1. 概述
KWDB 作为一款面向 AIoT 场景的分布式多模数据库产品,支持在同一实例同时建立时序库和关系库并融合处理多模数据,具备千万级设备接入、百万级数据秒级写入、亿级数据秒级读取等时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。
KWDB 的 SQL 引擎由解析器 、优化器 和执行器组成,编译优化部分主要介绍解析器和优化器。
解析器:核心作用是将用户输入的 SQL 语句转换为 KWDB 可运行的结构化数据,同时完成必要的规范性校验,主要包含词法解析、语法解析和语义解析三个关键步骤。
优化器:核心作用是基于规则与成本优化策略,对解析器生成的结构化数据进行等价转换,在不改变 SQL 语句原意的前提下,提升执行效率、降低运行成本,主要涵盖 RBO 优化、CBO 优化和多模计算优化等方式。
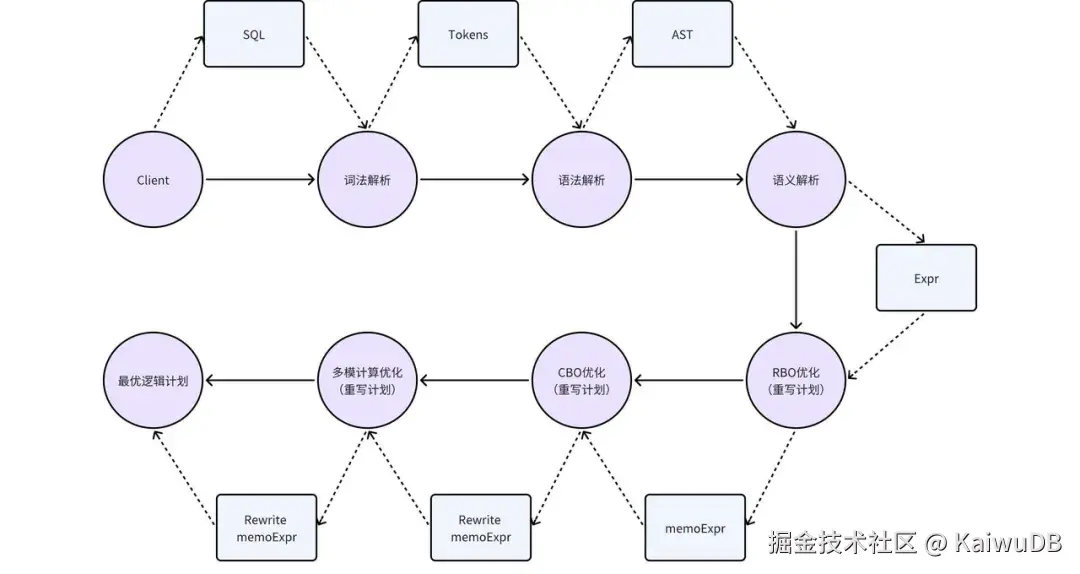
2. KWDB 查询编译和优化基础架构
在 KWDB 的编译阶段,SQL 语句主要经历词法解析、语法解析和语义解析三个处理步骤。其中,为进一步优化执行计划,在语义解析阶段还会同步进行 RBO 优化。
2.1 词法解析
KWDB 的词法解析会依据 yacc 文件中定义的词法单元,将 SQL 语句从字符流转换为具备明确词法属性的词法单元列表(tokens),这些词法单元包括关键字、标识符、常量和运算符等。
具体步骤如下:
预处理:去除 SQL 语句中的注释与空白字符,简化后续解析流程。
词法单元识别:扫描处理后的 SQL 字符流,按照词法规则分解并识别出各个词法单元。
构建 tokens 列表:将识别出的词法单元按照原始 SQL 语句的顺序排列,形成 tokens 列表。
例如有以下查询语句:
css
SELECT a, b FROM t WHERE c > 30;词法分析的结果如下:
css
SELECT(关键字)
a(标识符)
,(分隔符)
b(标识符)
FROM(关键字)
t(标识符)
WHERE(关键字)
c(标识符)
>(运算符)
30(常量)
;(分隔符)2.2 语法解析
KWDB 的语法解析会根据 yacc 文件中定义的语法规则,对 tokens 列表进行遍历识别,主要完成两项核心任务:一是校验语法是否存在错误,二是判断是否存在规约冲突。
无法生成语法树的情况如下:
语法错误:在判断需要进行规约(生成语法)时校验失败,如:未定义的语法。
移进-规约冲突:无法决定是移入(继续读取token)还是规约(生成语法),通常是因为输入串中的符号可能会匹配多个产生式的右侧。
规约-规约冲突:存在多个规约操作的可能性,无法确定应使用哪一个规约规则,存在歧义。
当每次规约操作均正确完成,且 tokens 列表遍历结束后,最终会生成抽象语法树(AST),为后续语义解析提供结构化基础。
2.3 语义解析
KWDB 的语义解析会对查询的语法树AST进行深入的分析,以确保查询在逻辑和语义上是有效的,并且能够正确地执行。
具体操作如下:
有效性校验:检查查询语句是否为 SQL 语言中的合法语句,包括表与列的存在性校验、数据类型兼容性检查、用户操作权限验证以及约束条件合规性校验等。
名称解析:确定表名、变量名等标识符的具体含义与对应值。
常数折叠:消除中间运算过程,例如将 0.5+0.5 直接替换为 1.0,减少执行阶段的计算量。
数据类型确定:明确中间结果的数据类型,例如当查询语句包含子查询时,需确定子查询返回结果的具体数据类型。
经过语义解析后生成的执行计划已具备可执行性,但此时的计划并非最优方案,还需通过后续优化步骤进一步提升性能。
2.4 RBO 优化
RBO(Rule-Based Optimization,基于规则的优化)的核心原理是基于关系代数的等价变换,用执行效率更高的等价表达式替换原始表达式。其典型优化规则包括列裁剪、最大最小值消除、投影消除和谓词下推等。
具体分析如下:
- 列裁剪
假设表t有 a、b、c、d 四列。
有以下查询语句:
css
SELECT a FROM t WHERE b > 5;① 未优化方案:读取表 t 的所有列数据,根据 b > 5 的条件过滤后,再投影出 a 列数据。
② 优化后方案:先进行列裁剪,仅读取 a、b 两列数据,再根据过滤条件筛选,最终输出 a 列结果,显著减少数据读取量。
- 最大最小值消除
有以下查询语句:
sql
SELECT min(a) FROM t;这句话可以转换成:
css
SELECT a FROM t ORDER BY a DESC LIMIT 1; 相较于传统聚合计算,排序 + 限制的方式无需遍历所有数据后进行聚合操作,执行效率更高。
- 投影消除
假设表t和tt均有a、b、c、d四列。
有以下查询语句:
vbnet
SELECT t1.a t2.b FROM t AS t1 JOIN (SELECT a, b, c FROM tt) AS t2 ON t1.a=t2.a;此查询语句投影列中只需要表t的a列和表tt的b列,而join的右侧子查询的投影列存在a、b、c三列,c列在外层是不需要的,所以计划中会消除掉c列。
- 谓词下推
有以下查询语句:
sql
SELECT * FROM t, tt WHERE t.a > 3 AND tt.b < 5;① 未优化方案:先对两表进行笛卡尔积计算(需处理 100×100=10000 条数据),再根据过滤条件筛选。
② 优化后方案:先将过滤条件下推至表扫描阶段,假设符合 t.a > 3 的数据有 10 条,符合 tt.b < 5 的数据有 8 条,再对过滤后的数据进行笛卡尔积计算(仅需处理 10×8=80 条数据),数据处理量大幅降低。
谓词下推就是将过滤条件尽量靠近叶子节点。
经过 RBO 优化后的执行计划,在性能效率与资源成本上均优于未优化方案。除 RBO 优化外,KWDB 还会针对 SQL 语句进行更深度的 CBO 优化与多模场景的计算优化,具体内容将在第 3、4 章节展开介绍。
3. 针对多模计算的优化
3.1 KWDB 多模计算本地化
3.1.1 计算本地化概念
计算本地化是指将查询(query)尽可能部署到时序引擎内部执行,通过减少跨引擎数据传输、实现数据本地处理,从而提升查询效率。其核心目标是找到时序引擎能够支持的最大计划树,确保尽可能多的计算逻辑在时序引擎中完成。
3.1.2 计算本地化的基本思路
计划树构建:查询语句经语法解析后会生成树状结构的表达式(称为 memo tree),树中每一层表达式后续将转换为对应的算子,由执行引擎执行。在构建 memo tree 的过程中,需对 filter 等标量表达式进行评估与处理。
最大本地化计划树识别:memo tree 基本构建完成后,通过自顶向下的遍历方式,分析树中各层算子能否在时序引擎中本地化执行,最终确定可在时序引擎中完整执行的最大计划树。
3.1.3 每层针对计算本地化的处理
Scan 层: 时序数据的扫描操作全部在时序引擎中执行,默认支持计算本地化。
Filter 层:
① 需要对 filter 表达式进行拆解,判断哪些 filter 条件能实现计算本地化和哪些 filter 条件不能实现计算本地化并记录;
② 对记录结果进行一系列运算获取最终需要进行计算本地化的 filter 集合;
③ 将能实现计算本地化的部分作为一个过滤算子放到时序引擎执行;
④ 关系引擎根据不能实现计算本地化的部分重新构建新的 filter 层;
⑤ 关系接收时序 filter 处理后的数据并再做过滤;
这样就完成了 filter 层的计算本地化处理。
Group 层:涵盖 GroupBy、ScalarGroupBy、DistinctOnExpr 三种类型,需检查两处能否本地化:
① GroupBy:检查 group by 列与聚合函数(含输入类型、个数及运算逻辑)能否本地化;
② ScalarGroupBy(仅聚合函数,无 group by):仅需检查聚合函数能否本地化;
③ DistinctOnExpr(仅 group by,无聚合函数):仅需检查 group by 列能否本地化;
注:若任一检查项不满足,整个 group 层无法本地化。
Projection 层 :检查投影操作能否本地化,例如投影列中若出现int + float 类型运算(时序引擎不支持),则本层不进行本地化处理。
Limit 层:支持在时序引擎中本地化执行;若为多节点部署,需由网关节点对各时序引擎返回的结果进行二次 limit 汇聚,确保最终结果正确。
其他层:目前暂未实现本地化支持(如 join 表达式),将在后续版本中逐步完善。
3.1.4 计算本地化控制
我们希望通过一个灵活的、可调整的机制去控制各个层的计算本地化判断。下面介绍一个控制计算本地化的机制:本地化计算白名单。
3.1.4.1 本地化计算白名单
本地化计算白名单,一个用于控制表达式能否进行本地化计算的名单,具体形式为一张系统表。他记录了时序引擎支持的所有表达式,白名单由下列元素构成:可本地化执行操作、参数数量、参数类型、可本地化执行位置、默认是否开启、支持类型。
下面解释一下各个元素。
① 可本地化执行操作:表示这个表达式的操作符能否在时序引擎本地化计算;
② 参数数量:表示这个表达式的参数数量;
③ 参数类型:表示这个表达式的参数类型,可以表示多个参数的类型,是一个数组;
④ 可本地化计算位置:表示这个表达式在 query 中出现的位置;
⑤ 默认是否开启:默认是否可以本地化计算,可手动变更;
⑥ 支持类型:支持表达式的类型,如 const、column、agg、bianary、compare。
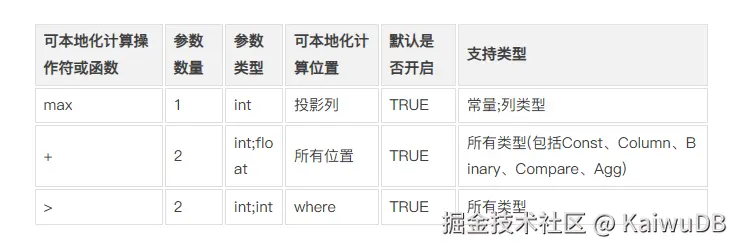
下面是一个白名单的例子:

在这个例子中,白名单允许满足某些条件的 "+" 操作符的表达式进行本地化计算机,"+"操作符满足以下条件时,可以通过本地化计算实现:
① "+" 操作符的参数数量为2,即左右参数;
② "+" 操作符的参数数类型为:左参数类型为int,右参数类型为int;
③ "+" 操作符出现在where条件中;
④ "+" 操作符的结果为一个常量或列类型。
3.1.4.2 利用白名单控制计算本地化
下面介绍下如何判定这个表达式在白名单中。
① 哈希编码生成:对每一条白名单记录,根据 "操作符 / 函数名称、参数数量、参数类型" 生成唯一的哈希编码(hash code)。
② 映射表构建:以哈希编码为 key,"可执行位置、表达式输出类型" 为 value,构建映射表(map)。
③ 表达式哈希计算:对需判断的表达式,同样根据 "操作符 / 函数名称、参数数量、参数类型" 生成哈希编码。
④ 映射表匹配与校验:用表达式的哈希编码在映射表中查询,若查询到对应 value,则进一步校验 "表达式实际位置是否匹配允许的位置""输出类型是否符合要求"。
⑤ 结果判定:若上述校验均通过,则该表达式可基于白名单规则进行本地化执行;否则不可本地化。
3.1.5 本地化计算判断举例说明
下面介绍一个例子判断计算本地化的过程。
如 select max(e1+e2) from d1.t1 where e1 > 0 group by e1; 其中 e1 列为int类型、e2列为float类型。
假设我们的白名单是这样的:
首先,这个 query 生成的 memo tree 是这样的。
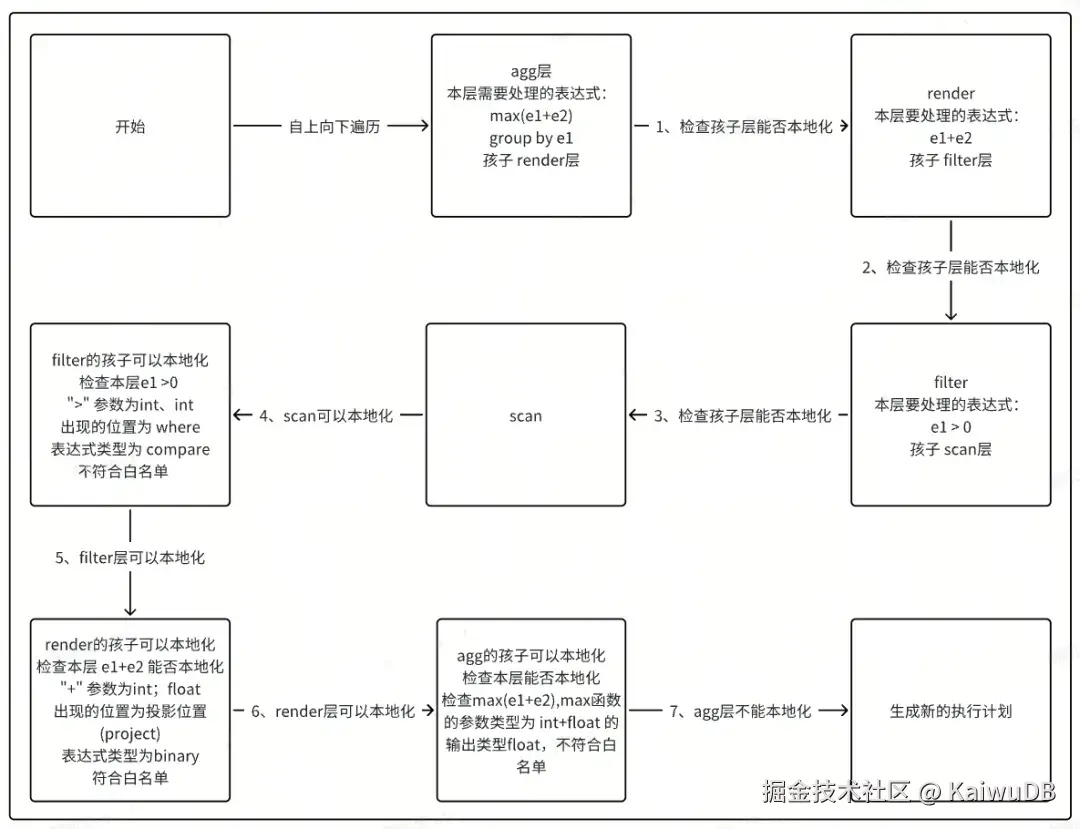
3.1.6 本地化计算主要逻辑入口
① CheckWhiteListAndAddSynchronize 本地化计算逻辑的入口;
② CheckWhiteListAndAddSynchronizeImp 本地化计算逻辑的主体,检查每一层算子能否本地化计算,其中包含检查每一层的函数;
③ CheckExprCanExecInTSEngine 判断本层表达式是否能由时序引擎本地化计算;
④ SetAddSynchronizer 给本层加并发标记。使用时序本地化计算的算子支持并发,所以找到可以本地化计算的最大树后,会加上可以并发的标记,以供时序引擎执行并发。
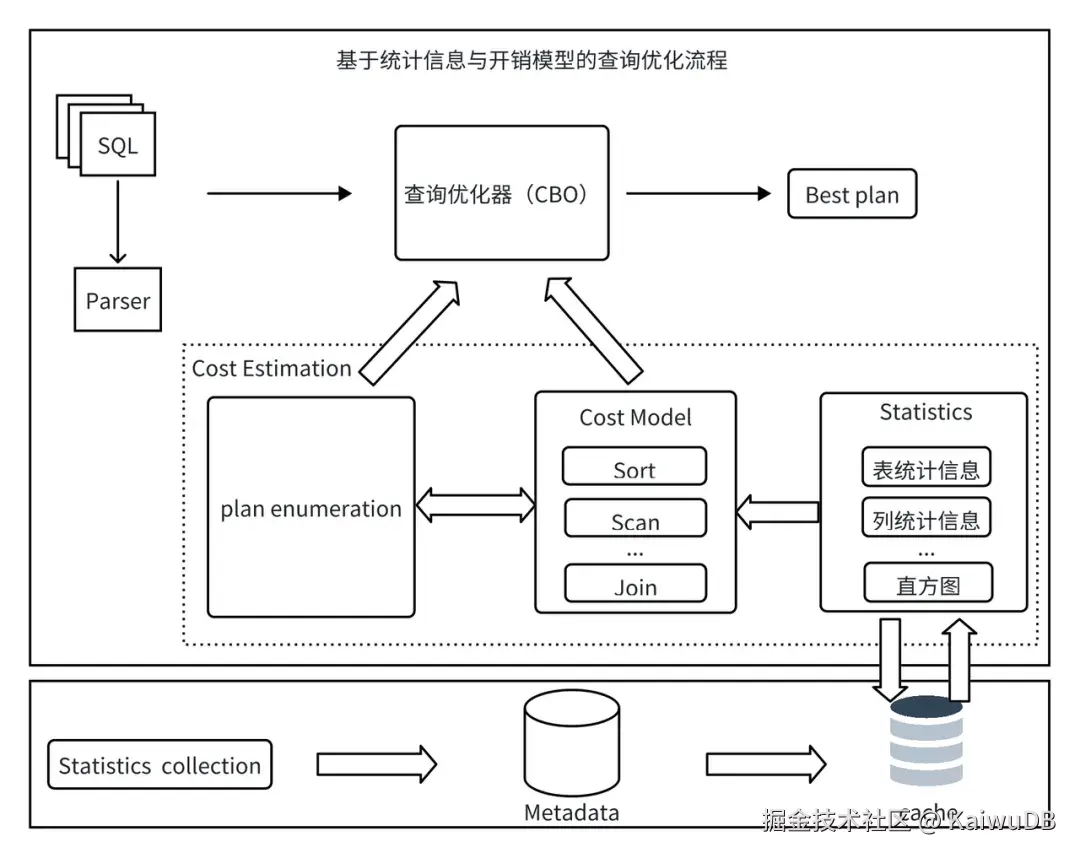
3.2 统计信息和 CBO
KWDB 的查询优化器采用 CBO(Cost-Based Optimization,基于成本的优化)策略,通过统计信息评估不同查询计划的预期执行成本,最终选择成本最低的执行计划。查询优化的主要流程如图所示:
3.2.1 统计信息
统计信息作为查询优化器的数据源,统计信息的收集过程如图所示:
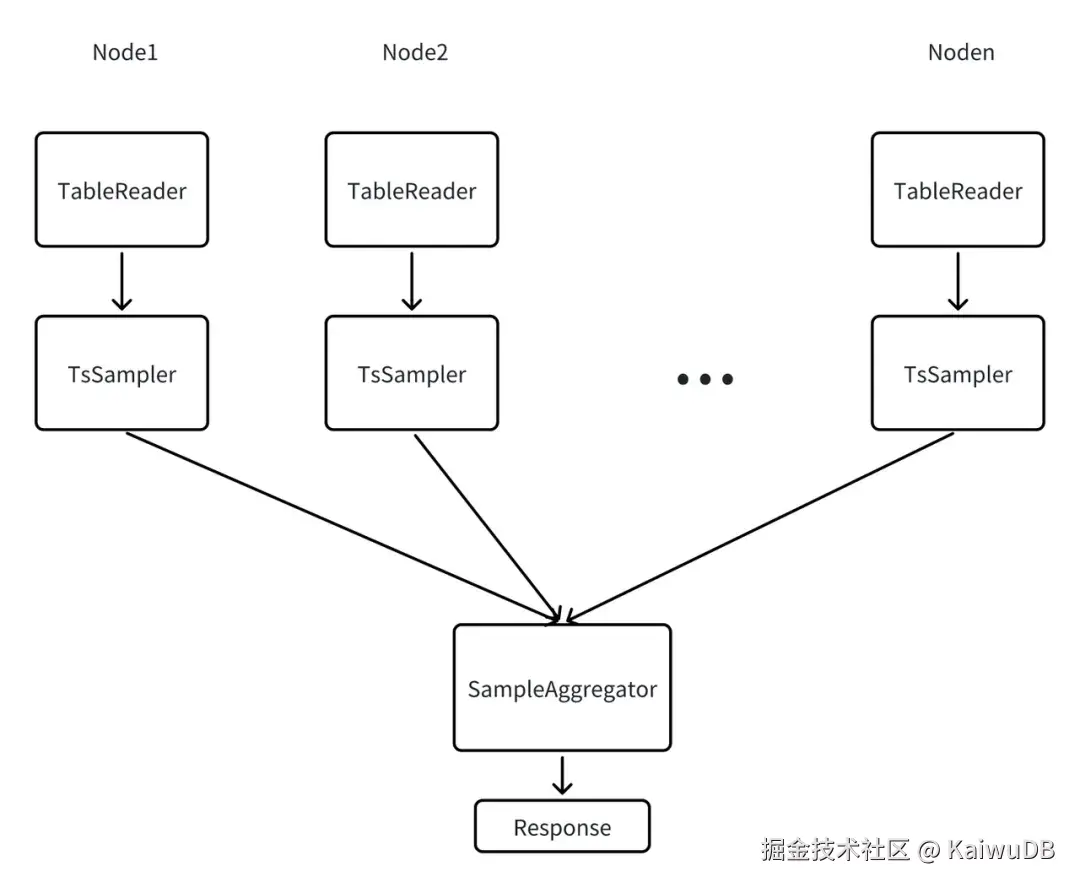
TableReader(表读取器):在各个数据节点上读取目标表的数据,为采样提供原始数据。
TsSampler(样本采样器):在每个节点上对 TableReader 读取的数据进行采样,统计该节点的表级信息、列的样本数据与基数。
SampleAggregator(采样汇总器):接收并聚合所有节点的采样结果,生成全局统计信息,并将其持久化存储至系统中,同时更新元数据缓存(Metadata Cache),供后续查询优化快速调用。
3.2.2 开销模型
开销模型由不同种操作类型的开销计算公式函数组成,在优化器中的主要行为包括:
① 对于传入的候选表达式,基于逻辑表达式树中的统计信息,对实际执行代价进行一个估计。
② 将估计代价分配给对应的表达式中,如果候选表达式的成本低于 memo 中的其他任何表达式,则它将成为该组的最佳新表达式。
Costor.go 中以 ComputeCost 为主函数入口展开,调用了相应的对象和其对应的函数来估算出表达式的执行代价。
3.2.3 计划列举
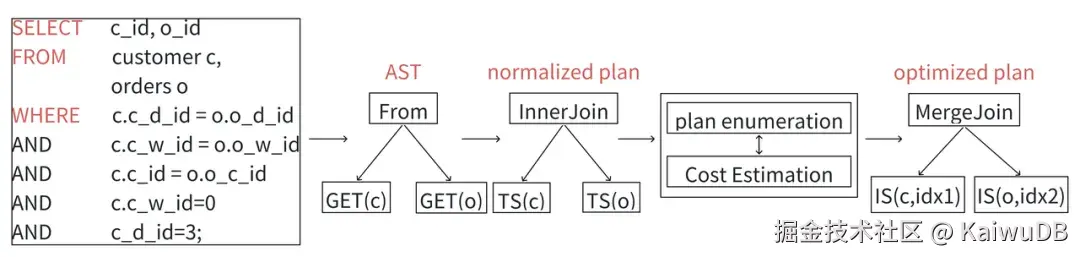
① 查询优化器采用Cascades框架,自顶向下进行优化;
② 在CBO初始阶段,将AST转化为一个规范化(normalized)计划;
③ 计划列举依次枚举所有与规范化计划等价的表达式,并估算每个表达式的代价;
④ 最后输出估算代价最小的计划,即最优计划。
以下举例说明:
3.3 总结
本文系统梳理了 KWDB 在查询编译与优化方面的核心流程,包括 SQL 语句的词法解析、语法解析、语义解析,以及基于规则的 RBO 优化、基于成本的 CBO 优化,同时详细介绍了针对多模场景的计算本地化优化策略。KWDB 项目目前仍处于快速迭代阶段,更多最新功能与技术创新可通过访问 KWDB 代码库获取。