🚀 大模型DPO微调实战:让AI客服变身专业导购助手
相信很多做电商的朋友都遇到过这些问题:
- 🤖 通用AI太"万金油":什么都能聊,但专业性不够,客户问尺码搭配就懵了
- 📝 传统客服培训成本高:新人要学几个月才能独当一面,人员流动还大
- 🎯 用户需求很个性化:每个宝宝情况不同,需要量身定制的专业建议
我们的解决思路
用DPO强化学习让AI学会"什么是好的专业回答"
简单说就是:给AI看大量的"好回答VS差回答"对比,让它自己学会判断什么样的回答更专业、更贴心。
全流程技术闭环教学体系
- 从环境搭建(硬件配置/GPU管理)→本地部署推理→模型优化(量化/蒸馏)→垂直领域微调,形成完整技术链路
- 提供20+个LLM的部署方案,解决显存不足、算力优化等真实场景痛点,提供可直接复用的工程方案
🎯 项目目标很明确
核心要解决的问题
- 让AI变专业:从"随便答答"到"专家级建议"
- 让服务更贴心:考虑宝宝年龄、体型、季节、性格等个性化因素
- 让回答更安全:涉及儿童产品,安全标准和注意事项不能马虎
具体要实现的能力
- 🎯 精准尺码推荐:不再是"买大一码"的敷衍建议
- 🛡️ 安全知识普及:主动提及面料安全、设计安全等专业信息
- 🎨 个性化搭配:根据孩子特点推荐最合适的款式和颜色
- 💬 温暖的交流:像经验丰富的育儿专家一样耐心专业
🔧 技术实现路线
选择的技术栈
- LLaMA Factory:微调工具的"瑞士军刀",配置简单效果好
- DPO算法:比传统PPO更稳定,直接从偏好数据学习
- Qwen3-4B:中文表现优秀,资源消耗适中
实施步骤超级清晰
- 数据准备:生成150个专业儿童服装咨询问答
- 偏好数据构建:让专家评判哪个回答更好,构建训练数据
- 模型微调:用DPO算法让AI学会专业回答
- 效果对比:看看微调前后的差别有多明显
📊 预期效果
微调前的AI(通用回答)
"这个问题建议咨询专业客服..." "一般来说买大一码比较合适..."
微调后的AI(专业回答)
"根据您家宝宝的情况,建议选择90码。考虑到2岁幼儿正在快速发育期,这个码数既不会限制活动,也能穿到明年春季。另外这款面料通过了A类安全标准,宝宝贴身穿着很安全..."
🚀 项目价值
对业务的直接帮助
- 提升转化率:专业建议让客户更信任,下单更果断
- 降低售后:精准推荐减少尺码不合适的退换货
- 节省人力:AI处理90%常见咨询,人工专注复杂问题
技术上的收获
- 掌握最新DPO技术:强化学习在垂直领域的实战应用
- 完整项目经验:从数据准备到部署的全流程实践
- 可复制的方法论:这套方法可以迁移到其他垂直领域
1.llama_factory

LLaMA Factory 技术架构全貌
1 LLaMA Factory是什么?
简单理解:
diff
LLaMA Factory = 一个"大模型微调工厂"
就像汽车工厂:
- 原材料:各种预训练大模型(LLaMA、Qwen、ChatGLM等)
- 生产线:各种微调方法(SFT、DPO、PPO、ORPO等)
- 产品:定制化的AI助手
- 操作界面:Web UI + 命令行工具本质 :LLaMA Factory是一个高度集成的封装框架,它调用底层包来实现功能,同时提供了统一的界面和配置系统。
2 架构层次分析
┌─────────────────────────────────────┐
│ 用户界面层 │
│ Web UI + 命令行 + 配置文件 │
├─────────────────────────────────────┤
│ LLaMA Factory核心层 │
│ 统一接口 + 配置管理 + 工作流编排 │
├─────────────────────────────────────┤
│ 算法实现层 │
│ TRL + Transformers + 自定义算法 │
├─────────────────────────────────────┤
│ 计算优化层 │
│ DeepSpeed + Accelerate + PEFT │
├─────────────────────────────────────┤
│ 基础框架层 │
│ PyTorch + CUDA + 硬件驱动 │
└─────────────────────────────────────┘核心依赖包详细分析
1 主要依赖包清单
根据您项目中的安装记录和我的技术分析,LLaMA Factory的核心依赖包括:
基础深度学习框架
bash
torch==2.4.0 # PyTorch核心框架
torchvision==0.19.0 # 视觉相关(主要用于依赖)
torchaudio==2.4.0 # 音频相关(主要用于依赖)Hugging Face生态
python
transformers>=4.41.0 # 模型加载和基础微调
datasets>=2.16.0 # 数据处理和加载
tokenizers>=0.19.0 # 分词器
accelerate>=0.30.0 # 分布式训练加速
peft>=0.11.0 # 参数高效微调(LoRA等)🚀 强化学习专用包
python
trl>=0.8.0 # Transformers Reinforcement Learning
# 这是强化学习的核心包!!!⚡ 性能优化包
python
deepspeed==0.15.2 # 大模型训练优化
triton==3.0.0 # GPU计算优化
bitsandbytes # 量化训练
flash-attn # 注意力机制优化📊 辅助工具包
python
gradio # Web界面
wandb # 训练监控
numpy, pandas # 数据处理
matplotlib, seaborn # 可视化2 核心包的作用分析
TRL(Transformers Reinforcement Learning)- 最关键的包
这是LLaMA Factory强化学习功能的真正核心!
python
# TRL提供的核心功能
from trl import (
SFTTrainer, # 监督微调训练器
DPOTrainer, # DPO训练器
PPOTrainer, # PPO训练器
RewardTrainer, # 奖励模型训练器
AutoModelForCausalLMWithValueHead, # 带价值头的模型
)LLaMA Factory的DPO实现实际上是这样调用TRL的:
python
# 简化版的实现逻辑
from trl import DPOTrainer
from transformers import AutoModelForCausalLM, AutoTokenizer
# LLaMA Factory做的事情:
def train_dpo(config):
# 1. 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(config.model_path)
tokenizer = AutoTokenizer.from_pretrained(config.model_path)
# 2. 准备数据(这里是LLaMA Factory的核心价值)
train_dataset = process_dpo_dataset(config.data_path)
# 3. 配置DPO训练器(封装了复杂的配置)
trainer = DPOTrainer(
model=model,
ref_model=None, # 参考模型
beta=0.1, # DPO温度参数
train_dataset=train_dataset,
tokenizer=tokenizer,
max_length=2048,
# ... 更多配置参数
)
# 4. 开始训练
trainer.train()
# 5. 保存模型
trainer.save_model(config.output_dir)LLaMA Factory的强化学习实现原理
1 并非重新发明轮子
核心发现 :LLaMA Factory没有重新实现强化学习算法,而是:
- 调用TRL库实现核心算法
- 封装配置管理让使用更简单
- 提供数据处理统一数据格式
- 集成优化工具提升训练效率
- 开发用户界面降低使用门槛
2 具体实现方式分析
DPO训练的完整调用链
python
# 用户操作
llamafactory-cli train --config dpo_config.yaml
# ↓ LLaMA Factory内部处理
def main():
# 1. 解析配置文件
config = parse_yaml_config("dpo_config.yaml")
# 2. 数据预处理(LLaMA Factory的核心价值)
dataset = load_and_process_dataset(
dataset_name=config.dataset,
data_format="dpo", # 自动处理DPO格式
template=config.template # 对话模板处理
)
# 3. 模型加载(支持多种模型)
model, tokenizer = load_model_and_tokenizer(
model_path=config.model_path,
model_type="auto", # 自动识别模型类型
finetuning_type="lora" # 支持LoRA等高效微调
)
# 4. 调用TRL进行实际训练
from trl import DPOTrainer
trainer = DPOTrainer(
model=model,
train_dataset=dataset,
**convert_config_to_trl_args(config) # 配置转换
)
# 5. 启动训练
trainer.train()
# ↓ 实际执行的是TRL的代码
# TRL内部实现了真正的DPO算法3 LLaMA Factory的核心价值
✅ 配置管理的价值
原始TRL使用(复杂):
python
from trl import DPOTrainer
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
import torch
# 需要手动配置所有参数
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer.pad_token = tokenizer.eos_token
# 复杂的训练参数配置
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
warmup_steps=100,
logging_steps=10,
save_steps=500,
learning_rate=5e-5,
fp16=True,
remove_unused_columns=False,
run_name="dpo-llama2",
)
# 手动创建DPO训练器
trainer = DPOTrainer(
model=model,
ref_model=None,
args=training_args,
beta=0.1,
train_dataset=train_dataset,
tokenizer=tokenizer,
max_length=512,
max_target_length=512,
max_prompt_length=512,
)
trainer.train()LLaMA Factory使用(简单):
yaml
# config.yaml
model_name_or_path: meta-llama/Llama-2-7b-hf
stage: dpo
dataset: dpo_dataset
finetuning_type: lora
lora_rank: 8
learning_rate: 5e-5
num_train_epochs: 3
per_device_train_batch_size: 2
gradient_accumulation_steps: 8
bash
# 一行命令搞定
llamafactory-cli train --config config.yaml数据处理的价值
原始数据格式:
json
{
"question": "孩子1岁半岁,冬天去山区旅游...",
"answer_A": "作为专业的儿童服装顾问...",
"answer_B": "1岁半岁宝宝山区冬游的家居服...",
"best_answer": ""
}LLaMA Factory自动转换为TRL需要的格式:
python
# LLaMA Factory内部转换
{
"prompt": "孩子1岁半岁,冬天去山区旅游...",
"chosen": "1岁半岁宝宝山区冬游的家居服...", # 更好的回答
"rejected": "作为专业的儿童服装顾问..." # 较差的回答
}如果直接用TRL,需要手动写代码进行这种转换!
✅ 模型集成的价值
支持多种模型类型:
python
# LLaMA Factory内部有模型适配层
SUPPORTED_MODELS = {
"llama": LlamaAdapter,
"qwen": QwenAdapter, # 您用的是这个
"chatglm": ChatGLMAdapter,
"baichuan": BaichuanAdapter,
# ... 更多模型
}
# 自动选择合适的适配器
def get_model_adapter(model_name):
if "qwen" in model_name.lower():
return QwenAdapter()
elif "llama" in model_name.lower():
return LlamaAdapter()
# ...LLaMA Factory vs 直接使用TRL
1 技术实现对比
| 维度 | 直接使用TRL | 使用LLaMA Factory |
|---|---|---|
| 算法实现 | 原生TRL实现 | 调用TRL实现(相同) |
| 配置复杂度 | 需要手写大量代码 | 配置文件搞定 |
| 数据处理 | 需要自己写转换代码 | 自动处理多种格式 |
| 模型支持 | 需要手动适配 | 支持主流模型 |
| 界面操作 | 纯代码 | Web界面 + 命令行 |
| 错误处理 | 需要自己调试 | 集成错误诊断 |
| 性能优化 | 需要手动配置 | 内置最佳实践 |
2 本质关系
ini
LLaMA Factory = TRL + 配置管理 + 数据处理 + 界面封装 + 最佳实践
就像:
- TRL = 汽车发动机(核心动力)
- LLaMA Factory = 整辆汽车(完整产品)
- 方向盘(Web界面)
- 仪表盘(监控面板)
- 自动挡(配置管理)
- GPS导航(最佳实践指导)2.llama_factory支持的数据结构
dataset_info.json 包含了所有经过预处理的 本地数据集 以及 在线数据集。如果希望使用自定义数据集,务必在 dataset_info.json 文件中添加对数据集及其内容的定义。
目前支持 Alpaca 格式和 ShareGPT 格式的数据集。
Alpaca
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。下面是一个例子
json
"alpaca_zh_demo.json"
{
"instruction": "计算这些物品的总费用。 ",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},在进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput。而 output 列对应的内容为模型回答。 在上面的例子中,人类的最终输入是:
json
计算这些物品的总费用。
输入:汽车 - $3000,衣服 - $100,书 - $20。模型的回答是:
json
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
指令监督微调数据集 格式要求 如下:
json
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
json
[
{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
[
"今天会下雨吗?",
"今天不会下雨,是个好天气。"
],
[
"今天适合出去玩吗?",
"非常适合,空气质量很好。"
]
]
}
]对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
json
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}偏好数据集
偏好数据集用于奖励模型训练、DPO 训练和 ORPO 训练。对于系统指令和人类输入,偏好数据集给出了一个更优的回答和一个更差的回答。
一些研究 表明通过让模型学习"什么更好"可以使得模型更加迎合人类的需求。 甚至可以使得参数相对较少的模型的表现优于参数更多的模型。
偏好数据集需要在 chosen 列中提供更优的回答,并在 rejected 列中提供更差的回答,在一轮问答中其格式如下
json
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"chosen": "优质回答(必填)",
"rejected": "劣质回答(必填)"
}
]
json
"数据集名称": {
"file_name": "data.json",
"ranking": true,
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}3.安装llama_factory 准备数据
bash
conda create --name llama_factory python=3.11
conda init
source ~/.bashrc
conda activate llama_factory
json
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation
清理(如果需要)
pip uninstall -y torch torchvision torchaudio bitsandbytes triton deepspeed
安装与 CUDA 12.1 匹配的 PyTorch
pip install --index-url download.pytorch.org/whl/cu121
"torch==2.4.0" "torchvision==0.19.0" "torchaudio==2.4.0"
安装匹配版本
pip install "triton==3.0.0" "deepspeed==0.15.2" pip3 install deepspeed==0.15.2
界面化启动
注意启动路径
启动后直接访问http://127.0.0.1:7860/
加入 社区 : 0元领取源码,攻克LLM工业级全栈技术开发!10+工业级方案
4.配置数据
基础数据准备
python
import json
import random
import time
from openai import OpenAI
from concurrent.futures import ThreadPoolExecutor
# 配置
API_KEY = "sk-0f9c12d7b6798t789b19b6eb78d4a7"
client = OpenAI(api_key=API_KEY, base_url="https://api.deepseek.com")
# 儿童服装专业场景(容易出微调效果的)
question_templates = {
"专业尺码建议": [
"我家宝宝{age}个月,{height}cm,{weight}斤,现在是{season},这件{item}选什么码合适?会不会买大了?",
"孩子{age}岁,比同龄人{size_diff}一些,平时{brand}牌子穿{size}码,你们家这件{item}建议选什么码?",
"双胞胎宝宝,一个{weight1}斤一个{weight2}斤,都{age}岁,这款{item}怎么选码?",
],
"儿童安全专业知识": [
"这件{item}的拉链是什么材质?会不会划伤宝宝皮肤?有没有防夹设计?",
"宝宝{age}个月,正在长牙期,这件衣服的纽扣会不会被咬掉?安全吗?",
"孩子有异位性皮炎,这个面料的pH值是多少?会刺激皮肤吗?",
"这件{item}符合GB31701-2015标准吗?甲醛含量多少?",
],
"儿童行为习惯匹配": [
"我家宝宝{age}岁,特别爱在地上爬,这件{item}耐脏吗?膝盖部分会不会很快磨破?",
"孩子{age}岁,还不会自己上厕所,这件{item}方便脱吗?松紧带会不会勒肚子?",
"宝宝{age}个月,正在学走路,经常摔倒,这件{item}的面料厚度够保护吗?",
"孩子特别好动,上蹿下跳的,这件{item}的接缝结实吗?会不会开线?",
],
"季节性专业搭配": [
"现在{season},温度{temp}度,孩子{age}岁,这件{item}里面需要穿什么?怎么搭配不会热?",
"马上要{next_season}了,这件{item}能穿到什么时候?需要买大一码为明年准备吗?",
"孩子{age}岁,{season}去{place}旅游,这套{item}搭配合适吗?需要带什么备用衣服?",
],
"儿童心理与偏好": [
"我家{gender}宝{age}岁,特别喜欢{character},不喜欢{dislike},这件{item}的设计孩子会喜欢吗?",
"孩子{age}岁,刚上幼儿园,比较内向,这件{item}的颜色会不会太{color_type}?",
"宝宝{age}个月,对声音很敏感,这件{item}的装饰会不会有声音?会影响睡觉吗?",
]
}
# 专业变量池(更具体、更专业)
variables = {
"age": ["6个月", "10个月", "1岁", "1岁半", "2岁", "3岁", "4岁", "5岁"],
"height": ["70", "75", "80", "85", "90", "95", "100", "105", "110"],
"weight": ["16", "18", "20", "22", "24", "26", "28", "30", "32"],
"season": ["春天", "夏天", "秋天", "冬天", "换季"],
"next_season": ["夏天", "秋天", "冬天", "春天"],
"item": ["连体衣", "分体睡衣", "外出服", "家居服", "防踢被", "爬服"],
"size_diff": ["偏瘦", "偏胖", "偏高", "偏矮"],
"brand": ["优衣库", "Gap", "Zara", "HM", "Carter's"],
"size": ["80", "90", "100", "110", "120"],
"weight1": ["20", "22", "24"],
"weight2": ["18", "21", "23"],
"temp": ["15-20", "20-25", "25-30", "10-15"],
"place": ["海边", "山区", "北方", "南方", "国外"],
"gender": ["男", "女"],
"character": ["小猪佩奇", "汪汪队", "冰雪奇缘", "超级飞侠"],
"dislike": ["太花哨的图案", "硬质装饰", "紧身设计"],
"color_type": ["鲜艳", "暗淡", "成熟"]
}
def generate_question():
category = random.choice(list(question_templates.keys()))
template = random.choice(question_templates[category])
question = template
for var, values in variables.items():
if f"{{{var}}}" in question:
question = question.replace(f"{{{var}}}", random.choice(values))
return question, category
def batch_generate_response(questions_batch):
# 针对不同类别使用专业的system prompt
system_prompts = {
"专业尺码建议": "你是资深的儿童服装尺码专家,有10年经验。要考虑儿童生长发育特点、季节因素、品牌差异,给出精准的尺码建议和理由。",
"儿童安全专业知识": "你是儿童用品安全专家,熟悉国标GB31701-2015,了解各种材质和工艺的安全性,要给出专业的安全评估。",
"儿童行为习惯匹配": "你是儿童发展心理学专家,了解各年龄段儿童的行为特点和生理需求,能根据孩子习惯推荐合适的服装功能。",
"季节性专业搭配": "你是儿童服装搭配师,精通不同季节、地区、温度下的儿童穿搭,能给出实用的搭配方案。",
"儿童心理与偏好": "你是儿童心理专家,了解不同年龄段孩子的心理特点和审美偏好,能推荐符合儿童心理需求的服装。"
}
combined_prompt = "请为以下专业的儿童服装咨询问题分别给出详细专业的回答,体现你的专业知识和经验,每个回答用\"---\"分隔:\n\n"
categories = []
for i, (question, category) in enumerate(questions_batch, 1):
combined_prompt += f"{i}. {question}\n"
categories.append(category)
# 使用第一个问题的类别作为主要专业方向
main_category = categories[0]
try:
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompts[main_category]},
{"role": "user", "content": combined_prompt}
],
temperature=0.7,
max_tokens=2000
)
full_response = response.choices[0].message.content.strip()
answers = full_response.split("---")
cleaned_answers = []
for answer in answers:
cleaned = answer.strip()
if cleaned.startswith(("1.", "2.", "3.", "4.", "5.")):
cleaned = cleaned[2:].strip()
cleaned_answers.append(cleaned)
return cleaned_answers[:len(questions_batch)]
except Exception as e:
print(f"批量API调用失败: {e}")
return [f"抱歉,这个问题比较专业,建议您联系我们的儿童服装专家客服获得详细解答。" for _ in questions_batch]
# 其余代码保持不变...
def process_batch(batch_questions):
answers = batch_generate_response(batch_questions)
results = []
for (question, category), answer in zip(batch_questions, answers):
sample = {
"instruction": "作为专业的儿童服装顾问,请根据儿童发育特点、安全标准、行为习惯等专业知识回答问题。",
"input": question,
"output": answer
}
results.append(sample)
return results
# 生成数据的代码保持不变...
print("生成专业儿童服装问题中...")
all_questions = []
used_questions = set()
while len(all_questions) < 150:
question, category = generate_question()
if question not in used_questions:
used_questions.add(question)
all_questions.append((question, category))
print(f"生成了{len(all_questions)}个专业问题")
# 批量处理
print("开始批量生成专业回答...")
batch_size = 5 # 专业问题复杂,减少批次大小
all_data = []
with ThreadPoolExecutor(max_workers=2) as executor:
futures = []
for i in range(0, len(all_questions), batch_size):
batch = all_questions[i:i+batch_size]
future = executor.submit(process_batch, batch)
futures.append(future)
for i, future in enumerate(futures):
try:
batch_results = future.result(timeout=45)
all_data.extend(batch_results)
print(f"完成批次 {i+1}/{len(futures)}, 已生成 {len(all_data)} 条专业数据")
except Exception as e:
print(f"批次 {i+1} 处理失败: {e}")
time.sleep(0.5)
print("专业数据生成完成!")
# 保存文件
random.shuffle(all_data)
train_data = all_data[:130]
test_data = all_data[130:150]
with open('train.jsonl', 'w', encoding='utf-8') as f:
for item in train_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
with open('test.jsonl', 'w', encoding='utf-8') as f:
for item in test_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"训练集: train.jsonl ({len(train_data)}条)")
print(f"测试集: test.jsonl ({len(test_data)}条)")DPO数据处理
python
import json
import requests
import time
from typing import Dict, List, Optional
import os
from tqdm import tqdm
class DPODataConverter:
def __init__(self, api_key: str):
"""
初始化 DPO 数据转换器
Args:
api_key: DeepSeek API 密钥
"""
self.api_key = api_key
self.base_url = "https://api.deepseek.com/v1/chat/completions"
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# 儿童服装客服评价规约
self.evaluation_prompt = """
你是专业的儿童服装客服质量评估专家。请评估以下客服回答的质量,重点关注:
1. 儿童友好性:语气温和、不恐吓、适合家长交流
2. 安全合规性:是否提及A类标准、过敏提示、安全注意事项
3. 专业准确性:尺码建议、面料选择、发育特点考虑是否合理
4. 服务完整性:是否包含澄清需求→专业建议→理由说明→后续引导的完整链路
5. 禁词合规:无夸大承诺、无医疗功效宣传、无不当营销
请判断这个回答是否足够优质。如果不够好,请生成一个更优质的回答。
原问题:{question}
原回答:{answer}
请严格按照以下JSON格式输出(不要包含任何其他文字):
{{
"is_good": true/false,
"reason": "评价理由",
"improved_answer": "改进后的回答(仅在is_good为false时提供)"
}}
"""
def call_deepseek_api(self, prompt: str, max_retries: int = 3) -> Optional[Dict]:
"""
调用 DeepSeek API
Args:
prompt: 输入提示
max_retries: 最大重试次数
Returns:
API 响应结果
"""
for attempt in range(max_retries):
try:
payload = {
"model": "deepseek-chat",
"messages": [
{
"role": "user",
"content": prompt
}
],
"temperature": 0.1, # 低温度保证稳定输出
"max_tokens": 2048
}
response = requests.post(
self.base_url,
headers=self.headers,
json=payload,
timeout=30
)
if response.status_code == 200:
result = response.json()
return result["choices"][0]["message"]["content"]
else:
print(f"API 调用失败,状态码:{response.status_code}")
print(f"错误信息:{response.text}")
except Exception as e:
print(f"第 {attempt + 1} 次调用失败:{str(e)}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指数退避
return None
def evaluate_answer(self, question: str, answer: str) -> Optional[Dict]:
"""
评估答案质量并生成改进版本
Args:
question: 用户问题
answer: 原始答案
Returns:
评估结果
"""
prompt = self.evaluation_prompt.format(question=question, answer=answer)
response = self.call_deepseek_api(prompt)
if not response:
return None
try:
# 清理响应,移除可能的markdown格式
clean_response = response.strip()
if clean_response.startswith("```json"):
clean_response = clean_response[7:]
if clean_response.endswith("```"):
clean_response = clean_response[:-3]
clean_response = clean_response.strip()
evaluation = json.loads(clean_response)
return evaluation
except json.JSONDecodeError as e:
print(f"JSON 解析失败:{str(e)}")
print(f"原始响应:{response}")
return None
def convert_to_dpo_format(self, input_file: str, output_file: str, max_samples: int = None):
"""
将 SFT 数据转换为 DPO 偏好数据格式
Args:
input_file: 输入的 SFT 数据文件路径
output_file: 输出的 DPO 数据文件路径
max_samples: 最大处理样本数(用于测试)
"""
dpo_data = []
processed_count = 0
success_count = 0
print(f"开始处理数据文件:{input_file}")
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 限制处理数量(测试时使用)
if max_samples:
lines = lines[:max_samples]
for line in tqdm(lines, desc="转换数据"):
try:
data = json.loads(line.strip())
# 提取原始数据
instruction = data.get("instruction", "")
input_text = data.get("input", "")
output_text = data.get("output", "")
# 构建完整问题
if input_text:
full_question = f"{instruction}\n\n{input_text}"
else:
full_question = instruction
# 评估答案质量
evaluation = self.evaluate_answer(input_text or instruction, output_text)
if evaluation:
if evaluation.get("is_good", False):
# 原答案质量好,作为 chosen,需要构造一个较差的 rejected
# 这里我们简化处理,生成一个通用的较差回答
rejected_answer = self._generate_poor_answer(input_text or instruction)
dpo_item = {
"instruction": instruction,
"input": input_text,
"chosen": output_text,
"rejected": rejected_answer
}
else:
# 原答案质量不好,作为 rejected,用改进版本作为 chosen
improved_answer = evaluation.get("improved_answer", "")
if improved_answer:
dpo_item = {
"instruction": instruction,
"input": input_text,
"chosen": improved_answer,
"rejected": output_text
}
else:
print(f"未能生成改进答案,跳过此样本")
continue
dpo_data.append(dpo_item)
success_count += 1
# 实时保存进度
if success_count % 10 == 0:
self._save_progress(dpo_data, output_file)
else:
print(f"评估失败,跳过样本:{input_text[:50]}...")
processed_count += 1
# API 调用限流
time.sleep(0.5)
except Exception as e:
print(f"处理样本时出错:{str(e)}")
continue
# 最终保存
self._save_progress(dpo_data, output_file)
print(f"\n转换完成!")
print(f"处理样本数:{processed_count}")
print(f"成功转换数:{success_count}")
print(f"输出文件:{output_file}")
def _generate_poor_answer(self, question: str) -> str:
"""
为质量好的答案生成一个较差的对比版本
"""
poor_templates = [
"这个问题很简单,随便买就行了。",
"不用想太多,贵的就是好的。",
"买大一码总是对的,孩子长得快。",
"这种问题网上搜一下就知道了。",
"我们的产品都很好,闭眼买就行。"
]
# 根据问题类型选择合适的差答案模板
import random
return random.choice(poor_templates)
def _save_progress(self, data: List[Dict], output_file: str):
"""保存进度到文件"""
with open(output_file, 'w', encoding='utf-8') as f:
for item in data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
def validate_dpo_format(self, file_path: str) -> bool:
"""
验证生成的 DPO 数据格式是否正确
Args:
file_path: DPO 数据文件路径
Returns:
格式是否正确
"""
required_fields = ["instruction", "input", "chosen", "rejected"]
try:
with open(file_path, 'r', encoding='utf-8') as f:
for i, line in enumerate(f, 1):
data = json.loads(line.strip())
# 检查必需字段
for field in required_fields:
if field not in data:
print(f"第 {i} 行缺少字段:{field}")
return False
# 检查 chosen 和 rejected 不能相同
if data["chosen"] == data["rejected"]:
print(f"第 {i} 行 chosen 和 rejected 内容相同")
return False
print("DPO 数据格式验证通过!")
return True
except Exception as e:
print(f"验证时出错:{str(e)}")
return False
# 使用示例
def main():
# 配置参数
API_KEY = "sk-0f9c1vc6f798g7f6vud8ceb78d4a7"
INPUT_FILE = "./train.jsonl" # 你的原始 SFT 数据文件
OUTPUT_FILE = "dpo_preference_data.jsonl" # 输出的 DPO 偏好数据
# 创建转换器
converter = DPODataConverter(api_key=API_KEY)
# 先处理少量样本测试
print("开始测试转换(前5个样本)...")
converter.convert_to_dpo_format(
input_file=INPUT_FILE,
output_file="test_" + OUTPUT_FILE,
max_samples=5
)
# 验证测试结果
if converter.validate_dpo_format("test_" + OUTPUT_FILE):
print("\n测试成功!开始处理完整数据集...")
# 处理完整数据集
converter.convert_to_dpo_format(
input_file=INPUT_FILE,
output_file=OUTPUT_FILE
)
# 最终验证
converter.validate_dpo_format(OUTPUT_FILE)
print(f"\n✅ 数据转换完成!")
print(f"输出文件:{OUTPUT_FILE}")
print(f"格式:LLaMA Factory DPO 偏好数据格式")
else:
print("❌ 测试失败,请检查 API 配置或数据格式")
if __name__ == "__main__":
main()
加入 社区 : 0元领取源码,攻克LLM工业级全栈技术开发!10+工业级方案
数据注册
bash
vim autodl-tmp/LLaMA-Factory/data/dataset_info.json
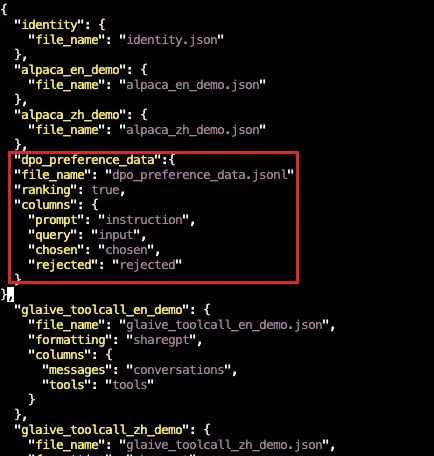
"dpo_preference_data":{
"file_name": "dpo_preference_data.jsonl",
"ranking": true,
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}
界面数据查看


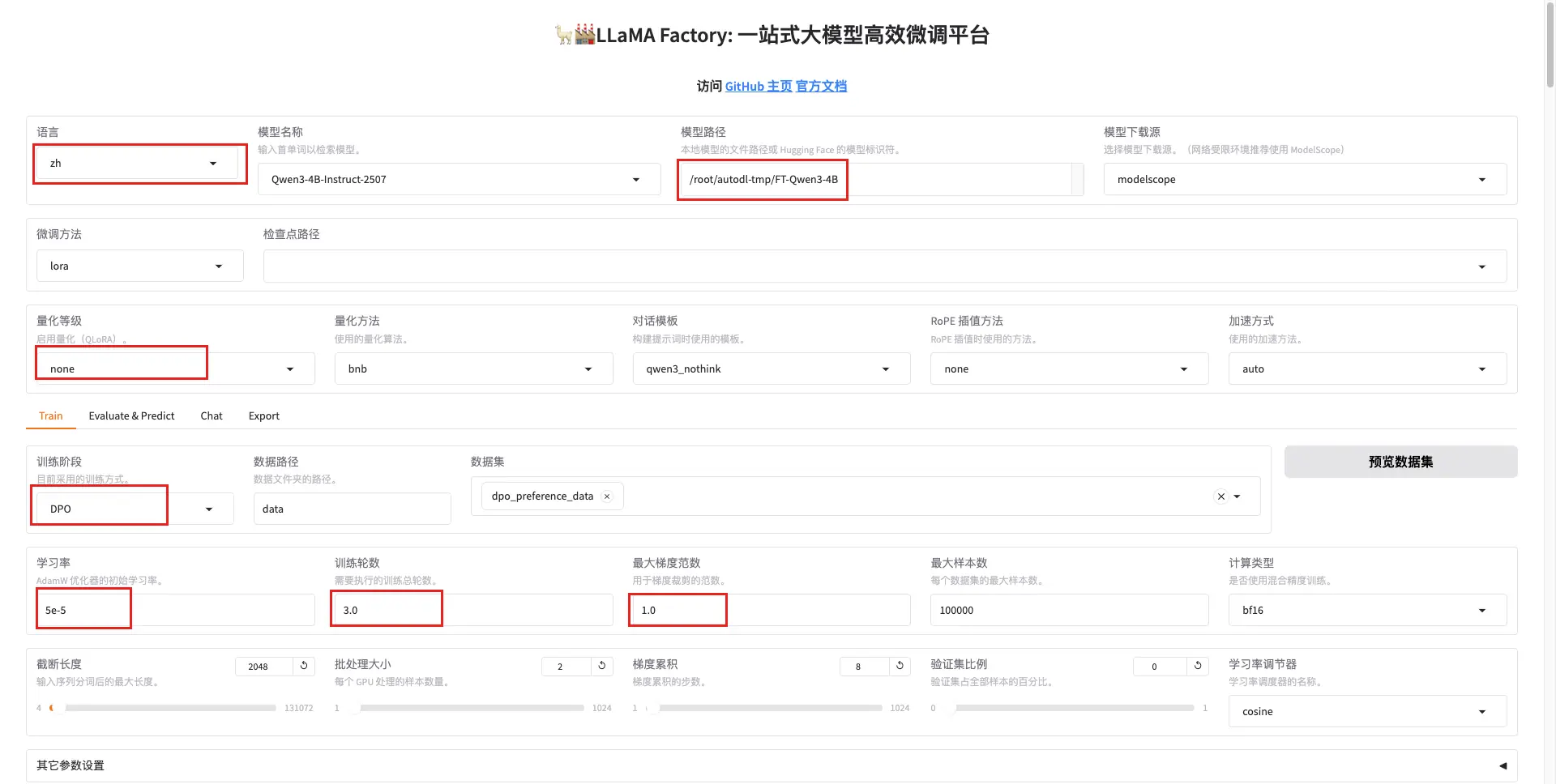
5.界面化调参配置
选参配置
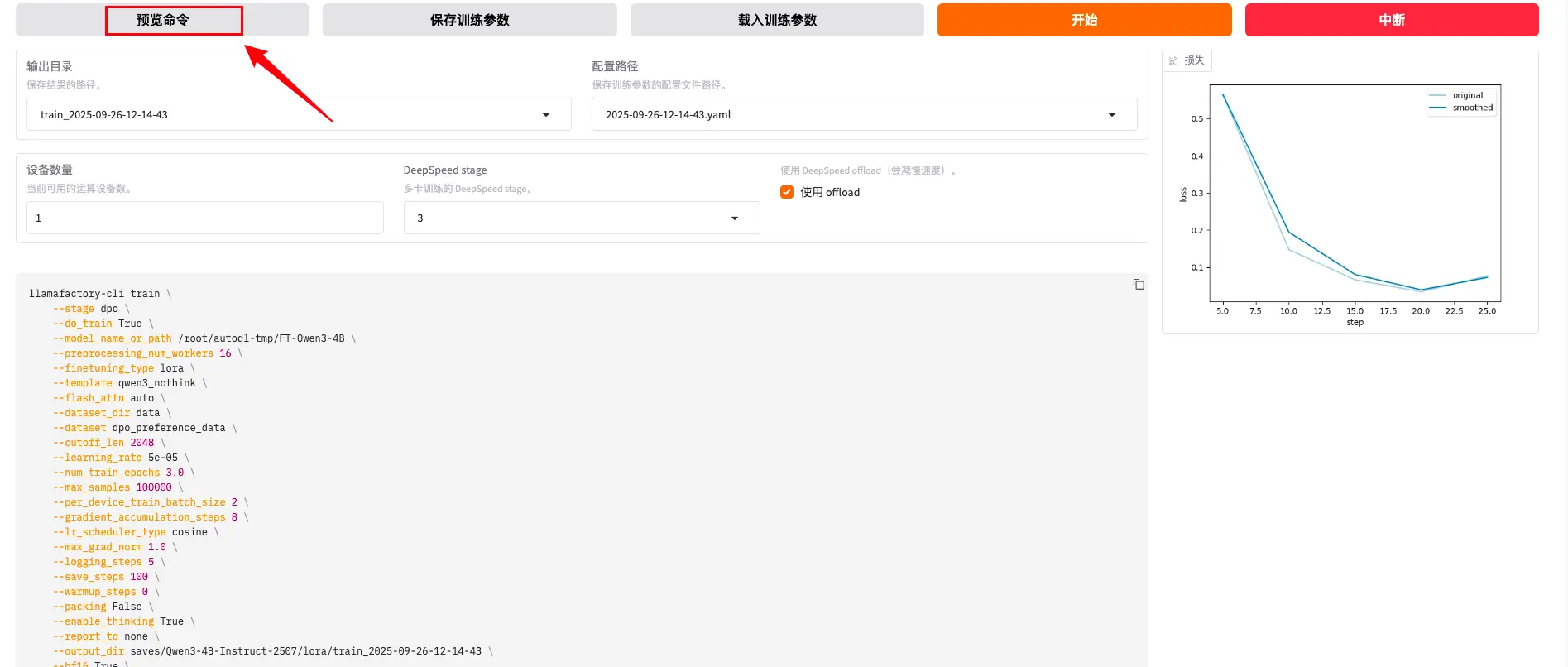
命令预览
命令详解
基础训练配置
训练阶段和模式
--stage dpo- 训练阶段:使用DPO(Direct Preference Optimization)偏好优化算法--do_train True- 启用训练模式:开始训练过程--model_name_or_path /root/autodl-tmp/FT-Qwen3-4B- 基础模型路径:使用预训练或已微调的Qwen3-4B模型
微调方法配置
--finetuning_type lora- 微调类型:使用LoRA(Low-Rank Adaptation)高效微调--template qwen3_nothink- 对话模板:使用Qwen3的无思考链模板格式--flash_attn auto- Flash Attention:自动启用Flash Attention加速注意力计算
数据处理参数
数据配置
--dataset_dir data- 数据集目录:数据文件存放在data文件夹--dataset dpo_preference_data- 数据集名称:使用DPO偏好数据集--cutoff_len 2048- 最大序列长度:截断超过2048个token的输入--max_samples 100000- 最大样本数:最多使用10万个训练样本--preprocessing_num_workers 16- 数据预处理工作进程数:使用16个进程并行处理数据
批处理配置
--per_device_train_batch_size 2- 每设备批大小:每个GPU处理2个样本--gradient_accumulation_steps 8- 梯度累积步数:累积8步后更新参数--packing False- 序列打包:不启用序列打包(保持原始序列结构)
训练超参数
学习率配置
--learning_rate 5e-05- 学习率:5×10⁻⁵,相对保守的学习率--lr_scheduler_type cosine- 学习率调度器:使用余弦退火调度--warmup_steps 0- 预热步数:不使用学习率预热
训练轮次和正则化
--num_train_epochs 3.0- 训练轮次:完整训练3个epoch--max_grad_norm 1.0- 梯度裁剪:限制梯度范数最大为1.0防止梯度爆炸--optim adamw_torch- 优化器:使用AdamW优化器的PyTorch实现
LoRA结构参数
--lora_rank 8- LoRA秩:低秩分解的秩为8,控制参数量--lora_alpha 16- LoRA缩放因子:alpha/rank=2,控制LoRA权重的缩放--lora_dropout 0- LoRA Dropout:不使用dropout--lora_target all- LoRA目标层:对所有可训练层应用LoRA
DPO特定参数
偏好优化配置
--pref_beta 0.1- DPO温度参数:控制偏好强度,0.1是常用值--pref_ftx 0- SFT损失权重:不混合SFT损失,纯DPO训练--pref_loss sigmoid- 偏好损失函数:使用sigmoid损失函数
系统和性能配置
计算精度和加速
--bf16 True- BFloat16精度:使用混合精度训练节省显存--deepspeed cache/ds_z3_offload_config.json- DeepSpeed配置:使用ZeRO-3显存优化--ddp_timeout 180000000- 分布式训练超时:设置极长超时时间
日志和保存
--logging_steps 5- 日志记录间隔:每5步记录一次训练指标--save_steps 100- 保存间隔:每100步保存一次检查点--plot_loss True- 绘制损失曲线:自动生成训练损失图表--report_to none- 日志上报:不向外部服务上报训练指标
其他配置
--enable_thinking True- 启用思考模式:可能与推理链相关的特殊模式--trust_remote_code True- 信任远程代码:允许执行模型中的自定义代码--include_num_input_tokens_seen True- 包含token统计:在日志中显示处理的token数量
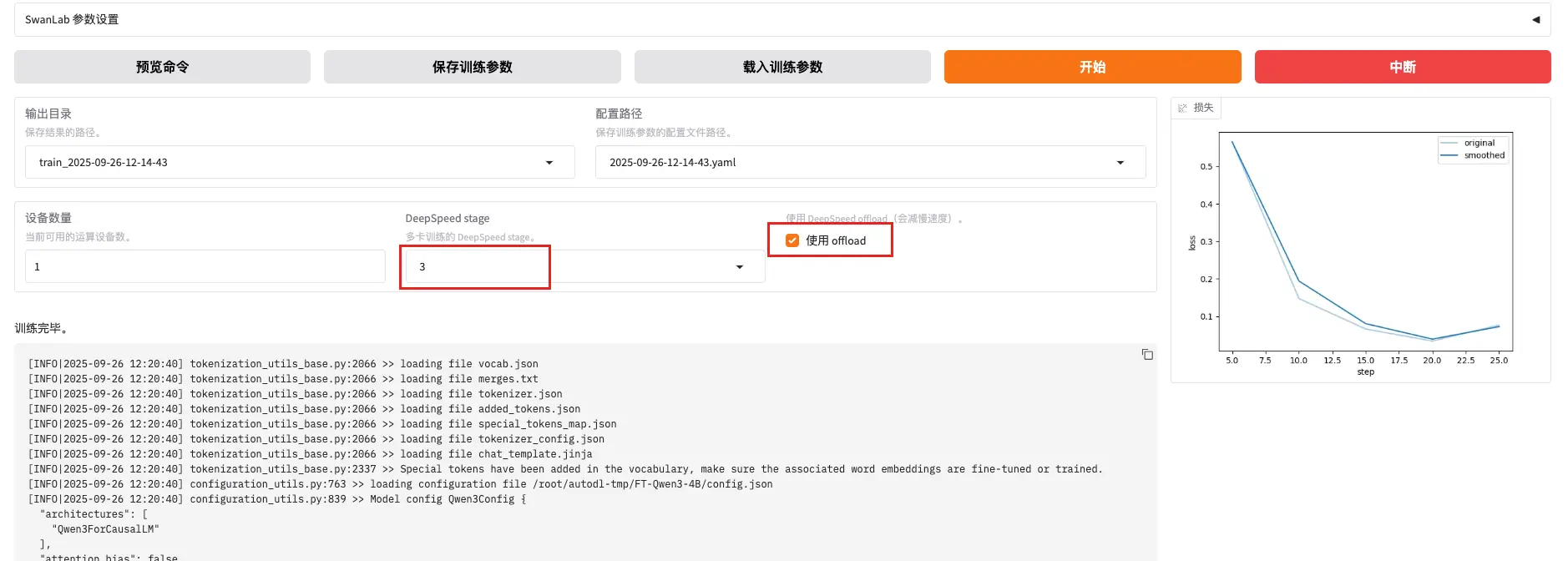
结果查看
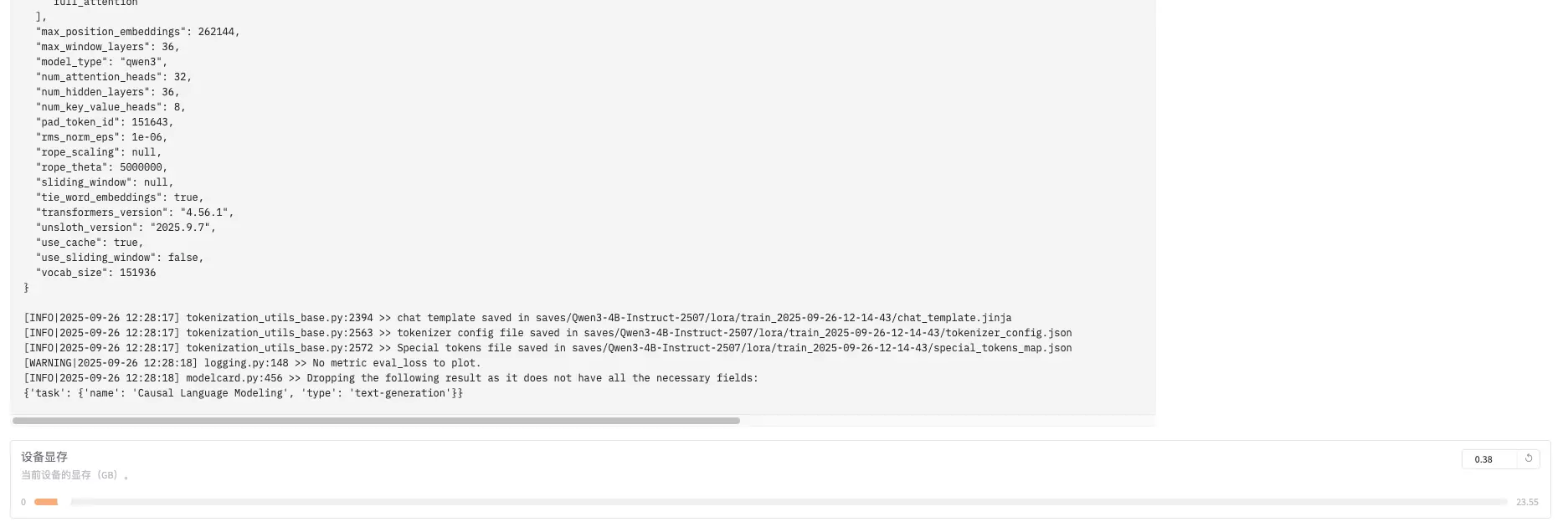
模型架构参数
基础标识参数
"model_type": "qwen3"- 模型类型,表示这是Qwen3系列模型"transformers_version": "4.56.1"- 使用的Transformers库版本"unsloth_version": "2025.9.7"- 使用的Unsloth加速库版本
核心架构参数
"num_hidden_layers": 36- 隐藏层数量,决定模型深度,36层表示这是一个相当深的模型"num_attention_heads": 32- 注意力头数量,多头注意力机制中的头数"num_key_value_heads": 8- 键值对头数量,用于分组查询注意力(GQA),比注意力头数少,提高效率"vocab_size": 151936- 词汇表大小,模型可以处理的不同token数量
位置编码参数
"max_position_embeddings": 262144- 最大位置嵌入长度,模型能处理的最大序列长度(约26万tokens)"rope_theta": 5000000- RoPE旋转位置编码的基频参数,影响位置编码的周期性"rope_scaling": null- RoPE缩放策略,null表示不使用缩放
滑动窗口注意力参数
"max_window_layers": 36- 使用滑动窗口的最大层数"sliding_window": null- 滑动窗口大小,null表示不使用滑动窗口"use_sliding_window": false- 是否启用滑动窗口机制
规范化和数值稳定性
"rms_norm_eps": 1e-06- RMS归一化的epsilon值,防止除零错误,确保数值稳定性
特殊token和缓存
"pad_token_id": 151643- 填充token的ID,用于批处理时对齐序列长度"tie_word_embeddings": true- 是否共享输入输出嵌入权重,节省参数量"use_cache": true- 是否使用KV缓存,加速推理过程
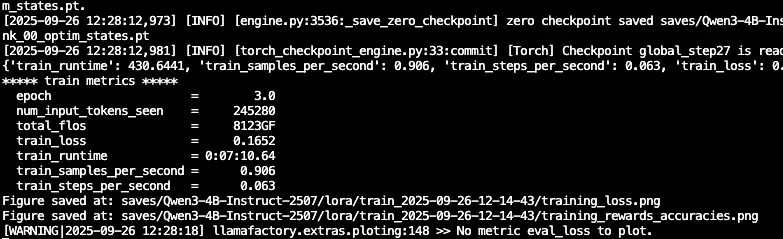
结论详解
检查点保存信息
bash
zero checkpoint saved saves/Qwen3-4B-Instruct-2507/lora/train_2025-09-26-12-14-43/- 模型训练检查点已保存
- 使用的是LoRA微调方法
- 基础模型:Qwen3-4B-Instruct-2507
- 保存时间:2025-09-26 12:14:43
核心训练指标解析
训练进度指标
epoch = 3.0- 当前训练轮次:已完成3个完整的数据遍历train_runtime = 0:07:10.64- 总训练时间:7分10.64秒
性能效率指标
train_samples_per_second = 0.906- 每秒处理样本数:0.906个样本/秒train_steps_per_second = 0.063- 每秒训练步数:0.063步/秒
数据处理指标
num_input_tokens_seen = 245200- 已处理的输入token总数:约24.5万个tokentotal_flos = 8123GF- 总浮点运算次数:8123 GigaFLOPs
损失函数
train_loss = 0.1652- 训练损失:0.1652,这是一个相对较低的值,表明模型学习效果良好
可视化输出
bash
Figure saved at: saves/Qwen3-4B-Instruct-2507/lora/train_2025-09-26-12-14-43/training_loss.png
Figure saved at: saves/Qwen3-4B-Instruct-2507/lora/train_2025-09-26-12-14-43/training_loss_vs_lr_accuracies.png- 系统自动生成了训练损失曲线图
- 生成了损失与学习率/准确率对比图
- 这些图表帮助分析训练过程和模型性能
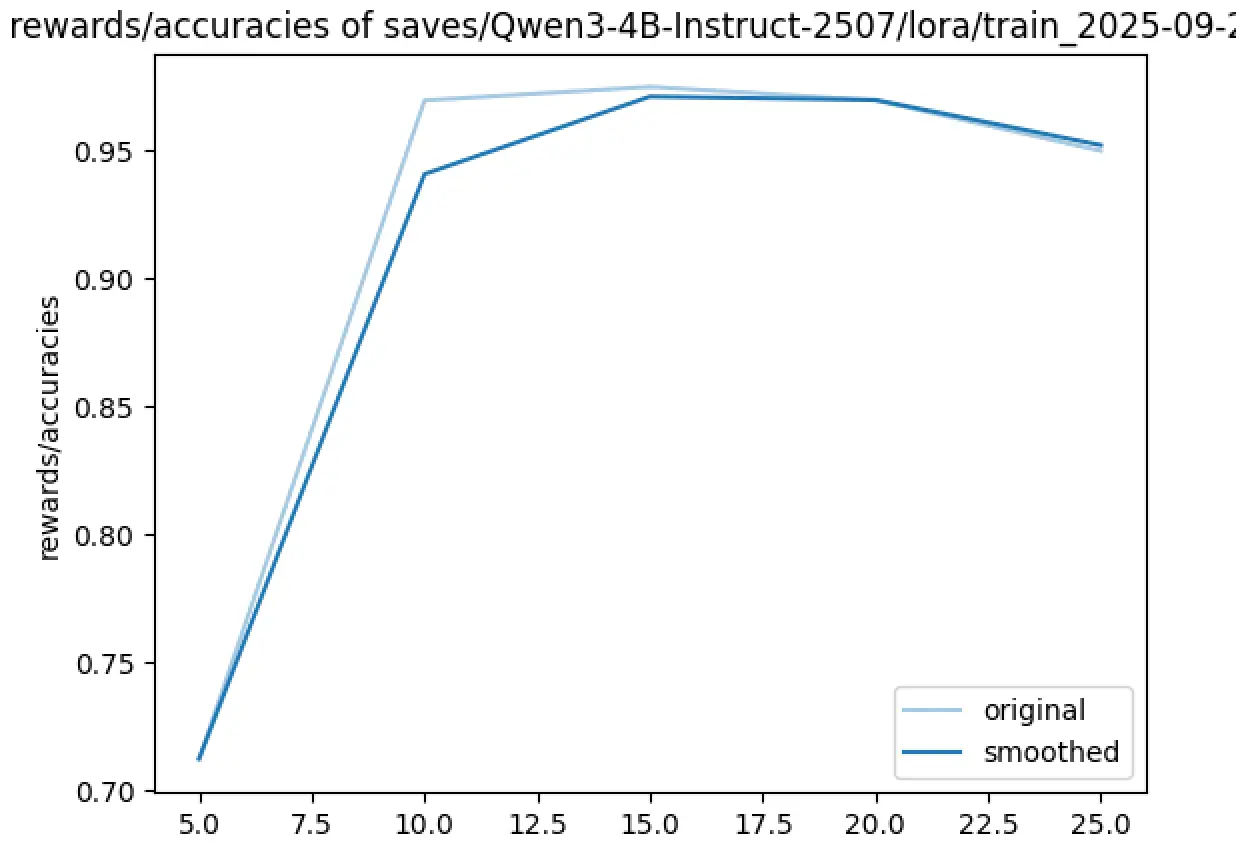
Rewards/Accuracies(奖励/准确率)
- Y轴:奖励值或准确率(0.70-0.97)
- 趋势 :向上递增,从0.71增长到0.95+
- 含义 :模型性能在提升
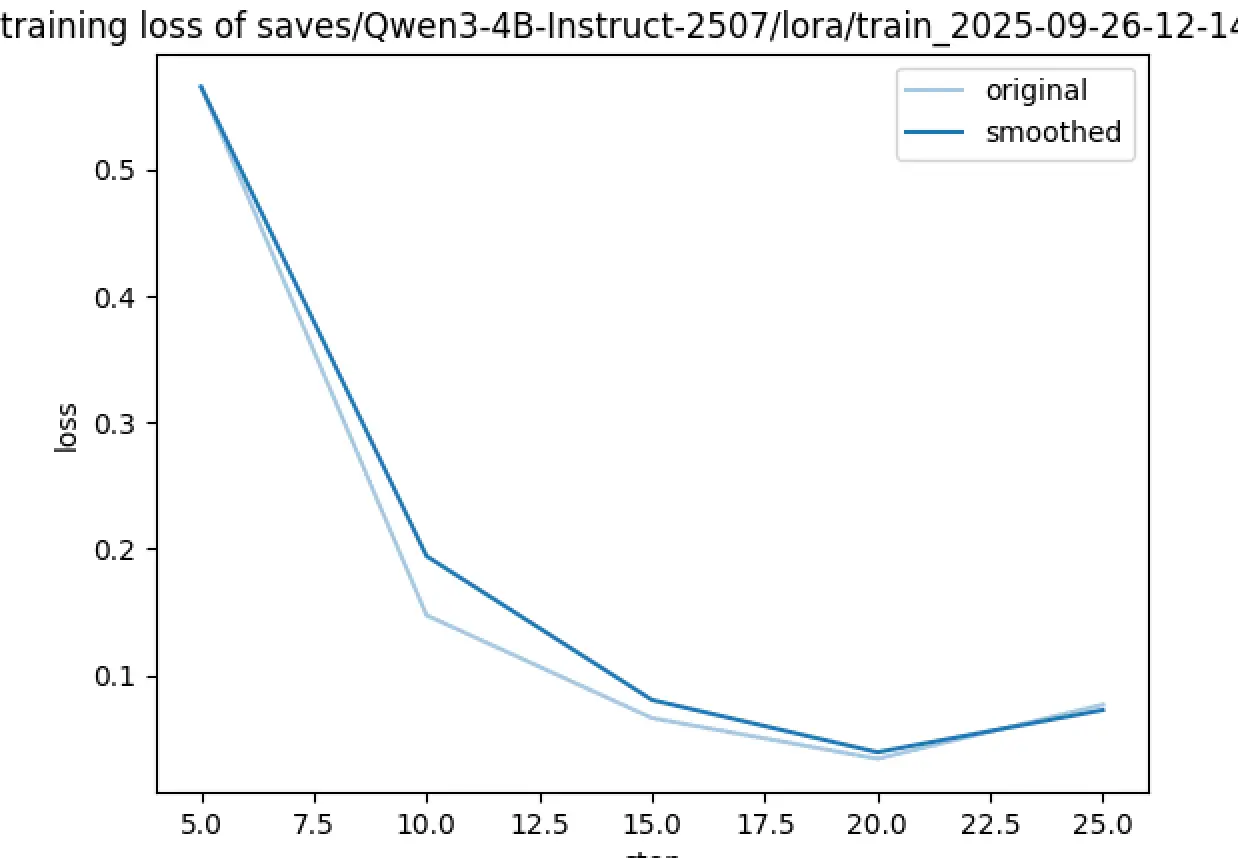
Training Loss(训练损失)
- Y轴:训练损失值(0.0-0.6)
- 趋势 :向下递减,从0.55降低到0.07左右
- 含义 :模型的预测错误在减少
为什么曲线方向相反?
数学关系解释
这两个指标在数学上呈现负相关关系:
-
损失函数的本质:
- 损失越高 = 模型预测越不准确
- 损失越低 = 模型预测越准确
-
奖励/准确率的本质:
- 准确率越高 = 模型表现越好
- 奖励越高 = 模型输出越符合期望
-
理想的训练过程:
- 随着训练进行,损失应该下降
- 同时,准确率/奖励应该上升
6.效果对比
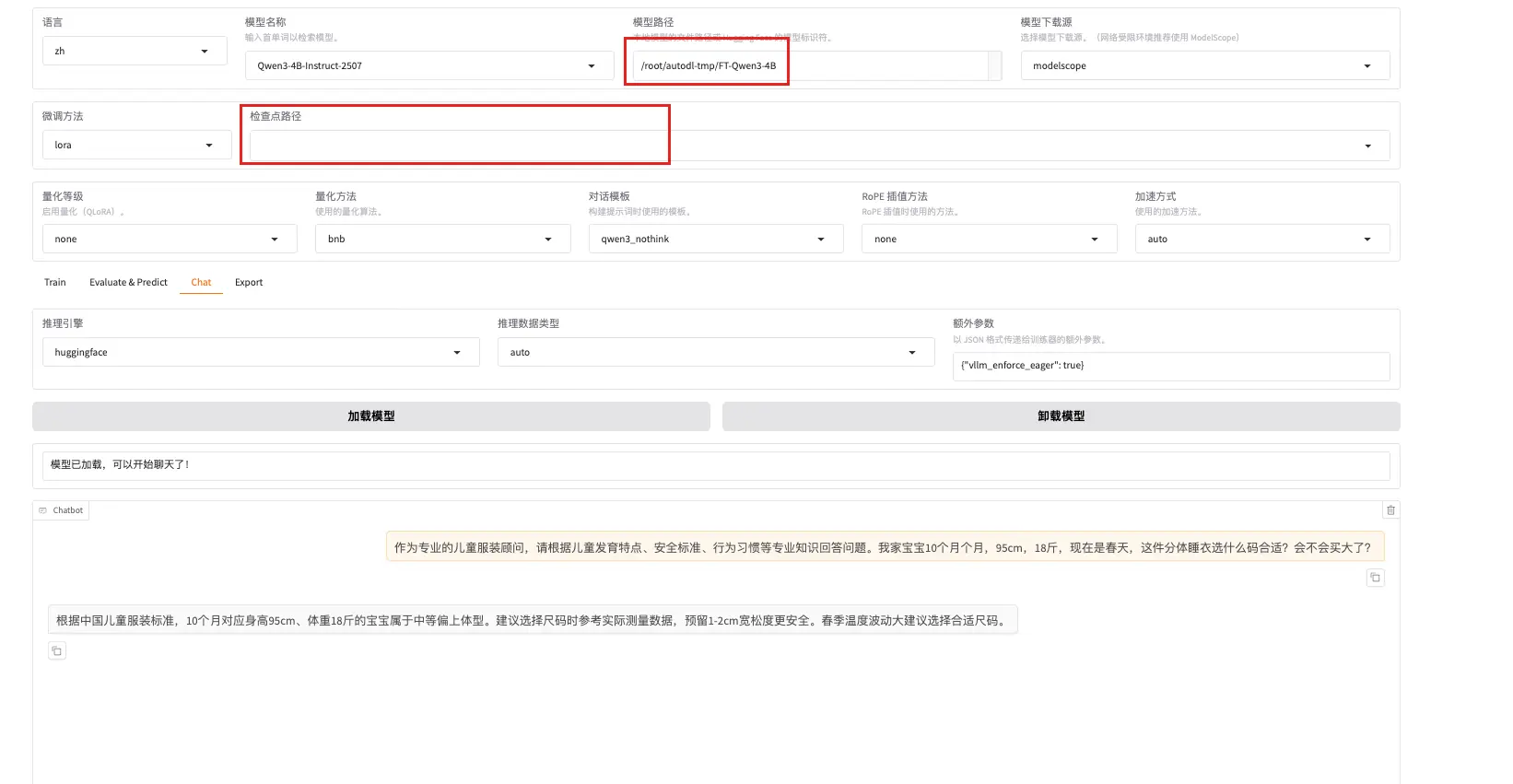
选择chat页面栏
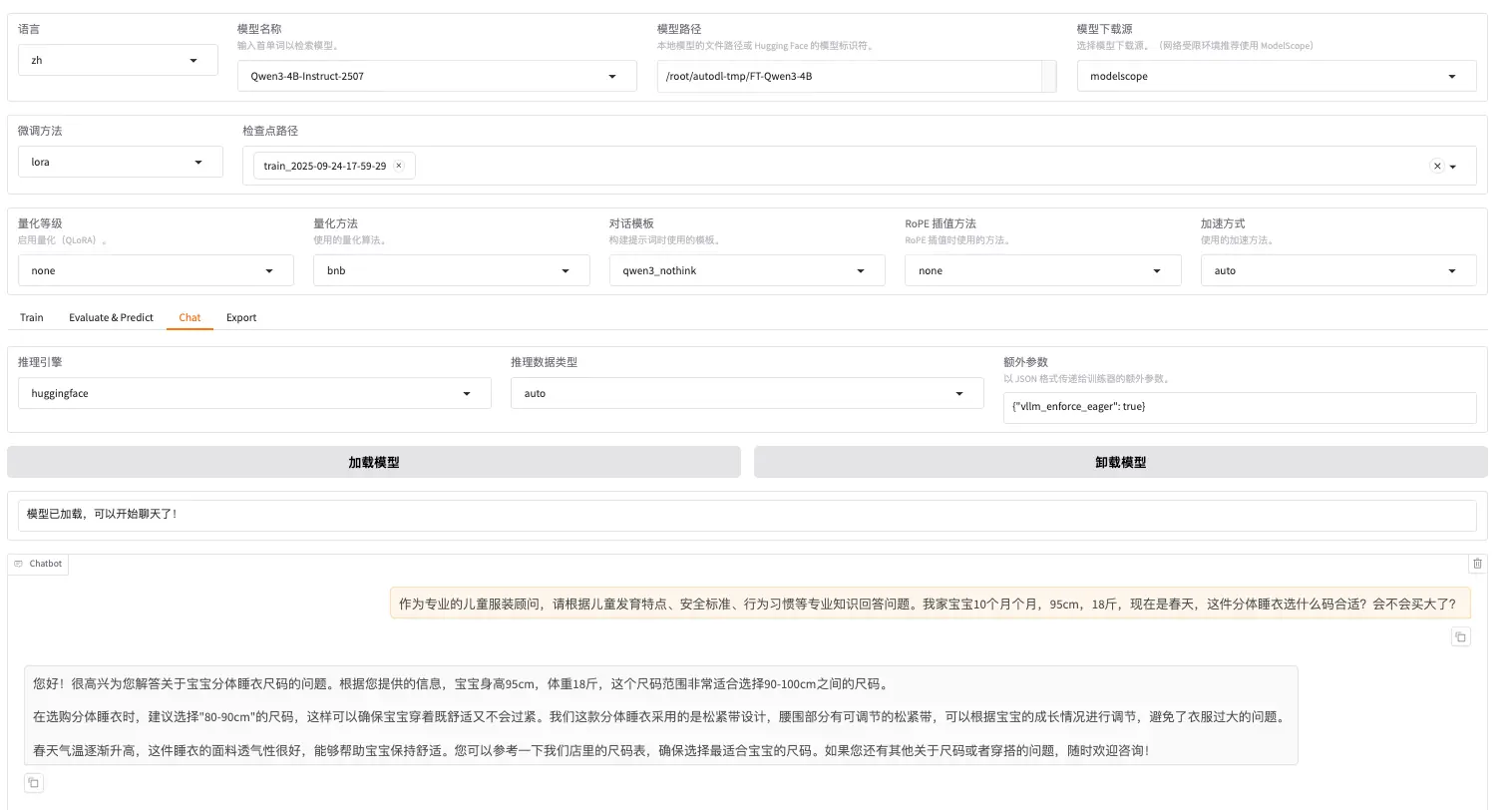
原生模型