零拷贝概览
"零拷贝"(Zero Copy )是 Linux 系统中一个非常重要的性能优化技术,尤其在 高性能网络编程 和 大文件传输 中应用广泛。
🧠 什么是"零拷贝"?
零拷贝(Zero Copy) 指的是:数据在内核空间和用户空间之间传输时,尽量避免不必要的拷贝操作,从而提高性能、降低 CPU 占用。
它并不是真的"0 次拷贝",而是 相比传统方式减少了数据复制次数。
🔁 传统 I/O 数据传输流程(以发送文件为例)
比如你用 read() + write() 从磁盘读取文件并发送到 socket:
- 硬盘 ➜ 内核缓冲区(DMA,1 次)
- 内核缓冲区 ➜ 用户空间(
read(),2 次) - 用户空间 ➜ 内核 socket 缓冲区(
write(),3 次) - socket 缓冲区 ➜ 网卡(DMA,4 次)
🚨 总共 4 次数据拷贝,其中 2 次是 CPU 参与拷贝。
✅ 零拷贝的方式(减少拷贝次数)
Linux 提供多种机制实现"零拷贝"效果:
1. sendfile()(最经典的零拷贝)
将 文件直接发送到 socket,不需要用户态缓冲区:
c
sendfile(out_socket, in_fd, NULL, file_size);流程变成:
- 硬盘 ➜ 内核 page cache(DMA)
- page cache ➜ 网卡(DMA)
✅ 仅需 2 次 DMA 拷贝,CPU 不参与复制数据。
2. mmap() + write()(半零拷贝)
将文件 mmap 到用户空间地址,然后 write():
c
void* data = mmap(NULL, size, PROT_READ, MAP_SHARED, fd, 0);
write(sock_fd, data, size);- 减少了一次用户态复制,但写 socket 仍需复制数据。
3. splice() + tee()(管道零拷贝)
适用于 文件/socket/pipe 的零拷贝数据流传输:
c
int pipefd[2];
pipe(pipefd);
splice(file_fd, NULL, pipefd[1], NULL, size, SPLICE_F_MORE);
splice(pipefd[0], NULL, sock_fd, NULL, size, SPLICE_F_MORE);通过 pipe buffer 中的 page 引用 实现传输。
🧪 应用场景
- Web服务器 :Nginx、Tomcat 用
sendfile()提升文件下载性能 - Kafka:用零拷贝将消息批量写入 socket
- 大文件传输系统:避免 CPU 成为性能瓶颈
- 高性能消息队列/日志系统
📈 零拷贝的优势
| 优点 | 说明 |
|---|---|
| 🚀 高吞吐量 | 少了多次内存拷贝,数据传输更快 |
| 🧠 低 CPU 消耗 | 拷贝操作由 DMA 执行,CPU 更轻松 |
| 🧵 更高并发能力 | 空出 CPU 核心处理更多连接 |
| 🔋 更省电 | CPU 空转少了,在服务端非常关键 |
⚠️ 零拷贝的限制或注意事项
| 限制 | 说明 |
|---|---|
| sendfile 只能用于文件 ➜ socket | 不支持内存中的数据传输 |
| 受内核版本和架构支持限制 | splice() 、sendfile() 在部分平台表现不同 |
| 无法压缩/加密等用户处理 | 零拷贝避免了用户态拷贝,也就无法修改数据 |
| mmap 使用复杂且易错 | 内存泄漏/越界访问/共享问题等 |
🧩 总结
| 技术 | 是否用户态拷贝 | 是否完全零拷贝 | 适用场景 |
|---|---|---|---|
| read + write | ✅ 有 | ❌ 否 | 通用逻辑,处理灵活 |
| sendfile | ❌ 无 | ✅ 是 | 文件下载、静态资源 |
| mmap + write | ❓ 视实现而定 | ❌ 否(半零拷贝) | 高效读取但可读写处理 |
| splice | ❌ 无 | ✅ 是 | pipe 传输/中继场景 |
什么是DMA?
是的,你说得对 ------ 硬盘到内存的数据拷贝,如果使用了 DMA(Direct Memory Access,直接内存访问),确实不需要 CPU 参与数据搬运本身。下面我给你详细解释一下:
💡 什么是 DMA?
DMA(Direct Memory Access) 是一种计算机硬件功能,它允许 外设(如硬盘、网卡)直接读写系统内存,而不通过 CPU 拷贝数据。
它的主要目标是:
👉 解放 CPU,提升性能。
🧱 没有 DMA 的传统数据传输方式(CPU 参与拷贝)
举个例子,你从硬盘读取一段数据:
- CPU 先向硬盘控制器发出读取命令。
- 硬盘把数据发送给 CPU。
- CPU 再把数据一字节一字节地写入内存。
🧠 这时候 CPU 就是"数据中介人",既要处理控制指令,还要"亲自搬砖"。
✅ 有了 DMA 后的数据传输流程
DMA 控制器是独立于 CPU 的硬件组件,负责替 CPU 处理数据传输任务。
过程变成:
- CPU 向 DMA 控制器下达指令:"从硬盘读 1MB 数据到内存地址 X。"
- CPU 就可以干别的事去了!
- DMA 控制器接手,从硬盘读数据,并直接写入内存。
- 传输完成后,DMA 会通过中断通知 CPU。
💥 数据路径:硬盘 ➜ DMA ➜ 内存,CPU 不参与传输过程。
📦 哪些设备用到 DMA?
- 磁盘控制器(SATA、NVMe 等)
- 网络接口卡(网卡 zero copy 也靠 DMA)
- 声卡
- 显卡(PCIe 显存映射)
📈 为什么 DMA + 零拷贝性能好?
- 省了 CPU 做搬运工,可以用来处理业务逻辑
- 省了一次或多次 内存拷贝
- 避免 缓存污染(CPU 缓存被搬运数据污染)
- 降低上下文切换,减少中断次数
🎯 总结一下
| 对比点 | 传统方式 | DMA |
|---|---|---|
| CPU 是否拷贝数据 | ✅ 是 | ❌ 否 |
| 是否并发传输 | ❌ 不行 | ✅ 可以 |
| 性能 | 较低 | 较高 |
| 实用场景 | 控制少量数据 | 大数据量、高速传输,如网卡/硬盘 |
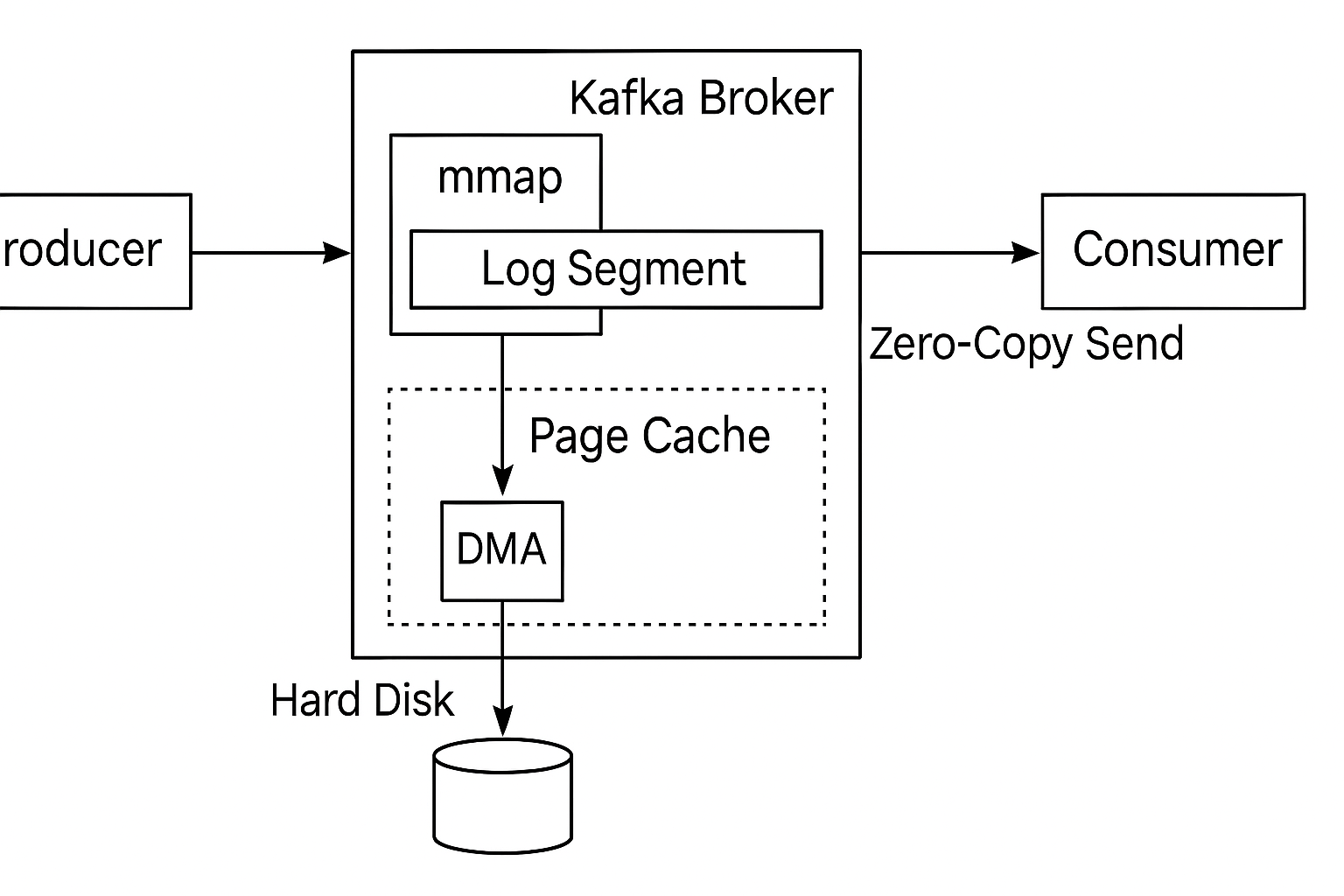
kafka的应用
🧠 Kafka 的高性能底层机制概览
Kafka 之所以性能这么猛,和以下三点息息相关:
- Page Cache(页缓存)
- mmap(内存映射)
- Zero-Copy Send(零拷贝发送)
这三者是配合使用的,一起实现了"写磁盘快 + 读磁盘快 + 发网络快"的闭环。
🔹 1. Page Cache:把磁盘文件当作内存用!
Kafka 消息写入磁盘时并不是直接 write(),而是写入操作系统的页缓存(Page Cache)。操作系统自动将数据缓存在内存中,等空闲时才异步刷盘(flush 到磁盘)。
好处:
- 写入速度快(操作系统只是在内存里改一改)
- 提高磁盘 IO 吞吐(批量落盘)
- 后续读操作可能直接命中缓存,避免磁盘 IO
Kafka 本身不做复杂缓存逻辑,直接利用 Linux 的 Page Cache 机制,简洁高效。
🔹 2. mmap:把磁盘文件映射成内存,顺序读写
Kafka 不通过 read() 或 write(),而是用 mmap 把日志文件映射成内存。
这样,写消息时只是改了内存,OS 自动把改动同步到磁盘(脏页刷盘)。
优点:
- 避免了用户空间和内核空间的拷贝(一次性写到 Page Cache)
- 文件变成内存数组一样操作,方便且高效
- 对消费者来说也更快,尤其是顺序读场景
Kafka 的 log segment 文件和索引文件都通过 mmap 进行访问。
🔹 3. Zero-Copy Send:文件直接发到网络,无需经过用户态
当 Kafka 把数据发送给消费者时(通过 socket),它用了一个高级的 Linux 特性:sendfile() 系统调用。
sendfile() 可以将文件数据直接从磁盘的 Page Cache 发送到网卡,完全绕过用户空间,不需要自己先 read 然后 write。
这个过程称为 零拷贝(zero-copy),其实是:
plain
传统方式:
硬盘 → 内核 → 用户空间 → 内核 socket buffer → 网卡
zero-copy:
硬盘 → 内核 Page Cache → 直接送往网卡好处:
- 避免两次上下文切换(read + write)
- 避免两次数据拷贝
- 大幅减少 CPU 消耗
- 提高吞吐,Kafka 每秒可传输上百万消息
🧱 Kafka 的数据流程小结
plain
Producer 发送数据 →
Kafka Broker 使用 mmap 写入磁盘(实际落在 Page Cache) →
Consumer 请求数据 →
Kafka 用 sendfile() 把数据从 Page Cache 直接发给 Consumer整个过程:
- 顺序写
- 内存映射(避免 read/write)
- Page Cache 提高缓存命中率
- 零拷贝发送(减少 CPU 和拷贝成本)
💡 总结
| 技术 | Kafka 中作用 |
|---|---|
| Page Cache | 减少磁盘 IO,提升写入速度 |
| mmap | 像操作内存一样操作文件,简化写入 |
| sendfile/zero-copy | 高效发送消息,绕过用户态,极大减轻 CPU 压力 |
这三者的配合让 Kafka 成为业界吞吐量最高的消息系统之一,在大数据、实时日志、消息中台等场景里无可替代。