一个程序员的成长,除了写代码,很大一部分也在于不断发现和运用更好的工具。分享8个大大提高工作效率的工具,同事还在加班的时候,你都回到家了。
ServBay:本地开发环境的基石
无论做什么开发,一个稳定、隔离、易于管理的环境都是基础。ServBay帮我把这个基础打得非常牢固。
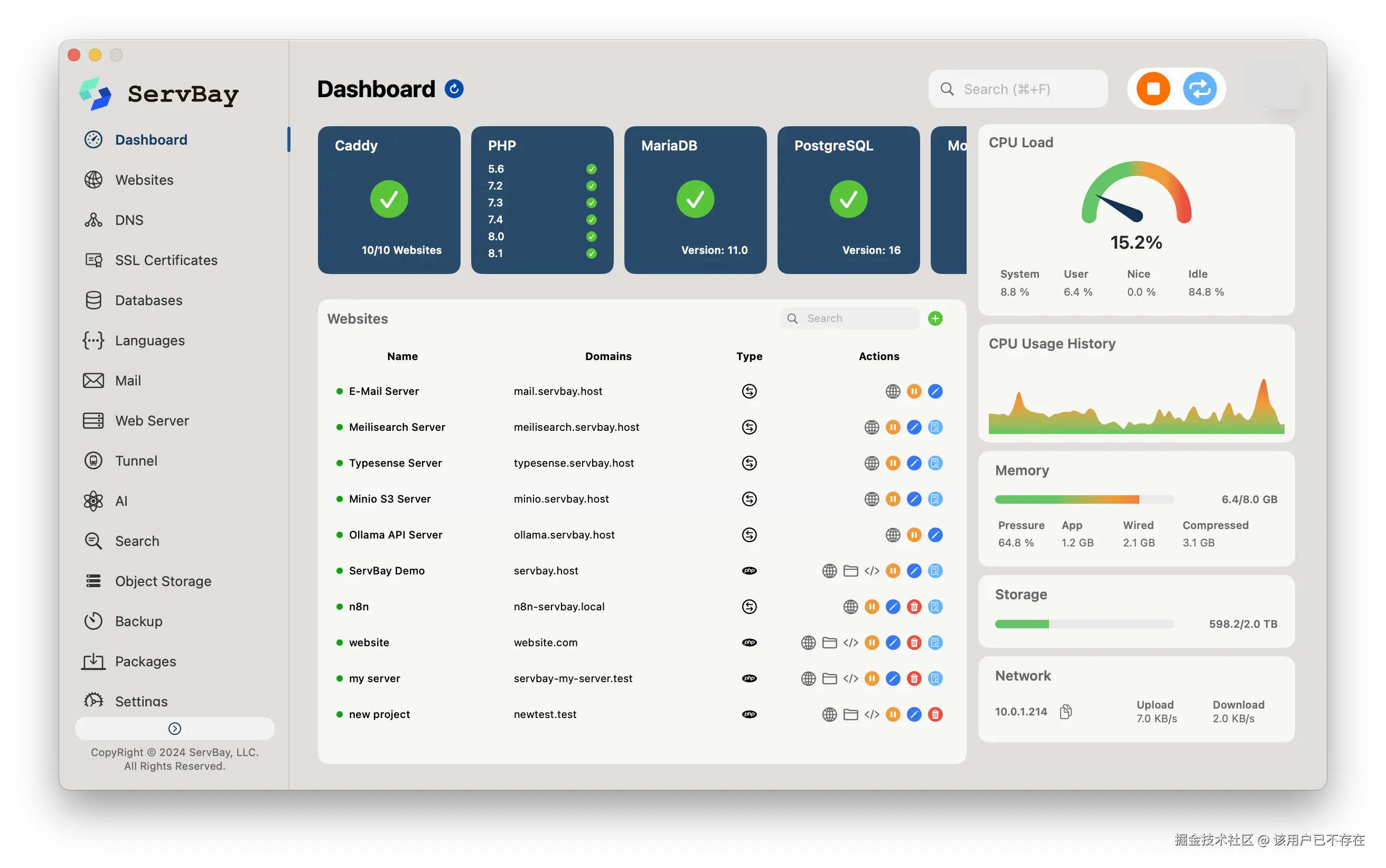
- 多版本共存 :我可以在一台电脑上同时安装和运行多个Python版本,维护老项目用2.7,新项目就用3.11,互不干扰。如果你是个全栈开发者,还可以一键安装其他语言,无论是开发还是做测试都非常方便。
- 服务全家桶:除了Python,它还集成了我常用的数据库(MySQL、MariaDB, PostgreSQL)、缓存(Redis)等服务。我不用再为每个服务单独安装和配置,在一个地方就能全部搞定。
- 一键切换和管理:它的图形界面支持一键切换Rust、Python等各种常用开发语言,启动停止服务这些操作变得非常直观,点几下鼠标就行。
- 一键安装本地 AI : 一键安装和运行DeepSeek、Qwen 3、Llama 3等这类开源大模型。想在本地跑个AI玩玩或者做开发,不需要折腾复杂的环境配置,点一下就行。
一句话点评:它是我本地开发环境的核心,帮我省去了大量在环境配置上折腾的时间。
Hypothesis:测试不再需要猜数据
写单元测试时,通常会自己想几个测试用例,比如测一个加法函数,可能会用assert add(2, 3) == 5,再加个负数assert add(-1, -5) == -6。但很难覆盖所有边界情况。Hypothesis这个库改变了我的测试思路。
它会根据我定义的规则,自动生成成百上千个刁钻的测试数据来攻击我的函数,专门找那些我没想到的边界情况。
示例代码:
python
from hypothesis import given
import hypothesis.strategies as st
def absolute_value(x):
if x < 0:
return -x
return x
# 我告诉Hypothesis,用任意整数来测试我的函数
@given(st.integers())
def test_absolute_value_is_always_positive(x):
# 我只定义规则:结果必须大于等于0
assert absolute_value(x) >= 0我不再需要手动写 test_absolute_value(5),test_absolute_value(-10) 等等。Hypothesis会自动用0、-1、非常大的数、非常小的数去测试,一旦发现反例就会立刻报告。
一句话点评:它能帮我找到那些靠手写测试用例几乎不可能发现的隐藏bug。
MonkeyType:为老代码自动加上类型注解
我接过一些没有类型注解(Type Hints)的老项目,手动一个个加str, int不仅枯燥,还容易出错。MonkeyType是Facebook开源的一个神器,它能通过运行代码,观察函数的输入和输出来自动生成类型注解。
我的使用流程通常是:
-
用
monkeytype run启动我的测试脚本。 -
MonkeyType会默默记录下所有函数的调用和返回值类型。
-
测试跑完后,用
monkeytype apply my_module命令,它就会把推断出的类型注解写回我的.py文件里。
命令行用法:
python
# 1. 运行你的脚本,并让MonkeyType收集类型信息
monkeytype run my_script.py
# 2. 将收集到的类型信息应用到你的模块文件
monkeytype apply my_project.my_module一句话点评:给没有类型注解的旧代码库补充类型时,它能帮我完成80%的体力活。
DuckDuckGo Search:无需API Key的轻量级搜索库

有时候,我需要写个小工具,让它能从网上搜索一些信息。通常这意味着要去申请Google或Bing的API Key,过程有点麻烦。Duck这个库就非常轻便,它能直接调用DuckDuckGo的搜索功能,不需要任何API Key。
示例代码:
python
from duckduckgo_search import DDGS
with DDGS() as ddgs:
for r in ddgs.text('Python web scraping libraries', max_results=5):
print(r['title'], r['href'])就这么几行代码,我就能拿到搜索结果的标题和链接,对于做一些简单的数据聚合或信息查询工具来说,简直太方便了。
一句话点评:当我需要快速实现程序化搜索功能,又不想折腾API Key时,我就会用它。
Requests-HTML:一体化网页解析库
很多人熟悉用 Requests 库获取网页,然后用BeautifulSoup来解析。Requests-HTML的作者和 Requests是同一个人,他把这两个步骤合二为一了。获取网页后,可以直接在响应对象上用CSS选择器来查找元素,代码写起来更连贯。
示例代码:
python
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
# 获取到响应后,直接用CSS选择器找元素
intro = r.html.find('#intro', first=True)
print(intro.text)
# 还能直接拿到所有链接
for link in r.html.links:
print(link)一句话点评 :对于不那么复杂的爬虫任务,它比requests + BeautifulSoup的组合拳更直接。
PGQueuer:用PostgreSQL就够了,轻量级任务队列
在Web开发中,处理耗时任务(比如发送邮件、处理视频)时,通常会用到任务队列,像Celery + Redis是很常见的组合。但有时我的项目很简单,只用到了PostgreSQL数据库,为了一个队列功能再引入一个Redis服务,感觉有点重。
PGQueuer让我可以直接用PostgreSQL来实现一个可靠的任务队列。它足够简单,也足够稳定。
示例代码:
python
# --- 发送任务 ---
from pgqueuer import PGQueuer
queue = PGQueuer('postgresql://user:pass@host/dbname')
queue.put({'email': 'test@example.com', 'content': 'Hello!'})
# --- 工作进程 ---
# worker.py
while True:
task = queue.get()
if task:
send_email(task.payload['email'], task.payload['content'])
task.ack() # 确认任务完成一句话点评:当我的项目里已经有PostgreSQL,并且只需要一个简单的后台任务队列时,我用它来避免增加技术栈的复杂度。
Snoop:比print()更强大的调试魔法
调试代码时,我以前也喜欢在函数里加一堆print()来看变量的变化。Snoop 其实是print()调试法的终极进化版。只需要在函数上加一个装饰器,它就能在运行函数时,把每一步的执行过程、变量的来龙去脉都清清楚楚地打印出来。
示例代码:
python
import snoop
@snoop
def factorial(x):
if x == 1:
return 1
return x * factorial(x - 1)
factorial(4)运行后,就会有非常详细的函数调用过程和每一步x的值,比自己手动print省事多了,也清晰多了。
一句话点评 :当我想快速搞懂一个复杂函数的内部执行逻辑时,Snoop 比打断点或加一堆print更直观。
PyWebView:用Python和Web技术轻松构建桌面应用
有时候我想把一个Web应用打包成桌面应用,但又觉得Electron太臃肿。PyWebView 是一个非常轻量的选择,它能创建一个本地窗口,然后在里面展示我的Web页面(可以是本地的HTML/CSS/JS文件,也可以是一个在线URL)。
它利用的是操作系统自带的浏览器内核(Windows上的Edge WebView2,macOS上的WebKit),所以打包出来的应用体积很小。
示例代码:
python
import webview
# 创建一个窗口,加载指定的URL
webview.create_window('我的桌面应用', 'https://python.org')
webview.start()这几行代码就能把一个网站变成一个独立的桌面程序。它还能实现Python和JavaScript之间的双向调用,可玩性很高。
一句话点评:当我需要快速地把Web项目包装成一个轻量级桌面应用时,我会优先考虑它。
工具是死的,但解决问题的思路是活的。希望我分享的这些工具能给你带来一些新思路,在你遇到类似问题时,能想起"哦,好像有个工具可以试试"。