一、概述
IndexTTS2 是一个基于索引的文本到语音合成系统,能够生成高质量的语音输出。该项目结合了先进的语音合成技术,提供了简单易用的接口,适用于各种语音合成应用场景。
项目链接:git clone https://github.com/iszhanjiawei/indexTTS2.git
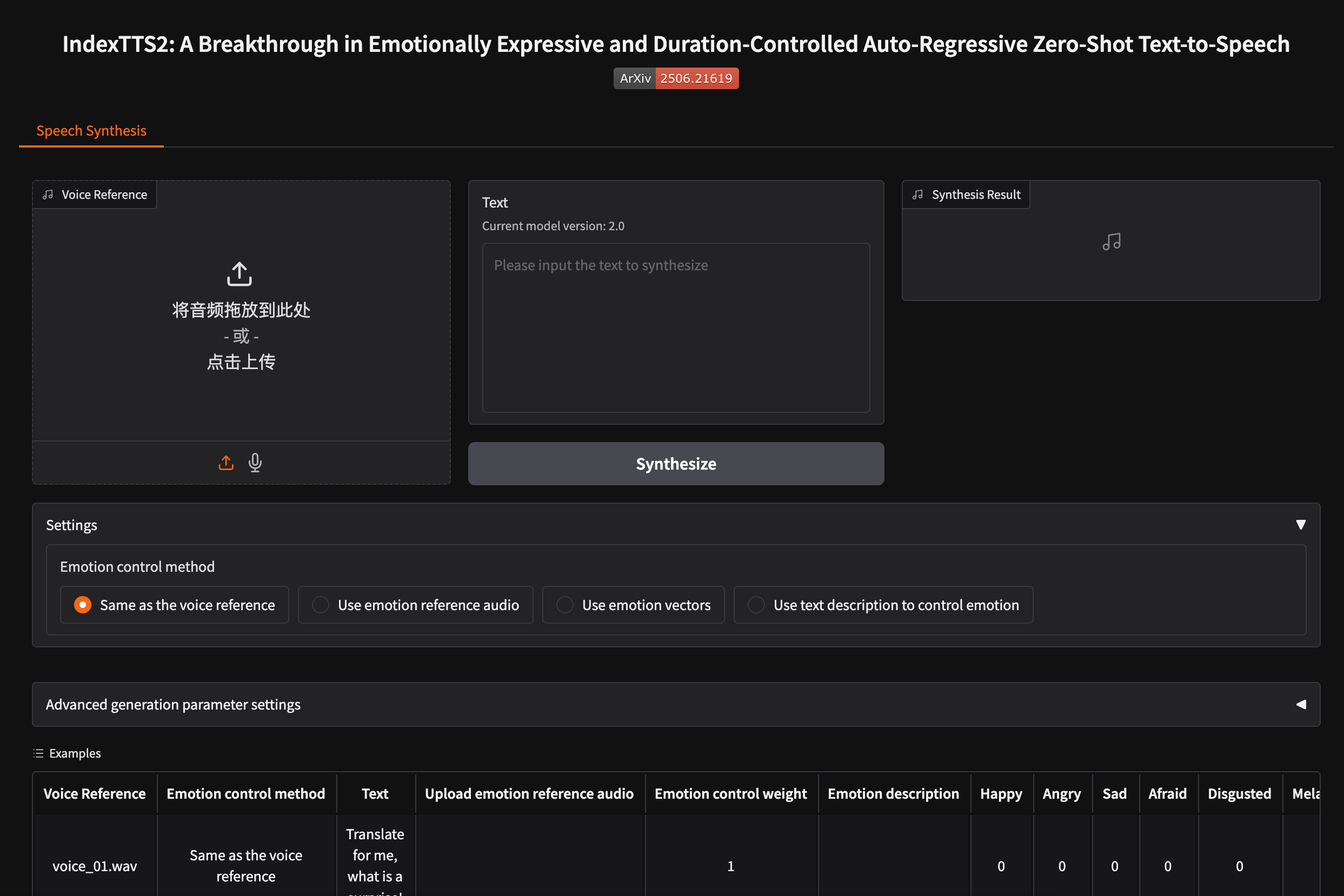
IndexTTS2操作界面:
二、环境要求
在开始安装之前,请确保您的系统满足以下要求:
Python 3.7+
PyTorch 1.7+
CUDA 11.0+ (如需GPU加速)
至少 16GB RAM
足够的磁盘空间存放模型和数据集
三、安装步骤
1. 克隆项目仓库
bash
git clone https://github.com/iszhanjiawei/indexTTS2.git
cd indexTTS22. 创建Python虚拟环境(推荐)
bash
# 使用conda
conda create -n indextts2 python=3.8
conda activate indextts2
# 或使用venv
python -m venv indextts2_env
source indextts2_env/bin/activate # Linux/Mac
# 或
indextts2_env\Scripts\activate # Windows3. 安装依赖包
bash
pip install -r requirements.txt如果项目没有提供requirements.txt,可以手动安装核心依赖:
bash
pip install torch>=1.7.0
pip install numpy
pip install scipy
pip install librosa
pip install soundfile
pip install matplotlib
pip install tqdm
pip install tensorboard4. 下载预训练模型
根据项目文档,下载所需的预训练模型:
bash
# 创建模型目录
mkdir -p checkpoints
mkdir -p pretrained_models
# 下载模型文件(请根据项目文档提供的链接下载)
# 将下载的模型文件放入相应目录5. 准备数据集(可选)
如果您想训练自己的模型,需要准备数据集:
bash
# 创建数据目录
mkdir -p datasets
# 将您的音频文件和标注文件放入数据集目录
# 具体格式请参考项目文档四、使用方法
基本语音合成
1.准备文本输入
创建一个文本文件或直接在代码中指定要合成的文本:
python
text = "欢迎使用IndexTTS2语音合成系统,这是一个高质量的文本转语音工具。"2.运行语音合成
根据项目提供的示例代码进行语音合成:
python
python synthesize.py --text "要合成的文本" --output_path output.wav或使用Python API:
python
from indexTTS2 import IndexTTS2
# 初始化模型
tts = IndexTTS2()
tts.load_model("path/to/checkpoint")
# 合成语音
audio = tts.synthesize("要合成的文本")
tts.save_audio(audio, "output.wav")高级配置
IndexTTS2支持多种参数调整,以获得最佳的语音质量:
python
# 示例配置
config = {
"speaker_id": 0, # 说话人ID
"pitch_control": 1.0, # 音调控制
"energy_control": 1.0, # 能量控制
"duration_control": 1.0, # 时长控制
"emotion": "neutral" # 情感控制
}
audio = tts.synthesize("要合成的文本", **config)批量处理
对于大量文本的合成,可以使用批量处理功能:
bash
python batch_synthesize.py --input_file texts.txt --output_dir outputs/其中texts.txt包含每行一个要合成的文本。
五、训练自定义模型
如果您想使用自己的数据训练模型:
- 准备训练数据
确保数据格式符合要求,通常需要:
-
音频文件(WAV格式)
-
对应的文本转录
-
可能还需要音素对齐信息
- 配置训练参数
编辑配置文件或直接传递参数:
bash
python train.py --config configs/base_config.yaml --data_path /path/to/dataset1.开始训练
bash
python train.py --batch_size 32 --epochs 1000 --save_dir checkpoints/2.监控训练过程
使用TensorBoard监控训练进度:
bash
tensorboard --logdir logs/六、常见问题与解决方案
1. 内存不足错误
如果遇到内存不足的问题,可以尝试:
-
减小批量大小
-
使用更短的音频样本
-
启用梯度累积
2. 合成质量不佳
-
检查模型是否完全收敛
-
调整合成参数(音调、能量等)
-
确保输入文本格式正确
3. 依赖冲突
如果遇到依赖包冲突:
-
使用项目推荐的具体版本
-
创建干净的虚拟环境
-
检查CUDA和PyTorch版本兼容性
性能优化建议
-
GPU加速:确保使用支持CUDA的GPU以获得最佳性能
-
内存优化:适当调整批量大小以平衡速度和内存使用
-
模型量化:对于部署,可以考虑模型量化以减少内存占用和加速推理