LangChain 入门教程:06LangGraph工作流编排
本页快捷跳转
- 目录:
- 引言
- [LangGraph 工作实现代码](#LangGraph 工作实现代码 "#workflow-code")
- [1、LangGraph 基础内容展示](#1、LangGraph 基础内容展示 "#basic-demo")
- [2、LangGraph 循环内容展示](#2、LangGraph 循环内容展示 "#loop-demo")
- [3、LangGraph 嵌套内容展示](#3、LangGraph 嵌套内容展示 "#nested-demo")
- [常见问题与快速排查 (Q/A)](#常见问题与快速排查 (Q/A) "#qa")
- 总结
- 术语与别名(便于检索与问法对齐)
本页摘要
- 主题:LangGraph 工作流编排入门
- 任务:状态管理、条件分支、循环、嵌套、检查点
- 快速问法:LangGraph 教程;如何创建状态图;条件路由怎么写;如何保存状态;如何可视化工作流图
- 关键词:StateGraph、ToolNode、MemorySaver、Conditional Edge、Checkpointer、Workflow
引言
当你开始组合多个 Agent 与多个 Tool 时,纯 LangChain 流程的编排和状态传递会变得复杂。LangGraph 提供"基于状态图的工作流"能力,让你用节点、边和条件路由清晰地组织复杂流程。
LangGraph概念
LangGraph 核心概念(状态图、节点、边、条件边):
- StateGraph:状态图。定义节点与边,并管理共享状态。
- 节点(Node):处理函数。读取并返回状态,用于对话、工具执行、更新记忆等。
- 边(Edge):节点之间的连接,描述状态如何流转。
- 条件边(Conditional Edge):由路由函数返回的"标签"决定下一跳;返回值必须与映射表的键一致。
LangGraph 工作实现代码
环境配置
requirements.txt
text
# 核心
langgraph>=0.6.10
langchain>=0.3.27
langchain-core>=0.3.76
# OpenAI 提供商(使用 OpenAI API 时需要)
langchain-openai>=0.3.28
# 本地模型(使用 Ollama 时需要)
langchain-ollama>=0.3.10
# 社区集成
langchain-community>=0.3.31
# 常用辅助
tiktoken>=0.9.0
python-dotenv>=1.1.1.env
text
OPENAI_API_KEY=your_api_key_here
OPENAI_BASE_URL=https://api.deepseek.com
OPENAI_MODEL=deepseek-chat
OPENAI_TEMPERATURE=0.2
OPENAI_MAX_TOKENS=512
TAVILY_API_KEY= your_tavily_api_key_here1、LangGraph 基础内容展示
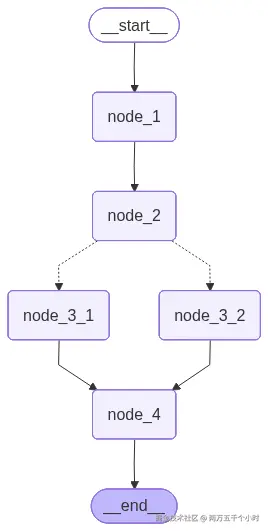
我们要完成"LangGraph基础工作流结构图"中的所有节点和边的实现。
- 1、节点的链式链接(Sequential Nodes):节点按顺序执行,每个节点的输出作为下一个节点的输入,形成线性工作流。
- 2、节点的条件分支(Conditional Edges):根据路由函数返回的标签(如"tools"、"END"),决定下一跳节点,实现动态分支选择。
python
from dataclasses import dataclass
from langgraph.graph import StateGraph, END
# 定义状态类
@dataclass
class BaseState:
"""定义LangGraph工作流的状态类"""
count: int = 0 # 记录节点执行次数
def node_1(state: BaseState) -> BaseState:
"""第1节点:打印日志并递增计数"""
print(f"节点1")
state.count += 1
return state
def node_2(state: BaseState) -> BaseState:
"""第2节点:进入分叉并递增计数"""
print(f"节点2分叉")
state.count += 1
return state
def node_3_1(state: BaseState) -> BaseState:
"""分支 3_1:递增计数"""
print(f"节点3_1")
state.count += 1
return state
def node_3_2(state: BaseState) -> BaseState:
"""分支 3_2:递增计数"""
print(f"节点3_2")
state.count += 1
return state
def node_4(state: BaseState) -> BaseState:
"""第4节点:结束前递增计数"""
print(f"节点4")
state.count += 1
return state
def route_node(state: BaseState) -> str:
"""根据状态路由到下一个节点(奇偶分支)
- 偶数:返回 'node_3_1'
- 奇数:返回 'node_3_2'
返回值必须与 add_conditional_edges 的映射键保持一致
"""
# 与 add_conditional_edges 映射键保持一致
# 简单路由逻辑:根据计数奇偶路由不同分支
return "node_3_1" if (state.count % 2 == 0) else "node_3_2"
# 创建LangGraph工作流
def create_workflow():
"""创建 LangGraph 基础工作流:
node_1 -> node_2 -> (node_3_1 | node_3_2) -> node_4 -> END
"""
# 初始化状态图并绑定状态类型
workflow = StateGraph(BaseState)
# 注册所有节点名称与处理函数
workflow.add_node("node_1",node_1)
workflow.add_node("node_2",node_2)
workflow.add_node("node_3_1",node_3_1)
workflow.add_node("node_3_2",node_3_2)
workflow.add_node("node_4",node_4)
# 设置入口点与边连接(顺序 + 条件分支)
workflow.set_entry_point("node_1")
# 工作流顺序:1 -> 2
workflow.add_edge("node_1","node_2")
# 条件分支:
# - route_node 返回 'node_3_1' 或 'node_3_2'
# - 显式映射确保导出图中清晰展示两个分支,并在返回非法值时提前报错
workflow.add_conditional_edges(
"node_2",
route_node,
{"node_3_1": "node_3_1", "node_3_2": "node_3_2"}
)
# 分支收敛到节点4并结束
workflow.add_edge("node_3_1","node_4")
workflow.add_edge("node_3_2","node_4")
workflow.add_edge("node_4",END)
# 编译图为可执行应用
app = workflow.compile()
# 导出工作流可视化图(Mermaid PNG)。该方法默认请求在线服务:
# - 如本地网络受限,可改为保存 Mermaid 源并离线渲染
# - 如需保存到脚本同目录,可改为:os.path.join(os.path.dirname(__file__), 'flow_01.png')
app.get_graph().draw_mermaid_png(output_file_path = 'blog/flow_01.png')
return app
def main() -> None:
"""运行工作流并输出最终计数"""
# 1) 创建工作流应用
app = create_workflow()
# 2) 初始化状态(count=0)
initial_state = BaseState()
# 3) 执行工作流
final_state = app.invoke(initial_state)
# 4) 兼容返回类型(dict 或状态对象)
count_val = final_state.get("count") if isinstance(final_state, dict) else getattr(final_state, "count", None)
# 输出最终计数(即经过的节点数)
print("最终计数:" + str(count_val))
if __name__ == "__main__":
main()LangGraph 基础工作流构建要点:
- 1、创建状态图:"workflow = StateGraph(BaseState)" - 基于状态类初始化工作流图
- 2、添加图节点:"workflow.add_node("node_1",node_1)" - 指定节点名称和对应的处理函数
- 3、设置起始节点:"workflow.set_entry_point("node_1")" - 定义工作流的入口节点
- 4、添加普通边:"workflow.add_edge("node_1","node_2")" - 建立节点间的线性执行路径
- 5、添加条件边:"workflow.add_conditional_edges("node_2",route_node,{"node_3_1": "node_3_1", "node_3_2": "node_3_2"})" - 基于路由函数实现动态分支选择
- 6、添加结束节点:"workflow.add_edge("node_4",END)" - 标记工作流的终止节点
- 7、编译工作流:"app = workflow.compile()" - 将图结构编译为可执行应用
- 8、生成可视化图:"app.get_graph().draw_mermaid_png(output_file_path = 'blog/flow_01.png')" - 输出Mermaid格式的工作流图表
2、LangGraph 循环内容展示
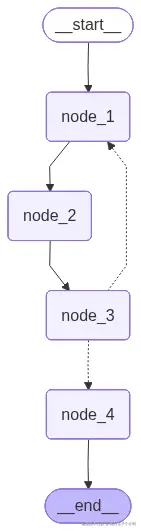
我们要完成"LangGraph循环工作流结构图"中的所有节点和边的实现。
- 1、节点循环操作注意事项:需要设置合理的终止条件,避免死循环和无限循环问题。
- 2、节点循环实现机制:通过条件路由函数控制循环流程,根据节点状态决定是否继续循环执行。
python
from dataclasses import dataclass
from langgraph.graph import StateGraph, END
# 定义状态类
@dataclass
class BaseState:
"""定义LangGraph工作流的状态类"""
count: int = 0
finished: bool = False
def node_1(state: BaseState) -> BaseState:
print(f"节点1")
state.count += 1
return state
def node_2(state: BaseState) -> BaseState:
print(f"节点2")
state.count += 1
return state
def node_3(state: BaseState) -> BaseState:
print(f"节点3分叉")
state.count += 1
if (state.count>3):
state.finished = True
return state
def node_4(state: BaseState) -> BaseState:
print(f"节点4")
state.count += 1
return state
MAX_LOOPS = 10
def route_node(state: BaseState) -> str:
"""根据状态路由到下一个节点,并添加退出条件避免无限循环"""
if state.finished:
return "node_4"
return "node_1"
# 创建LangGraph工作流
def create_workflow():
"""创建LangGraph工作流"""
# 初始化状态图
workflow = StateGraph(BaseState)
# 添加节点
workflow.add_node("node_1",node_1)
workflow.add_node("node_2",node_2)
workflow.add_node("node_3",node_3)
workflow.add_node("node_4",node_4)
# 设置入口点和边连接
workflow.set_entry_point("node_1")
# 工作流顺序
workflow.add_edge("node_1","node_2")
workflow.add_edge("node_2","node_3")
# 条件分支:node_3 根据路由选择进入 node_1 或最终 node_4
workflow.add_conditional_edges(
"node_3",
route_node,
{"node_1": "node_1", "node_4": "node_4"}
)
# 注意:不再添加直接边 node_3 -> node_4,避免与条件分支重复导致并发写入
# 最终收尾后结束
workflow.add_edge("node_4", END)
# 编译图
app = workflow.compile()
# 生成工作流可视化图
app.get_graph().draw_mermaid_png(output_file_path = 'blog/flow_02.png')
return app
def main() -> None:
# 创建工作流
app = create_workflow()
initial_state = BaseState()
final_state = app.invoke(initial_state)
# LangGraph 返回值可能是字典或状态对象,做兼容处理
count_val = final_state.get("count")
print("最终计数:" + str(count_val))
if __name__ == "__main__":
main()LangGraph 循环工作流构建要点:
- 1、循环节点的实现:通过条件路由函数控制循环流程,确保循环逻辑的正确实现,例如:"node3分支"根据条件再次指向"node1",实现循环执行。
- 2、循环终止条件的设置:需要定义明确的终止条件,设置合理的终止条件避免无限循环或循环次数过多的问题,例如:确保"node3分支"在满足条件时指向"node4",结束循环。
- 3、循环内状态更新的处理:在循环体内部,需要更新状态以反映循环执行的进度,通过状态管理确保数据一致性,避免状态丢失或错误。
3、LangGraph 嵌套内容展示
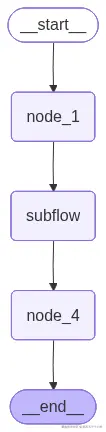
我们要完成"LangGraph嵌套工作流结构图"中的所有节点和边的实现。
- 1、子图节点的实现与父图节点一致:子图遵循与父图相同的节点实现规范,确保代码复用和一致性。
- 2、父图将已编译的子图作为一个节点加入 :通过
add_node方法将编译后的子图作为单个节点集成到父图中。 - 3、父图与子图共享同一状态类型:父子图使用相同的状态类型,子图执行后自动将更新状态返回给父图。
- 4、路由与映射需保持一致:确保子图返回的标签在父图的路由映射中有效,避免非法标签错误。
python
from dataclasses import dataclass
from langgraph.graph import StateGraph, END
@dataclass
class BaseState:
"""工作流共享状态"""
count: int = 0
# ===== 子图节点 =====
def node_2(state: BaseState) -> BaseState:
print("子图-节点2")
state.count += 1
return state
def node_3_1(state: BaseState) -> BaseState:
print("子图-节点3_1")
state.count += 1
return state
def node_3_2(state: BaseState) -> BaseState:
print("子图-节点3_2")
state.count += 1
return state
# 条件路由:根据计数奇偶选择不同分支
# 返回值需与 add_conditional_edges 显式映射的键一致
def route_node(state: BaseState) -> str:
"""根据计数奇偶路由到不同子图节点"""
return "node_3_1" if (state.count % 2 == 0) else "node_3_2"
def create_subworkflow():
"""创建并编译子图:node_2 -> 条件 -> node_3_1 / node_3_2 -> END"""
sub = StateGraph(BaseState)
sub.add_node("node_2", node_2)
sub.add_node("node_3_1", node_3_1)
sub.add_node("node_3_2", node_3_2)
sub.set_entry_point("node_2")
sub.add_conditional_edges(
"node_2",
route_node,
{"node_3_1": "node_3_1", "node_3_2": "node_3_2"}
)
sub.add_edge("node_3_1", END)
sub.add_edge("node_3_2", END)
return sub.compile()
# ===== 父图节点 =====
def node_1(state: BaseState) -> BaseState:
print("父图-节点1")
state.count += 1
return state
def node_4(state: BaseState) -> BaseState:
print("父图-节点4")
state.count += 1
return state
def create_workflow():
"""创建父图,并将已编译的子图作为一个节点加入"""
workflow = StateGraph(BaseState)
workflow.add_node("node_1", node_1)
workflow.add_node("subflow", create_subworkflow()) # 嵌套子图
workflow.add_node("node_4", node_4)
workflow.set_entry_point("node_1")
workflow.add_edge("node_1", "subflow")
workflow.add_edge("subflow", "node_4")
workflow.add_edge("node_4", END)
app = workflow.compile()
# 生成工作流可视化图(如无法联网,可改用 mermaid-cli 离线渲染)
app.get_graph().draw_mermaid_png(output_file_path = 'blog/flow_03.png')
return app
def main() -> None:
app = create_workflow()
initial_state = BaseState()
final_state = app.invoke(initial_state)
# 兼容状态对象或字典形式
count_val = final_state.get("count") if isinstance(final_state, dict) else getattr(final_state, "count", None)
print("最终计数:" + str(count_val))
if __name__ == "__main__":
main()LangGraph 嵌套工作流构建要点:
- 1、子图节点就是一个工作流:子图节点的实现就是一个完整的工作流,包含多个节点和边,子图节点的执行结果会自动返回给父图。
- 2、子图节点也可以作为父图的一个节点 :在子图节点工作流中,还可以添加
add_node子图节点。 - 3、父图与子图嵌套的组合:可以实现复杂的agent智能组合工作流程。
常见问题与快速排查 (Q/A)
Q1:LangGraph 工作流卡在某个节点不继续执行
关键词:LangGraph,工作流卡住,节点不继续,条件路由,continue,循环退出,结束节点,死循环,流程图,可视化 可能原因:
- 节点函数没有正确返回 "continue" 或下一个节点名称
- 条件分支逻辑判断错误,没有匹配到任何分支
- 状态图中缺少结束节点或循环退出条件
排查步骤:
- 检查节点函数的返回值,确保返回有效的下一个节点名称
- 使用
graph.get_graph(x).draw_mermaid()可视化工作流,确认节点连接关系 - 在条件分支函数中添加调试日志,确认分支判断逻辑
- 检查状态图中是否设置了
set_finish_point或循环退出条件
Q2:工作流状态数据丢失或未正确保存
关键词:状态丢失,持久化,MemorySaver,检查点,状态类,字段定义,并发,覆盖,thread_id,日志 可能原因:
- 没有正确配置
MemorySaver或检查点保存机制 - 状态对象字段定义与节点函数返回值不匹配
- 并发执行时状态覆盖
排查步骤:
- 确认在构建图时添加了
memory=MemorySaver() - 检查状态类字段定义是否包含所有需要持久化的数据
- 使用
thread_id区分不同会话的状态 - 在节点函数中添加状态日志,跟踪状态变化
Q3:嵌套工作流执行异常
关键词:嵌套,子图,父图,状态兼容,返回格式,嵌套层级,图可视化,状态管理 可能原因:
- 子图与父图的状态结构不兼容
- 子图节点返回的数据格式与父图期望不符
- 嵌套层级过深导致状态管理复杂
排查步骤:
- 确保子图状态类是父图状态的子集或兼容结构
- 检查子图节点的输入输出数据格式
- 使用
graph.get_graph(x).draw_mermaid()可视化嵌套结构 - 限制嵌套层级,避免过度复杂的状态管理
Q4:工具调用失败或超时
关键词:工具调用,失败,超时,异常处理,重试,超时设置,参数校验,try-except,API,网络 可能原因:
- 工具函数抛出异常未处理
- 外部API调用超时或网络问题
- 工具参数验证失败
排查步骤:
- 在工具节点函数中添加异常捕获和重试机制
- 设置合理的超时时间
- 验证工具输入参数的有效性
- 使用
try-except包装工具调用,返回错误信息而非抛出异常
Q5:工作流性能问题
关键词:性能优化,节点耗时,检查点频率,异步,缓存,数据结构,瓶颈,并行,批处理 可能原因:
- 节点函数计算复杂度过高
- 频繁的状态保存和加载
- 工具调用响应缓慢
排查步骤:
- 分析各节点执行时间,识别性能瓶颈
- 优化状态保存频率,只在必要时保存检查点
- 对耗时工具调用进行异步处理或缓存
- 考虑使用更高效的数据结构存储状态
总结
如果你已经熟悉 LangChain 的工具与提示词模块,本教程将帮助你把"面向工具的智能体"升级为"面向工作流的智能系统",在复杂业务中获得更高的可靠性与可控性。
LangGraph 的核心价值
- 复杂流程编排:条件分支、循环、嵌套、异常处理,可控且可回溯
- 状态持久化与恢复:MemorySaver 检查点支持断点续跑与回滚,降低失败成本
- 可观察与调试:流程图、逐步回放、日志追踪,定位问题更高效
- 模块化与复用:节点/子图复用,适合团队协作与渐进式演进
适用场景
- 多工具协同的智能体:需要多次推理与工具调用的复杂流程
- 数据管道与任务编排:抓取、清洗、分析等多步骤任务
- 长期运行且高可靠性要求:断点续跑、幂等与失败重试
- 合规与可控输出:可回溯审计、明确边界与权限管理
通过本教程,你已具备从线性到复杂工作流的搭建能力。建议以最小可用流程起步,按"线性 → 条件分支 → 循环 → 子图 → 状态持久化与监控"的顺序迭代,并在每一步引入可观察性与故障处理,确保可靠性与可维护性。
术语与别名(便于检索与问法对齐)
- StateGraph:状态图;工作流图;流程编排
- ToolNode:工具节点;工具执行节点
- MemorySaver:检查点;状态持久化;记忆管理
- Conditional Edge:条件边;路由;分支控制
- Checkpointer:检查点器;状态存储器