你想成为那位用巧妙提示解锁 LLM 知识与算力"宝库"的低语者(whisperer)吗?要判断何种提示才算聪明、如何"撩"出正确答案,你首先需要理解 LLM 如何处理信息------也就是它们如何"思考" 。
本章我们将采用**"洋葱式" (层层剥离)的方式来展开。你将先在《什么是 LLM? 》中从 最外层把 LLM 看作受训的文本"模仿器";接着在《LLM 如何观察世界》中了解它们如何把文本切分为称作token**的"可咀嚼小块",以及当切分不顺利时会带来的后果。
随后,你会在《一次一个 token 》中看到 token 序列是如何一点一点 生成的,并在《温度与概率 》中了解选择下一个 token 的不同策略。最后,在《Transformer 架构 》中,你将深入 LLM 的最内层机理 :把它理解为一组通过名为注意力 的"问答游戏"彼此沟通的"小脑袋",并据此理解提示次序为何重要。
在整个过程中,请记住:这本书讲的是如何使用 LLM ,而不是 LLM 本身的全部细节。因此,很多很酷但对提示工程无关 的技术细节(比如矩阵乘法、激活函数)我们不会展开。如果你想深潜这些内容,可以参考经典文章 The Illustrated Transformer 。不过,只要你的目标是写出优秀的提示 ,你并不需要那么多技术背景------现在就让我们深入你确实需要知道的部分。
什么是 LLM?
在最基础的层面,LLM 就是一个**"输入字符串 → 输出字符串"的服务:文本进,文本出。输入称为 提示(prompt) ,输出称为 补全(completion) ,有时也称回复(response)**(见图 2-1)。
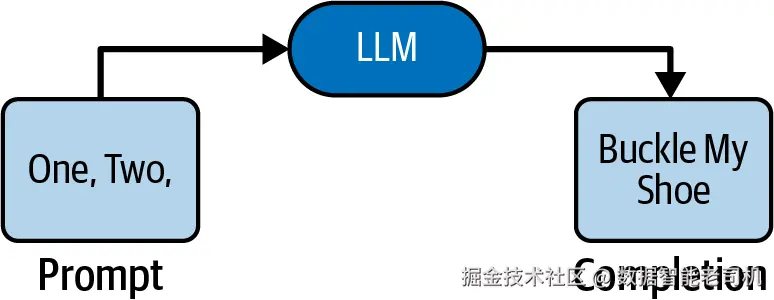
图 2-1. 一个 LLM 接收提示 "One, Two," 并给出补全 "Buckle My Shoe"
一个未经训练 的 LLM 初见天日时,它的补全大都像是随机的 Unicode 符号堆,与提示几乎没有关系 。它需要先被训练 ,然后才能有用。训练之后,LLM 就不再是"字符串对字符串",而是用语言回答语言。
训练需要超出大多数项目组能力范围的技巧、算力与时间 ,所以绝大多数 LLM 应用都会使用现成的通用基础模型(foundation models) ------它们已被训练(可能还做了少量微调;见旁注)。因此,我们并不指望你亲自训练一个 LLM------但如果你要用 LLM,尤其是要编程式 地使用它,理解它被训练来做什么就至关重要。
什么是微调(Fine-Tuning)?
训练 LLM 需要大量数据与算力,但许多基础"课程"(例如英语语法规则)在不同训练集之间差别不大。因此,训练 LLM 时常常不是从零开始 ,而是从另一种 LLM 的副本 起步------它可能在不同语料上训练过。
例如,OpenAI Codex (为 GitHub Copilot 开发的代码生成 LLM)的早期版本,就是在现有模型(GPT-3,面向自然语言的 LLM)基础上,使用大量发布于 GitHub 的源代码 进行微调 得到的。
如果一个模型先在数据集 A 上训练,再在数据集 B 上微调,那么通常你在编写提示时应当按它仿佛直接在 B 上训练来对待。我们将在第 7 章更深入地讨论微调。
LLM 使用一个称为训练集 的大型文档集合(依然是字符串)来训练。具体包含哪些文档取决于 LLM 的用途(示例见图 2-2)。训练集通常是多种来源的混合:书籍、文章、Reddit 等平台的对话、GitHub 上的代码等。模型应当学会 生成看起来就像训练集 的输出。具体而言:当模型收到的提示恰好是训练集中某个文档的开头 时,理想的补全应该是最可能 延续该原始文档的文本。换句话说,模型在模仿。
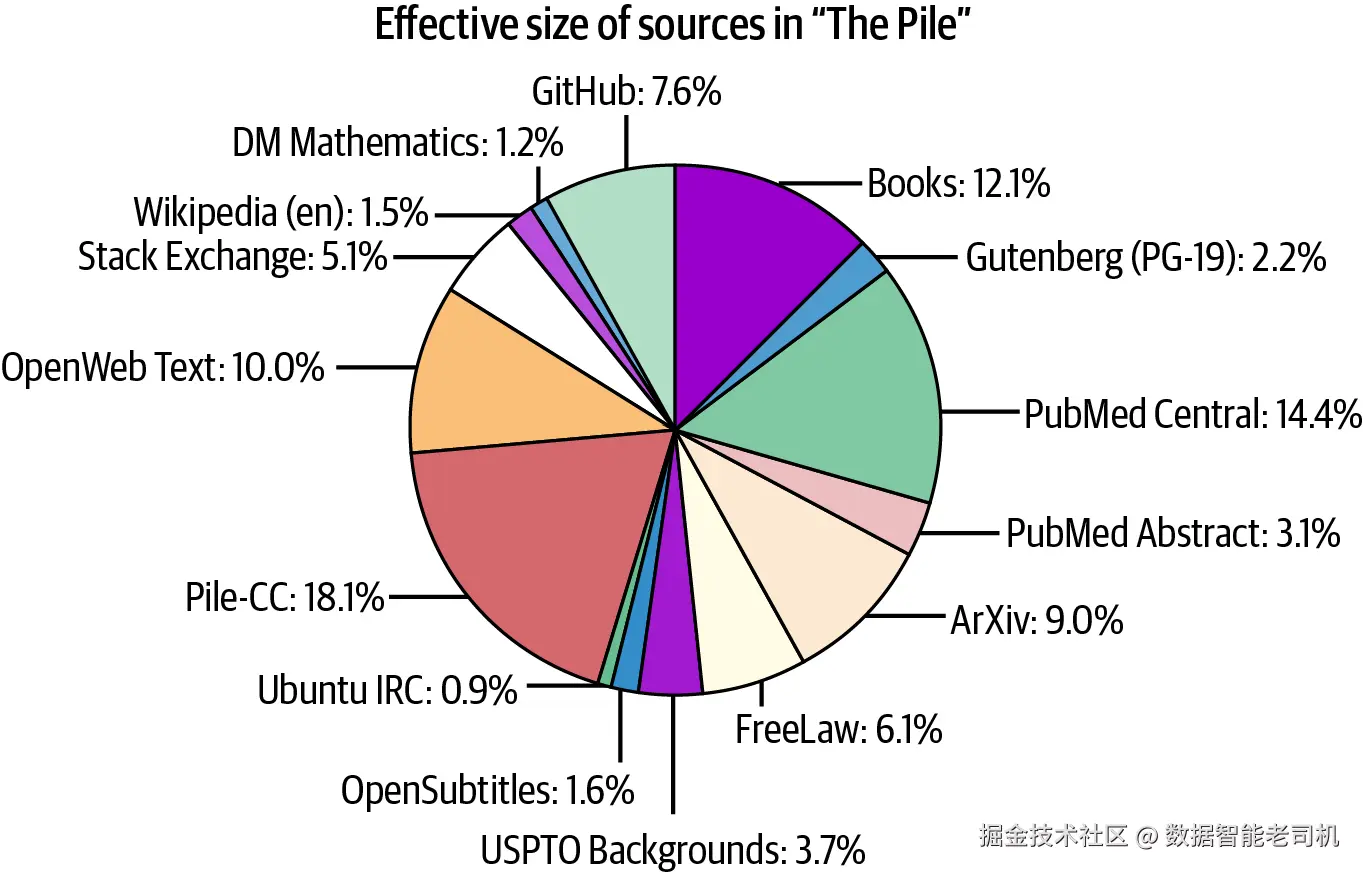
图 2-2. 开源训练集 The Pile 的组成:事实性散文、虚构性散文、对话及其他互联网内容的混合
那么,LLM 与"把训练数据做成的超大搜索引擎索引 "有何不同?毕竟,搜索引擎完全可以满分 完成 LLM 所受的那种训练任务------给定文档开头,它能以100% 准确率 找到该文档的后续。可我们要的绝不是只会鹦鹉学舌 训练集的搜索引擎:LLM 不应当"背诵训练集",而应当学习其中的模式 (尤其是逻辑与推理模式),以便完成任何提示 ,而不仅仅是训练集里的提示。机械记忆 被视为一种缺陷。LLM 的内部架构 (鼓励从具体样例中抽象)与训练流程 (尽量喂以多样且不重复的数据,并在未见数据上评估)都旨在避免这种缺陷。
这种"防止记忆"的机制有时会失效:模型没有学到事实与模式,反而死记硬背 了文本片段------这叫作过拟合 。在现成的商业模型中,大规模 过拟合应当是罕见 的;但仍需意识到:如果一个 LLM 看似很好地解决了它"在训练时见过"的问题,这并不意味着 它在面对相似但未见过的问题时也会表现同样出色。
尽管如此,与你的 LLM 相处一段时间后,你会逐渐形成一种直觉 :根据模型受训任务 来推测它的表现。因此,当你想知道某个提示可能得到怎样的补全时,不要问"一个理性的人会如何回复 ",而要问:"一篇以这个提示为开头 的文档 ,最可能 如何续写?"
提示
想象你从训练集中随机 抽取了一篇文档。你唯一已知的信息是:它以该提示开头。统计上最可能 的续写是什么?这就是你应当预期的 LLM 输出。
补全文档
下面是一个关于"文档补全"的推理示例。考虑以下文本:
Yesterday, my TV stopped working. Now, I can't turn it on at
对于以此开头的文本,以下哪种补全在统计上最可能?
y2ior3wThursday.all.
这三种补全都并非绝不可能 。有时猫咪踩到键盘会出现补全 1;有时句子在改写中被打乱,会出现 2。但最可能 的续写显然是 3,几乎所有 LLM 都会选择它。
继续把补全 3 接上并让 LLM 再向前跑一点:
Yesterday, my TV stopped working. Now, I can't turn it on at all.
对于这样开头的文本,接下来最可能的补全是哪一个?
a. This is why I chose to settle down with a book tonight.
b. Shall we watch the game at your place instead?
c. \n
d. \n
e. First, try unplugging the TV from the wall and plugging it back in.
这就取决于训练集 了。假设 LLM 主要在叙事性散文 (短篇小说、长篇、杂志、报纸)上训练,那么 a (今晚读书)比其他选项更像"常见续写"。至于 b 的问句,虽然可能出现在某个故事中段 ,但一个故事不会 从没有引号的问句开头 ,所以一个"短故事模型"不太会预测 b。
但如果训练集中再加入邮件与对话 的转录,b 就立刻显得非常合理 。不过这里我"诱导"了一下:真正由某个 LLM(OpenAI 的 text-davinci-003 ,GPT-3 的一个变体)生成的是 e ,它在模仿训练集中大量存在的建议/客服对话。
这里的主题渐渐清晰:你对训练数据 了解得越多,就越能对受该数据训练 的 LLM 输出形成更好的直觉。许多商用 LLM 并不公开它们的训练数据------选择 一个好的训练集本身就是模型成功的重要"秘方"。即便如此,通常仍能对训练集所含文档类型形成一些合理预期。
人类思维 vs. LLM 处理
LLM 会选择最像 正确答案的续写,而这与人类阅读文本时的一些假设相悖。原因在于:人类产出文本,并不只是为了生成看起来"像样"的输出。假设你想写一篇博客,介绍你在 Acast 播客网站上听到的一期节目。你可能会这样开头:
在他们最新一集《The rest is history》中,他们谈到了百年战争(可在 acast 收听: http:// ......当然,你并不熟记这个 URL,于是你会在此停笔去搜一下 。理想情况下,你找到了正确链接:shows.acast.com/the-rest-is-history-podcast/episodes/321-hundred-years-war-a-storm-of-swords。或者你没找到,这时你也许会把整段括号删掉,改成"(本期已不可收听)"。
模型不会 去 google,也不会 回头编辑,所以它只是猜 。¹ 原生的 LLM 也不会表达怀疑②、不会附上"刚才只是猜的"之类的免责声明,或给出任何它只是猜测 而非确知 的线索------因为归根结底,模型一直都在猜。③ 这一次恰好猜到了一个在人类写作流程中本应"切换模式"的地方(人会去搜索,而不是继续凭直觉敲字)。
LLM 非常擅长模仿 它在"要猜的东西"里见到的任何模式 。毕竟,这正是它被训练的目标。所以,如果它编造了一个社会安全号码,它会是一串看起来合理 的数字;如果它编了一个播客的 URL,它会看起来像播客的 URL。
在这个例子里,我用的是 OpenAI 的 text-curie-001(GPT-3 的一个小变体),它把 URL 补成了:
vbnet
http://www.acast.com/the-rest-is-history-episode-5-the-Hundred-Years-War- \
1411-1453-with-dr-martin-kemp)这里的 Dr. Martin Kemp 是真实人物吗?也许和历史播客有关?甚至就是我们谈到的这个播客?确实有一位牛津大学的艺术史学者叫 Martin Kemp ,不过把这次补全是否指向他,听起来更像是语言学理论 的问题而不是 LLM 问题(见图 2-3)。无论如何,他并没有在 The Rest Is History 这档节目里谈百年战争。
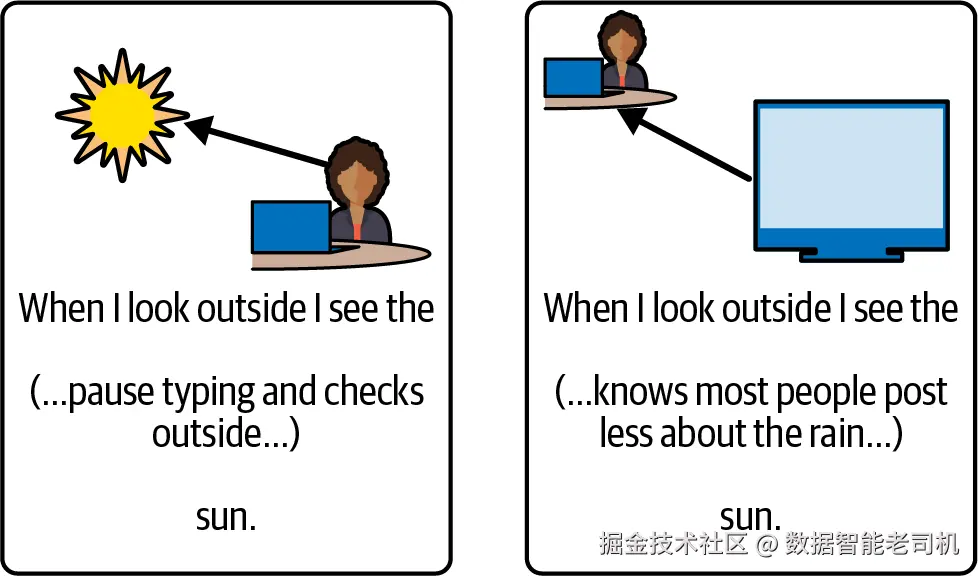
图 2-3. 人们的语言反映现实 ;模型的语言反映人们
幻觉(Hallucinations)
由于 LLM 被训练成"训练数据的模仿机 ",会带来一个不幸后果:幻觉 ④------即模型自信地产生貌似合理 、但事实错误的信息。无论临时使用还是嵌入应用中,这都是常见问题。
从模型视角看,幻觉与其它补全并无二致 ,因此像"不要瞎编 "这样的提示指令作用非常有限 。典型做法是让模型给出可核验的背景 :例如推理过程 ⑤、可独立执行的计算 、来源链接 ,或可被检索的关键词和细节 。比如,要核查"有一位英国国王娶了他表妹 "这句话很难;但"有一位英国国王娶了他表妹------即 George IV,娶了 Caroline of Brunswick "就容易多了。对付幻觉的最佳法则是: "信任但要验证",甚至可以不必"信任" 。
幻觉也可以被诱发 。如果你的提示提到了并不存在 的事物,LLM 通常会继续假定其存在 。先说错再在中途自我纠正的文档很少见,所以模型通常会默认提示为真 ,这被称为真值偏置(truth bias) 。
你也可以让"真值偏置"为你所用------如果你想让模型评估一个假设/反事实 情形,并不需要说"假装现在是 2030 年,尼安德特人已经被复活 "。直接写"现在是 2031 年,第一批尼安德特人复活已满一年"即可。
提示
如果你能访问一个直接产出补全 的 LLM(即没有被 ChatGPT 之类聊天界面封装的"原生 LLM"),这是尝试输入若干所谓 make-believe prompts ("假设成真"型提示)的好时机。
像前文"复活尼安德特人"的例子,这类提示不是直接问"如果......怎么办",而是暗示 该假设场景已经发生 。
把这种做法与聊天式 LLM 的回答对比一下------有什么不同?
不过,LLM 的真值偏置也很危险 ,尤其对编程式 应用而言。在程序化构造提示 时,太容易引入反事实 或荒谬 元素。人类读到这段提示,可能会停下来、挑眉质问:"真这样? " LLM 没这个选项。它会尽力配合 把提示当真,很少 会纠正你。因此,你有责任提供不需要纠正的提示。
LLM 如何"看见"世界
在《什么是 LLM?》里你已经了解到,LLM 消费与生成的都是字符串。这里值得"掀开引擎盖"再看一眼:LLM 是如何"看见"字符串的?我们习惯把字符串当作字符序列 来思考,但这并非 LLM 看到的样子。LLM 可以 围绕字符进行推理,但那并不是它的原生能力 ,需要它投入相当多的"注意力"。截至本文写作时(2024 年秋),即使是最先进的模型仍可能被诸如" 'strawberry' 里有几个 R? "这类问题糊弄到。
或许也该指出,人类其实也不 是逐字符地读字符串。在大脑处理的非常早期阶段,字符就被分组成词 了;我们真正阅读的是词,而不是字母。这也是为什么我们常常读过了拼写错误却没察觉------当文本抵达意识层面时,我们的大脑已把它"自动校正"过一遍。
你可以用刻意"搅乱"的句子来做很多有趣的实验------只要它们还在你内心"自动纠错"的可承受边缘上(见图 2-4 左)。然而,如果你以不尊重词边界的方式去打乱文本,你的读者这一天就基本"报废"了(见图 2-4 右)。

图 2-4. 打乱同一段文本的两种方式
左图保持词边界 不变,仅在词内 打乱字母顺序;右图保持字母顺序 不变,却改变了词边界。大多数人觉得左侧明显更容易读。
和人类相似,LLM 也不 逐字母阅读。当你把文本发给模型时,它会先被拆分成一连串多字母片段 ,称为 token 。它们通常长 3--4 个字符 ,但对常见单词或字母序列也会有更长的 token。某个模型所使用的 token 集合称为它的词表(vocabulary) 。
在读取文本时,模型首先通过一个分词器(tokenizer)把文本变为 token 序列,然后才交给 LLM 本体处理;接着 LLM 生成一串 token(内部以数字表示),最后在返回给你前再把它们翻译回文本(见图 2-5)。
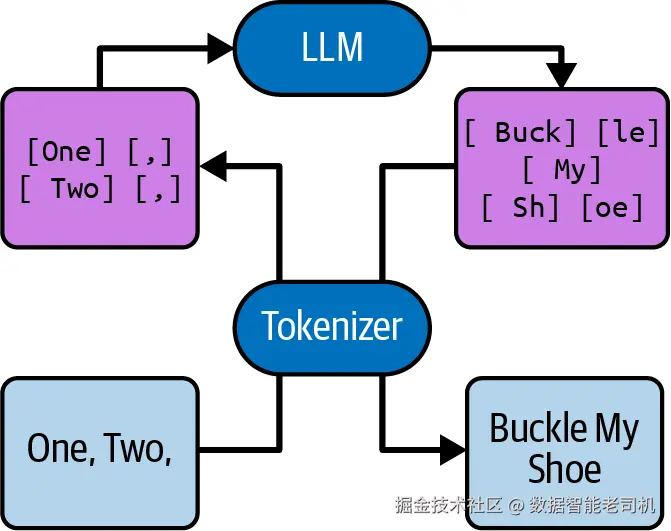
图 2-5. 分词器把文本翻译为 LLM 处理的数字序列------以及把它翻译回来
注意,并非所有分词器都会包含以空白开头的复合 token,但很多会------OpenAI 的分词器就是显著例子。
LLM 把文本看成由 token 构成;人类把文本看成由 词构成。听起来两者很相似,但这里有几个关键差异。
差异 1:LLM 使用确定性分词器
对人类来说,把字母翻译成词是模糊 的:我们会尝试在看到的字母序列里找"最像"的词。相反,LLM 使用确定性的分词器 ------这会让拼写错误格外显眼 。例如,在 OpenAI 的 GPT 分词器里(被广泛采用,不止用于 OpenAI 模型),"ghost " 是单个 token ;而错拼的 "gohst " 会被切成 g -- oh -- st 三个 token------显然不同,因此模型容易察觉错拼。尽管如此,LLM 通常对错拼相当有韧性,因为它们在训练集中见多了。
差异 2:LLM 不能"放慢速度逐字检查"
人类可以放慢速度、有意识地逐个字母检查;LLM 只能用它内置 的分词器(而且也不能"放慢")。很多 LLM 会从训练集中学习 某个 token 由哪些字母构成,但凡是需要模型拆解/重组 token 的句法任务都会更难。
图 2-6 展示了一个关于"把词的字母反转 "的 ChatGPT 对话案例。按理说,反转字母是个简单的模式操作,LLM 通常很擅长。但由于需要拆分再重组 token,对模型来说就过于困难,于是无论反转还是"再反转回去"都严重出错。
在图中,初次反转与反转回去都错漏百出。对你这个应用构建者而言,启示是:尽量避免 让模型完成涉及子 token 级的任务。
提示
如果你要让 LLM 执行的任务里,有一部分需要拆 token 再组回去 ,考虑把这部分逻辑放在前处理/后处理里完成。

图 2-6. ChatGPT 尝试并失败于"反转字母"
举个利用上面"提示"的例子:假设你的应用在玩类似 Scattergories 的游戏,目标是寻找满足句法属性 的词条,比如"以 W 开头的禁酒运动人士 ""以 Sw 开头的欧洲国家 "或"名字里含 3 个字母 R 的水果 "。那么一个可行策略是:先把 LLM 当作知识神谕 去拿到一长串"禁酒人士/欧洲国家"的列表,再用你的句法逻辑 把列表过滤 掉不符合的项。如果你把全部负担都压给 LLM,就可能遇到失败(见图 2-7)。
注意,图中的模型非确定性 ,而且在两次尝试 里以两种不同方式 失败。另请注意, Sweden、 Switzerland、 Somalia 在 ChatGPT 的分词器里都是单个 token。

图 2-7. ChatGPT 难以识别以 "Sw" 开头的国家
差异 3:LLM "看文本"的方式不同
最后一个差异:我们人类对 token 与字母的许多方面有直觉式理解 。尤其是我们看见 它们,因此知道哪些字母是圆的、哪些是方的;我们能理解 ASCII 艺术 ,因为我们能看到它(尽管很多模型也在训练中背了不少 ASCII 艺术)。对我们来说,带重音符的字母只是这个字母的一个变体 ,阅读"重音满天飞"的文本并不太困难 。而对模型而言,即便它勉力做到了 ,也要消耗相当多 的处理能力,从而挤占你真正关心任务的算力预算。
一个特别的情形是大小写 。看看图 2-8。为什么这件看似简单的事会做得这么差(呃......goed ......我是说 gone )?请在继续阅读前,带着分词陷阱的视角先自己猜一猜。
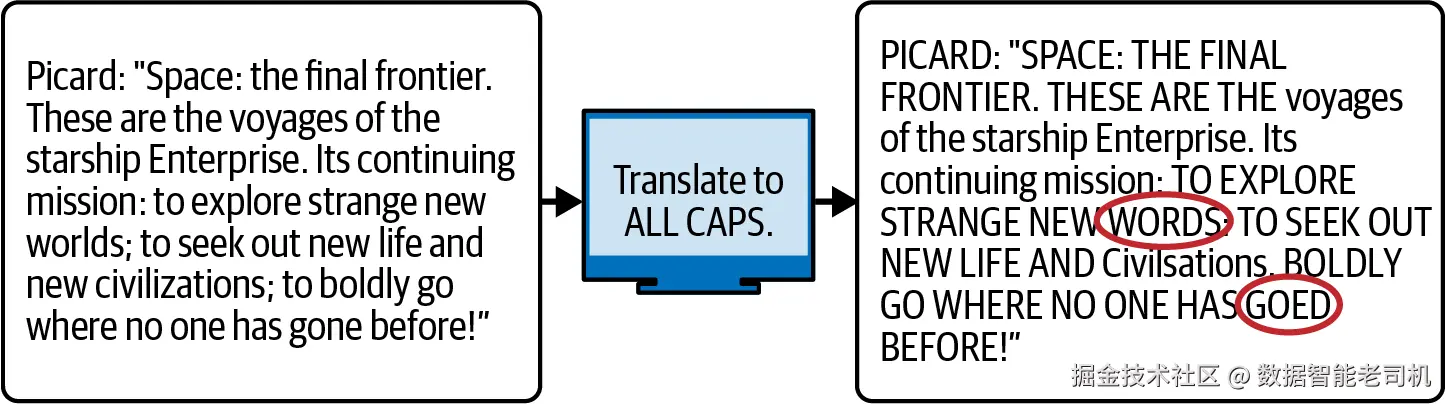
图 2-8. 让 OpenAI 的 text-babbage-001 把文本转成全大写
这会产生一些典型又好笑的错误------示例里我们用的是很小的模型;更大的模型通常不至于这么容易"跌坑"。
对人类而言,A 与 a 不过是同一字母的两种形态 ;但在分词里,含有大写字母的 token 与含有小写字母的 token 非常不同 。模型对此心知肚明 ,因为训练数据里到处都是类似现象:它们知道句号后的 For 与句中间的 for 很相近。
然而,大多数分词器并不利于 模型学习这些联结,因为大写化 后的 token 并不总能与小写 的 token 一一对应 。例如,GPT 分词器把 "strange new worlds " 切成 strange new worlds (4 个 token);但全大写后变成 STRANGE NEW WORLDS (6 个 token)。同理,"gone " 是一个 token,而 GONE 是两个。
更强的 LLM 在处理大小写方面更稳健 ,但这依然会分散 它们处理你真正任务 (很可能与大小写无关)的精力。(说到底,你并不需要 LLM 来做大小写转换 !)因此,聪明的提示工程师 会尽量避免让模型频繁在大小写之间来回转换,把这类工作留给前后处理更合适。
统计 Token(Counting Tokens)
你不能把分词器(tokenizer)和模型 随意混搭。每个模型都使用固定 的分词器------因此,了解你所用模型的分词器非常值得。
在编写 LLM 应用时,你很可能希望在进行提示工程时就能直接运行分词器 (例如用 Hugging Face 或 tiktoken 之类的库)。不过,分词器最常见的用途并不是做复杂的 token 边界分析,而是更"平凡"的一件事:计数。
这是因为,从模型视角看,token 数量 决定了你的文本有多"长"。这涵盖了关于长度的所有方面:模型阅读提示 所花的时间与提示中的 token 数近似线性 相关;模型生成答案 所花的时间与产出的 token 数 近似线性相关。计算成本 也一样:一次预测需要的算力与序列长度相关。因此,大多数"模型即服务"的计费方式都是按处理/生成的 token 数 来收费。写作本文时,花 1 美元通常可以买到5 万到 100 万个输出 token(视模型而定)。
最后,token 数还决定了**上下文窗口(context window)**的问题------也就是 LLM 在任意时刻能处理的文本总量。这是所有现代 LLM 的一个限制,我们会在全书反复提到它。
LLM 并非"来者不拒,任意长短"。它要求输入 的 token 数小于 上下文窗口大小,而且其补全结果 也必须满足"提示 + 补全 的 token 总数不超过上下文窗口"的约束。上下文窗口大小通常以几千到几十万 个 token 计。理论上这已不少------折合 A4 页面可达数页、数十页,甚至上百页 。但在实践中你往往还是会"用爆 "它:窗口再大也有填满甚至溢出的冲动,所以你需要数 token来防止这种情况。
没有一个通用公式 能把字符数 换算成token 数 。它取决于文本内容 和分词器 。非常常见的 GPT 分词器在处理英文自然语言时,平均大约每个 token ≈ 4 个字符 。这相当典型,尽管一些较新的分词器会稍微更高效 (即平均每个 token 对应更多字符)。
多数分词器都对英语 做了优化,⁶ 对其他语言往往效率较低 ,也就是每个 token 包含的字符更少 。随机数字串更低效,平均每个 token 仅略高于 2 个字符 。随机字母数字串(如加密密钥 )更糟,通常不足 2 个字符/token 。包含稀有字符 的字符串最为低效------例如 Unicode 的笑脸 ☺ 实际上会被切成两个 token。
注
大多数 LLM 的词表里至少包含几个特殊 token :最常见的是文本结束 token 。训练时会在每个训练文档末尾附上它,让模型学会"何时结束"。一旦模型输出了该 token,补全就会在那一刻被截断。
一次一个 Token(One Token at a Time)
让我们把"洋葱"再剥一层------在抵达核心之前的最后一层。引擎盖下,LLM 并不是直接"文本 → 文本 ",也不是严格意义上的"tokens → tokens "。而是"多 tokens → 单个 token "的循环:模型不断重复"获取下一个 token "的操作,并把一个个 token 累加起来,直到形成完整文本。
自回归模型(Auto-Regressive Models)
对 LLM 进行一次前向 就会给出统计上最可能的下一个 token 。⁷ 然后,把这个 token 接 到提示末尾,LLM 再跑一遍 ,在新的提示条件下给出下一个最可能的 token ,⁸ 如此往复(见图 2-9)。这种一次一个 token 、并且下一步依赖上一步 的过程称为自回归(autoregressive) 。
就像你在手机上打字,键盘上方会出现三连词 建议;运行 LLM 就像反复按中间那个键。
这种规律而几近单调 的"一步一 token"模式,凸显了 LLM 生成文本与人类打字的一个重大差异:我们写作时会停下来检查、思考或反省 ;而模型每一步都得产出一个 token 。LLM 不会 因为"需要多想一会儿"就获得额外时间 ,⁹ 也不能停滞。
图 2-9. LLM 以"一次一个 token"的方式生成回应
一旦输出了一个 token,LLM 就被它束缚住 了:它不能回退 把该 token 擦掉;它也不会 像人那样在文中"声明更正"之前输出的不当内容,因为训练语料里几乎没有 这类"在成稿里当场反悔"的写法------毕竟人类作者可以在出错处 直接回退并修正 ,所以"原地撤回"的成文样式极为稀少。哦对了,严格说起来,takebacks 更常写成两个词,那我应该写 take backs 才对。
这一特性会让 LLM 看起来固执 甚至有点滑稽 :它会沿着明显不通的路径越走越远。但真正的含义是:当需要识别错误与回退时,这类能力需要由**应用设计者(你)**来提供与编排。
模式与重复(Patterns and Repetitions)
自回归系统的另一类问题是:它们可能陷入自己制造的模式 里。LLM 很擅长识别模式,因此有时(纯属偶然)会生成一个模式 并找不到合适的"退出点"。毕竟,一旦形成模式,在任意一个 token 处,"延续 模式"的概率往往高于"打破 模式"。这会带来高度重复的输出(见图 2-10)。

图 2-10. 由 OpenAI 的 text-curie-001 模型产出的"喜欢某部电视剧的理由"清单(为演示选择的较旧模型;较新的模型通常不太会如此尴尬地掉进重复陷阱)
在图中,LLM 给出了一份喜欢一部电视剧的理由清单。你能发现多少种模式?下面是我们发现的:
- 条目是连续编号 的陈述,每条占一行。这看起来是可取的。
- 它们都以 "The" 开头,这也还可以接受。
- 它们大多呈"X is Y and Z "的形式。这让人烦,因为会危及正确性 :如果不存在合适的 Z ,模型可能会编一个。不过,它在第 5 条之后就停用了这种结构。
- 在连续几条都以 "The franchise" 开头之后,后面的全都 这么写了。这很蠢。
- 到了结尾附近,legacy、following、future、foundation、fanbase 被反复 出现,让人厌烦。这也很蠢。
- 清单没完没了 、从不停下。这是因为在每一条之后,"继续 列表"的概率比"这就是最后一条 "更大。而模型不会觉得无聊。
- 到了结尾附近,legacy、following、future、foundation、fanbase 被反复出现,让人厌烦。这也很蠢。
- 清单没完没了、从不停下。这是因为在每一条之后,"继续列表"的概率比"这就是最后一条"更大。而模型不会觉得无聊。¹⁰
处理这类重复性 输出的办法,通常就是检测并过滤 。另一种做法是对输出进行一定的随机化 。我们将在下一节讨论输出的随机化。
温度与概率(Temperature and Probabilities)
在上一节中,你了解到 LLM 会计算最可能 的下一个 token。可如果把这颗"洋葱"再剥一层,你会发现:实际上,模型在选择某一个 token 之前,会先为所有可能的 token 计算概率 。在引擎盖下负责选出实际 token 的过程称为采样(sampling) (见图 2-11)。
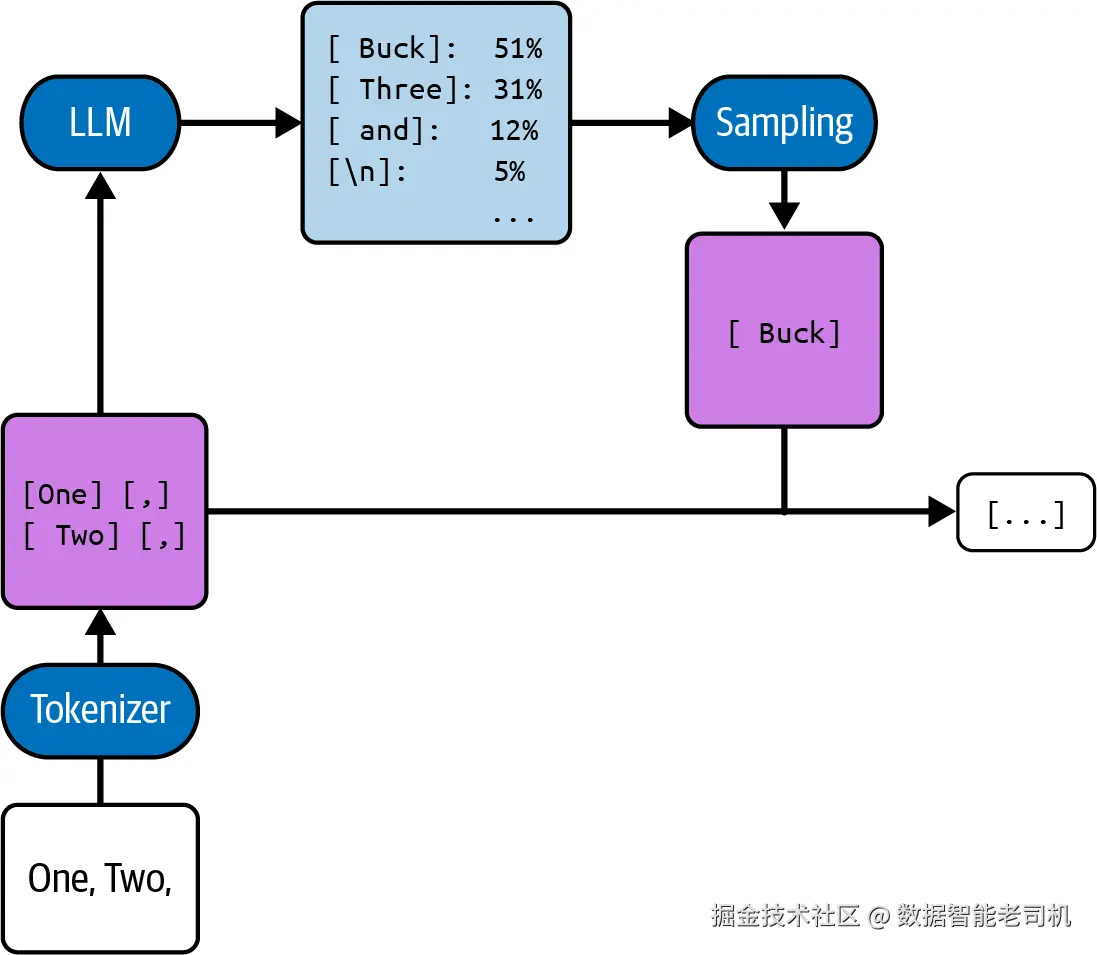
图 2-11. 采样过程示意
注意:LLM 不只是计算"最可能的那个 token",而是计算所有 token 的可能性。
许多模型会把这些概率返回给你 。模型通常以 logprobs 的形式返回(即 token 概率的自然对数)。logprob 越高 ,模型就越认为该 token 更可能 。logprob 从不大于 0 ;logprob = 0 意味着模型确信 这就是下一个 token。最可能的 token 的 logprob 常见地介于 --2 到 0 之间(见图 2-12)。
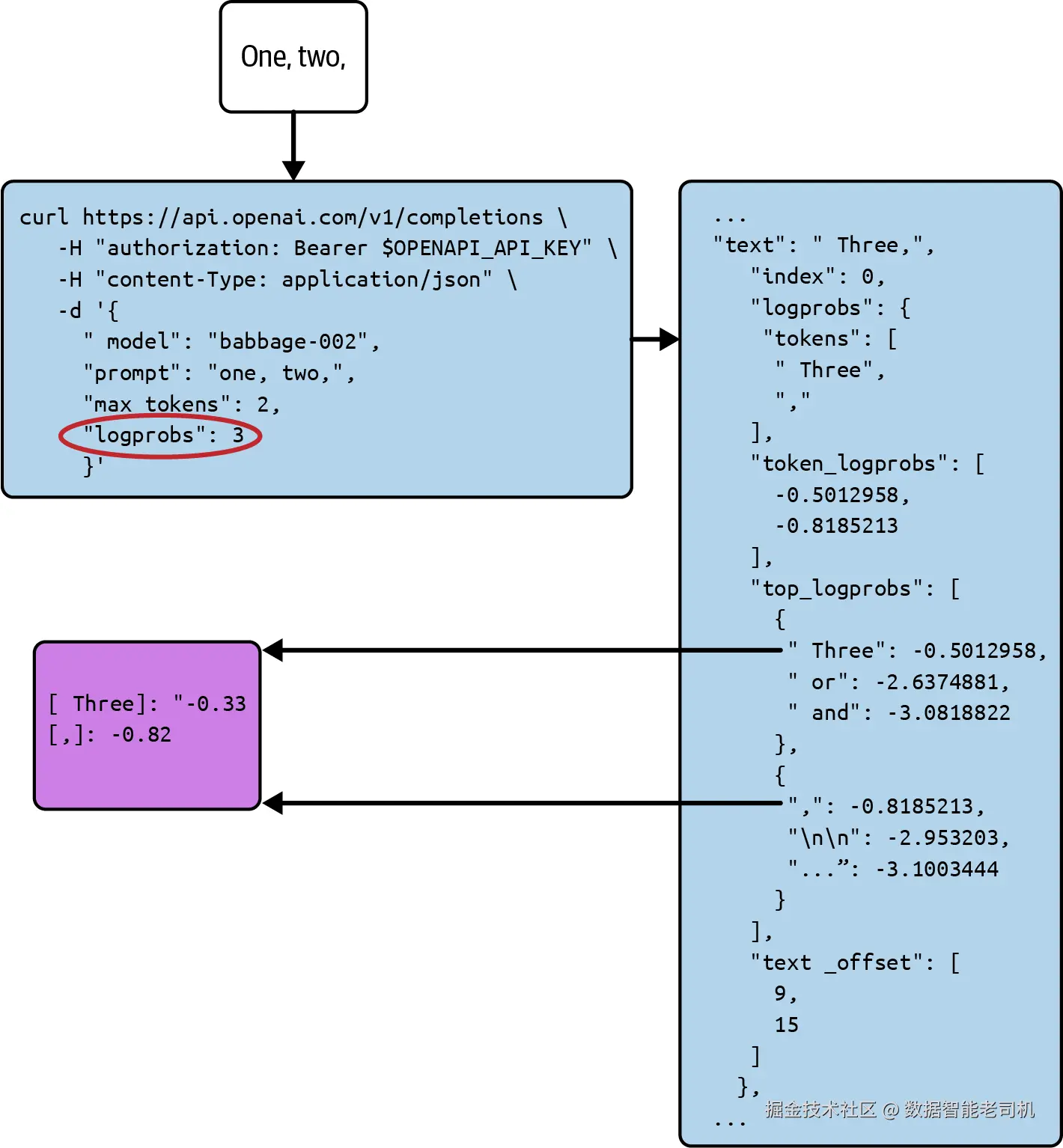
图 2-12. 一个请求 logprobs 的 API 调用示例,并从中取出所选补全的 logprobs
说明:图中将请求参数 logprobs 设为 3,表示会返回前三个最可能 token 的 logprobs。
不过,你未必总是 想要最可能的 token。尤其当你能自动测试 补全质量时,可能希望生成多个备选 ,再把差的丢掉。典型做法 是把温度(temperature)设为 > 0 。温度是一个不小于 0 的数,决定模型应该有多"有创意"。更具体地说,当温度 > 0 时,模型会给出随机性 的补全:通常仍倾向于选择最可能的 token,但也会偶尔选取 一些概率较低 但不至于离谱的 token。温度越高,且若前几名 token 的 logprob 彼此越接近,就越有可能选中次优 甚至第 3、4、5 名的 token。其精确公式如下:
p(tokeni)=∑jexp(logprobj/t)exp(logprobi/t)
下面看看不同温度的适用场景:
0
你要最可能 的 token,不要 替代项。当正确性最重要 时推荐使用。另外,温度设为 0 的 LLM 近似确定性,¹¹ 在某些应用中,可重复性是优势。
0.1--0.4
若存在"与第一名只差一点点"的候选,你希望有小概率 选中它。常见用法:你想生成少量 不同解(例如你知道如何筛选 出最优的那一个);或你只要单个补全 ,但希望它比温度 0 时更生动/更有变化。
0.5--0.7
你希望随机性影响更大 ,并且可以接受 有时会选中"模型本以为不如另一候选"的 token。常见用法:你需要大量相互独立 的备选(通常 10 个以上)。
1
你希望 token 的分布贴合训练集 的统计分布。比如前缀是 "One, Two,",在训练集中它有 51% 的概率跟着 token Buck 、31% 的概率跟着 Three (且模型已学到这一点)。若在温度 1 下多次运行模型,那么约 51% 的次数会得到 Buck ,约 31% 的次数会得到 Three 。
> 1
你希望文本比训练集更随机 。这意味着模型更不容易 选择"标准续写",而更容易 选择"特别奇怪的续写"。
高温度会让 LLM 听起来像是喝醉了 。在温度 > 1 的长篇生成 中,错误率通常会随时间上升 。原因是温度只影响最后一层 把概率变成输出的步骤,并不改变 模型前面用于计算这些概率 的主体处理。因此,模型会把刚生成的错误 当作一种模式 来模仿,于是它会继续造错 ;而较高温度又会叠加更多错误(见图 2-13)。

图 2-13. 高温对 LLM 的影响有点像酒精对人的影响
图中展示了在高温度 下的退化:第 3 项的生成从"可读但易错"一路走到"连词都难辨"。注意:图中各项是用 OpenAI text-davinci-003 在逐步升高温度下采样得到的。
回到"模型写清单"的例子。典型文本里的清单常在 3、4、5 项处收尾;若更长,10 往往是下一个明显的停点 。每写完一行,它要么继续 列表(把下一个数字作为下一个 token 产出),要么宣告结束(比如再产出一个换行,或别的 token)。
- 在温度 0 下,LLM 总会选择它认为更可能 的那个选项。通常意味着它会一直往下写,至少在越过"最后一个明显停点"后如此。
- 在温度 1 下,若 LLM 判断"继续"的概率是 x ,那么它就以 x 的概率 继续。因此在很多行之后,它大概率会在某处停下 ,且期望长度 接近训练集中列表的典型长度。
总体而言,这是一个权衡(见表 2-1)。
表 2-1. 不同温度区间的优缺点
| 高温度 | 低温度 |
|---|---|
| + 备选更多。 | + 正确解更多。 |
| + 许多生成属性(如列表长度)与训练集分布相似。 | + 更可复现(更接近确定性)。 |
此外,还有其他采样方式,最著名的是束搜索(beam search) 。它试图考虑这样一种事实:选择一个"看似很可能"的 token,可能会让下一步 没有好的承接 token。束搜索通过向前看若干步 、确保存在可能的后续序列 来缓解这一点。这通常能带来更准确 的结果,但由于时间与算力成本更高 ,在工程应用中使用得不那么频繁。
Transformer 架构(The Transformer Architecture)
现在是掀开"洋葱"的最后一层,直面 LLM "大脑"的时候了。你剥开一看......这根本不止一个大脑,而是成千上万 个小脑袋(minibrains) 。它们在结构上彼此完全相同 ,各自执行非常相似 的任务。序列中的每个 token 之上 都坐着一个小脑袋,这些小脑袋共同组成了Transformer------所有现代 LLM 所采用的架构。
每个小脑袋一开始都会被告知自己所对应的 token 以及它在文档中的位置 。这个小脑袋会在一个固定步数内"思考"(这些步称为层 layers )。在此期间,它可以接收来自左侧小脑袋 的信息。它的任务是从自己的位置去理解整篇文档,并将这种理解用于两种方式:
- 在最后一步之前的所有步骤 里,它会把自己的中间结果 的一部分分享给右侧的小脑袋。(稍后我们会详细讨论。)
- 在最后一步 ,它被要求预测它右边紧邻的那个 token会是什么。
每个小脑袋都经历相同的流程:计算并共享中间结果 ,然后做出一次猜测 。事实上,这些小脑袋彼此是克隆 :处理逻辑一致,唯一不同的是输入 ------它们各自起始于哪个 token、以及左边的小脑袋告诉了它哪些中间结果。
但它们进行这些步骤的目的 并不相同:最右边最后一个 token 上的小脑袋负责预测"下一个 token" 。它分享出的中间结果并不重要,因为右边没有脑袋 可听;而其他 小脑袋则正好相反:它们的目的在于把中间结果分享给右边 的小脑袋,它们对"自己右侧那个已知 token"的预测并不重要,因为那一个已经是已知的。
当最右侧的 token 做出预测后,上一节《一次一个 Token》的自回归 过程就启动了:模型"吐出"一个新 token,并在它上方安放一个全新的小脑袋 ,让它在固定层数内,围绕自己位置的上下文继续细化理解;之后,它再预测下一个 token。反复进行 ------更准确地说是缓存并反复 ,因为这一计算会在后续处理提示与生成补全时一再复用。
这个算法的一个示例如图 2-14 所示,每一列 代表一个小脑袋及其随时间变化 的状态。在例子中,你让模型补全"One, Two, ",最终会得到两个 token: Buck 与 le 。我们来跟随 Transformer 如何到达这个回答:在四个输入 token One、,、Two、, 上各坐着一个小脑袋(最后一个逗号是该 token 的第二次出现 )。它们各自思考四层 ¹²,逐步细化对文本的理解;在每一步,它们都会从左侧 的 token 获得"到目前为止学到什么"的更新 ;并各自计算"右边 那个 token 可能是什么"的猜测。
前几次猜测针对的仍是提示(prompt)里的 token: One、,、Two、, 。我们已经知道提示了,所以这些猜测被丢弃 。随后模型来到补全(completion)区,此时猜测 就成为核心 :下一个猜测被转为预测 ,即 token Buck 。一个新的小脑袋被安放到它上方,走完四步,给出预测 le 。如果你继续生成补全,将在 le 之上再安放新的小脑袋,依此类推。
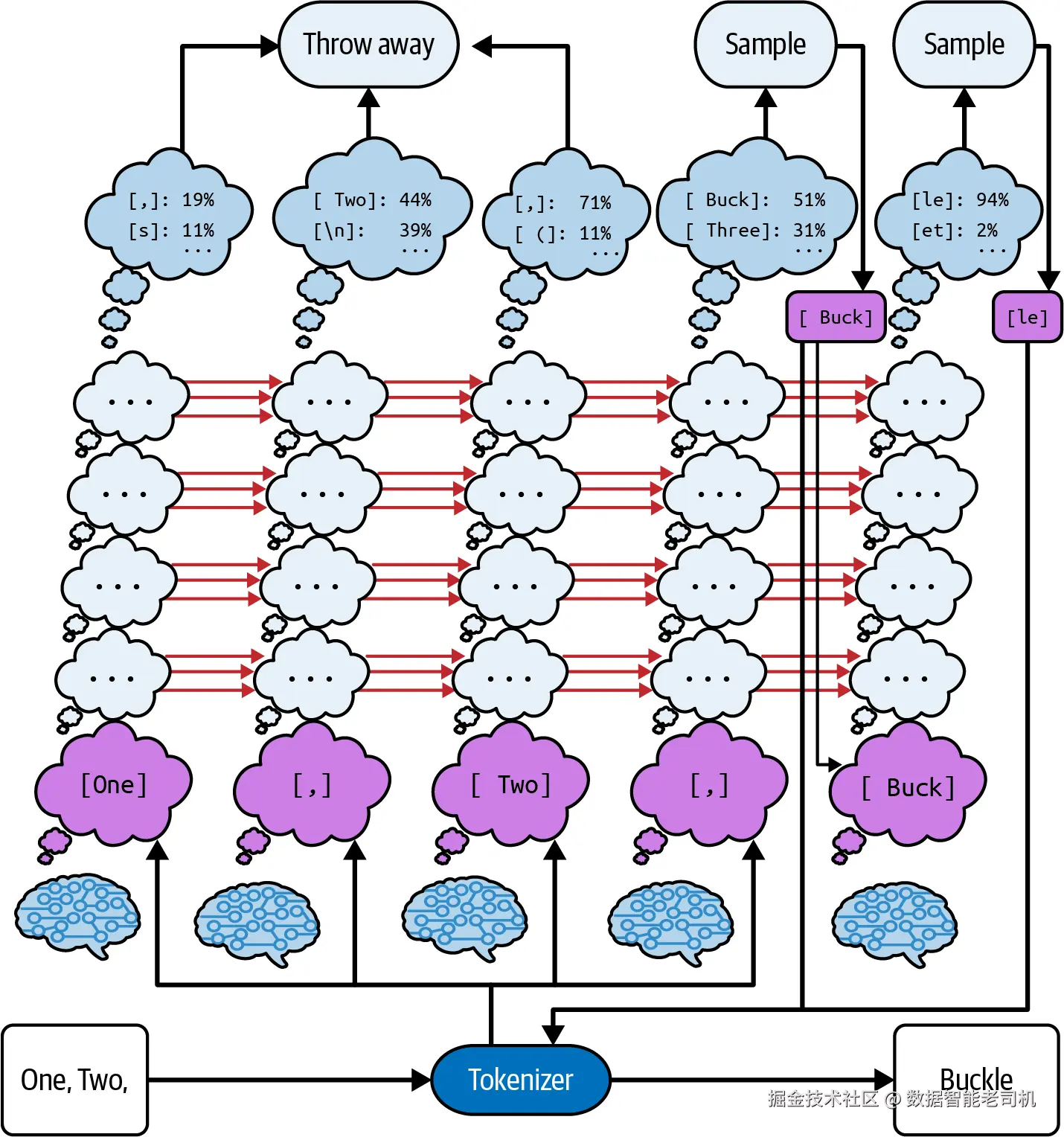
图 2-14. 模型内部为生成一个 token 所做的工作------较后的层叠画在较前层之上
现在回到这些中间结果 的共享。它们的共享方式称为注意力机制(attention) ------这是 Transformer 在 LLM 中的核心创新 (第 1 章已经提到)。注意力是一种在小脑袋之间传递信息 的方式。显然,可能存在成千上万 个小脑袋,每一个都可能掌握着对其他所有 小脑袋有用的信息。为了避免信息交换陷入混乱,必须严格约束。其工作方式如下:
- 每个小脑袋都有想知道的事 ,因此它会提交若干"问题(queries) ",希望能被别的小脑袋回答。比如,一个小脑袋坐在 token my 上,它想知道"我 "指的是谁,于是合理的问题就是:"谁在说话? "
- 每个小脑袋也有可以分享的事 ,因此它会提交若干"可供(keys/values) "信息,希望能对其他小脑袋有用。比如,一个小脑袋坐在 token Susan 上,此前它已经学到该 token 处于一句自我介绍的末尾 ("Hello, I'm Susan.")。于是,为了帮助后续小脑袋,它会提交一条信息:"当前说话的人是 Susan。 "
- 之后,每个"问题"会与最匹配的答案 进行配对 。"谁在说话? "就会与"当前说话的人是 Susan"很好地匹配。
- 每个问题的最佳答案 会被告知 给提出问题的小脑袋。于是,位于 my 的小脑袋会被告知:"当前说话的人是 Susan "。当然,虽然在这个例子里我们让小脑袋们似乎用英语交流,但在现实中它们使用的是由长向量 ¹³构成的"语言",而且这种"语言"对每个 LLM 都是独一无二的------因为它是在训练过程中由模型"自发发明"的。
注
- 信息只会 从左向右流动。
- 信息只会 从下向上流动。
在现代 LLM 中,这种问答机制还遵循一个约束,称为掩码(masking) :不是所有 小脑袋都能回答问题;只有 提问者左侧 的小脑袋可以回答。而且,一个小脑袋不会被告知 自己的答案有没有被采用,因此右侧 的大脑无法影响左侧的大脑。¹⁴
这种信息流带来一些工程上的后果 。例如,要计算某个小脑袋在某一层的状态,模型只需要 该层中它左侧 小脑袋的状态,以及它自己 在更低层 的状态。这意味着某些计算可以并行 ------这也是生成式 Transformer 训练效率高 的原因之一。任意时刻,已完成计算的阶段形成一个三角形(见图 2-15)。

图 2-15. 计算 LLM 内部状态
图中:首先(左上)只能计算第一个 token 的最底层 ;接着(上中)可以计算第一个 token 的次底层 与第二个 token 的最底层 ;再下一步(右上)可计算第一个 token 的第三层 、第二个 token 的第二层 、第三个 token 的第一层 ......直到所有状态计算完毕,便可采样出一个新 token。
并行带来提速,但当模型从读取提示 切换到生成补全 时,三角形的计算方式会失效 :模型必须等某个 token 完整处理完 ,才能选择下一个 token 并计算新小脑袋的第一层 。这就是为什么 LLM 在阅读长提示 时通常比生成长补全 快得多。速度同时取决于处理的 token 数 与生成的 token 数 ,但提示 token 的处理通常快一个数量级。
这个三角形结构反映了 LLM 一个总体的"向后且向下 (backward-and-downward)"的"视野方向",或者打个趣称为"向后且向笨(backward-and-dumbward)":
- 向后(Backward)
小脑袋只能 看左侧 ;它们可以回看得很远,但绝不 能向前看。这就是人们把 GPT 等称为单向 Transformer(unidirectional transformer)的含义。信息不会 从右向左流动。这使得生成式 Transformer 易于训练与运行 ,但也对它们的信息处理方式有重大影响。 - 向下("向笨" Dumbward)
在同一层里,小脑袋只会从更靠左 的小脑袋获得答案,这意味着在第 i 层里,任何"推理链 "最多也只能有 i 步(如果我们把"每层的小脑袋思考一次"视作一步)。小脑袋无法 把更高层 得到的洞见传回 更低层继续加工。唯一的例外是:当 LLM 在生成文本时,最高层 的结果------也就是token ------被产出,它将成为下一个小脑袋第一层 的起点 。这种"一边说一边想 "是模型让信息从高层流向低层 的唯一途径 ------就像把想法在脑子里"搅一搅"。这颇让人想起一句俗语:"我得先把话说出口,才知道自己在想什么 。"这一原则正是链式思维(chain-of-thought)提示的基础(见第 8 章)。
举个例子:上一段 到底有多少个单词 ?如果你跟我一样,你也许懒得数 ,希望作者直接告诉你。好吧------是 173 个。当然,从理论上讲,你也可以自己往上翻去数,对吧?
我们把本章内容(直到包含"上一段有多少个词?"这道题)喂给 ChatGPT,问它同样的问题。它回答:"上一段包含 348 个词。 "不仅错,而且离谱:对那一段来说远远过多,对整篇文本来说又远远不够。
当然,我们对 LLM 的要求在这里极高 。人类会做得更好。¹⁵ 人可以再读一遍 并在心里维持一个计数器 。这对 LLM 行不通,因为它只读一遍 且不能回看 。所以,当小脑袋们唯一一次处理那一段时,它们还不知道 "词数 "是关键特征,因为这个请求出现在正文之后 。它们正忙着考虑语义、语气风格与各种表层特征,并不会把全部注意力放在那个最终会重要的点上。
这就是为什么提示的顺序 对提示工程至关重要------它常常决定成败 。确实,当我把"数词数"的问题放在开头 来问......好吧,ChatGPT 仍然没算对 (因为"计数"对 LLM 确实困难),但它靠近得多 ,声称是 173 。在第 6 章,我们会回到"如何组织提示各部分的顺序"这一主题。
提示
如果你想判断某项能力是否现实可行 让 LLM 处理,请自问:
一个把相关常识都"烂熟于心"的人类专家,能否在 一次性书写中 不回退、不编辑、不做笔记** 地 完成这段提示 ?
结论
本章我们讨论了四个核心事实。第一,LLM 是文档补全引擎 。第二,它们会模仿 训练中见过的文档。第三,LLM 一次只生成一个 token ,无法暂停或回退修改先前的 token。最后,LLM 自始至终只通读一遍 文本。下一章我们将看看,这些事实如何转化为一套通用的提示工程范式。