一.线程特性总结
1.关于页表的问题
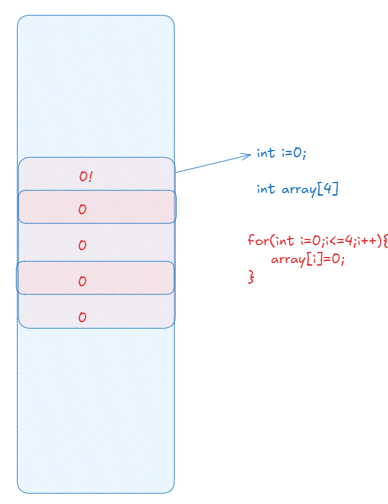
1.如何理解new和malloc?系统调用brk和mmap,在申请时并没有直接申请物理地址 ,只是更改了虚拟地址空间的堆的范围 。当真正要使用的时候系统触发缺页中断,才会真正申请物理内存。------这本质是一种延迟申请,提高了内存使用的充分度。
2.写时拷贝是以整个页框为单位的。
3.申请内存只需要申请地址空间就可以了。
4.如何区分是缺页,还是真的越界?
首先我们思考一个问题:越界了一定会报错吗?不一定 。这种情况下,操作系统都不知道,需要自己debug。具体看是否指向一个非法空间。
前提:总之是页号无法正常映射转换,确定页号是否在对应的合法区域中
⻚号合法性检查:操作系统在处理中断或异常时,⾸先检查触发事件的虚拟地址的⻚号是
否合法。如果⻚号合法但⻚⾯不在内存中,则为缺⻚中断;如果⻚号⾮法,则为越界访
问。内存映射检查:操作系统还可以检查触发事件的虚拟地址是否在当前进程的内存映射范围
内。如果地址在映射范围内但⻚⾯不在内存中,则为缺⻚中断;如果地址不在映射范围
内,则为越界访问。• 线程资源划分的真相:只要将虚拟地址空间进⾏划分,进程资源就天然被划分好了。
2.线程的优缺点与进程的对比
优点:
1.创建一个新线程的代价要比创建一个进程小得多。
2.线程拿的是进程的一部分资源,占用的资源自然比进程少
3.可充分利用多处理器的可并行数量。
4.在等待慢速IO操作结束的同时,程序也可执行其他计算任务
5.IO密集与计算密集
计算密集:加密解密压缩,为了能在多处理器系统上运行,将计算分配到多个线程中实现
IO密集:下载,为了提高性能会将IO操作重叠,线程可以同时等待不同的IO操作,比如下载一个文件的不同区域
6.与进程先比,线程的切换需要操作系统更少的工作量。要做进程切换,就要做CPU上下文切换(PCB),CPU内部的CR3切换(页表映射)。当前进程想知道当前是哪个进程,只需要查一个全局的指针current(会被优化到寄存器中)即可。
对于线程切换,如果下一个线程仍处于同一个进程(可以根据虚拟地址空间判断),仍然需要切换寄存其中的大部分数据,但是:地址空间,页表是不需要切换的,不需要保存CR3寄存器中的上下文。
7.上下文的切换会扰乱处理器的缓存机制, cache命中也是实现局部性原理的重要一环。TLB也会缓存虚拟和物理的映射,而进程切换会导致TLB和Cache失效,下次运行需要重新缓存。
缺点:
其实都是因为线程太多导致的,进程也同样有这个问题
1.线程并不是越多越好。对于多处理器进行计算密集应用,如果有多于处理器数量的线程被创建,反而可能会增加额外的同步和调度开销从而降低效率。
2.健壮性降低
◦ 编写多线程需要更全⾯更深⼊的考虑,在⼀个多线程程序⾥,因时间分配上的细微偏差或者
因共享了不该共享的变量⽽造成不良影响的可能性是很⼤的,换句话说线程之间是缺乏保护
的。
3.缺乏访问控制
◦ 进程是访问控制的基本粒度,在⼀个线程中调⽤某些OS函数会对整个进程造成影响。
注:其实访问控制同时也是线程的优点。只要代码的健壮性够高线程就百利难有一害
4.编程难度提⾼
◦ 编写与调试⼀个多线程程序⽐单线程程序困难得多
线程 vs 进程
线程有自己独立的上下文数据,这就是线程被独立调度的逻辑
线程有自己的栈结构:线程是一个动态的概念。
进程是资源分配的基本单位
线程是调度的基本单位
线程共享进程数据(进程地址空间共享),但也有自己的一部分"私有"数据
◦ 线程ID
◦ ⼀组寄存器,线程的上下⽂数据
◦ 栈
◦ errno
◦ 信号屏蔽字◦ 调度优先级
进程的多个线程共享资源
同⼀地址空间,因此 Text Segment 、 Data Segment 都是共享的,如果定义⼀个函数,在各线程中
都可以调⽤,如果定义⼀个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
• ⽂件描述符表• 每种信号的处理⽅式(SIG_ IGN、SIG_ DFL或者⾃定义的信号处理函数)
• 当前⼯作⽬录
• ⽤⼾id和组id
二.线程控制
1.验证线程由进程模拟
验证:线程由进程模拟实现------使用第三方库,从此就有了新线程,主线程的关系。新线程,代表一组虚拟地址,这些代码就是虚拟地址对应的代码和数据,主线程也是如此。
cpp
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <pthread.h>
#include <cstdio>
#include <cstring>
void* routine(void* args){
std::string str = static_cast<char *>(args);
while(1){
std::cout << "我是新线程:" << str << std::endl;
sleep(1);
}
}
int main(){
pthread_t tid;
pthread_create(&tid, nullptr, routine, (void*)"thread-1");
while(1){
std::cout << "我是主线程..." << std::endl;
sleep(1);
}
return 0;
}要注意的是,这里我们创建线程并不是使用系统调用,在编译链接时需要加选项-pthread
运行结果如下:
cpp
g++ -o test_thread testThread.cpp -std=c++11 -lpthread
wujiahao@VM-12-14-ubuntu:~/testThread$ ./test_thread
我是主线程...我是新线程:thread-1
我是主线程...
我是新线程:thread-1
我是新线程:thread-1
我是主线程...
我是新线程:thread-1
我是主线程...特别的,要想查到进程内的线程,需要用指令,而kill进程时会让所有线程退出,杀死进程。这也就验证了信号有多线程共享
ps -aL
cpp
wujiahao@VM-12-14-ubuntu:~$ ps -aL
PID LWP TTY TIME CMD
86549 86549 pts/0 00:00:00 test_thread
86549 86550 pts/0 00:00:00 test_thread
86552 86552 pts/1 00:00:00 ps注意:
LWP:light weight process
因此在进程的task_struct中,还会存在一个字段叫pid_t lwp。CPU调度的时候,看的是lwp,而不是pid。在只有一个执行流时,lwp和pid是同一个值。
1.关于调度的时间片分配:等分给不同线程
2.线程可能会出异常。出异常后会如何?
cpp
void* routine(void* args){
std::string str = static_cast<char *>(args);
while(1){
std::cout << "我是新线程:" << str << std::endl;
int a=10;
a/=0;
sleep(1);
}
}可以看到,只要一个线程出现异常,一整个进程都会崩溃。
cpp
wujiahao@VM-12-14-ubuntu:~/testThread$ ./test_thread
我是主线程...
我是新线程:thread-1
Floating point exception (core dumped)3.上面的这个代码,多线程在打印消息会混在一起,是为什么?
显示器文件是共享资源,在没有加保护时就会出现数据不一致
2.引入pthread库
为什么在linux下创建线程需要一个库?这个库是什么?
Linux系统不存在真正意义上的线程,他所谓的概念是使用轻量级进程模拟的。操作系统中,用轻量级进程模拟线程也只是我们的说法。
所以,Linux系统只会提供创建轻量级进程的系统调用,比如vfork和clone------和父进程共享地址空间。
为了处理用户和系统之间的这些差异,于是设计了pthread库将创建轻量级进程封装,给用户提供创建线程的接口。
1.线程控制的接口
C++11 多线程:在Linux下照样也是封装了pthread库的
C++封装线程库的目的:为了保证语言的跨平台和可移植性
换句话说,语言的跨平台和可移植,如何实现?所有平台全都写一份,按条件编译形成库。
所有语言的线程相关接口有且只有一种实现方法:封装pthread库
2.创建线程:pthread_create
cpp
NAME
pthread_create - create a new thread
SYNOPSIS
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
Compile and link with -pthread.线程创建好之后,新线程要被主线程等待,否则会产生类似僵尸进程的问题------内存泄漏
主线程只需要使用join即可
cpp
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <pthread.h>
#include <cstdio>
#include <cstring>
void* routine(void* args){
std::string str = static_cast<char *>(args);
int cnt=3;
while(cnt--){
std::cout << "我是新线程:" << str << std::endl;
sleep(1);
}
}
int main(){
pthread_t tid;
int n= pthread_create(&tid, nullptr, routine, (void*)"thread-1");
pthread_join(tid, nullptr);
return 0;
}结果如下:新进程被主线程等待成功,新线程退出后,主线程也退出。
cpp
wujiahao@VM-12-14-ubuntu:~/testThread$ ./test_thread
我是新线程:thread-1
我是新线程:thread-1
我是新线程:thread-1
当我们打印出tid时,发现其值跟lwp不同:
cpp
tid:140177831552576
我是新线程:thread-1
我是新线程:thread-1
我是新线程:thread-1打印出来的tid是通过pthread库中的函数pthread_self得到的,它返回一个pthread_t类型的变量,指代的是调用pthread_self函数的线程的"ID"。
如何理解这个id?这个id是pthread库给每个线程定义的进程内唯一标识,是pthread库维持的。
由于每个进程有自己独立的内存空间,故此ID的作用域是进程而非系统(内核不认识)。
其实pthread库也是通过内核提供的系统调用(比如vfork,clone)来创建线程的。而内核会为每个线程创建系统全局唯一的"ID"来标识这个线程。
其实,线程的tid,就不应该是lwp。因为我们使用的线程是封装的pthread库,lwp作为被封装的一种数据不应该暴露出来。
tips:LWP 是什么呢?
LWP 得到的是真正的线程ID。之前使⽤ pthread_self 得到的这个数实际上是⼀个地址,在虚拟地址空间上的⼀个地址,通过这个地址,可以找到关于这个线程的基本信息,包括线程ID,线程栈,寄存器等属性。
在 ps -aL 得到的线程ID,有⼀个线程ID和进程ID相同,这个线程就是主线程,主线程的栈在虚拟地址空间的栈上,⽽其他线程的栈在是在共享区(堆栈之间),因为pthread系列函数都是pthread库提供给我们的。⽽pthread库是在共享区的。所以除了主线程之外的其他线程的栈都在共享区。
3.pthread_self:谁调用,就返回谁的tid
cpp
NAME
pthread_self - obtain ID of the calling thread
SYNOPSIS
#include <pthread.h>
pthread_t pthread_self(void);
Compile and link with -pthread.4.main函数是不是也是一个线程?那么它是不是也会有一个tid?
cpp
我是主线程,我的tid:tid:1400106484096645.线程传参和返回值
多线程进程地址空间是共享的,可以同时访问同一个函数。例如上面的FormatID。
我们可以设置一个全局的变量flag,让新线程每次循环++flag,主线程打印flag
线程领域的资源是可以直接共享的。那么对于Format函数,是不是就是重入函数?
对于这个函数来说,是可重入的,不会出现问题,因为使用的是一个临时的空间。
cpp
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <pthread.h>
#include <cstdio>
#include <cstring>
int flag = 100;
void showtid(pthread_t &tid)
{
printf("tid: 0x%lx\n", tid);
}
std::string FormatId(const pthread_t &tid)
{
char id[64];
snprintf(id, sizeof(id), "0x%lx", tid);
return id;
}
// code done, result ok
// code done, result not ok
// code no finish
void *routine(void *args)
{
std::string name = static_cast<const char *>(args);
pthread_t tid = pthread_self();
int cnt = 5;
while (cnt)
{
std::cout << "我是一个新线程: 我的名字是: " << name << " 我的Id是: " << FormatId(tid) << std::endl;
sleep(1);
cnt--;
flag++;
}
return (void *)123; // 暂时:线程退出的时候的退出码
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, routine, (void *)"thread-1");
showtid(tid);
int cnt = 5;
while (cnt)
{
std::cout << "我是main线程: 我的名字是: main thread" << " 我的Id是: "
<< FormatId(pthread_self()) << ", flag: " << flag << std::endl;
sleep(1);
cnt--;
}
void *ret = nullptr; // ret也是一个变量!!也有空间哦!
pthread_join(tid, &ret);
std::cout << "ret is : " << (long long int)ret << std::endl;
return 0;
}返回值:
我们新线程执行的方法返回值是void*的,主线程在进行等待新线程(join)时会捕捉这个返回值。
我们可以看看join的参数:
cpp
NAME
pthread_join - join with a terminated thread
SYNOPSIS
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
Compile and link with -pthread.
void *routine(void *args)
{
std::string name = static_cast<const char *>(args);
pthread_t tid = pthread_self();
int cnt = 5;
while (cnt)
{
std::cout << "我是一个新线程: 我的名字是: " << name << " 我的Id是: " << FormatId(tid) << std::endl;
sleep(1);
cnt--;
flag++;
}
return (void *)123; // 暂时:线程退出的时候的退出码
}至于返回值返回到哪,从哪里拿到的返回值,我们暂时把这个问题保留。
主线程:怎么在join的时候没有看到异常相关的字段呢?我们知道代码运行的结果有三种:
cpp
// code done, result ok
// code done, result not ok
// code no finishjoin这里为什么只有一个拿到退出码的选项?等待的目标线程如果异常,整个进程都会退出,包括main线程,所以join定义异常字段没有意义,也看不到。异常信号是进程处理的话题
3.页表与页表项
页目录表的表像存储页表的起始地址,在内核中以一个无符号长整形存储------32位。
页表的标志位有12项,我们要表示一个页的起始地址只需要20位,剩下的12位用来存储标志位
cpp
// ⻚表标志位
#define L_PTE_PRESENT (1 << 0)
#define L_PTE_FILE (1 << 1) /* only when !PRESENT */
#define L_PTE_YOUNG (1 << 1)
#define L_PTE_BUFFERABLE (1 << 2) /* matches PTE */
#define L_PTE_CACHEABLE (1 << 3) /* matches PTE */
#define L_PTE_USER (1 << 4)
#define L_PTE_WRITE (1 << 5)
#define L_PTE_EXEC (1 << 6)
#define L_PTE_DIRTY (1 << 7)
#define L_PTE_COHERENT (1 << 9) /* I/O coherent (xsc3) */
#define L_PTE_SHARED (1 << 10) /* shared between CPUs (v6) */
#define L_PTE_ASID (1 << 11) /* non-global (use ASID, v6) */
// ⻚表是?
typedef struct { unsigned long pte; } pte_t; // ⻚表项
typedef struct { unsigned long pgd; } pgd_t; // ⻚全局⽬录项分配页表的结构和函数
cpp
pgd_t *pgd_alloc(struct mm_struct *mm)
{
pgd_t *ret, *init;
ret = (pgd_t *)__get_free_page(GFP_KERNEL | __GFP_ZERO);
init = pgd_offset(&init_mm, 0UL);
if (ret)
{
#ifdef CONFIG_ALPHA_LARGE_VMALLOC
memcpy(ret + USER_PTRS_PER_PGD, init + USER_PTRS_PER_PGD,
(PTRS_PER_PGD - USER_PTRS_PER_PGD - 1) * sizeof(pgd_t));
#else
pgd_val(ret[PTRS_PER_PGD - 2]) = pgd_val(init[PTRS_PER_PGD - 2]);
#endif
/* The last PGD entry is the VPTB self-map. */
pgd_val(ret[PTRS_PER_PGD - 1]) = pte_val(mk_pte(virt_to_page(ret), PAGE_KERNEL));
}
return ret;
}
pte_t *pte_alloc_one_kernel(struct mm_struct *mm, unsigned long address)
{
pte_t *pte = (pte_t *)__get_free_page(GFP_KERNEL | __GFP_REPEAT | __GFP_ZERO);
return pte;
}
struct mm_struct
{
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct *mmap_cache; /* last find_vma result */
unsigned long (*get_unmapped_area)(struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area)(struct mm_struct *mm, unsigned long addr);
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole
below free_area_cache */
unsigned long free_area_cache; /* first hole of size
cached_hole_size or larger */
pgd_t *pgd; // ⻚⽬录起始地址
}4.线程的传参与返回值
问题:新线程的方法中,传参只能用字符串吗?返回时只能是整数吗?
可不可以传入,返回对象?可以!甚至可以是任意类型!
一般来说,main函数结束,代表主线程结束,一般也代表进程结束
新线程对应的入口函数运行结束,代表当前线程结束
证明:创建线程传参可以传入一个对象,用于派发任务和返回结果。
我们先写一个Task类用于分发任务,再写一个Result类返回结果。
cpp
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <pthread.h>
#include <cstdio>
#include <cstring>
class Task
{
public:
Task(int a, int b) : _a(a), _b(b) {}
int Execute()
{
return _a + _b;
}
~Task() {}
private:
int _a;
int _b;
};
class Result
{
public:
Result(int result) : _result(result)
{
}
int GetResult() { return _result; }
~Result() {}
private:
int _result;
};
int flag = 100;
void showtid(pthread_t &tid)
{
printf("tid: 0x%lx\n", tid);
}
std::string FormatId(const pthread_t &tid)
{
char id[64];
snprintf(id, sizeof(id), "0x%lx", tid);
return id;
}
void *routine(void *args)
{
Task *task=static_cast<Task *>(args);
sleep(1);
Result *result=new Result(task->Execute());
sleep(1);
return result;
}
int main()
{
pthread_t tid;
Task *t=new Task(120,230);
pthread_create(&tid, nullptr, routine, t);
Result *ret=nullptr;
pthread_join(tid, (void **)&ret);
//join成功后,返回result对象
long long n=ret->GetResult();
std::cout<<"新线程结束,退出码为:"<<n<<std::endl;
return 0;
}结果:
cpp
wujiahao@VM-12-14-ubuntu:~/testThread$ ./test_thread
新线程结束,退出码为:3505.线程的终止
1.线程终止:现成的入口函数进行return就是线程终止
cpp
void *routine(void *args)
{
Task *task=static_cast<Task *>(args);
sleep(1);
Result *result=new Result(task->Execute());
sleep(1);
return result;
}调用exit可以让线程退出吗?不能!exit是终止进程的!
2.调用pthread_exit退出线程
cpp
void *routine(void *args)
{
Task *task=static_cast<Task *>(args);
sleep(1);
Result *result=new Result(task->Execute());
sleep(1);
pthread_exit(result);
}3.pthread_cancel:取消线程,常规做法是主线程调用来取消新线程
子问题:主线程和新线程谁先运行?不确定,因为底层是轻量级进程,谁先运行取决于调度。
cpp
int main()
{
pthread_t tid;
Task *t=new Task(120,230);
pthread_create(&tid, nullptr, routine, t);
sleep(3);
pthread_cancel(tid);
Result *ret=nullptr;
pthread_join(tid, (void **)&ret);
long long n=ret->GetResult();
std::cout<<"新线程结束,退出码为:"<<n<<std::endl;
return 0;
}新线程退出被join后,结果是-1.这个值是一个宏值:PTHREAD_CANCELED.
join拿到的就是线程退出时设定的返回值,不考虑实际线程运行结果如何。
3.如果主线程不想再关心新线程,而是让它结束的时候让他自己释放,怎么做?设置线程为分离状态。
县城默认是需要被等待的:joinable,如果要达到上面的效果,就需要将线程设置为分离状态(detach)
线程分离,可以由新线程主动分离,也可以主线程分离新线程。
即便线程分离了,它依然在当前的地址空间中,进程的所有资源被分离的线程依然可以访问操作,只不过主线程不等待新线
对线程设置分离:pthread_detach
cpp
NAME
pthread_detach - detach a thread
SYNOPSIS
#include <pthread.h>
int pthread_detach(pthread_t thread);
Compile and link with -pthread.主分离新:分离之后不可被join,主线程join失败返回错误码。
cpp
int main()
{
pthread_t tid;
Task *t=new Task(120,230);
pthread_create(&tid, nullptr, routine, t);
sleep(3);
pthread_detach(tid);
std::cout<<"新线程被分离"<<std::endl;
Result *ret=nullptr;
int n=pthread_join(tid, (void **)&ret);
if(n!=0){
std::cout<<"pthread_join error"<<strerror(n)<<std::endl;
}
long long n=ret->GetResult();
std::cout<<"新线程结束,退出码为:"<<n<<std::endl;
return 0;
}新主动分离
cpp
void *routine(void *args)
{
pthread_detach(pthread_self());
Task *task=static_cast<Task *>(args);
sleep(1);
Result *result=new Result(task->Execute());
sleep(1);
pthread_exit(result);
}6.创建多线程
创建与等待,需要一个一个等待
下面的写法会导致一个线程安全问题:多个执行流访问同一个没有被保护的临界资源,就会造成数据不一致问题。
我们只需要给每个线程创建一个id独立的空间即可。修改完id对应空间的数据就可以直接释放。
cpp
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <pthread.h>
#include <cstdio>
#include <cstring>
const int num = 10;
void *routine(void *args)
{
sleep(1);
std::string name = static_cast<const char *>(args);
//给每个线程创建一个id独立的空间,修改完id对应空间的数据就可以被释放。
delete (char*)args;
int cnt = 5;
while (cnt--)
{
std::cout << "new线程名字: " << name << std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
// char id[64];
std::vector<pthread_t> tids;
for (int i = 0; i < num; i++)
{
pthread_t tid;
// bug??
char *id = new char[64];
snprintf(id, 64, "thread-%d", i);
int n = pthread_create(&tid, nullptr, routine, id);
if (n == 0)
tids.push_back(tid);
else
continue;
}
for (int i = 0; i < num; i++)
{
// 一个一个的等待
int n = pthread_join(tids[i], nullptr);
if (n == 0)
{
std::cout << "等待新线程成功" << std::endl;
}
}
return 0;
}三.线程ID与地址空间布局
Linux没有真正的线程,只是用轻量级进程模拟的------操作系统提供的接口不是线程的接口,而是轻量级进程的。
在用户层,封装轻量级进程形成原生线程库。用户级别的库,可执行程序都是ELF格式,我的可执行程序加载,形成进程,动态链接和动态地址重定向,要将动态库加载到内存,映射到当前进程的地址空间中
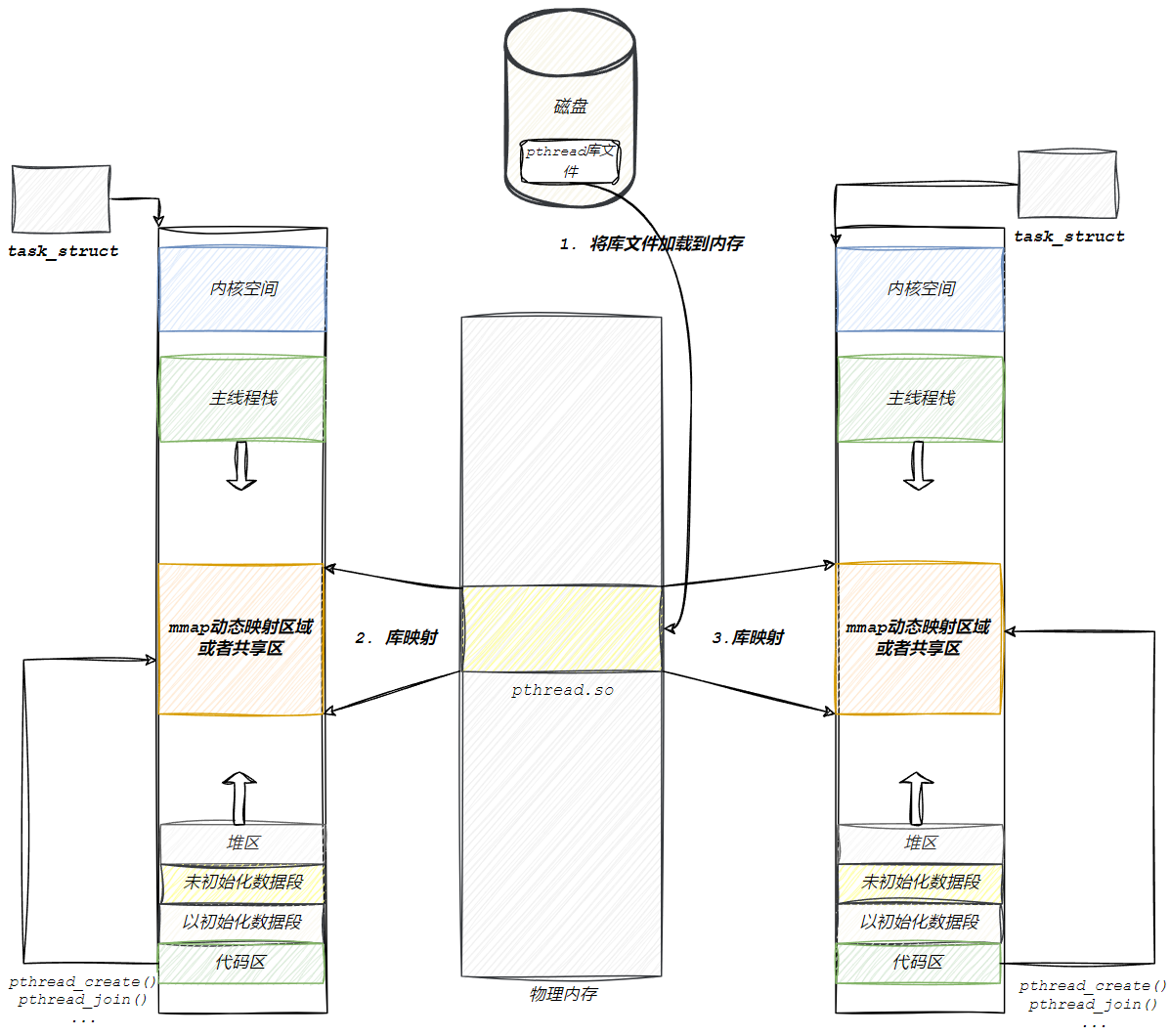
进程自己的代码区可以访问到pthread库内部的函数或数据
所以说,线程的概念是在库中维护的,在库内部就一定存在多个被创建好的线程,库一定会管理线程。
先描述,再组织
cpp
struct tcb{
//线程应该有的属性
线程状态
线程id
线程独立的栈结构
线程栈大小
...
}为什么要在库里创建tcb?因为我们会使用创建一个返回tcb的接口:pthread_create!
整个线程的概念,关于调度等部分由内核lwp实现,关于上面的基本信息由用户层的库实现
mmap区域:动态库所加载的区域'
线程结束后,会把返回值写回struct_pthread中的ret值中,线程运行结束后,但库里对应的数据块不会被释放,所以线程需要join。而在join时,会传入tid------对应数据块的起始地址,然后将返回值ret通过join带出来。最后释放线程对应的数据块。
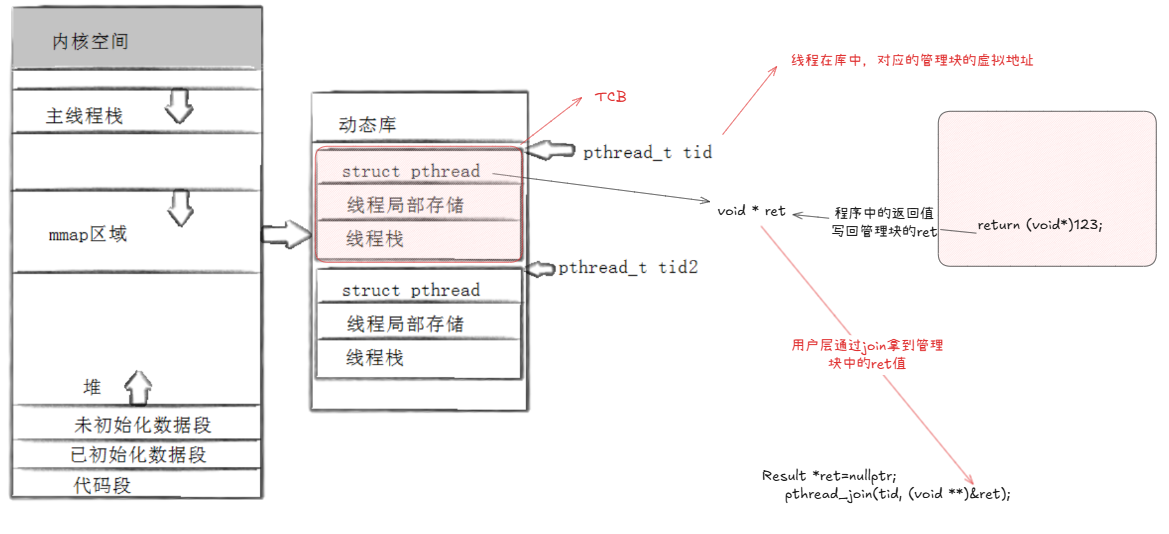
每个线程都有自己独立的栈空间,主线程使用内核中的栈,新栈使用数据块中的栈
当我们调用pthread_create,它既会在库中创建县城控制的管理块,也会在内核中调用系统调用clone创建轻量级进程。当CPU调度当前新线程时,会执行它所对应的routine方法,并将这个方法传给clone,将产生和使用的数据入自己的线程栈,并且将线程栈也返回给clone。新县城的id就对应其数据块struct_pthread的起始地址
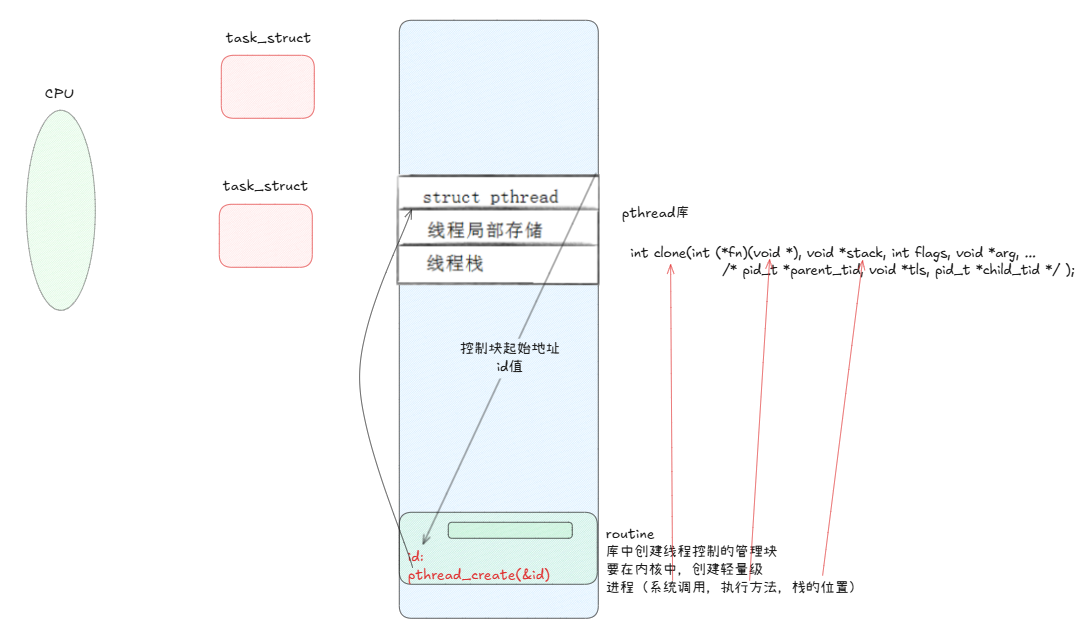
用户线程和lwp如何联动?
例如:你叫舍友张三帮你带饭,你只需要明确好什么时候,让谁,带什么,多久回来这些基本信息就好。张三去买饭时就是你的代表。
而对于操作系统也一样要创建线程,在用户空间创建线程控制块,指定好要做的方法,把临时数据保存到线程自己的线程栈中,在用户看来就创建好了线程,但是执行却还是由内核创建的轻量级进程完成的。唯一要做的就是线程执行完毕后,把结果写回用户空间的ret中。
Linux用户级线程:内核LWP=1:1
回答上面的三个问题:
线程ID:pthread_create创建时返回的线程控制块的首地址
线程传参和返回值:将线程的返回值写入到控制块的void*中,然后通过join获取返回值
线程分离:struct tcb中存在一个线程状态,默认为1------joinable。
Linux所有线程,都在库里。