引言:为什么需要了解底层原理?
在日常开发中,我们经常使用volatile、synchronized和原子类来解决并发问题。但仅仅会使用这些工具是不够的,只有深入理解它们的底层实现原理,才能在复杂的并发场景中做出正确的技术选型,写出高性能、线程安全的代码。
想象一下:如果你只知道开车,却不了解发动机原理,当车子出现异常时你就无从下手。同样,只知道使用并发工具而不了解原理,在出现性能问题或诡异的并发bug时,你将束手无策。
本文将从CPU层面开始,逐步深入到JVM实现,用通俗易懂的比喻和代码示例,完整揭示Java并发机制的底层原理。
一、硬件基础:CPU与内存的交互
要理解Java并发机制,首先需要了解现代计算机架构的基本工作原理。
1.1 计算机存储层次结构
CPU寄存器 → L1缓存 → L2缓存 → L3缓存 → 主内存 → 磁盘速度对比:
-
CPU寄存器:~1ns(光速)
-
L1缓存:~1ns
-
L2缓存:~4ns
-
L3缓存:~10ns
-
主内存:~100ns(慢100倍!)
通俗比喻:
-
CPU寄存器:你手头上正在看的书
-
L1缓存:桌面上的几本常用书
-
L2/L3缓存:书架上的书
-
主内存:图书馆的书架
-
磁盘:远处的仓库
访问速度差异巨大,所以CPU会尽量把数据保存在离自己近的缓存中。
1.2 缓存行(Cache Line)
定义:CPU缓存的最小操作单位,通常是64字节。
通俗比喻:图书管理员的小推车上的一个格子,一次能放固定数量的书。管理员不会只拿一本书,而是把这本书及其旁边的几本书一起拿到小推车上。
// 伪代码演示缓存行的影响
public class CacheLineExample {
// 两个变量可能在同一个缓存行中 - 可能导致"虚假共享"
private volatile long variableA; // 8字节
private volatile long variableB; // 8字节
// 使用填充避免伪共享
private volatile long variableA;
private long p1, p2, p3, p4, p5, p6, p7; // 填充56字节
private volatile long variableB;
}虚假共享问题:如果两个不相关的变量在同一个缓存行中,一个CPU修改variableA时,会使其他CPU中整个缓存行失效,包括variableB,即使variableB没有被修改。
1.3 CPU流水线与内存顺序冲突
CPU流水线:像工厂流水线一样,将指令分解成多个步骤并行执行,提高效率。
// 没有流水线:完成3条指令需要9个周期
// 指令1:取指→译码→执行
// 指令2:取指→译码→执行
// 指令3:取指→译码→执行
// 有流水线:完成3条指令只需要5个周期
// 周期1:指令1取指
// 周期2:指令1译码,指令2取指
// 周期3:指令1执行,指令2译码,指令3取指
// 周期4:指令2执行,指令3译码
// 周期5:指令3执行内存顺序冲突:多个CPU同时修改同一缓存行的不同部分,导致CPU必须清空流水线,就像工厂流水线因为零件冲突而暂停。
二、volatile关键字的底层原理
2.1 volatile的语义
-
可见性:保证一个线程修改后,其他线程立即能看到最新值
-
禁止指令重排序:防止编译器优化打乱执行顺序
通俗比喻:volatile变量就像公司公告板上的重要通知。任何人修改通知时,必须立即更新公告板,并且所有人都能看到最新内容,不能偷偷修改。
2.2 内存屏障(Memory Barriers)
比喻:图书馆里的"请排队"隔离带,确保操作按顺序执行,防止乱序。
public class VolatileExample {
private volatile boolean flag = false;
private int value = 0;
public void writer() {
value = 42; // 普通写
// 写屏障 - 保证之前的写操作对后续操作可见
flag = true; // volatile写 - 插入写屏障
}
public void reader() {
if (flag) { // volatile读 - 插入读屏障
// 读屏障 - 保证之后的读操作能看到volatile读之前的所有写操作
System.out.println(value); // 保证看到value=42,而不是0
}
}
}2.3 volatile的硬件实现
当对volatile变量进行写操作时,JVM会向处理器发送Lock前缀的指令:
; Java代码:instance = new Singleton(); // instance是volatile变量
; 对应的汇编代码:
movb $0×0,0×1104800(%esi)
lock addl $0×0,(%esp) ; Lock前缀指令Lock前缀指令的作用:
-
立即写回内存:将当前处理器缓存行的数据强制写回系统内存
-
使其他缓存失效:通过缓存一致性协议,使其他CPU中缓存该内存地址的数据无效
通俗比喻:
-
普通变量:你在自己的笔记本上修改内容,别人不知道你改了
-
volatile变量:你在公告板上修改内容,同时用大喇叭喊:"我修改了,你们的笔记本副本都作废!"
2.4 缓存一致性协议(MESI)
MESI协议通过四种状态维护缓存一致性,就像图书馆的书籍管理:
-
M(Modified):这本书只有我手上有,而且我修改过了,与书架上的不同
-
E(Exclusive):这本书只有我手上有,但与书架上的内容一致
-
S(Shared):这本书我和其他人手上都有,内容都与书架一致
-
I(Invalid):我手上的这本书已经过时了,不能使用
三、synchronized的锁升级机制
3.1 synchronized的三种应用形式
public class SynchronizedExample {
// 1. 实例同步方法 - 锁当前实例对象(这把门的钥匙)
public synchronized void instanceMethod() {
// 临界区 - 只有拿到钥匙的线程能进入
}
// 2. 静态同步方法 - 锁当前类的Class对象(整栋大楼的总钥匙)
public static synchronized void staticMethod() {
// 临界区
}
// 3. 同步代码块 - 锁指定对象(特定房间的钥匙)
private final Object lock = new Object();
public void codeBlock() {
synchronized(lock) {
// 临界区
}
}
}3.2 Java对象头与Mark Word
每个Java对象都有一个对象头,就像每个人的身份证。对象头包含重要的Mark Word,记录对象的锁状态信息。
32位JVM的Mark Word结构:
| 锁状态 | 25bit | 4bit | 1bit(偏向锁) | 2bit(锁标志) |
|----------|---------------|----------|--------------|--------------|
| 无锁 | 对象哈希码 | 分代年龄 | 0 | 01 |
| 偏向锁 | 线程ID+Epoch | 分代年龄 | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | | 00 |
| 重量级锁 | 指向互斥量的指针 | | 10 |
| GC标记 | 空 | | | 11 |通俗比喻:Mark Word就像你的工作证,可以显示不同的状态:"空闲"、"张三专属"、"正在登记使用"、"会议室占用中"。
3.3 锁的升级过程
锁的升级路径:无锁 → 偏向锁 → 轻量级锁 → 重量级锁
这个设计很聪明:先用低成本方案,发现不行再逐步升级,就像处理问题先尝试简单方法,不行再用复杂方法。
3.3.1 偏向锁(Biased Locking)
场景:大多数情况下锁总是被同一线程重复获取
通俗比喻:公司会议室贴上"张三专属"标签。张三来了直接进入,不用登记。但如果李四也想用,就要撕掉标签,改用登记制度。
// 偏向锁的初始化流程
public void biasedLockDemo() {
Object lock = new Object();
// 第一次同步,启用偏向锁
synchronized(lock) {
// 在对象头记录当前线程ID,就像贴上"张三专属"
System.out.println("第一次获取锁,启用偏向锁");
}
// 同一线程再次同步,直接进入
synchronized(lock) {
// 检查线程ID匹配,无需CAS操作,直接进入
System.out.println("同一线程再次获取锁,直接进入");
}
}工作原理:
-
第一次获取锁时,在对象头记录线程ID
-
以后同一线程再次获取锁时,直接检查线程ID匹配即可
-
如果有其他线程竞争,就升级为轻量级锁
3.3.2 轻量级锁(Lightweight Locking)
场景:多个线程交替执行同步块,没有真正竞争
通俗比喻:会议室门口放个登记本。谁要用会议室,就在本子上签个名。用完后擦掉签名。如果两个人同时来登记,后到的人稍等一会再尝试。
public void lightweightLockDemo() {
Object lock = new Object();
Thread t1 = new Thread(() -> {
synchronized(lock) {
// 线程t1通过CAS在登记本上签名成功
try { Thread.sleep(100); } catch (InterruptedException e) {}
// 退出时擦掉签名
}
});
Thread t2 = new Thread(() -> {
try { Thread.sleep(10); } catch (InterruptedException e) {}
synchronized(lock) {
// 线程t2开始时发现登记本上已有签名(CAS失败)
// 自旋等待一会后再次尝试CAS,成功获得锁
}
});
t1.start();
t2.start();
}工作原理:
-
在当前线程栈帧中创建锁记录(Lock Record)
-
将对象头的Mark Word复制到锁记录中
-
使用CAS尝试将对象头指向锁记录
-
如果成功,获得锁;如果失败,自旋重试
3.3.3 重量级锁(Heavyweight Locking)
场景:多个线程激烈竞争同一把锁
通俗比喻:会议室安排专门的管理员。想用会议室的人要排队,用完后管理员叫下一个。虽然效率低,但保证不会冲突。
用户态与内核态切换的开销:
public class HeavyweightLockCost {
private final Object heavyLock = new Object();
public void expensiveOperation() {
synchronized(heavyLock) {
// 这里可能触发用户态→内核态切换,就像:
// 1. 普通员工(用户态)需要找经理(内核态)审批
// 2. 保存当前工作状态(保存寄存器)
// 3. 走到经理办公室(模式切换)
// 4. 等待经理处理(内核调度)
// 5. 拿结果回到工位(模式切换)
// 6. 恢复工作状态(恢复寄存器)
// 总开销:数千CPU周期!
}
}
}重量级锁的开销明细:
-
上下文保存:保存所有CPU寄存器状态
-
模式切换:用户态→内核态的权限切换
-
线程调度:内核执行线程阻塞和唤醒
-
缓存失效:相关缓存行可能失效
3.4 锁升级的触发条件

四、原子操作的实现原理
4.1 什么是原子操作?
原子操作:不可被中断的一个或一系列操作。
通俗比喻:ATM机转账,要么扣款和到账都成功,要么都失败,不会出现只扣款不到账的中间状态。
经典问题 :i++不是原子操作
public class NonAtomicExample {
private int i = 0;
public void increment() {
i++; // 实际上包含3个步骤:
// 1. 读取i的值(比如读取到5)
// 2. 计算i+1(得到6)
// 3. 将结果写回i(写入6)
// 如果两个线程同时执行,可能都读取到5,都计算得到6,都写入6
// 结果应该是7,但实际是6,丢失了一次更新!
}
}4.2 CPU层面的原子操作实现
4.2.1 总线锁定
工作原理:通过处理器的LOCK#信号锁定总线,阻止其他处理器访问内存。
通俗比喻:为了一家小店装修,封锁整条商业街,所有店铺都不能营业。
特点:
-
✅ 绝对安全:其他CPU完全无法干扰
-
❌ 开销巨大:影响所有内存访问,性能差
4.2.2 缓存锁定
工作原理:利用缓存一致性协议(MESI),只锁定特定缓存行。
通俗比喻:只封锁这家店铺装修,其他店铺正常营业。
流程:
CPU1要修改数据X(在缓存中)
↓
CPU1锁定自己缓存中的X
↓
CPU1通知其他CPU:"我正要修改X,你们的副本都作废!"
↓
其他CPU标记自己缓存中的X为"无效"
↓
CPU1安全地修改X
↓
其他CPU下次需要X时,必须重新从内存加载最新值4.3 Java中的原子操作实现
4.3.1 基于CAS的原子类
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicExample {
private AtomicInteger atomicI = new AtomicInteger(0);
private int normalI = 0;
// 线程安全的计数器 - 使用CAS
public void safeIncrement() {
atomicI.incrementAndGet(); // 底层使用CAS,保证原子性
}
// 非线程安全的计数器 - 可能丢失更新
public void unsafeIncrement() {
normalI++; // 非原子操作,多线程同时执行时可能丢失更新
}
// 手动实现CAS - 展示原理
public void manualCAS() {
int oldValue, newValue;
do {
oldValue = atomicI.get(); // 读取当前值
newValue = oldValue + 1; // 计算新值
// CAS: 如果当前值还是oldValue,就更新为newValue
// 否则重试(说明其他线程修改了值)
} while (!atomicI.compareAndSet(oldValue, newValue));
}
public static void main(String[] args) throws InterruptedException {
AtomicExample example = new AtomicExample();
// 创建多个线程同时增加计数器
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
example.safeIncrement(); // 原子操作,结果正确
example.unsafeIncrement(); // 非原子操作,结果错误
}
});
threads[i].start();
}
for (Thread t : threads) {
t.join();
}
System.out.println("原子计数器结果: " + example.atomicI.get()); // 一定是10000
System.out.println("普通计数器结果: " + example.normalI); // 可能小于10000
}
}4.3.2 CAS的底层实现
Java的CAS操作利用处理器的CMPXCHG指令:
// Java层面的CAS调用
boolean success = atomicI.compareAndSet(expect, update);
// 底层对应CPU指令
CMPXCHG [memory], expect, update
// 比较memory处的值与expect
// 如果相等,将update写入memory,设置标志位
// 否则,不做操作,清除标志位通俗比喻:CAS就像乐观的合租室友:
-
出门前看一眼冰箱有3个苹果
-
买菜回来,想放2个苹果进去(期望总数5个)
-
放之前再检查一下:如果还是3个,就放入2个变成5个
-
如果已经被 roommate 动过(变成2个或4个),就不放入了,重新计划
4.4 CAS的三大问题及解决方案
问题1:ABA问题
场景:值从A变成B又变回A,CAS检查时认为没有变化。
// 存在ABA问题的场景
public class ABAProblem {
private AtomicInteger atomicValue = new AtomicInteger(1);
public void demonstrateABA() {
// 线程1:A -> B -> A
atomicValue.set(2); // A→B
atomicValue.set(1); // B→A
// 线程2:检查到值还是1,认为没有被修改过
boolean success = atomicValue.compareAndSet(1, 3);
// success = true,但实际上值已经变化过了!
System.out.println("CAS成功: " + success); // 输出true
}
}通俗比喻:你离开时房间很乱(A),室友打扫干净(B)然后又弄乱(A)。你回来一看:"还是那么乱,没人动过嘛!" 但实际上房间经历了很多变化。
解决方案:使用版本号
import java.util.concurrent.atomic.AtomicStampedReference;
public class ABASolution {
private AtomicStampedReference<Integer> atomicStampedRef =
new AtomicStampedReference<>(1, 0); // 初始值1,版本号0
public void safeUpdate() {
int[] stampHolder = new int[1];
int expectedValue = atomicStampedRef.get(stampHolder);
int newValue = expectedValue + 1;
int expectedStamp = stampHolder[0]; // 期望的版本号
int newStamp = expectedStamp + 1; // 新版本号
// 同时检查值和版本戳
boolean success = atomicStampedRef.compareAndSet(
expectedValue, newValue, expectedStamp, newStamp);
System.out.println("更新" + (success ? "成功" : "失败"));
}
public void demonstrateSolution() {
// 线程1:1₀ → 2₁ → 1₂ (值+版本号)
atomicStampedRef.set(2, 1); // 1₀ → 2₁
atomicStampedRef.set(1, 2); // 2₁ → 1₂
// 线程2:期望 1₀,实际是 1₂,版本号不匹配,更新失败!
safeUpdate(); // 输出"更新失败"
}
}问题2:循环时间长开销大
如果竞争激烈,线程可能一直循环重试,浪费CPU。
解决方案:自适应自旋、pause指令
// JVM内部的优化策略
public class CASOptimization {
// 1. 自适应自旋:根据历史成功率调整自旋次数
// - 如果经常成功,多自旋一会
// - 如果经常失败,少自旋甚至直接阻塞
// 2. 使用pause指令减少CPU能耗
// - 让CPU在重试间稍作休息
// - 减少能耗,避免"内存顺序冲突"导致的流水线清空
// 3. 达到一定自旋次数后升级为重量级锁
}问题3:只能操作单个变量
CAS一次只能保证一个变量的原子性。
解决方案:
public class MultipleVariables {
// 方案1:多个变量使用锁
private int x, y;
private final Object lock = new Object();
public void updateWithLock(int newX, int newY) {
synchronized(lock) {
x = newX;
y = newY;
}
}
// 方案2:使用AtomicReference打包多个变量
private static class Point {
final int x;
final int y;
Point(int x, int y) { this.x = x; this.y = y; }
}
private final AtomicReference<Point> values =
new AtomicReference<>(new Point(0, 0));
public void updateWithAtomicReference(int newX, int newY) {
Point current;
Point newPoint;
do {
current = values.get();
newPoint = new Point(newX, newY);
} while (!values.compareAndSet(current, newPoint));
}
}五、实战:选择合适的并发控制机制
5.1 性能对比基准测试
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.LongAdder;
public class ConcurrentBenchmark {
private volatile boolean volatileFlag;
private final Object lock = new Object();
private int synchronizedCounter = 0;
private AtomicInteger atomicCounter = new AtomicInteger(0);
private LongAdder adderCounter = new LongAdder();
// 测试不同实现方式的性能
public long benchmarkVolatile(int iterations) {
long start = System.nanoTime();
for (int i = 0; i < iterations; i++) {
volatileFlag = !volatileFlag; // volatile写
}
return System.nanoTime() - start;
}
public long benchmarkSynchronized(int iterations) {
long start = System.nanoTime();
for (int i = 0; i < iterations; i++) {
synchronized(lock) {
synchronizedCounter++;
}
}
return System.nanoTime() - start;
}
public long benchmarkAtomic(int iterations) {
long start = System.nanoTime();
for (int i = 0; i < iterations; i++) {
atomicCounter.incrementAndGet();
}
return System.nanoTime() - start;
}
public long benchmarkLongAdder(int iterations) {
long start = System.nanoTime();
for (int i = 0; i < iterations; i++) {
adderCounter.increment();
}
return System.nanoTime() - start;
}
}5.2 选择指南
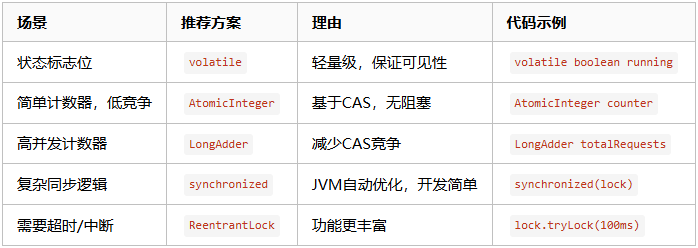
5.3 最佳实践示例
public class ConcurrentBestPractices {
// 1. 状态标志 - 使用volatile(保证可见性,不保证原子性)
private volatile boolean shutdownRequested = false;
public void shutdown() {
shutdownRequested = true; // 所有线程立即可见
}
public void workerThread() {
while (!shutdownRequested) {
// 处理任务...
}
}
// 2. 简单计数器 - 使用Atomic类(保证原子性)
private final AtomicInteger requestCount = new AtomicInteger(0);
public void handleRequest() {
requestCount.incrementAndGet(); // 原子操作
// 处理请求...
}
// 3. 复杂对象状态更新 - 使用synchronized
private final List<String> logEntries = new ArrayList<>();
public void addLogEntry(String entry) {
synchronized(logEntries) {
logEntries.add(entry);
// 其他复杂逻辑...
if (logEntries.size() > 1000) {
logEntries.subList(0, 500).clear(); // 需要原子性
}
}
}
// 4. 避免伪共享 - 使用填充
private static class PaddedAtomicLong extends AtomicLong {
// 填充缓存行,避免与相邻变量共享缓存行
public volatile long p1, p2, p3, p4, p5, p6, p7 = 7L;
}
// 5. 根据竞争程度选择方案
public void smartIncrement() {
// 低竞争时使用CAS
if (atomicCounter.get() < 1000) {
atomicCounter.incrementAndGet();
} else {
// 高竞争时使用LongAdder
adderCounter.increment();
}
}
}六、总结
Java并发机制的底层实现是一个多层次协作的复杂系统,理解这些原理对于编写高性能、线程安全的代码至关重要。
6.1 核心要点回顾
-
volatile:
通过内存屏障保证可见性和顺序性
底层使用Lock前缀指令和缓存一致性协议
适合状态标志,不保证复合操作的原子性
-
synchronized:
基于对象头和Monitor实现
智能的锁升级机制:偏向锁→轻量级锁→重量级锁
在保证线程安全的同时尽量降低开销
-
原子操作:
CPU层面通过总线锁定或缓存锁定实现
Java层面通过CAS循环实现
需要处理ABA问题、循环开销等问题
6.2 设计哲学
Java并发机制的设计体现了重要的工程哲学:
-
无竞争优化:通过偏向锁等机制,让无竞争情况下的开销最小
-
渐进式升级:根据竞争激烈程度自动选择合适的同步机制
-
平台适应性:充分利用不同CPU架构的特性
-
开发便利性:提供高层抽象,隐藏底层复杂性
6.3 学习建议
要真正掌握Java并发编程,建议:
-
理解原理:不仅要会用,更要明白为什么这样用
-
分析场景:根据具体场景选择最合适的并发控制机制
-
关注性能:在保证正确性的前提下考虑性能影响
-
持续学习:Java并发库在不断演进,保持学习心态
-
实践验证:通过测试和性能分析验证理解是否正确
6.4 思维模型
建立正确的并发思维模型:
-
把CPU缓存想象成:每个线程的私人工作空间
-
把内存屏障想象成:同步点的"检查站"
-
把锁想象成:资源的访问权限令牌
-
把CAS想象成:乐观的并发控制策略
通过深入理解这些底层原理,我们不仅能够写出更好的并发代码,也能够在遇到并发问题时快速定位和解决,真正成为并发编程的专家。
记住:并发bug往往在最意想不到的时候出现,只有深入理解原理,才能防患于未然。
文章转载自: ++佛祖让我来巡山++