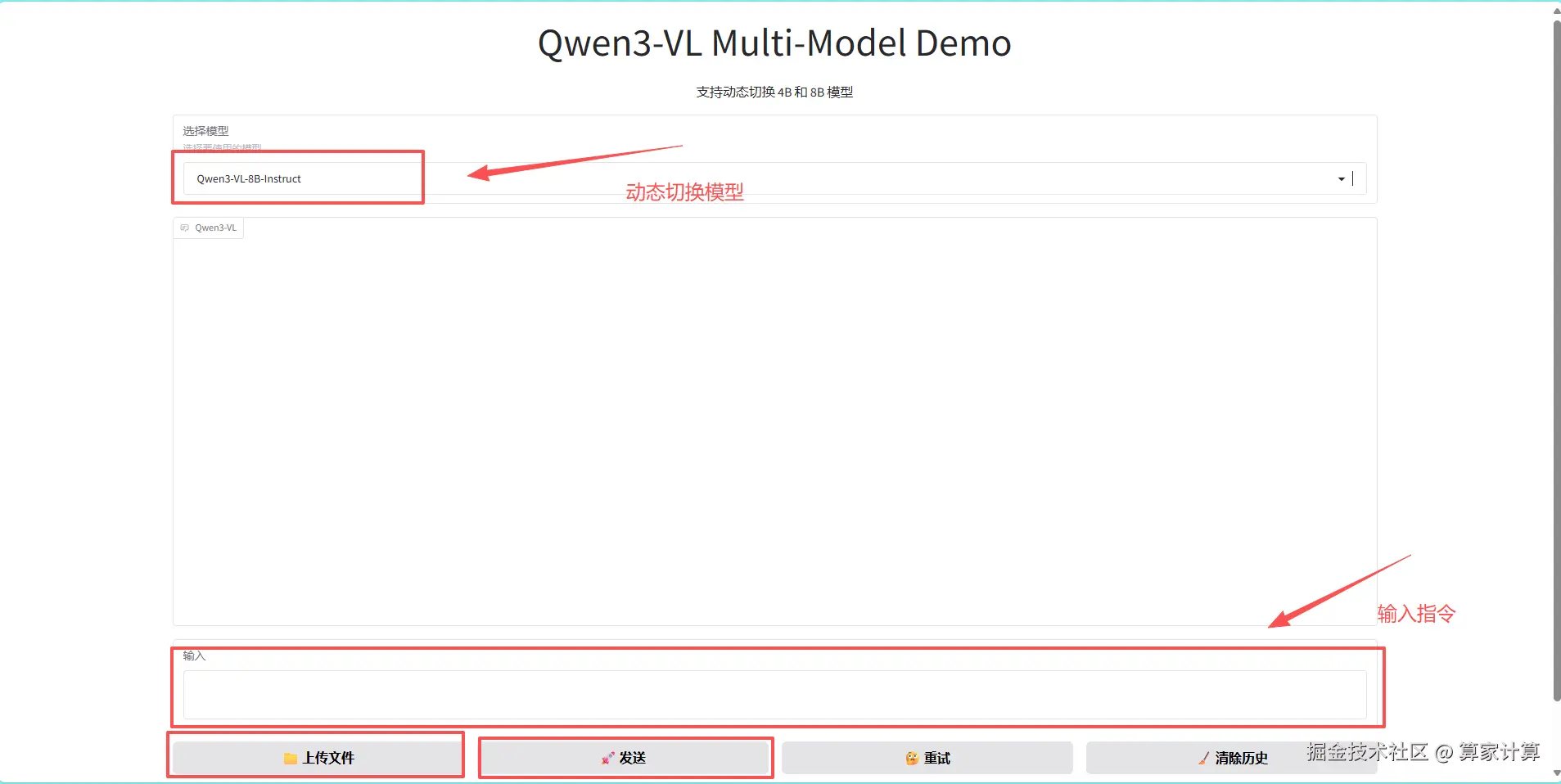
一、模型介绍
Qwen3-VL 是迄今为止 Qwen 系列中最强大的视觉语言模型。
这一代产品全面升级:卓越的文本理解和生成、更深层次的视觉感知和推理、扩展的上下文长度、增强的空间和视频动态理解以及更强大的智能体交互能力。
提供从边缘扩展到云的密集和 MoE 架构,并具有 Instruct 和推理增强型思维版本,可实现灵活的按需部署。
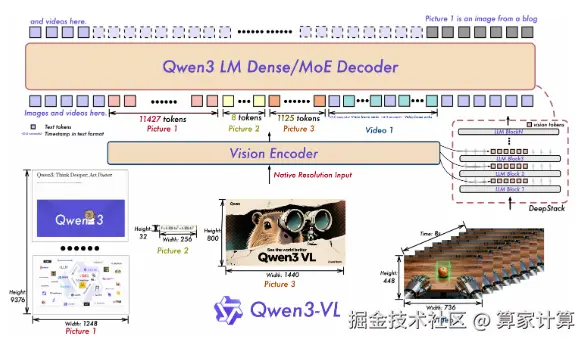
模型架构
二、模型部署步骤
部署环境
| Ubuntu | 22.04 |
|---|---|
| Cuda | 12.4 |
| Python | 3.12.2 |
| NVIDIA Corporation | RTX4090*1/2 |
1.更新基础的软件包
查看系统版本信息
bash
#查看系统的版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release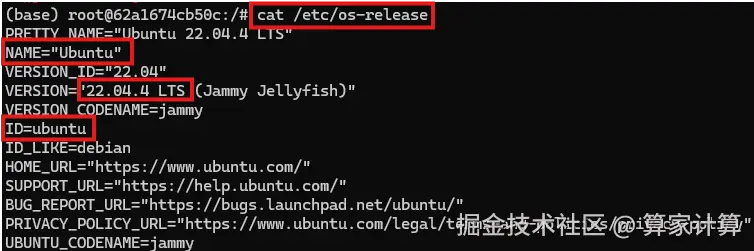
配置国内源
apt 配置阿里源
将以下内容粘贴进文件中
arduino
deb http://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb http://mirrors.aliyun.com/debian-security/ bullseye-security main
deb-src http://mirrors.aliyun.com/debian-security/ bullseye-security main
deb http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib2.基础 Miniconda3 环境
查看系统是否有 miniconda 的环境
conda -V
显示如上输出,即安装了相应环境,若没有 miniconda 的环境,通过以下方法进行安装
bash
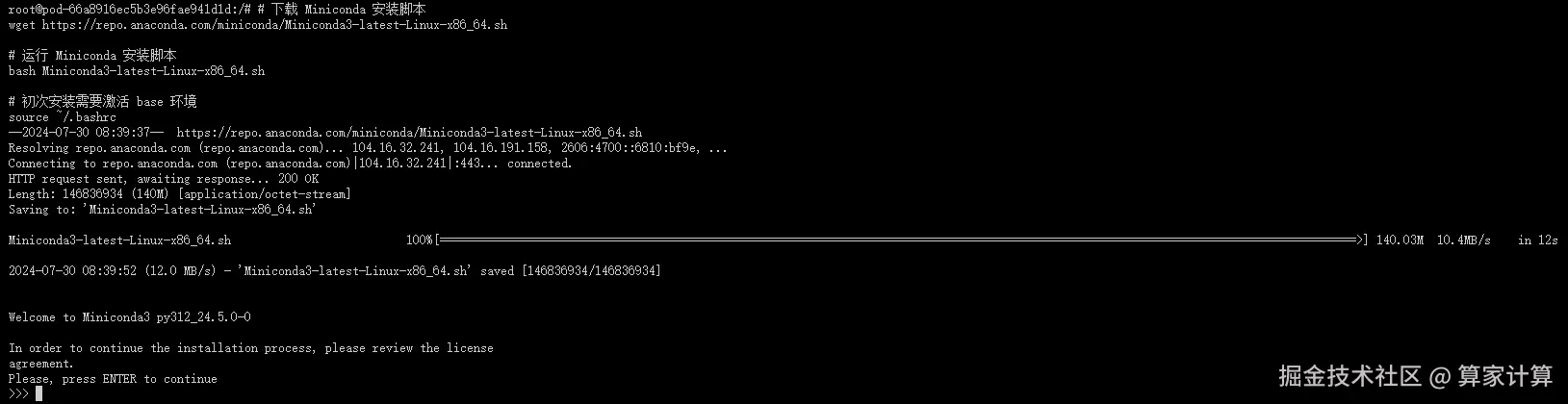
#下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
#运行 Miniconda 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
#初次安装需要激活 base 环境
source ~/.bashrc按下回车键(enter)
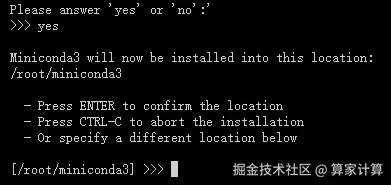
输入 yes
输入 yes
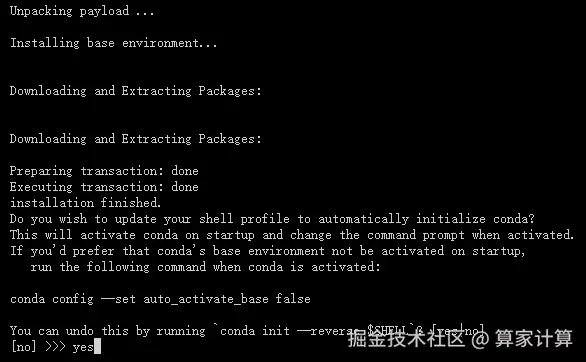
安装成功如下图所示

3.创建虚拟环境
ini
conda activate -n Qwen python==3.12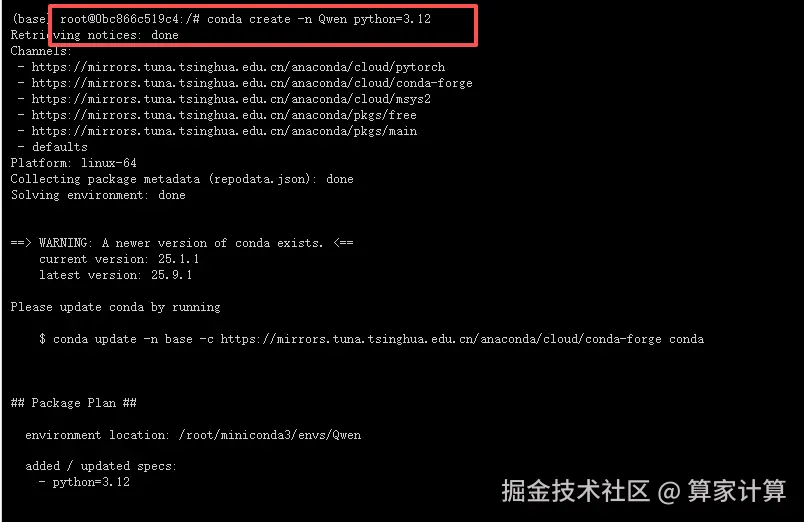

激活虚拟环境
conda activate Qwen
4.从 github 仓库克隆项目
输入命令克隆并进入项目
bash
git clone https://github.com/QwenLM/Qwen3-VL.git
cd Qwen3-VL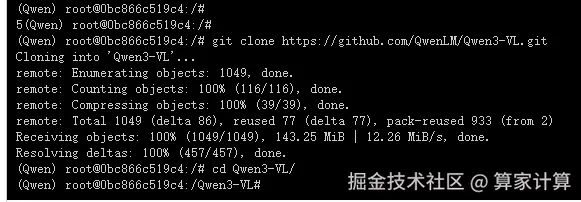
5.下载模型依赖库
其中gradio需要选择不指定版本
ruby
pip install -r requirements_web_demo.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/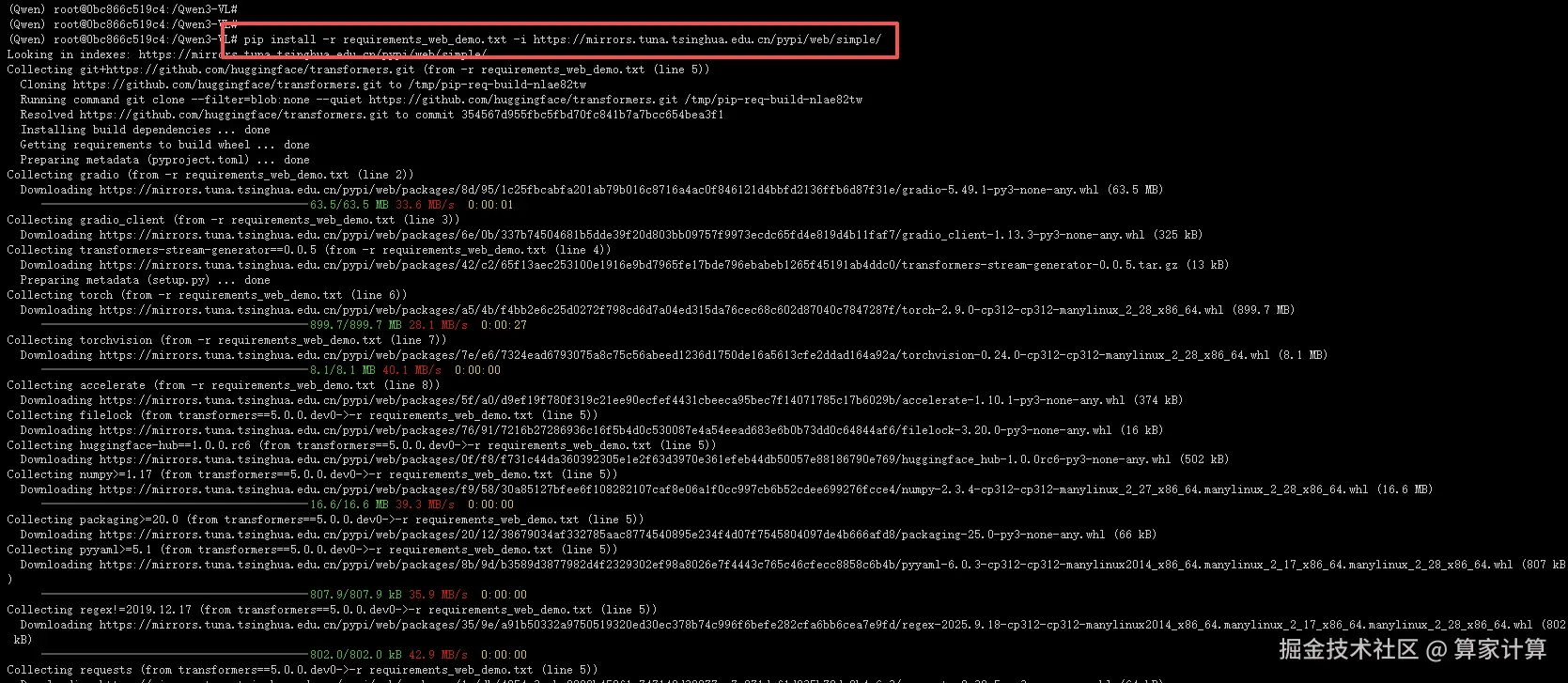
下载完成
同时下载vllm引擎,如果运行时出现库缺失问题请继续下载
6.下载模型权重
css
modelscope download --model Qwen/Qwen3-VL-4B-Instruct --local_dir ./Qwen3-VL-4B-Instruct
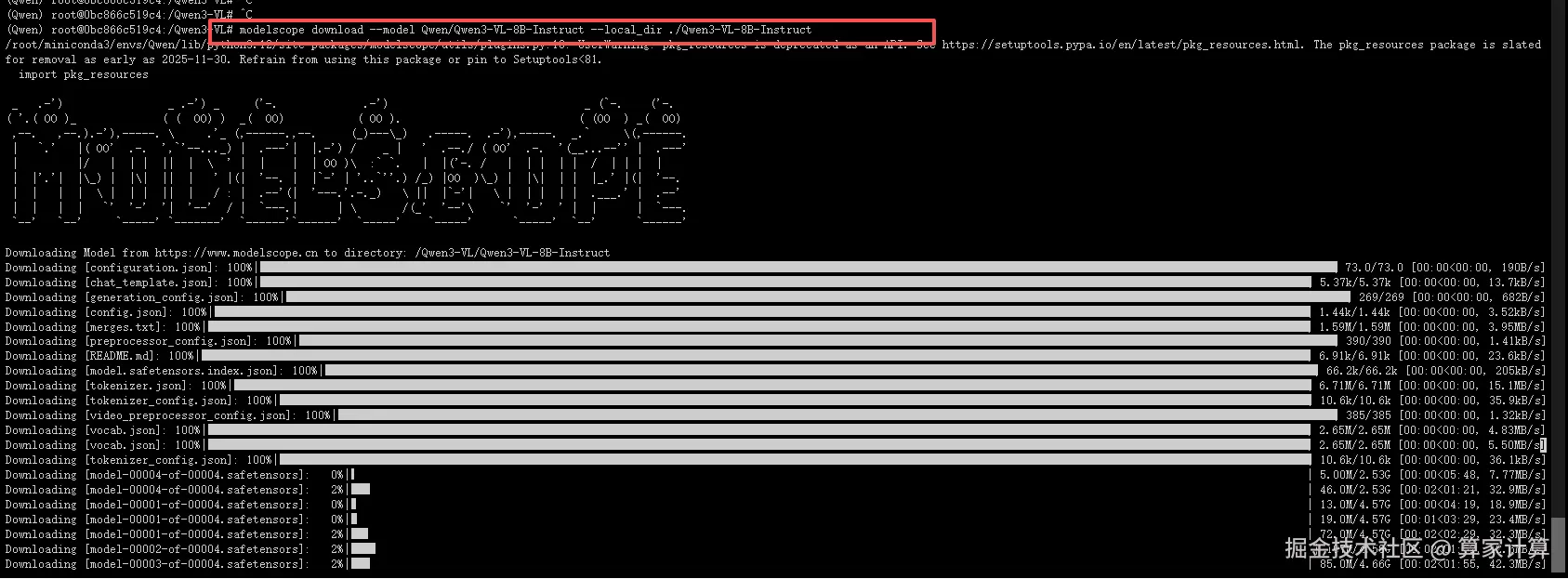
css
modelscope download --model Qwen/Qwen3-VL-8B-Instruct --local_dir ./Qwen3-VL-8B-Instruct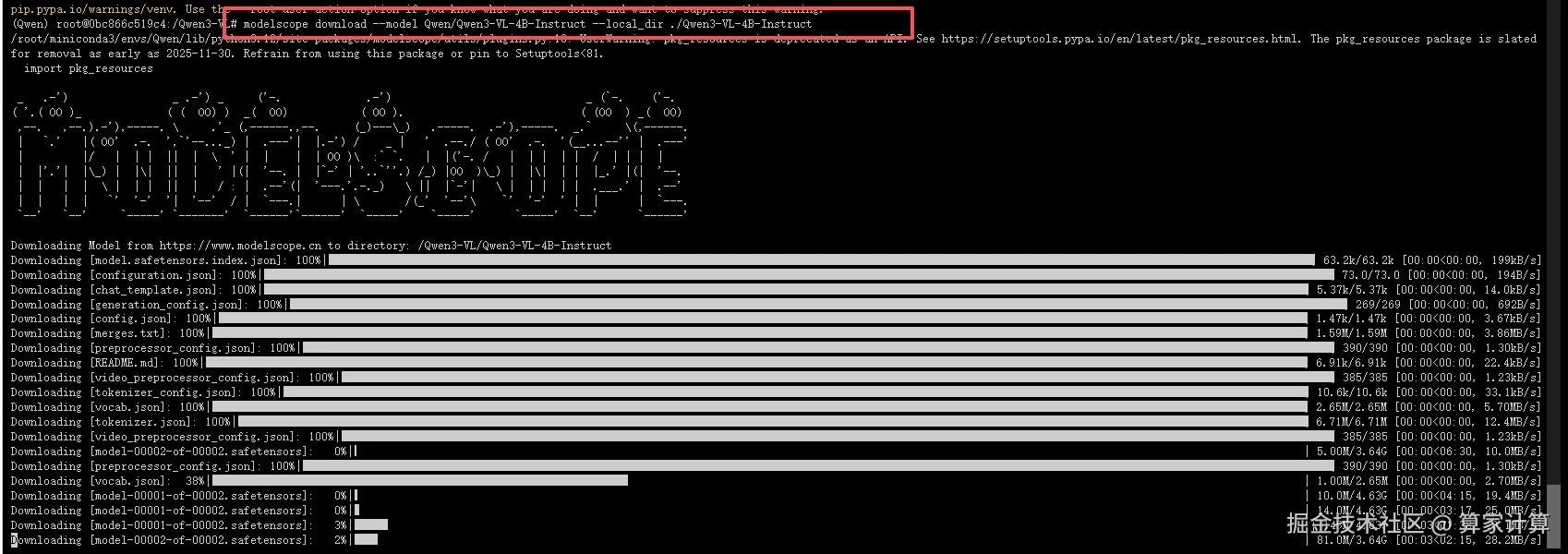
7.修改适量代码
对weui文件进行修改实现在两个模型之间切换
bash
python web_demo_mm.py #默认启动8B模型
python
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import os
import copy
import re
import gc
import threading
from argparse import ArgumentParser
from threading import Thread
import gradio as gr
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText, TextIteratorStreamer
try:
from vllm import SamplingParams, LLM
from qwen_vl_utils import process_vision_info
VLLM_AVAILABLE = True
except ImportError:
VLLM_AVAILABLE = False
print("Warning: vLLM not available. Install vllm and qwen-vl-utils to use vLLM backend.")
class ModelManager:
"""管理多个模型的加载和切换"""
def __init__(self):
self.models = {}
self.current_model = None
self.current_processor = None
self.current_backend = None
self.current_model_name = None
self.lock = threading.Lock()
def load_model(self, model_name, model_path, backend='vllm', gpu_memory_utilization=0.85,
tensor_parallel_size=2, max_model_len=32768, cpu_only=False, flash_attn2=False):
"""加载指定模型"""
with self.lock:
# 如果模型已加载,直接返回
if model_name in self.models:
self.current_model = self.models[model_name]['model']
self.current_processor = self.models[model_name]['processor']
self.current_backend = self.models[model_name]['backend']
self.current_model_name = model_name
return self.current_model, self.current_processor, self.current_backend
# 检查模型路径是否存在
if not os.path.exists(model_path):
raise FileNotFoundError(f"Model path not found: {model_path}")
print(f"Loading model {model_name} from: {model_path}")
# 释放当前模型占用的显存
if self.current_model:
self.unload_model(self.current_model_name)
model, processor, backend_type = self._load_single_model(
model_path, backend, gpu_memory_utilization, tensor_parallel_size,
max_model_len, cpu_only, flash_attn2
)
# 保存模型引用
self.models[model_name] = {
'model': model,
'processor': processor,
'backend': backend_type,
'path': model_path
}
self.current_model = model
self.current_processor = processor
self.current_backend = backend_type
self.current_model_name = model_name
print(f"Successfully loaded model {model_name} using {backend_type} backend")
return model, processor, backend_type
def _load_single_model(self, model_path, backend, gpu_memory_utilization,
tensor_parallel_size, max_model_len, cpu_only, flash_attn2):
"""加载单个模型"""
if backend == 'vllm' and VLLM_AVAILABLE:
try:
# 根据模型大小调整配置
if "4B" in model_path or "4b" in model_path:
# 4B模型使用更保守的配置
gpu_memory_utilization = min(gpu_memory_utilization, 0.7)
tensor_parallel_size = 1 # 4B模型单GPU运行
max_model_len = 16384
elif "8B" in model_path or "8b" in model_path:
# 8B模型使用默认配置
pass
os.environ['VLLM_WORKER_MULTIPROC_METHOD'] = 'spawn'
model = LLM(
model=model_path,
trust_remote_code=True,
gpu_memory_utilization=gpu_memory_utilization,
enforce_eager=False,
tensor_parallel_size=tensor_parallel_size,
seed=0,
max_model_len=max_model_len,
disable_custom_all_reduce=True
)
processor = AutoProcessor.from_pretrained(model_path)
return model, processor, 'vllm'
except Exception as e:
print(f"vLLM backend failed: {e}")
print("Falling back to HuggingFace backend...")
backend = 'hf'
# HuggingFace后端
if cpu_only:
device_map = 'cpu'
else:
device_map = 'auto'
if flash_attn2:
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.float16,
attn_implementation='flash_attention_2',
device_map=device_map,
trust_remote_code=True
)
else:
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map=device_map,
trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_path)
return model, processor, 'hf'
def unload_model(self, model_name):
"""卸载指定模型"""
if model_name in self.models:
print(f"Unloading model {model_name}")
model_info = self.models[model_name]
# 释放模型资源
try:
# 对于vLLM模型,直接删除引用即可,vLLM会自动清理
if hasattr(model_info['model'], 'llm_engine'):
# 新版本vLLM可能没有shutdown方法,我们直接删除引用
pass
elif hasattr(model_info['model'], 'cpu'):
# PyTorch模型,移到CPU
model_info['model'].cpu()
except Exception as e:
print(f"Error during model unloading: {e}")
# 清理GPU缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 垃圾回收
gc.collect()
del self.models[model_name]
print(f"Model {model_name} unloaded")
def switch_model(self, model_name, model_configs):
"""切换到指定模型"""
if model_name in model_configs:
config = model_configs[model_name]
return self.load_model(
model_name,
config['path'],
backend=config.get('backend', 'vllm'),
gpu_memory_utilization=config.get('gpu_memory_utilization', 0.85),
tensor_parallel_size=config.get('tensor_parallel_size', 2),
max_model_len=config.get('max_model_len', 32768),
cpu_only=config.get('cpu_only', False),
flash_attn2=config.get('flash_attn2', False)
)
else:
raise ValueError(f"Model {model_name} not found in configurations")
def _get_args():
parser = ArgumentParser()
current_dir = os.path.dirname(os.path.abspath(__file__))
# 默认模型路径
default_4b_path = os.path.join(current_dir, 'Qwen3-VL-4B-Instruct')
default_8b_path = os.path.join(current_dir, 'Qwen3-VL-8B-Instruct')
parser.add_argument('-c',
'--checkpoint-path',
type=str,
default=default_8b_path,
help='Checkpoint name or path, default to %(default)r')
parser.add_argument('--cpu-only', action='store_true', help='Run demo with CPU only')
parser.add_argument('--flash-attn2',
action='store_true',
default=False,
help='Enable flash_attention_2 when loading the model.')
parser.add_argument('--share',
action='store_true',
default=False,
help='Create a publicly shareable link for the interface.')
parser.add_argument('--inbrowser',
action='store_true',
default=False,
help='Automatically launch the interface in a new tab on the default browser.')
parser.add_argument('--server-port', type=int, default=8080, help='Demo server port.')
parser.add_argument('--server-name', type=str, default='0.0.0.0', help='Demo server name.')
parser.add_argument('--backend',
type=str,
choices=['hf', 'vllm'],
default='vllm',
help='Backend to use: hf (HuggingFace) or vllm (vLLM)')
parser.add_argument('--gpu-memory-utilization',
type=float,
default=0.85,
help='GPU memory utilization for vLLM (default: 0.85)')
parser.add_argument('--tensor-parallel-size',
type=int,
default=2,
help='Tensor parallel size for vLLM (default: 2)')
parser.add_argument('--max-model-len',
type=int,
default=32768,
help='Maximum model length for vLLM (default: 32768)')
parser.add_argument('--default-model',
type=str,
choices=['4B', '8B'],
default='8B',
help='Default model to load at startup: 4B or 8B (default: 8B)')
args = parser.parse_args()
return args
def _parse_text(text):
lines = text.split('\n')
lines = [line for line in lines if line != '']
count = 0
for i, line in enumerate(lines):
if '```' in line:
count += 1
items = line.split('`')
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = '<br></code></pre>'
else:
if i > 0:
if count % 2 == 1:
line = line.replace('`', r'`')
line = line.replace('<', '<')
line = line.replace('>', '>')
line = line.replace(' ', ' ')
line = line.replace('*', '*')
line = line.replace('_', '_')
line = line.replace('-', '-')
line = line.replace('.', '.')
line = line.replace('!', '!')
line = line.replace('(', '(')
line = line.replace(')', ')')
line = line.replace('$', '$')
lines[i] = '<br>' + line
text = ''.join(lines)
return text
def _remove_image_special(text):
text = text.replace('<ref>', '').replace('</ref>', '')
return re.sub(r'<box>.*?(</box>|$)', '', text)
def _is_video_file(filename):
video_extensions = ['.mp4', '.avi', '.mkv', '.mov', '.wmv', '.flv', '.webm', '.mpeg']
return any(filename.lower().endswith(ext) for ext in video_extensions)
def _transform_messages(original_messages):
transformed_messages = []
for message in original_messages:
new_content = []
for item in message['content']:
if 'image' in item:
new_item = {'type': 'image', 'image': item['image']}
elif 'text' in item:
new_item = {'type': 'text', 'text': item['text']}
elif 'video' in item:
new_item = {'type': 'video', 'video': item['video']}
else:
continue
new_content.append(new_item)
new_message = {'role': message['role'], 'content': new_content}
transformed_messages.append(new_message)
return transformed_messages
def _prepare_inputs_for_vllm(messages, processor):
"""Prepare inputs for vLLM inference"""
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs, video_kwargs = process_vision_info(
messages,
image_patch_size=processor.image_processor.patch_size,
return_video_kwargs=True,
return_video_metadata=True
)
mm_data = {}
if image_inputs is not None:
mm_data['image'] = image_inputs
if video_inputs is not None:
mm_data['video'] = video_inputs
return {
'prompt': text,
'multi_modal_data': mm_data,
'mm_processor_kwargs': video_kwargs
}
def _launch_demo(args, model_manager, model_configs):
"""启动演示界面"""
def call_local_model(messages):
"""调用当前加载的模型进行推理"""
messages = _transform_messages(messages)
if model_manager.current_backend == 'vllm':
# vLLM inference
inputs = _prepare_inputs_for_vllm(messages, model_manager.current_processor)
sampling_params = SamplingParams(max_tokens=1024, temperature=0.7, top_p=0.9)
accumulated_text = ''
for output in model_manager.current_model.generate(inputs, sampling_params=sampling_params):
for completion in output.outputs:
new_text = completion.text
if new_text:
accumulated_text += new_text
yield accumulated_text
else:
# HuggingFace inference
inputs = model_manager.current_processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
tokenizer = model_manager.current_processor.tokenizer
streamer = TextIteratorStreamer(tokenizer, timeout=20.0, skip_prompt=True, skip_special_tokens=True)
inputs = {k: v.to(model_manager.current_model.device) for k, v in inputs.items()}
gen_kwargs = {
'max_new_tokens': 1024,
'streamer': streamer,
'temperature': 0.7,
'top_p': 0.9,
**inputs
}
thread = Thread(target=model_manager.current_model.generate, kwargs=gen_kwargs)
thread.start()
generated_text = ''
for new_text in streamer:
generated_text += new_text
yield generated_text
def predict(_chatbot, task_history, current_model_name):
"""预测函数"""
chat_query = _chatbot[-1][0]
query = task_history[-1][0]
if len(chat_query) == 0:
_chatbot.pop()
task_history.pop()
return _chatbot, current_model_name
print(f'User ({current_model_name}): ' + _parse_text(query))
history_cp = copy.deepcopy(task_history)
full_response = ''
messages = []
content = []
for q, a in history_cp:
if isinstance(q, (tuple, list)):
if _is_video_file(q[0]):
content.append({'video': f'{os.path.abspath(q[0])}'})
else:
content.append({'image': f'{os.path.abspath(q[0])}'})
else:
content.append({'text': q})
messages.append({'role': 'user', 'content': content})
messages.append({'role': 'assistant', 'content': [{'text': a}]})
content = []
messages.pop()
for response in call_local_model(messages):
_chatbot[-1] = (_parse_text(chat_query), _remove_image_special(_parse_text(response)))
yield _chatbot, current_model_name
full_response = _parse_text(response)
task_history[-1] = (query, full_response)
print(f'Qwen-VL-Chat ({current_model_name}): ' + _parse_text(full_response))
yield _chatbot, current_model_name
def regenerate(_chatbot, task_history, current_model_name):
"""重新生成响应"""
if not task_history:
return _chatbot, current_model_name
item = task_history[-1]
if item[1] is None:
return _chatbot, current_model_name
task_history[-1] = (item[0], None)
chatbot_item = _chatbot.pop(-1)
if chatbot_item[0] is None:
_chatbot[-1] = (_chatbot[-1][0], None)
else:
_chatbot.append((chatbot_item[0], None))
_chatbot_gen = predict(_chatbot, task_history, current_model_name)
for _chatbot, current_model_name in _chatbot_gen:
yield _chatbot, current_model_name
def switch_model_handler(model_name, _chatbot, task_history):
"""切换模型处理器"""
try:
# 显示加载消息
loading_msg = f"正在切换到 {model_name} 模型..."
if _chatbot and len(_chatbot) > 0:
_chatbot[-1] = (_chatbot[-1][0], loading_msg)
else:
_chatbot.append(("", loading_msg))
yield _chatbot, model_name, gr.update(interactive=False), gr.update(interactive=False)
# 切换模型
model_manager.switch_model(model_name, model_configs)
# 清空聊天历史
task_history.clear()
_chatbot.clear()
# 显示成功消息
success_msg = f"已成功切换到 {model_name} 模型!"
_chatbot.append(("", success_msg))
yield _chatbot, model_name, gr.update(interactive=True), gr.update(interactive=True)
# 短暂显示后清空成功消息
import time
time.sleep(2)
_chatbot.clear()
yield _chatbot, model_name, gr.update(interactive=True), gr.update(interactive=True)
except Exception as e:
error_msg = f"切换模型失败: {str(e)}"
if _chatbot and len(_chatbot) > 0:
_chatbot[-1] = (_chatbot[-1][0], error_msg)
else:
_chatbot.append(("", error_msg))
yield _chatbot, model_name, gr.update(interactive=True), gr.update(interactive=True)
def add_text(history, task_history, text, current_model_name):
"""添加文本到对话"""
task_text = text
history = history if history is not None else []
task_history = task_history if task_history is not None else []
history = history + [(_parse_text(text), None)]
task_history = task_history + [(task_text, None)]
return history, task_history, '', current_model_name
def add_file(history, task_history, file, current_model_name):
"""添加文件到对话"""
history = history if history is not None else []
task_history = task_history if task_history is not None else []
history = history + [((file.name,), None)]
task_history = task_history + [((file.name,), None)]
return history, task_history, current_model_name
def reset_user_input():
return gr.update(value='')
def reset_state(_chatbot, task_history, current_model_name):
"""重置对话状态"""
task_history.clear()
_chatbot.clear()
# 清理GPU缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
gc.collect()
return [], current_model_name
# 创建模型配置
current_dir = os.path.dirname(os.path.abspath(__file__))
if not model_configs:
model_configs = {
"Qwen3-VL-4B-Instruct": {
"path": os.path.join(current_dir, "Qwen3-VL-4B-Instruct"),
"backend": "vllm",
"gpu_memory_utilization": 0.7, # 4B模型使用更保守的配置
"tensor_parallel_size": 1, # 4B模型单GPU运行
"max_model_len": 16384
},
"Qwen3-VL-8B-Instruct": {
"path": os.path.join(current_dir, "Qwen3-VL-8B-Instruct"),
"backend": "vllm",
"gpu_memory_utilization": 0.85,
"tensor_parallel_size": 2,
"max_model_len": 32768
}
}
# 根据命令行参数确定默认模型
if args.default_model == '4B':
default_model = "Qwen3-VL-4B-Instruct"
else:
default_model = "Qwen3-VL-8B-Instruct"
print(f"Starting with default model: {default_model}")
# 初始化默认模型
if default_model in model_configs and os.path.exists(model_configs[default_model]["path"]):
model_manager.load_model(default_model, model_configs[default_model]["path"])
else:
# 如果默认模型不存在,尝试加载第一个可用的模型
for model_name, config in model_configs.items():
if os.path.exists(config["path"]):
model_manager.load_model(model_name, config["path"])
default_model = model_name
break
with gr.Blocks() as demo:
gr.Markdown("""<center><font size=8>Qwen3-VL Multi-Model Demo</center>""")
gr.Markdown("""<center><font size=3>支持动态切换 4B 和 8B 模型</center>""")
# 模型选择下拉菜单 - 只显示存在的模型
available_models = []
for model_name, config in model_configs.items():
if os.path.exists(config["path"]):
available_models.append(model_name)
if not available_models:
raise ValueError("No valid models found. Please check your model paths.")
model_selector = gr.Dropdown(
choices=available_models,
value=default_model,
label="选择模型",
info="选择要使用的模型"
)
current_model_name = gr.State(value=default_model)
chatbot = gr.Chatbot(label='Qwen3-VL', elem_classes='control-height', height=500)
query = gr.Textbox(lines=2, label='输入')
task_history = gr.State([])
with gr.Row():
addfile_btn = gr.UploadButton('📁 上传文件', file_types=['image', 'video'])
submit_btn = gr.Button('🚀 发送', interactive=True)
regen_btn = gr.Button('🤔️ 重试', interactive=True)
empty_bin = gr.Button('🧹 清除历史')
# 模型切换事件
model_selector.change(
switch_model_handler,
[model_selector, chatbot, task_history],
[chatbot, current_model_name, submit_btn, regen_btn]
)
# 对话事件
submit_btn.click(
add_text,
[chatbot, task_history, query, current_model_name],
[chatbot, task_history, query, current_model_name]
).then(
predict,
[chatbot, task_history, current_model_name],
[chatbot, current_model_name]
)
submit_btn.click(reset_user_input, [], [query])
empty_bin.click(
reset_state,
[chatbot, task_history, current_model_name],
[chatbot, current_model_name]
)
regen_btn.click(
regenerate,
[chatbot, task_history, current_model_name],
[chatbot, current_model_name]
)
addfile_btn.upload(
add_file,
[chatbot, task_history, addfile_btn, current_model_name],
[chatbot, task_history, current_model_name]
)
gr.Markdown("""\
<font size=2>注意: 本演示受 Qwen3-VL 的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播有害内容。""")
demo.queue().launch(
share=args.share,
inbrowser=args.inbrowser,
server_port=args.server_port,
server_name=args.server_name,
)
def main():
args = _get_args()
# 初始化模型管理器
model_manager = ModelManager()
# 定义模型配置
current_dir = os.path.dirname(os.path.abspath(__file__))
model_configs = {
"Qwen3-VL-4B-Instruct": {
"path": os.path.join(current_dir, "Qwen3-VL-4B-Instruct"),
"backend": args.backend,
"gpu_memory_utilization": 0.7, # 4B模型使用更保守的配置
"tensor_parallel_size": 1, # 4B模型单GPU运行
"max_model_len": 16384,
"cpu_only": args.cpu_only,
"flash_attn2": args.flash_attn2
},
"Qwen3-VL-8B-Instruct": {
"path": os.path.join(current_dir, "Qwen3-VL-8B-Instruct"),
"backend": args.backend,
"gpu_memory_utilization": args.gpu_memory_utilization,
"tensor_parallel_size": args.tensor_parallel_size,
"max_model_len": args.max_model_len,
"cpu_only": args.cpu_only,
"flash_attn2": args.flash_attn2
}
}
# 启动演示
_launch_demo(args, model_manager, model_configs)
if __name__ == '__main__':
main()7.1 模型默认选择8B,如果需要指定4B模型需要运行如下命令
arduino
python web_demo_mm.py --default-model 4B8.访问界面
同过开放端口或者隧道工具访问界面