具身机器人VLA算法入门及实战(四):具身智能VLA技术行业进展
一、 理想
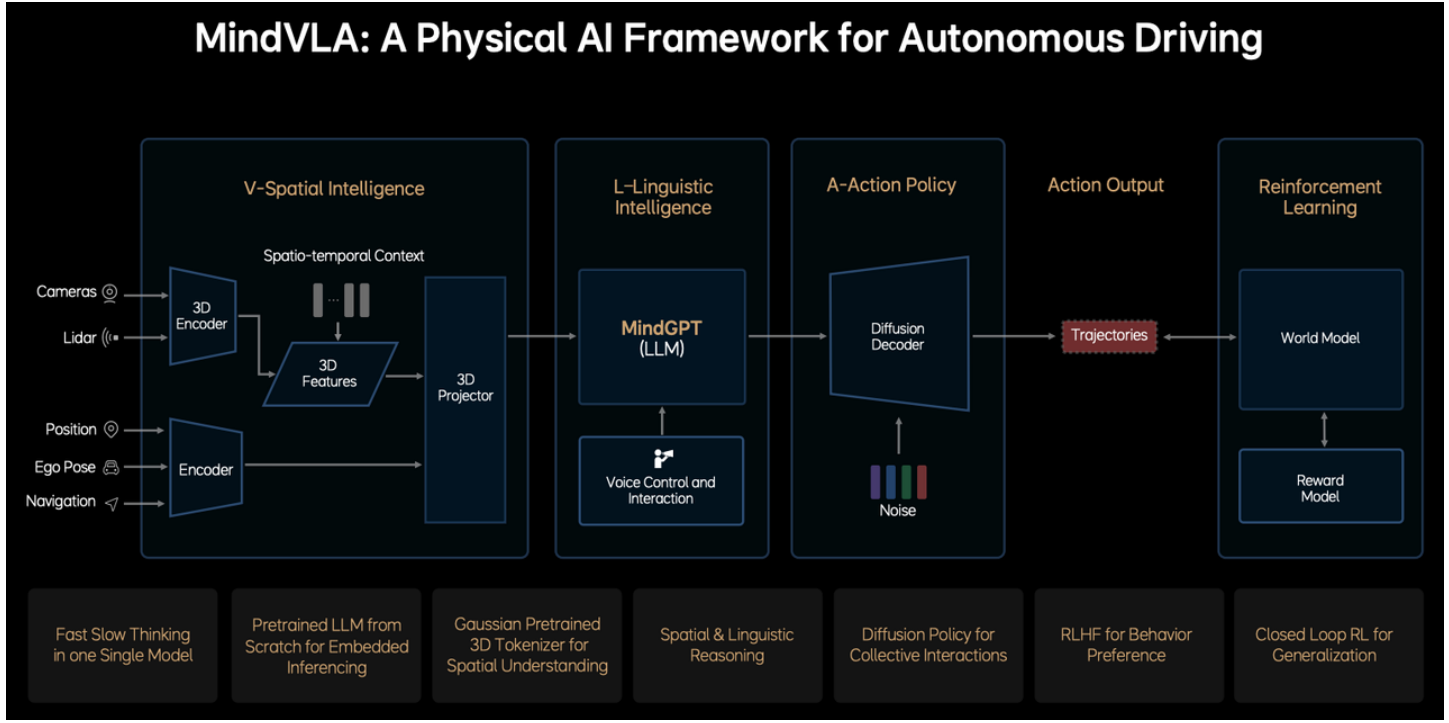
二、小鹏
⼩鹏汽⻋在新X9发布上市之前,做了⼀场AI技术分享会,再次强调了⾃⼰是⼀家AI驱动的技术公司。⽽这次技术分享会的⼀个核⼼内容就是:⼩鹏汽⻋正在研发VLA基座模型,也在研发"世界模型",⽽且⼩鹏汽⻋已经拥有10 EFLOPS的算⼒。
可以说,⼩鹏汽⻋整个智驾技术路线也已经向业界下⼀代主流路线VLA开始迭代。
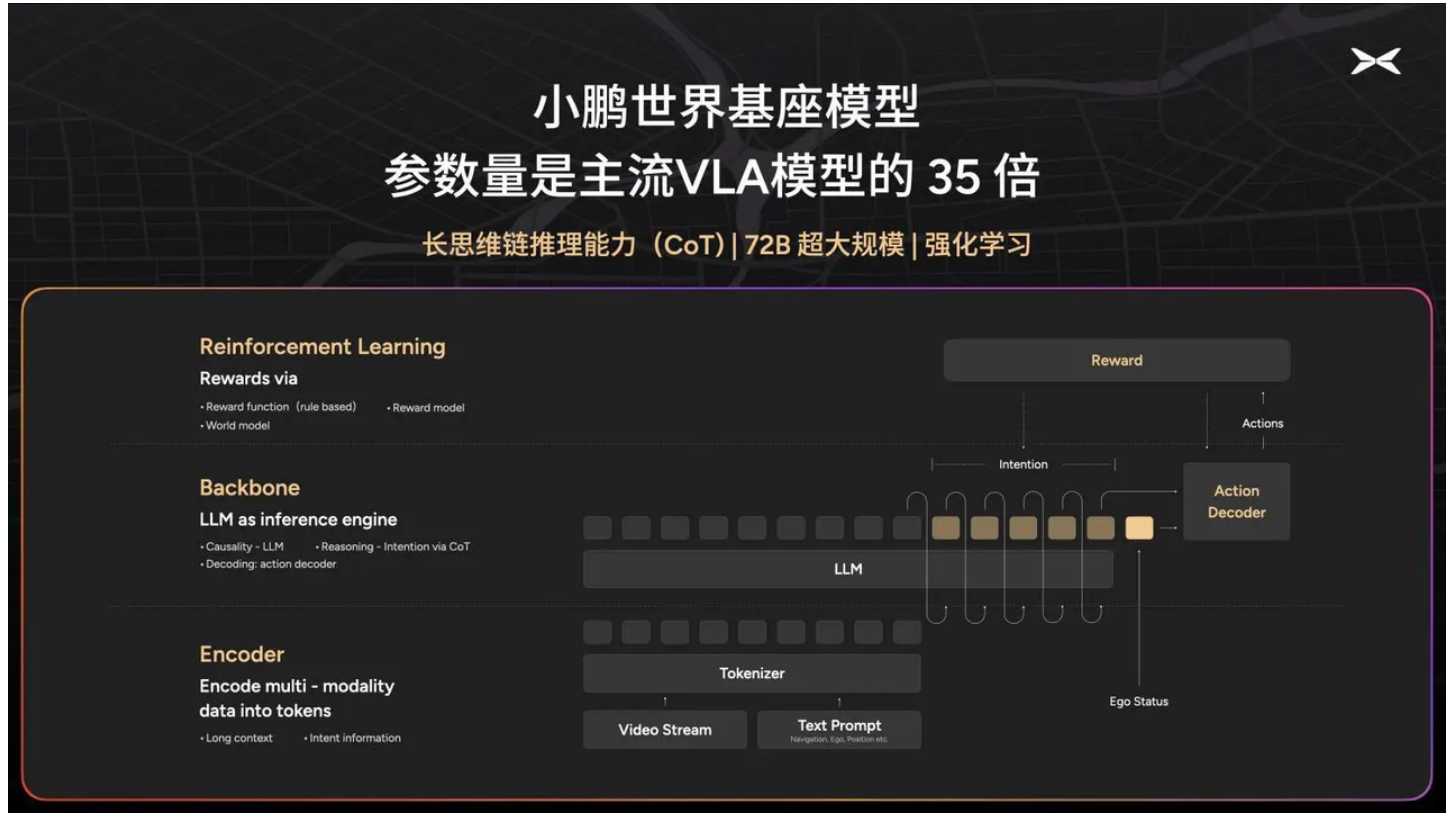
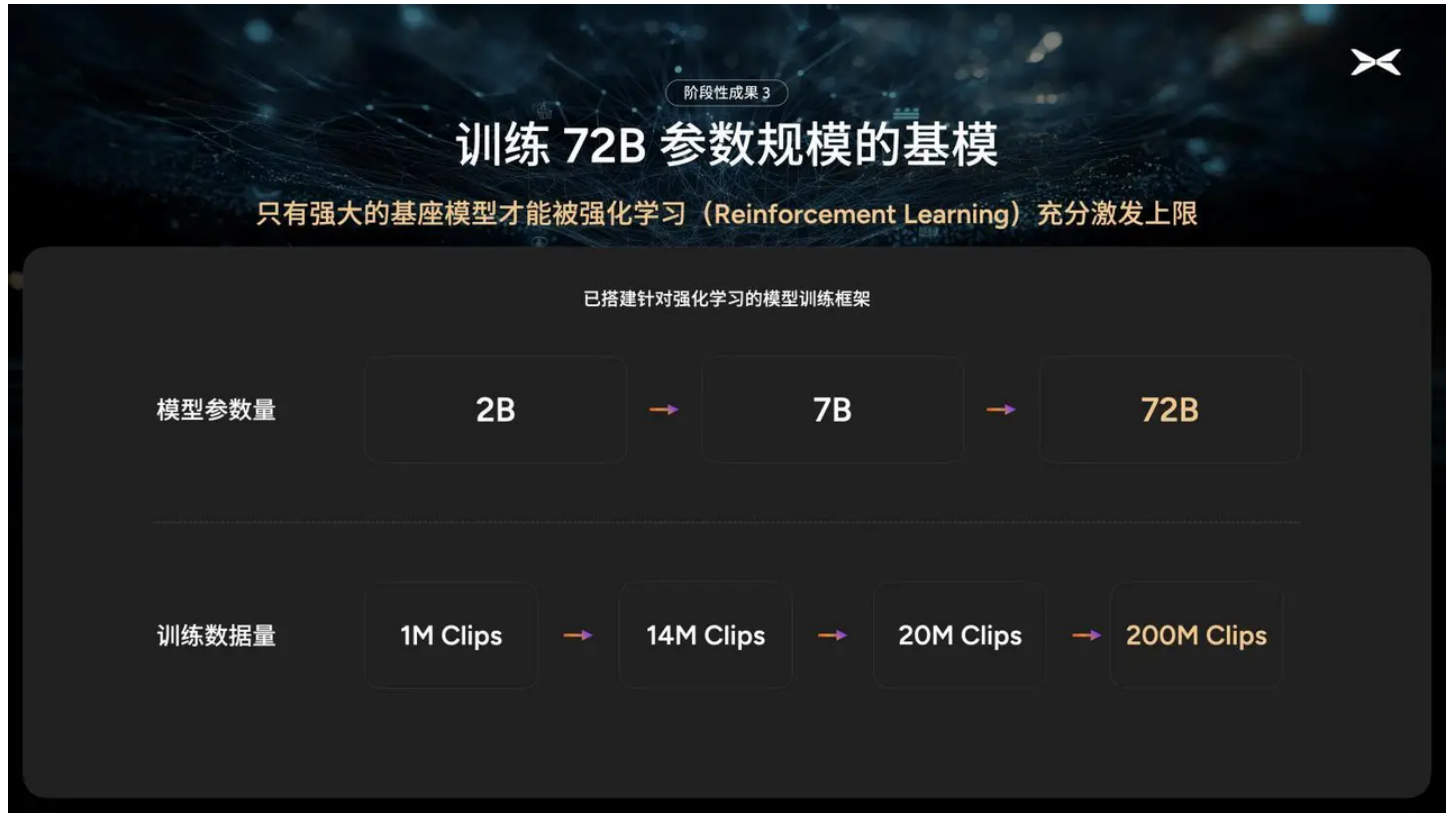
三、元戎启⾏
元戎启⾏则更进⼀步,于2025年1⽉22⽇宣布与某头部⻋企合作,基于英伟达Thor芯⽚推出VLA量产⻋型,计划年内交付消费者,元戎还透露将在Robotaxi领域探索VLA应⽤,展现了技术普适性的野⼼。
3⽉30⽇,在百⼈会智能汽⻋创新技术与产业论坛上,元戎启⾏CEO周光表⽰已完成VLA模型(多模态的视觉语⾔动作模型)的道路测试,并将基于VLA模型打造全系列的智能驾驶系统产品,涵盖激光雷达⽅案与纯视觉⽅案,适配多种芯⽚平台,预计今年将有超5款搭载VLA模型的⻋型进⼊消费者市场。周光认为,VLA模型作为当下最先进的技术,使汽⻋成为了AI智能体,在需求暴涨的背景下,VLA模型将重塑市场格局。https://www.stcn.com/article/detail/1626804.html
四、小米
2025年3⽉中旬,⼩⽶汽⻋与华中科技⼤学联合发表论⽂:ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation,提出了⼀种全新的端到端⾃动驾驶框架 ORION,旨在解决现有⽅法在闭环评估中因果推理能⼒不⾜的问题。
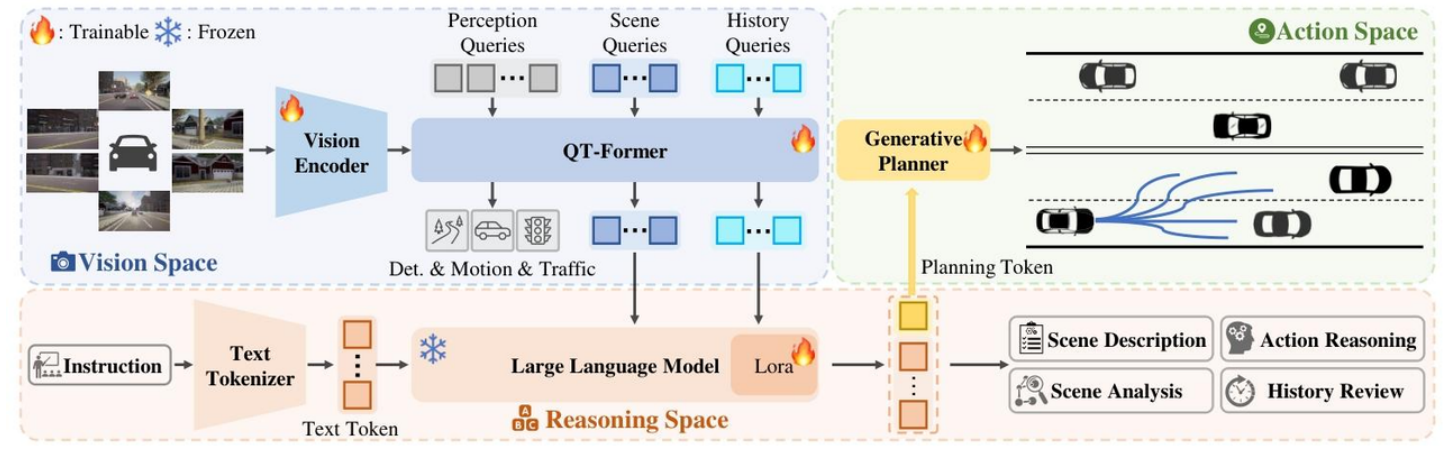
核⼼内容:
- 研究背景与挑战
- 端到端⾃动驾驶的瓶颈:传统端到端⽅法在闭环评估中因因果推理能⼒有限,难以做出正确决策。尽管视觉语⾔模型(VLM)具备强⼤的理解和推理能⼒,但其语义推理空间与动作空间的数值轨迹输出存在鸿沟,导致闭环性能不佳。
- 现有⽅法的缺陷
- 直接⽂本输出:VLM 不擅⻓数值推理,且⾃回归机制⽆法处理⼈类规划的不确定性。
- 元动作辅助:VLM 与经典端到端⽅法解耦,⽆法协同优化轨迹和推理过程。
五、参考⽂献
关键Paper
- Towards Generalist Robot Learning from Internet Video: A Survey
- 机器⼈领域的VLA开⼭之作RT-2框架:RT-2: Vision-Language Action Models Transfer Web Knowledge to Robotic Control
- OpenVLA: An Open-Source Vision-Language-Action Model
- A Dual Process VLA: Efficient Robotic Manipulation Leveraging VLM
- Helix: A Vision-Language-Action Model for Generalist Humanoid Control
- A Survey on Vision-Language-Action Models for Embodied AI
- Survey on Vision-Language-Action Models
- OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
- CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
VLA其他相关论⽂速递
- Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- OpenVLA: An Open-Source Vision-Language-Action Model
- TOWARDS SYNERGISTIC, GENERALIZED AND EFFICIENT DUAL-SYSTEM FOR ROBOTIC MANIPULATION
- π0: A Vision-Language-Action Flow Model for General Robot Control
- RDT-1B: A DIFFUSION FOUNDATION MODEL FOR BIMANUAL MANIPULATION
- GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
- Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression
- DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
- Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
- ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
- VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion
⼩⽶
理想VLA相关论⽂
- GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
- Generalizing Motion Planners with Mixture of Experts for Autonomous Driving
- Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving
- StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
- Balanced 3DGS: Gaussian-wise Parallelism Rendering with Fine-Grained Tiling
- ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
- DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
- DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation
理想VLA技术报告PPT
• 技术报告
Report
- 具⾝智能与⾃动驾驶的结合点:VLA
- ⼩鹏汽⻋启动VLA基模研发,2亿Clips训练720亿超⼤规模模型
- ⼩⽶汽⻋端到端VLA⾃动驾驶⽅案Orion,似乎在diss理想的MindVLA
- 理想全新⼀代智驾VLA技术⽅案解读
- 2025年,⾃动驾驶即将开"卷"的端到端⼤模型 2.0 - VLA (Vision Language Action)
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- OpenVLA: An Open-Source Vision-Language-Action Model https://openvla.github.io/
- 2024 年 Physical Intelligence 发布的 VLA 模型 π0,基于 transformer + 流匹配(flow matching) 架构,当前开源领域最强的 VLA 模型之⼀。
- 理想贾鹏GTC 2025讲VLA完整视频(带字幕)