在企业搜索相关性标注任务中实现了与大语言模型(LLM)相媲美的性能,同时显著提高了处理效率和降低了成本。
📝重点思路
🔸合成数据生成:使用LLM如GPT-4o,从企业文档中生成合成查询,这些查询是基于实际文档内容生成的,确保其与企业上下文相关。
🔸负样本挖掘:在生成合成查询后,利用BM25等信息检索算法,从文档库中检索出适合的负样本。这些负样本是指那些看似相关但实际上并不匹配的文档,以此构建出多样化的训练数据集,帮助模型学习如何区分真正相关的文档和仅相似或部分相关的文档。
🔸标签生成:随使用LLM对生成的查询-文档对进行相关性标记,为每个查询-文档对分配了一个从0(不相关)到4(高度相关)的评分。这个标签化过程使用了专门设计的提示模板,以确保生成的标签准确且一致。
🔸SLM微调:将生成的查询-文档-标签三元组用作训练数据,来微调SLM(例如Phi-3.5 Mini Instruct)。通过这种微调,SLM可以学习如何在实际企业搜索环境中,更准确地判断文档与查询之间的相关性。
🔎分析总结
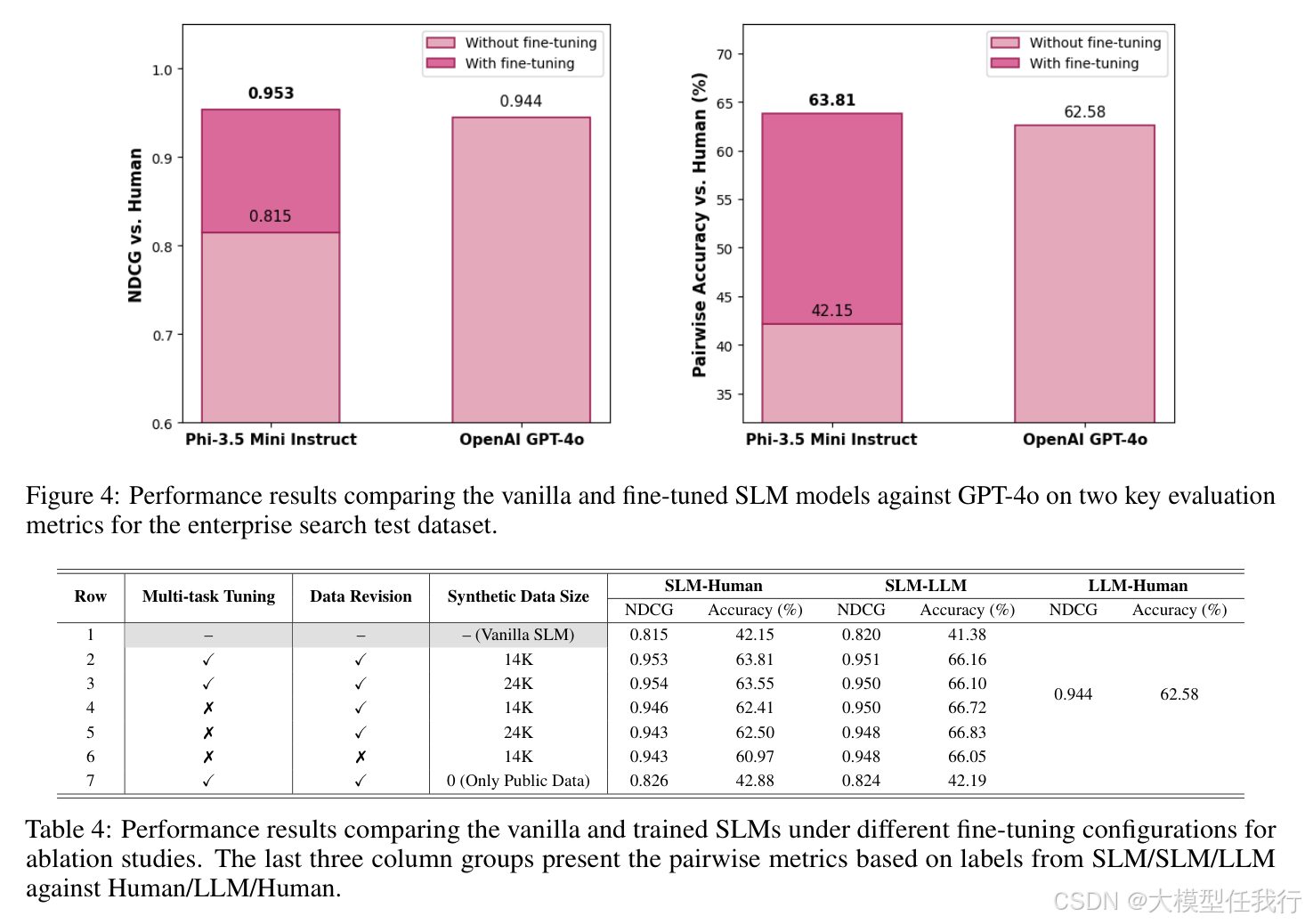
🔸实验结果显示,微调后的SLM在与人类标注的NDCG(0.953)和对比准确率(63.81%)上都优于GPT-4o(NDCG: 0.944,准确率: 62.58%),证明了SLM在企业查询标注任务中的有效性。
🔸通过合成数据生成,SLM实现了更高的处理吞吐量(每分钟873.33个请求),远远超过一般LLM标注器的处理速度。
🔸成本分析表明,微调后的SLM在输入和输出成本上显著低于LLM,证实了其经济效益。
🔸手动分析表明,微调后的模型在判断文档相关性时展现出了更好的校准性和信心,能够准确评估完全无关的文档。
💡个人观点
论文将合成数据生成与小语言模型的微调结合起来,提供了一种可行且高效的企业搜索相关性标注方案。
🧩附录