系统架构设计
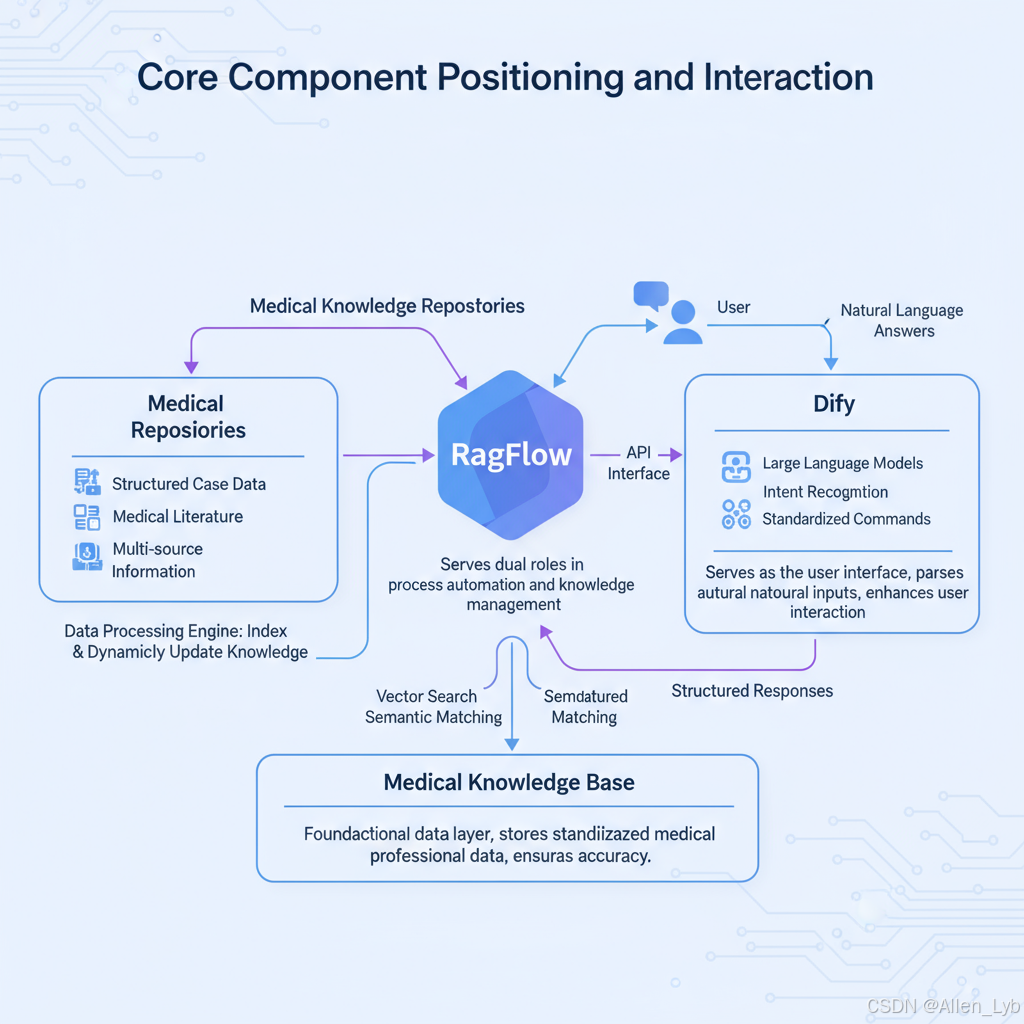
本系统架构采用分层协同设计,以 RagFlow 作为流程中枢与知识管理核心,Dify 作为自然语言交互入口,通过标准化接口实现医疗知识库的自动化查询与智能响应。整体架构包含环境支撑层、核心功能层与交互层三个逻辑单元,各组件通过 API 接口实现数据流转与功能联动,形成闭环知识服务体系。
核心组件定位与交互关系
- RagFlow:承担流程自动化与知识管理双重角色,一方面通过内置的数据处理引擎连接医疗知识库(包含结构化病例数据、医学文献、诊疗指南等多源信息),实现知识的索引构建与动态更新;另一方面作为中枢系统,接收 Dify 传递的用户意图,触发预设流程完成知识库精准查询与结果整合。
- Dify:作为用户交互入口,基于大语言模型实现自然语言输入解析,通过意图识别算法将用户查询转化为标准化指令,再通过 API 接口传递至 RagFlow。同时,Dify 负责将 RagFlow 返回的结构化结果转化为自然语言回答,提升用户交互体验。
- 医疗知识库 :作为底层数据支撑,存储经过标准化处理的医疗专业数据,支持 RagFlow 的向量检索与语义匹配功能,确保查询结果的准确性与权威性。
数据流转逻辑
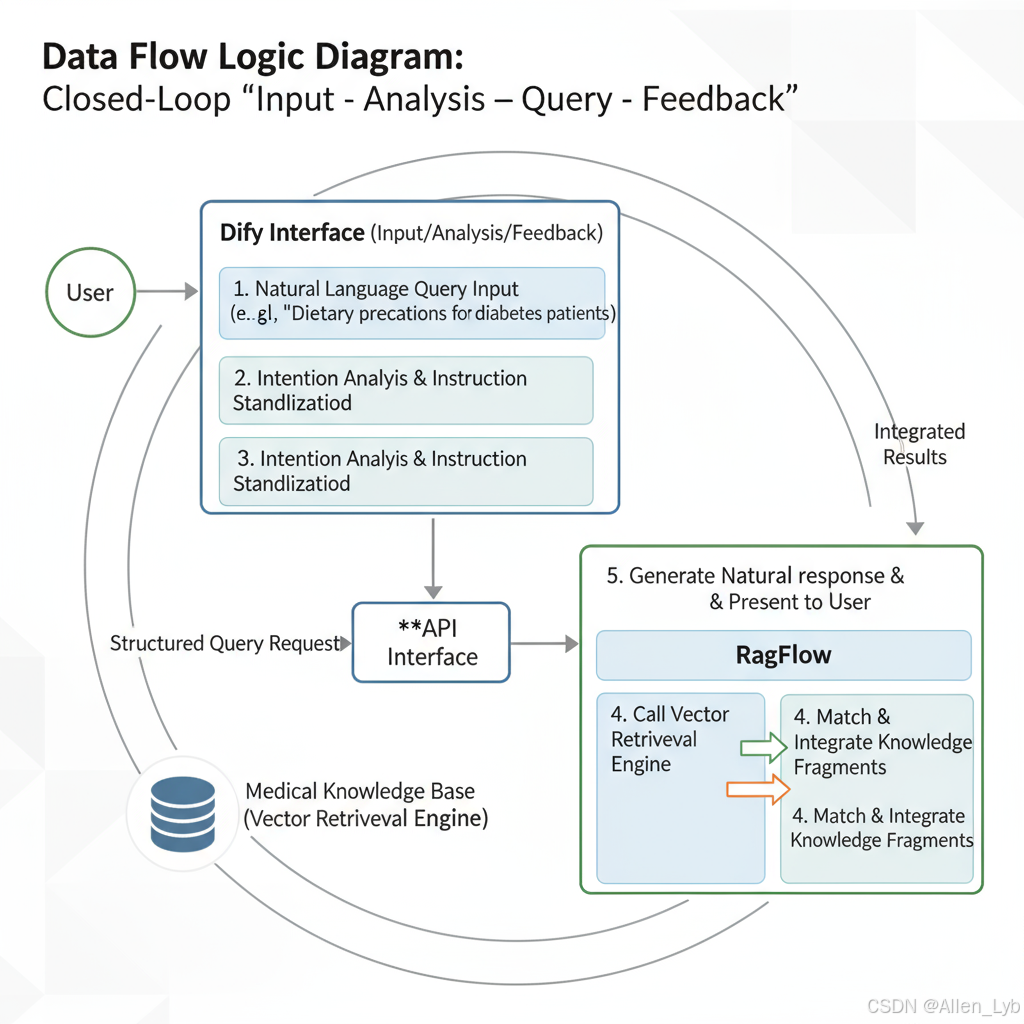
系统采用"输入-解析-查询-反馈"的闭环流转机制,具体流程如下:
用户交互流程
- 用户通过 Dify 界面输入自然语言查询(如"糖尿病患者的饮食注意事项");
- Dify 进行意图解析与指令标准化,生成结构化查询请求;
- 请求通过 API 接口 传输至 RagFlow,触发知识检索流程;
- RagFlow 调用医疗知识库的向量检索引擎,匹配相关知识片段并整合;
- 整合结果经 RagFlow 处理后返回至 Dify,由 Dify 生成自然语言回答呈现给用户。
技术集成与扩展预留
架构设计中已为后续代码开发预留关键集成点,包括:
- API 接口层:需开发标准化 RESTful API 实现 Dify 与 RagFlow 的双向通信,定义意图指令格式、知识库查询参数及结果返回规范,支持 Python/Java 等多语言调用;
- 数据处理脚本:在 RagFlow 侧需开发医疗数据预处理模块(如 PDF 文献解析、病例数据清洗脚本),确保知识库数据的结构化与标准化,可采用 Python 的 Pandas 库与 NLTK 工具包实现;
- 流程配置接口:预留 RagFlow 流程模板自定义入口,支持医疗场景化查询流程的可视化配置(如鉴别诊断流程、用药推荐逻辑)。
通过上述架构设计,RagFlow 与 Dify 的协同实现了医疗知识"存储-检索-交互"的全链路自动化,既保留了知识库的专业性与准确性,又通过自然语言交互降低了医疗信息获取门槛,为后续技术落地奠定了模块化、可扩展的系统基础。
环境搭建与配置
RagFlow环境部署
0. 目标环境与先决条件
-
OS:Linux / macOS / Windows(WSL2 建议)
-
Node.js:v14--v16 (若使用
node-sass,更推荐 v14/16;若已迁移sass,可放宽到 v18+) -
包管理器:npm(或 pnpm / yarn,三选一,不要混用)
-
Git、构建工具链:
- Linux:
build-essential、python3(node-gyp 依赖) - macOS:
xcode-select --install - Windows:管理员 PowerShell 运行
npm i --global --production windows-build-tools(或安装 Visual Studio Build Tools)
- Linux:
1. 源码获取(可选:锁定分支/标签)
bash
# 1) 克隆代码(替换为实际仓库地址/分支/标签)
git clone https://github.com/ragflow/ragflow.git
cd ragflow
# 2) (可选)切到稳定分支或标签
git checkout <branch-or-tag>
# 3) (可选)启用子模块
# git submodule update --init --recursive小贴士 :在仓库根目录写 .nvmrc 与 engines,避免团队版本漂移:
bash
# .nvmrc
v16
json
// package.json
"engines": { "node": ">=14 <=18", "npm": ">=6" }2. 依赖管理(node-sass 常见错误的系统化解法)
目标:在尽量不改代码的前提下,保证装依赖 100% 通过。
2.1 Node 版本匹配(优先)
bash
# 使用 nvm 固定版本(推荐 v14 或 v16)
nvm install 16
nvm use 162.2 加速与镜像(中国大陆网络建议)
bash
npm config set registry https://registry.npmmirror.com
npm config set sass_binary_site https://npm.taobao.org/mirrors/node-sass/
# 可选:增加 node-gyp 源
npm config set python python32.3 安装依赖(按需处理 node-sass)
方案 A:继续使用 node-sass(保持兼容)
bash
npm install
# 若失败,先单独装 node-sass 的二进制
npm install node-sass --save --sass_binary_site=https://npm.taobao.org/mirrors/node-sass/
npm rebuild node-sass方案 B:迁移到 sass(推荐)
bash
npm uninstall node-sass
npm install sass --save
# 如构建脚本使用了 node-sass CLI,需要将脚本改为 "sass" 或使用构建工具插件常见错误速解
node-sass binding missing / node-gyp rebuild 失败→ 确认 Node 版本在 LTS 范围(14/16),安装构建工具链,执行npm rebuild node-sass。ERR_OSSL_EVP_UNSUPPORTED(Node 高版本 OpenSSL)→ 降 Node 至 16 或启动时export NODE_OPTIONS=--openssl-legacy-provider(临时过渡,不建议长用)。- "网络超时 / 二进制下载失败" → 配置
sass_binary_site、换镜像源、或离线缓存.npmrc + .npm/_cacache。
3. 启动与运行
3.1 开发模式(热更新)
bash
# 典型脚本
npm run dev
# 若项目仅提供 start:
npm run start控制台出现:
RagFlow server running on port 3000即表示监听 3000 端口成功。
3.2 生产模式(构建 + 守护)
bash
# 构建产物
npm run build
# 生产启动(示例)
npm run start:prod
# 借助 PM2 守护进程
npm install -g pm2
pm2 start npm --name ragflow -- run start:prod
pm2 logs ragflow
pm2 save3.3 健康检查与验证
bash
# 健康检查(示例接口,按实际路由调整)
curl -f http://127.0.0.1:3000/health || exit 1
# 或检查首页
curl -I http://127.0.0.1:30004. 基础配置(.env 与配置层次)
- 复制模板并编辑:
bash
cp .env.example .env- 核心参数(示例):
env
# 监听端口
PORT=3000
# 数据库连接(按项目类型换成 Mongo/MySQL/Postgres...)
DATABASE_URL=postgres://user:pass@127.0.0.1:5432/ragflow
# 缓存/消息队列(可选)
REDIS_URL=redis://127.0.0.1:6379/0
# 日志与运行环境
NODE_ENV=production
LOG_LEVEL=info
# 外部依赖(如向量库/对象存储/检索服务)
VECTOR_DB_URL=http://127.0.0.1:8080
S3_ENDPOINT=https://s3.example.com优先级建议 :
.env(本地) < 环境变量(容器/CI) < 生产密钥管控(Vault/KMS)。不要把.env提交到仓库。
5. 可选:Docker 一键化(团队统一环境)
Dockerfile(示例)
dockerfile
FROM node:16-alpine
WORKDIR /app
COPY package*.json ./
RUN npm config set registry https://registry.npmmirror.com
RUN npm install --production
COPY . .
RUN npm run build
ENV PORT=3000
EXPOSE 3000
CMD ["npm", "run", "start:prod"]docker-compose.yml(示例)
yaml
version: "3.8"
services:
ragflow:
build: .
ports:
- "3000:3000"
env_file:
- .env
restart: always6. 目录与脚本规范(避免踩坑)
- 仅保留一个锁文件:
package-lock.json或pnpm-lock.yaml/yarn.lock;不要混用。 - 在
package.json中补充统一脚本:
json
{
"scripts": {
"dev": "cross-env NODE_ENV=development nodemon src/main.js",
"build": "tsc -p tsconfig.json || vite build || webpack --mode production",
"start": "node dist/main.js",
"start:prod": "cross-env NODE_ENV=production node dist/main.js",
"health": "node scripts/healthcheck.js"
}
}7. 常见问题排查(Cheat Sheet)
| 症状 | 可能原因 | 快速修复 |
|---|---|---|
node-sass 构建失败 |
Node 版本不匹配 / 二进制下载失败 | nvm use 16 → 配置镜像 → npm rebuild node-sass |
ERR_OSSL_EVP_UNSUPPORTED |
Node/OpenSSL 版本冲突 | 降 Node 至 16 或临时 NODE_OPTIONS=--openssl-legacy-provider |
| 启动端口被占用 | 3000 已被占用 | 改 .env 的 PORT 或 lsof -i:3000 杀进程 |
| 前后端跨域 | CORS 未配置 | 在服务端开启 CORS 白名单或反向代理(Nginx/Traefik) |
| 生产 CPU 飙高 | 开发模式或 Sourcemap 打开 | 使用 start:prod,关闭开发插件与过量日志 |
8. 最小可执行清单(TL;DR)
bash
# 环境
nvm install 16 && nvm use 16
npm config set registry https://registry.npmmirror.com
# 获取 & 依赖
git clone https://github.com/ragflow/ragflow.git
cd ragflow
cp .env.example .env && vi .env
npm install || (npm i node-sass --sass_binary_site=https://npm.taobao.org/mirrors/node-sass/ && npm rebuild node-sass)
# 启动
npm run build
npm run start:prod
# 预期日志
# RagFlow server running on port 3000Dify SDK集成与初始化
Dify SDK集成需遵循"安装-配置-调用-异常处理"的标准化流程,确保医疗知识库查询接口的稳定对接。
pip install dify-sdk安装最新稳定版 SDK,锁定在部署脚本中统一管理依赖。- 在部署环境写入
DIFY_API_KEY环境变量,避免在代码或仓库中硬编码密钥。 - 运行时通过
os.getenv('DIFY_API_KEY')读取密钥,未设置时需提前校验并抛出友好提示。
初始化示例
python
import os
import dify_sdk
from dify_sdk.rest import ApiException
api_key = os.getenv("DIFY_API_KEY")
if not api_key:
raise RuntimeError("缺少 DIFY_API_KEY 环境变量")
configuration = dify_sdk.Configuration()
configuration.api_key["Authorization"] = api_key
api_client = dify_sdk.ApiClient(configuration)
chat_api = dify_sdk.ChatApi(api_client)调用与异常处理
python
try:
response = chat_api.create_chat_completion(
request_id="unique-medical-query-id",
user="doctor_user",
inputs={"question": "糖尿病患者的饮食注意事项"},
response_mode="blocking",
)
print(f"查询结果: {response.answer}")
except ApiException as exc:
print(f"API 调用失败: {exc.status} - {exc.reason}")
except Exception as exc:
print(f"系统异常: {exc}")request_id建议使用可追踪的唯一值,便于日志关联。inputs中附带充分的临床上下文,可提升知识库检索准确度。- 捕获
ApiException能帮助区分接口异常与系统故障,按需补充日志与重试策略。
安全要点:生产环境中需通过密钥管理服务(如AWS KMS、HashiCorp Vault)强化密钥保护,同时限制API密钥的最小权限范围,仅开放医疗知识库查询所需接口权限。
错误处理需覆盖API层与系统层异常,包括超时、权限不足、参数错误等场景,通过分层捕获机制确保服务稳定性,避免单一异常导致整个查询系统中断。
基础环境验证与问题排查
-
先完成基础可用性验证:通过浏览器访问 RagFlow 控制台
http://localhost:3000,确认登录页和核心模块加载正常;用 Dify SDK 健康检查验证 Python 侧联通性:pythonfrom dify_client import Client client = Client(api_key="your_key") assert client.health_check.ping() == {"status": "ok"} -
如出现异常,按以下顺序排查:
- 端口冲突 :
lsof -i:3000(RagFlow)或lsof -i:8000(Dify)定位占用进程,必要时kill -9 <PID>释放后重启服务。 - 依赖缺失 :
pip list | grep dify_sdk检查 SDK 是否存在;若缺失或版本错误,执行pip install dify-sdk==0.3.0。 - 密钥配置 :确认配置文件中的
API_KEY或环境变量$DIFY_API_KEY与 Dify 平台项目设置一致,避免认证失败。
- 端口冲突 :
-
验证与排查完成后,记录结果、保留关键日志,为后续集成测试提供可追溯依据。
医疗知识库构建与预处理
多源医疗数据采集与整合
数据采集框架
- 统一进行源分类:公共卫生数据集、权威机构 API、临床合作数据;按疾病监测、诊疗指南、真实世界数据构建闭环。
- 公共卫生数据集(CDC 法定传染病报告、NHS 人口健康数据等)定期发布 CSV/JSON,具备时空连续性,可直接用于流行病学趋势建模。
- 权威机构 API(如 WHO GHO)提供标准化指标;按指标编码和国家代码拉取最新数据,便于跨国对比与更新。
- 临床合作数据来自 EHR,强调脱敏、合规与可审计性,形成面向诊疗决策的高价值数据层。
WHO GHO 调用示例
python
import requests
def fetch_who_data(indicator_code: str, country_code: str):
base_url = f"https://ghoapi.azureedge.net/api/{indicator_code}"
params = {"$filter": f"SpatialDim eq '{country_code}'"}
resp = requests.get(base_url, headers={"Accept": "application/json"}, params=params, timeout=10)
if resp.status_code != 200:
raise RuntimeError(f"GHO API 请求失败:{resp.status_code} {resp.text}")
return resp.json().get("value", [])
# 示例:抓取中国 2020 年新生儿死亡率
data = fetch_who_data("MDG_0000000026", "CHN")
china_2020 = [item for item in data if item.get("TimeDim") == "2020"]
print(china_2020)- 使用
$filter精确限定国家,TimeDim/Value字段可直接用于趋势分析。 - 加入超时和错误信息输出,便于监控与告警。
EHR 数据脱敏要点
- 直接标识符(患者 ID、姓名等)采用 SHA-256 等不可逆散列;保留冲突检测机制。
- 准标识符执行 k-匿名化(如出生日期仅保留年份、邮编保留前缀),同时监控群组大小。
- 聚合统计输出叠加差分隐私噪声,防止逆推个体。
- 全流程满足 HIPAA/GDPR:记录脱敏日志、严格的原始/脱敏数据物理隔离、定期合规审计。
建议:
- 建立多源数据更新调度与质量评估脚本,自动化异常告警。
- 为脱敏流程编写单元/集成测试及审计报告模板,方便监管审核。
医疗数据标准化与结构化建模
医疗数据的标准化与结构化建模,是构建高效医疗知识库与智能化查询系统的核心基础。通过统一数据定义 、清晰关系建模 以及语义化表示,可以实现医疗信息的高效组织、精准关联与灵活查询,为临床决策支持和知识发现奠定技术底座。
一、核心数据实体与属性规范
系统需抽象并定义四大核心数据实体,每类实体包含明确的主键标识及标准化属性字段:
-
疾病(Diseases)
- 属性:疾病ID、名称、ICD-10编码、病因、诊断标准等
- 特点:作为医疗知识库的核心索引实体,对应症状、药品及治疗方案等多个对象。
-
症状(Symptoms)
- 属性:症状ID、名称、临床表现、关联系统(如呼吸系统、消化系统等)
- 特点:为疾病诊断和临床推理提供基础语义支撑。
-
药品(Medications)
- 属性:药品ID、通用名称、商品名、成分、适应症、用法用量、副作用等
- 特点:与疾病及治疗方案紧密关联,支持药物知识图谱的构建。
-
治疗方案(TreatmentPlans)
- 属性:方案ID、名称、适用疾病、实施步骤、预期效果等
- 特点:作为疾病管理和临床路径的重要组成部分,可关联多类干预措施。
二、实体间关系建模与映射
为了支持复杂的临床语义检索与自动推理,系统需明确定义实体间的关联关系结构:
-
疾病 ↔ 症状:多对多关系。
- 一种疾病可能对应多种症状,一种症状也可能出现在多种疾病中。
- 通过**中间关联表(Disease_Symptom_Relation)**实现映射,记录疾病ID与症状ID的对应关系,并可扩展置信度、临床权重等字段。
-
疾病 ↔ 药品:多对多关系。
- 支持疾病到治疗药物的溯源与前向推理,便于临床推荐与处方辅助。
-
疾病 ↔ 治疗方案:一对多关系。
- 一种疾病可对应多个治疗方案,满足不同临床场景与个体化治疗需求。
三、语义化与标准化支撑
为进一步提升数据可互操作性与可扩展性,建模过程中需遵循国际通用标准与本体规范:
- 引入ICD、SNOMED CT等标准编码体系,确保概念语义一致性;
- 使用统一命名规范与数据字典,降低数据冗余与歧义;
- 支持RDF/OWL等语义网技术,为后续知识图谱构建奠定基础。