Transformer 前馈网络 (FFN) 深度解析
1. 概述与引言
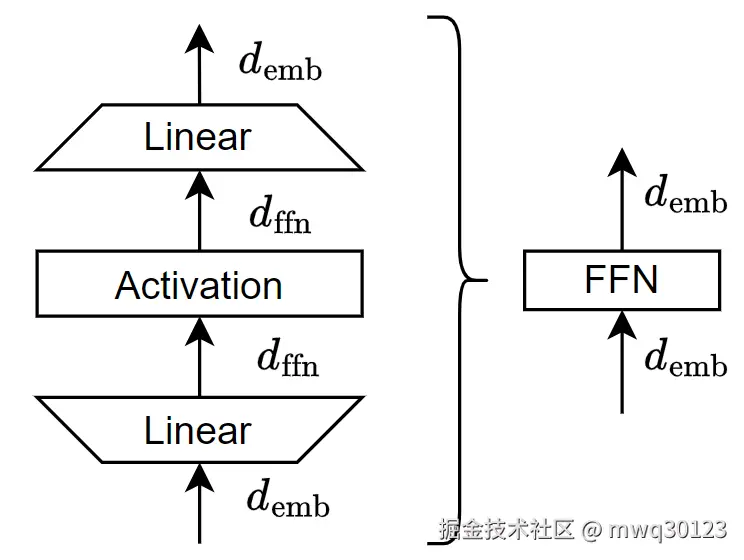
前馈网络(Feed-Forward Network, FFN),在现代深度学习架构中,特指一个由两个线性变换层与一个非线性激活函数构成的核心模块。它不仅是 Transformer 架构的基石,其"扩展-收缩"的设计模式也已成为深度学习领域一个重要的设计范式。
如果您读过《Attention Is All You Need》原始论文,或深入研究过 GPT、LLaMA 等模型的源码,可能会注意到一个反复出现的结构:在 Transformer 的前馈网络中,输入维度通常会被扩大4倍,然后再还原回原始维度。这个看似随意的"×4"因子,背后蕴含着对模型表达能力、计算效率与理论动机的深刻权衡。
本文档将系统性地拆解 FFN 的结构逻辑、设计动机及其在各大主流模型中的演化趋势。
2. 核心架构
FFN 模块的典型架构包含一个扩展线性层、一个非线性激活函数和一个收缩线性层。
其数学表达为:
FFN(x)=σ(xW1+b1)W2+b2
其中,激活函数 σ 在早期通常是 ReLU,因此也常写作:
FFN(x)=max(0,xW1+b1)W2+b2
各参数的维度设计是其关键特征:
W1∈Rdmodel×dff,W2∈Rdff×dmodel
这里的 dmodel 是模型的输入/输出维度,而 dff 是 FFN 内部的隐藏层维度。这个架构的核心在于,通常 dff 远大于 dmodel,构成了"扩展-收缩"的模式。
通过将输入 emb_dim 投影到一个更高维的空间(4 * emb_dim),模型在这个"更宽"的空间里有更多的能力去学习和拟合复杂的函数和模式。激活函数(如 GELU)在这个高维空间中进行操作,可以组合出比在原始低维空间中更丰富的特征。最后,第二个线性层再将这些丰富的信息"压缩"并投影回原始的 emb_dim,以便于后续的残差连接。
这个过程可以被直观地理解为一个**"记忆"或"特征提取器"**:
- 1.第一个线性层将注意力层的输出投影到一个巨大的"特征库"中。
- 2.GELU 激活函数根据输入,"点亮"或"激活"了库中相关的特征。
- 3.第二个线性层根据被激活的特征,重新组合成一个有意义的输出。
3. FFN 的角色与设计动机
在标准的 Transformer Block 中,FFN 与自注意力层(Self-Attention)协同工作。自注意力负责捕捉序列中全局的依赖关系,而 FFN 则负责对每个位置的表示进行独立的、深度的非线性变换。其设计动机主要有以下三点:
-
提高模型的表达能力(非线性投影空间)
自注意力层的计算本质上是线性的(加权求和)。FFN 是每个 Transformer Block 中最主要的非线性来源。通过将特征投影到一个更高维的隐藏空间(dff),模型获得了更强的函数拟合能力,允许其在每个 token 上学习更复杂、更丰富的特征组合,这类似于传统多层感知机(MLP)中扩展隐藏层以增强模型容量的思路。
-
与计算效率的权衡
虽然扩大维度会带来更多参数,但在现代硬件(如 GPU)上,大规模的密集矩阵乘法(Dense Matrix Multiplication)通常能达到更高的计算吞吐效率。将内部维度设置为模型维度的4倍,被证明是在模型性能与计算效率之间取得的一个出色的平衡点,这一经验性选择在众多模型中都表现出了高效和稳定的训练特性。
-
理论动机:近似更高阶映射
从函数逼近的角度看,FFN 的"高维投影 → 非线性激活 → 低维重构"过程,与核方法(Kernel Methods)中"将特征映射到高维空间使其线性可分"的思想有异曲同工之妙。通过在高维空间中进行非线性筛选,FFN 增强了 Transformer 在每个 token 层面上的局部建模与特征提取能力。
4. 架构的延续与演化
从 GPT-1 到最新的 LLaMA 模型,FFN 的核心"扩展-收缩"结构被持续沿用,但其内部的激活函数和具体的扩展因子则在不断演化。
| 模型 | d_model | d_ff (内部维度) | 激活函数 | 说明 |
|---|---|---|---|---|
| GPT-1 (2018) | 768 | 3072 (×4) | ReLU | 经典的 Transformer FFN 配置 |
| GPT-2 (2019) | 1600 | 6400 (×4) | GELU | 采用平滑的 GELU 激活函数,训练更稳定 |
| GPT-3 (2020) | 12288 | 49152 (×4) | GELU | "4倍因子"作为标准配置被继续沿用 |
| LLaMA (2023) | 4096 | 11008 (~2.7×) | SwiGLU | 采用更高效的门控激活单元 SwiGLU |
| Mistral (2023) | 4096 | 14336 (~3.5×) | SwiGLU | 在效率和性能之间进行动态折中 |
| PaLM (2022) | 8192 | 65536 (×8) | GELU | 在超大模型上探索更大的扩展因子 |
5. 下一代趋势:从固定扩张到动态结构
随着模型规模和硬件的演进,FFN 的设计也出现了新的方向,旨在追求更高的效率和性能:
-
GLU 变体 (如 SwiGLU, GeGLU)
这类激活函数替代了传统的 ReLU/GELU,通过引入"门控机制"来动态地控制信息流。论文《GLU Variants Improve Transformer Models》等研究显示,GLU 变体可以在相似的参数量下显著提升模型性能。
-
混合专家系统 (Mixture of Experts, MoE)
MoE 结构从根本上改变了 FFN 的工作方式。它不再是将输入投影到一个大的密集 FFN 中,而是设置多个并行的、小型的 FFN(称为"专家"),并通过一个门控网络为每个 token 动态地选择激活少数几个专家。这本质上是一种稀疏化的超高维投影,能在不显著增加总计算量(FLOPs)的情况下,极大地扩展模型的参数量和容量。
-
可学习/动态扩张比
未来的模型可能不再固定扩展因子,而是根据层、甚至根据 token 的重要性来动态地决定 FFN 的内部维度,从而实现更高效的参数分配。
6. 总结:"4倍扩张"是一种经验上的最优点
| 角度 | 含义解释 |
|---|---|
| 结构设计 | 线性-非线性-线性,用于提升模型的非线性表达能力。 |
| 参数效率 | 在计算量与性能之间的一种高效折中,尤其适合 GPU 并行计算。 |
| 理论基础 | 思想上类似于核方法,即在高维空间中进行特征变换和筛选。 |
| 经验验证 | 几乎所有成功的 Transformer 模型都沿用了此设计,证明了其稳定性和有效性。 |
一句话总结:Transformer FFN 中的"4倍扩张"设计并非偶然,而是初代模型在计算效率与模型表达能力之间找到的"黄金比例",并作为一项成功的实践被广泛继承和演化。它不仅是一行参数配置,更是整个 Transformer 设计哲学的缩影。