开篇:一个需要被回答的问题
2012年,一篇名为《ImageNet Classification with Deep Convolutional Neural Networks》的论文在NeurIPS(当时叫NIPS)会议上发表。作者提出了一个名为AlexNet的深度卷积神经网络(CNN)架构,在ImageNet大规模视觉识别挑战赛(ILSVRC)中以显著优势夺冠,top-5错误率从26.2%降至15.3%,超越第二名近10个百分点。这不仅是技术上的突破,更是深度学习从学术边缘走向主流的标志性事件。
十三年后的2025年,每个人都在谈论AI,焦虑AI,思考"我会不会被AI替代"。这十几年间,人类对"智能"这个概念的理解发生了根本的改变。
这不是一个关于技术的故事,而是一个关于人类认知如何被升级的故事。
第一幕:识别的觉醒(2012-2015)
AlexNet:从"教"到"学"的哥白尼式转向
在AlexNet之前,有一个对计算机视觉的经典假设:特征需要人类设计。
想象一个场景。一个工程师坐在办公室里,看着图像识别的问题,他想:
"要认出一只狗,我需要设计什么特征?狗的眼睛是什么样?它的耳朵形状怎么描述?毛皮的纹理如何用数学表达?"
这不是闲聊,而是真实的工作流程。工程师需要用人类的智慧来定义什么是"重要的特征"。这个过程叫特征工程,是计算机视觉领域最核心的技能。
2012年,AlexNet改变了这个假设。
erlang
AlexNet的核心思想:
给我100万张标注的图片 + 大量计算资源 + 深层神经网络(8层)
→ 机器会自己学特征
(不需要人教)
结果:
在ILSVRC-2012中,AlexNet的top-5错误率为15.3%
比第二名(基于传统方法,错误率约26.2%)低了近10个百分点
最震撼的是:
没有人预先告诉网络要寻找什么特征
机器自己学会了边缘检测、纹理模式等
这些特征是人类没有显式描述的这是一个哥白尼式的转向。
在这个时刻,人类犯了一个基本的错误:我们以为"特征设计"是核心能力。实际上,数据质量和规模才是。
从这一刻起,行业的价值链重组了。特征工程师的价值下降,数据工程师的价值上升。因为现在重要的不是"你能想到什么特征",而是"你能收集和标注多少高质量的数据"。
ResNet:数学的美与工程的优雅
但AlexNet打开了一扇门后,人们遇到了第二个问题。
研究者想:"如果网络更深,性能会更好吗?"于是VGGNet尝试了19层。但当网络继续加深时,性能反而下降了。这看起来违反直觉:为什么网络更深反而更差?
后来的研究发现了原因:梯度消失。深网络的梯度在反向传播时,像洪水中的声音一样逐渐衰减,最后消失。
2015年,何恺明团队提出了ResNet,用一个优雅的解决方案:跳跃连接(Skip Connection)。
ini
普通网络:
y = f(x)
深度网络中,中间层的梯度衰减
ResNet网络:
y = x + f(x)
关键的第一项"x":
梯度可以直接流过,永远不会完全消失
所以深度网络可以训练成功这个简单的改进(就是加一条线),让网络从十几层深到152层。ResNet在ImageNet上的单模型top-5错误率达到4.49%,赢得ILSVRC 2015冠军。
这不仅是技术进步,这是一个关于"简单即优雅"的哲学教训。

第一幕的认知转变
这个时期,一个关键的思维转变发生了:
arduino
Before AlexNet & ResNet:
"我需要聪明的工程师来设计特征和架构"
→ 价值来自"个人的创意和洞察"
After AlexNet & ResNet:
"我需要好的数据和优雅的架构设计"
→ 价值来自"系统性地收集数据 + 发现简单原理"
这是从"天才工程师"到"系统化流程"的转变对应到社会层面,这反映在:从个人能力到团队流程的转变。
一个优秀的设计师,在没有数据支持的情况下,光靠想象力也画不出AI时代的图像识别系统。需要的是整个流程:数据标注员(确保数据质量)、工程师(架构设计)、计算资源(GPU集群)、运维(监控系统)。每个角色都很关键,没有"最聪明的那个人"能单独完成。
第二幕:序列的记忆(1997-2017)
LSTM:不是记住所有,而是选择记忆
虽然LSTM在1997年就被提出,但直到2014年左右,随着计算能力的提升和大规模数据的可用,LSTM才在序列建模中广泛应用并展现威力。
到了这个时期,AI已经能"看"了。下一个问题是:机器能"理解"吗?特别是,能不能理解时间序列中的长距离依赖?
想象这个例子:
erlang
句子:The bank executive announced his resignation,
after 20 years of service. He said ...
要理解"He"指的是谁,需要回顾前面提到的"executive"
简单RNN的问题:
要走过中间的18个词才能建立这个连接
每一步的梯度都会衰减
20步之后,"executive"的信息已经完全消失
结果:无法理解长距离的指代LSTM的创新不在于强行记住所有信息,而在于:学会选择性地记住。
arduino
LSTM的三个门的逻辑:
遗忘门(Forget Gate):
"这个故事讲完了,我可以忘记这些细节"
→ 允许有选择的遗忘
输入门(Input Gate):
"这个新信息很重要,我必须记住"
→ 允许有选择的记忆
输出门(Output Gate):
"现在需要用哪些记忆来完成任务"
→ 允许有选择的输出
这就像人类的记忆一样
我们不记住所有的细节
而是记住关键信息
这个转变有多深刻?它改变了我们对"理解"本身的定义。
Before LSTM广泛应用,人们认为:理解 = 记住所有细节
After LSTM,人们认识到:理解 = 抓住关键信息,忽视噪音
这直接反映在教育哲学上:
diff
传统教育模式:
学生应该记住所有知识点(准备考试)
LSTM启发的新模式:
学生应该学会:
- 什么信息是关键的
- 什么细节可以遗忘
- 怎样在需要时快速检索信息LSTM时代的职业转变
LSTM技术成熟后,数据科学家开始面对一个新问题:我怎样处理序列数据?
这导致了一批新职业的出现:
- 自然语言处理工程师
- 时间序列分析师
- 语音识别工程师
这些职业的共同点是:不再是"给定固定的输入,做一个分类",而是"理解序列中的因果关系"。职业要求从"会调用sklearn库"升级到"理解RNN的梯度流"。
第三幕:注意力的革命(2017)
Transformer:从"一个接一个"到"整体关注"
2017年6月,Google团队发表了《Attention is All You Need》这篇论文,彻底改变了AI的发展方向。标题灵感来自Beatles的歌曲《All You Need is Love》。
在这之前,处理序列的标准做法就是RNN/LSTM:按顺序逐个处理。
diff
LSTM的方式:
词1 → 词2 → 词3 → ... → 词100
必须按顺序,无法并行
这导致的问题:
- GPU的并行能力浪费(GPU擅长同时处理很多数据)
- 训练时间很长
- 长距离依赖仍然有挑战(虽然LSTM改善了)Transformer说:为什么要顺序处理?
scss
Transformer的创新:
所有词同时进入注意力层
关键问题:所有词同时处理,怎样决定关注谁?
答案:用注意力权重
具体的计算:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
词1 对其他99个词计算重要性分数 → 用分数加权求和
词2 对其他99个词计算重要性分数 → 用分数加权求和
...
所有词同时完成
结果:
- 真正的并行,训练速度大幅提升
- 长距离依赖自动解决(所有词距离都是1)
- 可以处理更长的文本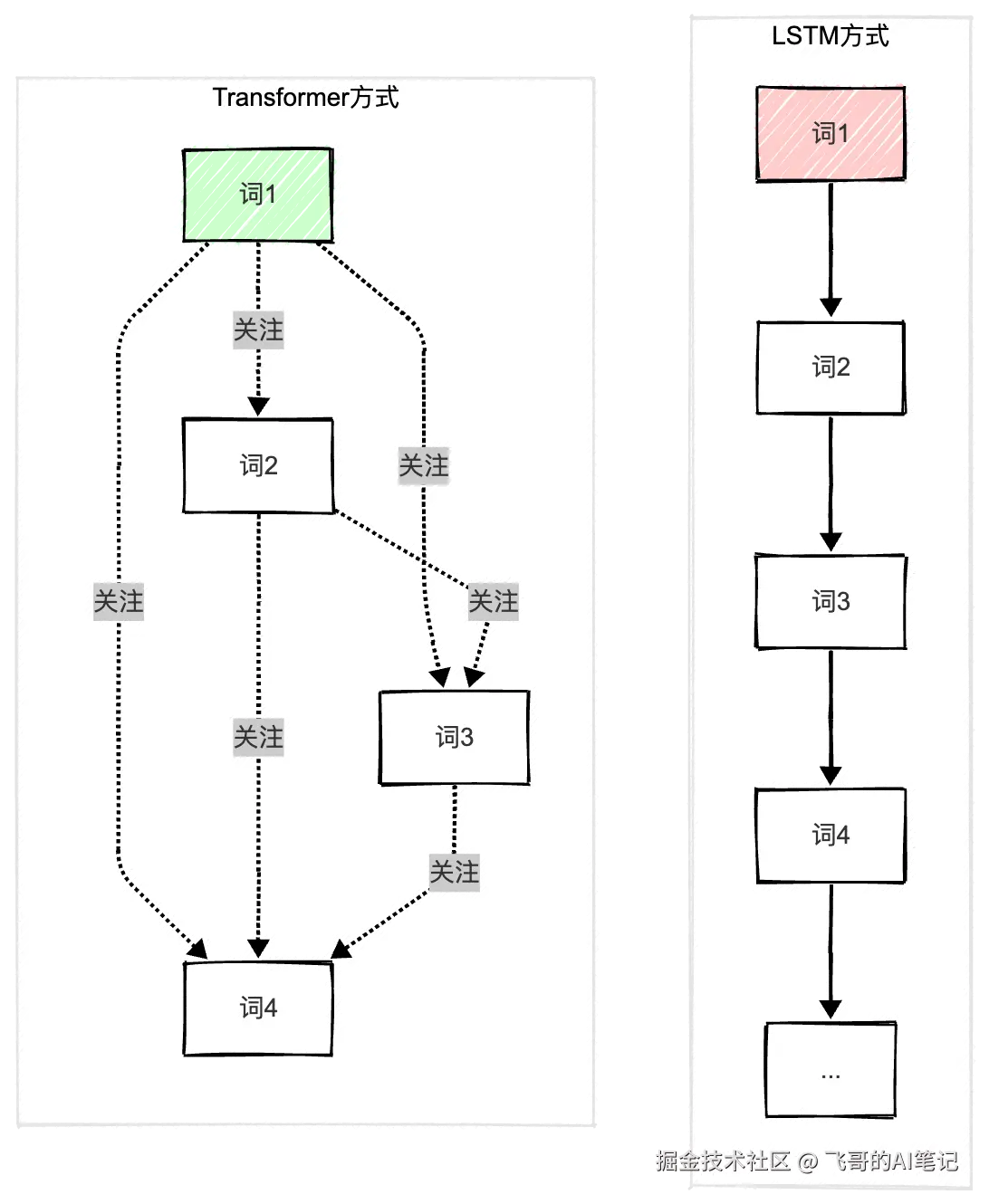
但Transformer的真正革命不在速度,而在思维方式。
Before Transformer:
"理解一个序列,要从头到尾跟踪因果关系"
After Transformer:
"理解一个序列,要看所有元素之间的相互关系"
这是从线性思维 到网络思维的转变。
多头注意力:多个视角同时理解
Transformer还有一个巧妙的设计:多头注意力(Multi-Head Attention)。
arduino
一个句子:"The bank executive announced his resignation."
不同的"注意力头"关注不同的关系:
Head 1(语法关系):
关注"his"和"executive"的连接
Head 2(语义关系):
关注"resignation"和"announced"的因果关系
Head 3(指代关系):
关注代词的指向
8个头同时工作,每个头看到不同的模式
最后综合8个头的输出,得到更全面的理解这个设计反映了一个深刻的思想:单一视角不够,需要多角度同时理解。
Transformer改变了社会组织的思考方式
这个改变的社会影响出乎意料。
Transformer证明了:相比于"严格的链式流程","充分的信息互联"能产生更好的结果。
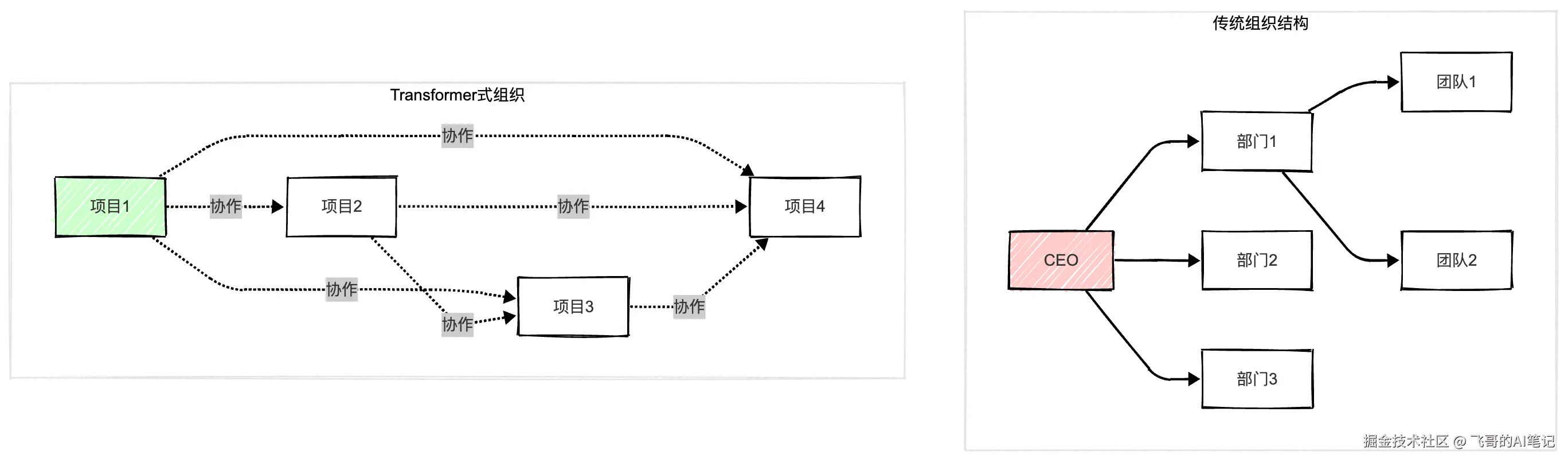
这反映在现代企业管理上:
makefile
传统组织:
CEO → 部门经理 → 小组经理 → 员工
信息严格沿着链条流动(类似LSTM)
新型组织(Transformer启发):
跨部门沟通频繁
任何人都可能和任何人协作
信息在整个网络中流动(类似Self-Attention)
效率提升:信息能快速跨部门整合
代价:管理变得复杂这也反映在城市规划上。智能城市不是从中心向外的树形结构,而是各个系统相互连接的网络。交通系统、能源系统、安全系统,都在相互通信,相互调整。
第四幕:多模态的统一(2020-2021)
Vision Transformer:图像也是序列
2020年末,Google提出Vision Transformer(ViT),证明了一个激进的想法:
图像处理不一定需要卷积神经网络。 图像可以像文本一样处理。
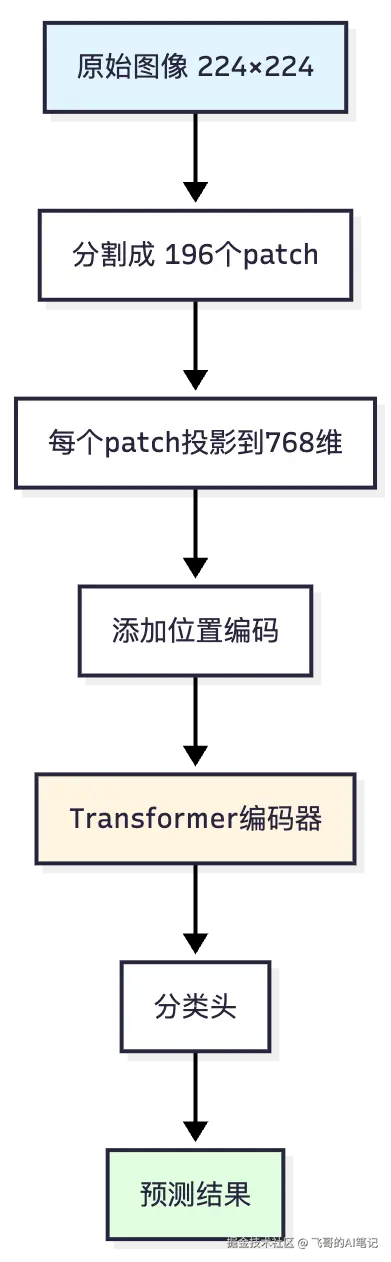
objectivec
传统计算机视觉:
图像 → CNN(利用局部相关性) → 特征 → 分类器
Vision Transformer:
图像 → 分块(16×16 patch) → 线性投影 → Transformer
(把图像看成"词序列")为什么这很激进?因为CNN是基于"局部相关性"的假设(图像中相邻像素关系紧密),而Transformer是基于"全局关系"的(所有位置之间都可能相关)。
结果呢?Vision Transformer的性能不仅没有下降,在大规模数据上超过了CNN。在ImageNet上达到88.55%的准确率。
CLIP:打破模态间的墙
2021年,OpenAI的CLIP更激进:用同一个模型处理图像和文本。
CLIP的训练方式很简单但很强大:
diff
训练数据:4亿个(图像,文字描述)对
训练目标:
给定一张图像和多个文字描述,预测哪个描述最匹配
(对比学习)
这个简单的任务让CLIP学到了:
- 图像和文本共同的语义空间
- "猫"这个词的含义和猫的图像应该在空间中靠近
- "运动"这个概念在图像和文本中应该对应CLIP的最强之处是零样本学习:
objectivec
CLIP从未见过"骑摩托车的人"这个类别
但给它一张"骑摩托车的人"的图像和这段文本描述
它说:匹配
为什么?因为它理解了"摩托车""人""骑"这些概念的关系
即使从未看过这个组合,也能通过概念的组合推理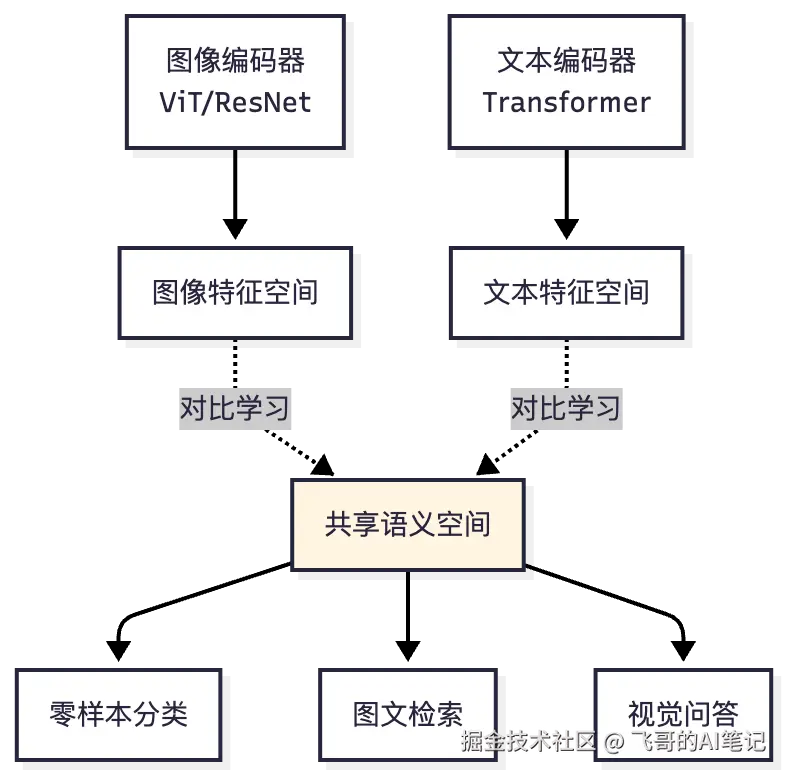
多模态带来的认知转变
多模态统一有个深刻的含义:
Before CLIP:
"图像和文本是两个不同的世界"
After CLIP:
"任何信息都可以表示在同一个向量空间"
这改变了我们对翻译的理解。
不仅仅是语言翻译,还有:
- 图像到文字的翻译(图像描述)
- 文字到图像的翻译(文生图)
- 代码到功能的翻译(代码理解)
它也改变了职业生态。从前,文案、设计、摄影是三个独立的职业。现在,它们的界限模糊了。一个人可以用Midjourney生成图像,用ChatGPT写文案,用Sora生成视频。
第五幕:创造的民主化(2014-2024)
GAN vs 扩散模型:两条创造之路
2014年,Ian Goodfellow提出了GAN(生成对抗网络),引入了一个革命性的想法:两个网络互相竞争,共同进步。
bash
生成器想:"我能骗过判别器吗?"
判别器想:"我能看出这是假的吗?"
这个对抗的过程推动了双方的进步
最终生成器可以生成完全逼真的图像
数学表达:
min_G max_D V(G,D) = E_x[log D(x)] + E_z[log(1-D(G(z)))]但GAN有个问题:训练不稳定。有时生成器太强,判别器学不会。有时相反。就像两个人比武,一个太强一个太弱,都没法进步。这被称为"模式坍塌"(Mode Collapse)问题。
2020年,Jonathan Ho等人提出的扩散模型(DDPM)提供了另一条路:
arduino
不是对抗,而是学会"逐步去噪"
Forward process(人工加噪):
清晰图 → 加点噪声 → 加更多噪声 → ... → 完全噪声
(T步,通常T=1000)
Reverse process(模型学习的过程):
白噪声 → 去掉噪声 → ... → 清晰图
关键:反向过程的每一步都很容易学
(从"有点噪声的图"预测"应该去掉的噪声")
结果呢?扩散模型胜出了。
- Stable Diffusion、DALL-E 2/3都用扩散模型
- 2024年的文生视频模型Sora和Veo也用扩散模型
- 在图像质量和训练稳定性上都优于GAN
生成能力的民主化
2024年发生的最重要的事是什么?任何人都能生成内容了。
yaml
2015年:生成高质量图像
需要:专业设计师 + Photoshop + 8小时
2024年:生成高质量图像
需要:任何人 + Midjourney + 5分钟
2015年:制作视频
需要:导演、摄影师、后期制作团队 + 1个月
2024年:制作视频
需要:一个人 + Sora/Veo + 1小时这改变了什么?从"创意的稀缺"到"品味的稀缺"。
Before:
能制作高质量内容的人很少 这些人的价值很高
After:
任何人都能制作内容 真正值钱的是"知道什么样的内容好"
我们看到内容创作行业加速分化:
- 初级设计师面临挑战(重复性美化工作被自动化)
- 资深创意总监价值提升(品味和战略变得关键)
- 新职业出现(Prompt工程师、AI内容协调员)
创造的哲学问题
生成模型带来了一个有趣的哲学问题:
AI在"创造"吗,还是在"重组"?
diff
人类的创造似乎也是重组:
- 画家看过很多画,融合成自己的风格
- 作家读过很多书,整合成自己的故事
- 作曲家听过很多音乐,创作新曲
那么AI生成模型:
- 从数十亿张图学到模式
- 根据描述生成新的组合
本质上有区别吗?这个问题引发了版权争议。艺术家和内容创作者起诉AI公司使用了未授权的作品训练。这些法律案件会深刻影响AI的未来------可能迫使AI模型只用授权数据训练,或者建立新的版权框架。
第六幕:推理的显式化(2024)
o1、DeepSeek-R1:思考变可见
2024年末,发生了一个重要转变。OpenAI发布了o1系列模型,DeepSeek发布了R1,它们都具有一个共同特点:推理过程是可见的。
Before:
swift
用户:"2+2等于多少?"
ChatGPT:"4"
用户:"你怎么知道的?"
ChatGPT:<无法解释推理过程>After:
css
用户:"证明√2是无理数"
o1/DeepSeek-R1:
<think>
首先,让我用反证法...
假设√2是有理数,那么可以表示为p/q,其中p、q互质...
那么2q² = p²...
这意味着p是偶数...
让我设p=2k...
那么2q² = 4k²...
所以q² = 2k²...
这说明q也是偶数...
但这与p、q互质矛盾...
</think>
因此√2是无理数。[详细证明过程]思考过程变成了可见的、可验证的。
DeepSeek-R1通过强化学习训练模型"多想想":
markdown
两阶段训练:
1. 监督微调(SFT):教模型基本推理格式
2. 强化学习(RL):奖励正确的推理过程
奖励函数设计:
- 过程奖励:评估推理步骤的正确性
- 最终奖励:评估最终答案的正确性
- 鼓励模型在困难问题上"多想想"
结果:
在AIME数学竞赛上,DeepSeek-R1达到86%的准确率这改变了什么?从"盲目信任能力"到"理解推理过程后相信"。
推理能力的社会含义
这个转变在医学、法律等高风险领域特别重要。
arduino
医学诊断:
Before:AI系统说"这是癌症,概率99%"
医生:我不知道它怎么判断的,所以不完全信任
After:AI系统展示推理过程
"我看到三个特征...
这个密度异常的区域...
这个形状不规则...
与已知的XX型癌症模式一致..."
医生:虽然AI比我快,但我能理解它的推理
如果推理有问题,我能指出这也改变了职业角色:
arduino
Before:
医生的职能 = 诊断
AI的职能 = 诊断
→ 竞争关系,医生可能被替代
After:
AI的职能 = 快速诊断 + 展示推理
医生的职能 = 验证推理 + 做治疗决策 + 患者沟通
→ 合作关系,医生升级到"判断者+决策者"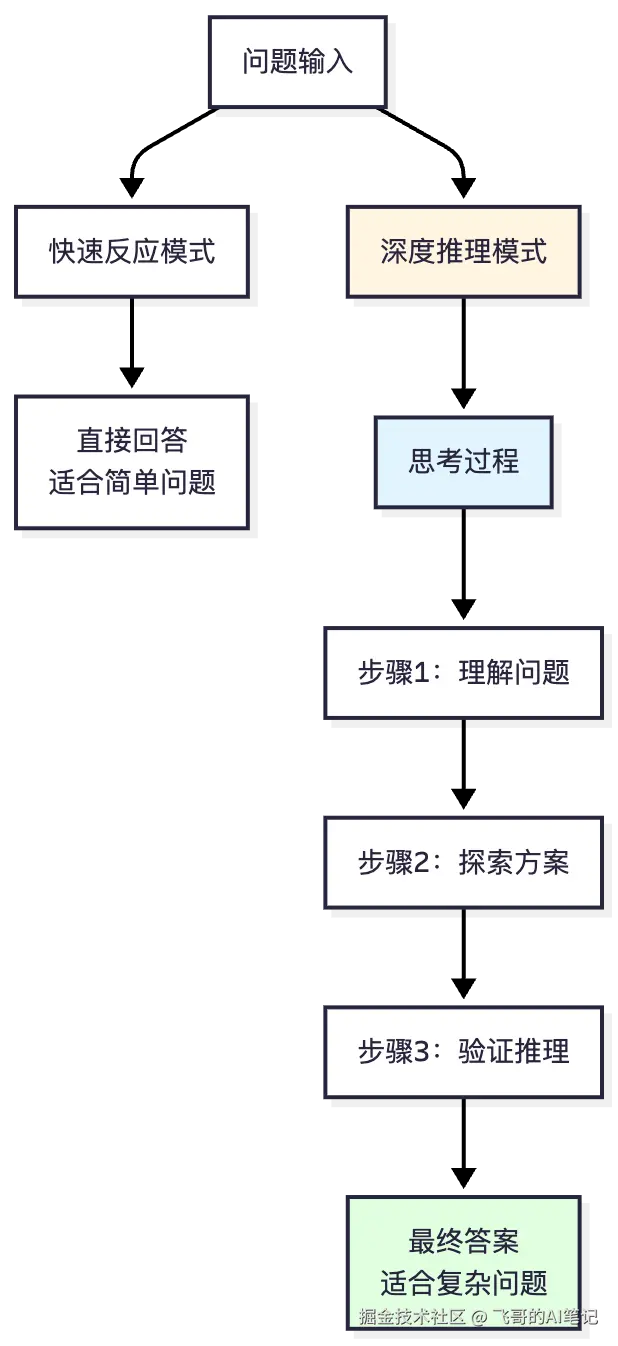
第七幕:科学发现的加速(2020-2024)
AlphaFold:从工程工具到科学突破
2020年,DeepMind的AlphaFold解决了蛋白质折叠问题,这标志着AI从"工程工具"跃升到"科学发现工具"。
问题的复杂度:
diff
蛋白质由氨基酸组成(20种类型)
给定氨基酸序列,预测3D结构
可能的形状数量 > 宇宙中的原子数
传统方法:
- X射线晶体学:需要数月到数年
- 冷冻电镜:昂贵且需要专业设备
- 计算模拟:算力要求极高,准确性有限
AlphaFold怎么做到的?
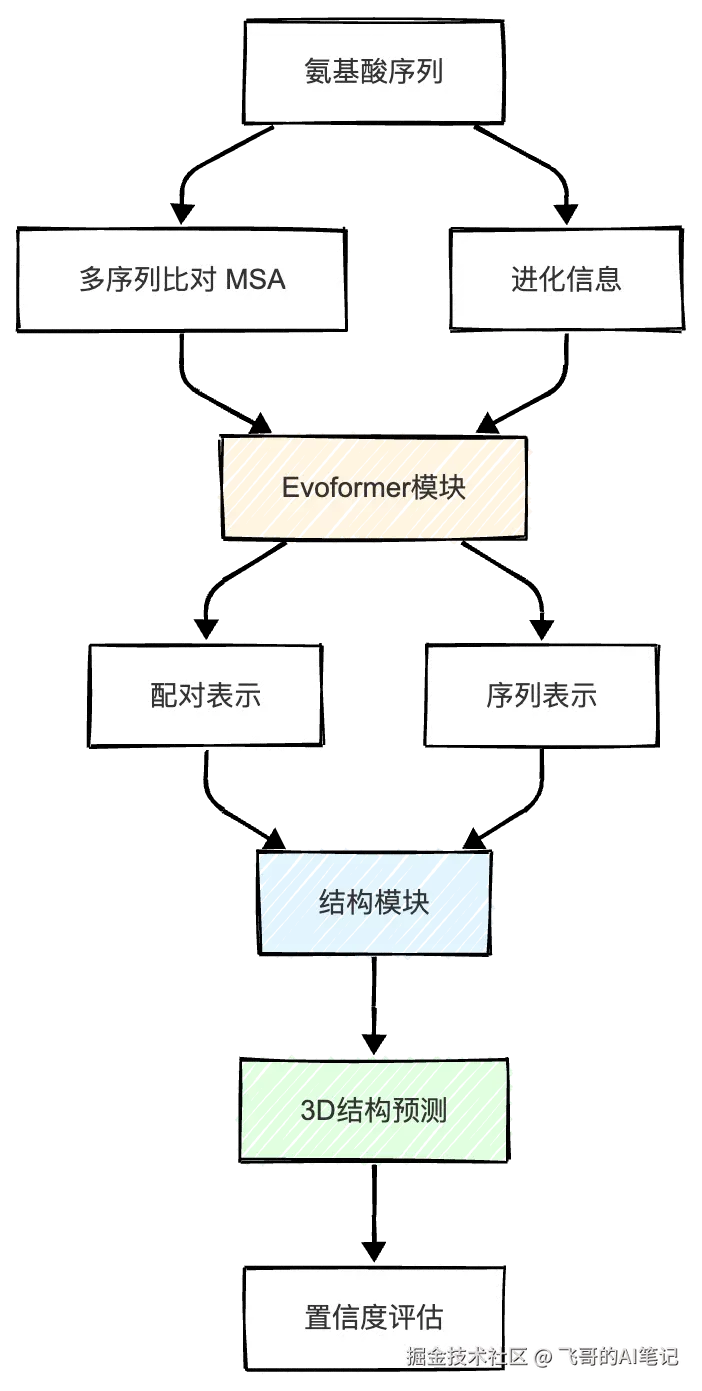
不是通过穷举,而是通过学习AlphaFold的核心创新:
markdown
架构设计:
1. 输入:氨基酸序列 + 多序列比对(MSA) + 结构模板
2. Evoformer模块(改进的Transformer):
- 建模序列和结构的关系
- 注意力机制处理长程相互作用
3. 结构模块:
- 直接预测3D坐标
- 迭代refinement
训练数据:
- 170,000+已知蛋白结构(Protein Data Bank)
- 监督学习 + 结构损失函数
划时代成果:
- CASP14竞赛GDT_TS指标:92.4分
- 预测准确度可媲美实验方法科学影响:
2024年,AlphaFold的开发者Demis Hassabis和John Jumper获得诺贝尔化学奖。这不仅是对技术的认可,更是对AI能做科学发现这个理念的认可。
现在的应用:
- 药物发现(AI筛选候选分子,加速数千倍)
- 疾病研究(理解致病蛋白的结构)
- 合成生物学(设计新蛋白)
- 已预测超过2亿个蛋白质结构
AI for Science的哲学含义
AlphaFold引发了一个问题:AI的创造性从哪里来?
arduino
AlphaFold"创造"了什么?
- 不是创造新的蛋白质
- 而是发现自然中已存在但人类未知的结构模式
这算"创造"吗?
比较:
- 哥伦布"发现"了美洲(已存在,人类未知)
- 诗人"创造"了新诗(从未存在过)
AlphaFold像哥伦布,不像诗人
但发现本身就极具价值这也改变了科学研究的方法:
arduino
Before AI:
科学家靠实验和直觉
每个发现需要多年
受限于实验条件和成本
After AI:
AI可以加速假设的验证
科学家的角色从"执行者"变成"设计者"
科学发现的周期从年缩短到月
新的科学范式:
提出假设 → AI快速验证 → 实验确认 → 迭代终幕:思维方式的根本改变
十三年演进的核心逻辑
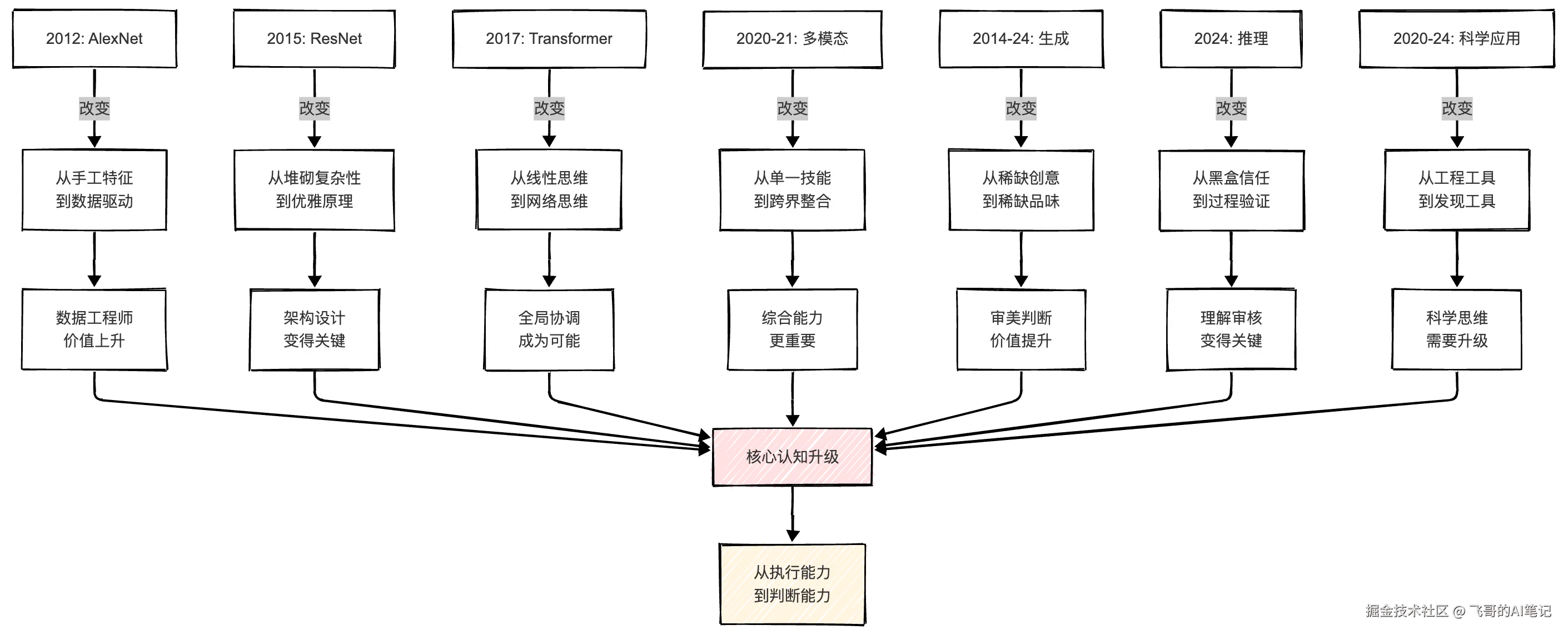
让我们回顾这十三年的旅程,会发现一条清晰的主线:
从"能力竞争"到"判断竞争"
十三年的演变带来的最深刻的改变是:职业竞争力的定义改变了。
diff
2012年的竞争力:
"我会做什么"
- 能写特征提取代码吗?
- 能调参吗?
- 能训练模型吗?
2025年的竞争力:
"我能判断什么"
- 什么时候用什么模型?
- 什么输出质量可以接受?
- 什么时候该信任AI,什么时候不该?
- 如何验证AI的推理过程?
从"执行能力"到"判断能力"学习方式的根本改变
这也改变了学习应该如何进行:
arduino
传统模式:
"掌握所有知识点"
学生:死记硬背
评估:考试成绩(记忆准确性)
AI时代:
"理解核心思想,知道怎么查,能够判断"
学生:理解概念,学会提问,验证答案
评估:能解决新问题吗?能判断答案质量吗?
关键转变:
从"知道答案" → 到"知道如何获得和验证答案"职业前景的重新塑造
AI没有"消灭"职业,而是改变了职业的内容:
arduino
医生的转变:
Before:诊断 + 开处方
After:验证AI诊断 + 复杂决策 + 患者沟通 + 伦理判断
律师的转变:
Before:研究法律条文 + 写文书
After:战略规划 + 复杂谈判 + 风险评估 + AI输出审核
程序员的转变:
Before:编写代码
After:系统设计 + 代码审查 + 架构决策 + AI协作
设计师的转变:
Before:制作视觉内容
After:创意策划 + 品味把关 + AI工具协调 + 品牌战略
共同模式:
从"直接操作" → 到"判断和审核"
从"单一技能" → 到"系统思维"
系统架构的竞争
2025年有个重要的认识:单个模型能力的竞争已经结束,真正的竞争是系统架构。
arduino
模型能力对比(举例):
GPT系列:推理能力强
Claude:代码能力强
Gemini:长文本处理强
各家开源模型:成本优势
结果:
没有绝对的赢家
只有"用途不同"真正的竞争变成了:怎样架构多个模型的协作。
diff
基础架构:
简单问题 → 用小模型/快速模型
中等问题 → 用中等模型
复杂推理 → 用强推理模型
超长文本 → 用长上下文模型
优化策略:
- 智能路由(根据任务复杂度选模型)
- 级联调用(先用小模型尝试,失败再用大模型)
- 并行验证(多个模型同时处理,交叉验证)
- 成本监控(追踪每个任务的成本效益)只有理解这些系统设计原则的工程师,才能在AI时代真正创造价值。
尾声:最精彩的时刻还未到来
现在的关键问题
如果说前面所有的闪耀时刻都在讲"技术怎样进步",那最后要问的是:社会怎样适应。
diff
2025年的真实困境:
就业市场:
- 初级岗位面临挑战
- 高级岗位需求增加
- 技能差异导致的收入分化扩大
教育体系:
- 学生发现所学知识可能过时
- 企业需要的是"AI协作能力"
- 教育体系滞后于产业需求
法律监管:
- AI的能力超过了法律的预见性
- 版权争议、隐私问题、安全风险
- 缺乏清晰的规则和标准
心理层面:
- 人们不确定"我的工作未来在哪"
- 焦虑和不确定性弥漫
- 需要重新定义"有价值的工作"真正的转变是什么
但仔细看,最深刻的转变其实很简单:
arduino
Before:
"AI是工具"
→ 工作内容:学习使用工具
→ 焦虑点:我用不好工具怎么办
After:
"AI是合作者"
→ 工作内容:与AI协作,判断和审核AI的输出
→ 焦虑点:我能管理和判断AI的工作吗
这不仅是工作方式的改变
而是对"工作本质"的重新思考十年演进的本质
让我们用一张图总结这十几年的变迁:
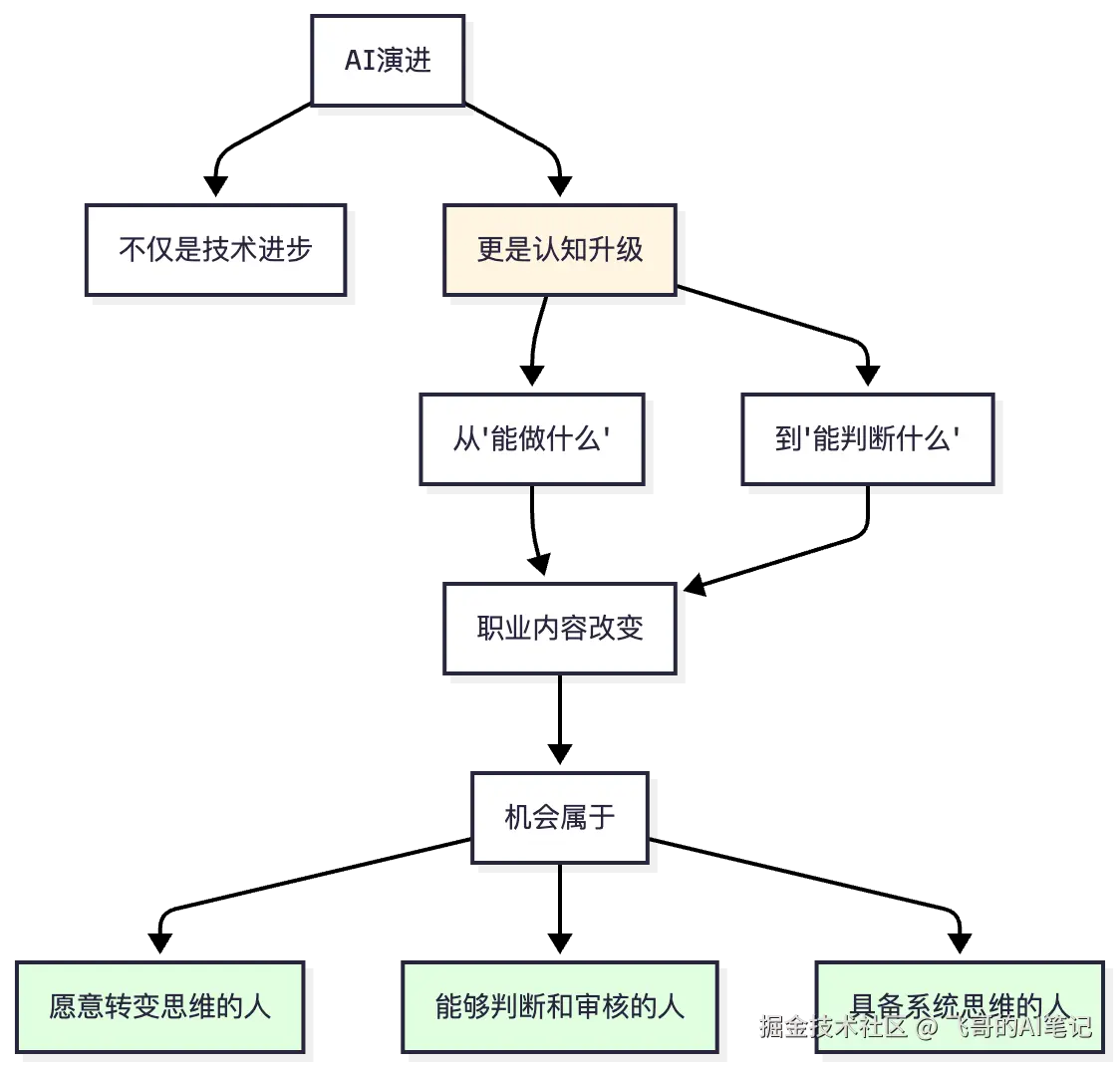
这些年,AI从一个局限在研究机构的话题,变成了改变每个人工作方式的现实。
但最深刻的不是技术本身,而是这种改变背后的逻辑:
每一次技术突破,都打破了人类对某个工作的理解,强迫人类重新思考"什么是这个职业的核心"。
- AlexNet说:核心不是特征设计,是数据质量
- ResNet说:核心不是复杂性,是优雅原理
- LSTM说:核心不是全部记忆,是选择记忆
- Transformer说:核心不是顺序处理,是全局关系
- 多模态说:核心不是单一技能,是跨界理解
- 生成说:核心不是制造能力,是品味判断
- 推理说:核心不是快速答案,是可验证过程
- AlphaFold说:核心不是人工实验,是智能发现
最后,现在不是危机,是重新定义的机会。
那些能理解这种转变、主动适应这种转变的人,会发现自己的职业不是被替代,而是升级了。从执行者升级为判断者,从单一技能者升级为系统思考者,从工具使用者升级为AI协作者。
从这个角度看,最精彩的时刻其实还没到来。
附录:技术演进时间线
yaml
1997年 LSTM提出(但直到2014年才广泛应用)
↓
2012年 AlexNet在NeurIPS发布 - 深度学习突破
↓
2014年 GAN提出 - 生成模型开端
↓
2015年 ResNet发布 - 超深网络成为可能
↓
2017年 Transformer发布 - 统一架构诞生
↓
2018年 BERT发布 - 双向预训练
↓
2020年 GPT-3 - 大模型时代
Vision Transformer - Transformer进入视觉
DDPM - 扩散模型突破
AlphaFold - 科学突破
↓
2021年 CLIP - 多模态学习
↓
2022年 ChatGPT - AI进入大众视野
↓
2023年 大模型爆发年
↓
2024年 推理能力提升(o1、DeepSeek-R1)
AlphaFold获诺贝尔奖
多模态生成(Sora、Veo)
↓
2025年 系统架构竞争时代作者注: 本文所有技术细节以公开发表的论文和官方资料为准,文中的社会影响分析单纯是基于行业观察和个人洞察,欢迎讨论和指正。 如果感兴趣,请给我留言,以后我们还可以谈谈 AI Forward Deployed Engineer (AI 前线部署工程师)。