周志华《机器学习---西瓜书》一
第一部分
一、机器学习的理论基础
PAC理论:一个模型f(x)f(x)f(x)得到的结果与正确的结果的差值小于规定误差的概率大于某一阈值。

二、基础术语
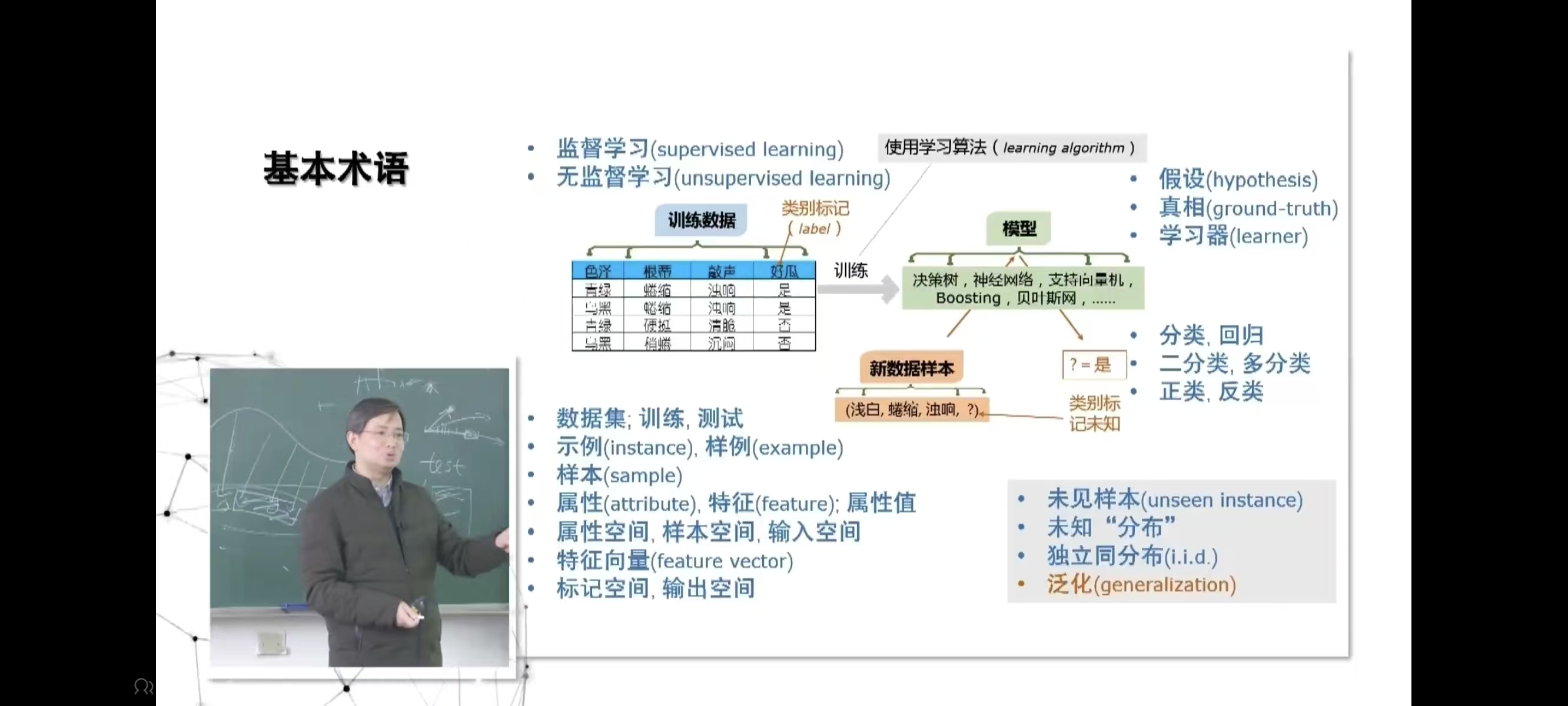
- 监督学习(supervised learning) :利用带有类别标记(label)的训练数据,通过学习算法训练出模型,用于对新数据样本的类别标记进行预测,典型任务有分类、回归等。
- 无监督学习(unsupervised learning) :在没有类别标记的训练数据上,通过学习算法发现数据中的潜在结构或规律,比如聚类等任务。
- 训练数据:用于训练模型的数据集,包含示例的属性和对应的类别标记(如示例中判断西瓜是否为好瓜的数据集。数据集包含为西瓜的图片以及已经标记好坏的结果)
- 类别标记(label) :训练数据中对样本所属类别的标注,如 "好瓜" 的 "是" 或 "否"。
- 学习算法(learning algorithm) :用于从训练数据中学习得到模型的算法。
- 假设(hypothesis) :学习器所学到的模型,是对数据规律的一种假设。只有基于一定的假设才能构建模型
- 真相(ground-truth) :数据真实的规律或类别标记,是学习器试图逼近的目标。
- 学习器(learner) :通过学习算法从训练数据中学习得到的模型,用于对新数据进行预测等操作。
- 数据集:由多个样本组成的集合,可分为训练集和测试集,训练集用于训练模型,测试集用于评估模型性能。
- 训练:利用训练数据让学习算法学习得到模型的过程。
- 测试:用测试集评估训练好的模型性能的过程。
- 示例(instance)、样例(example) :数据集中的单个数据对象,如数据集中的一个西瓜记录。
- 样本(sample) :与示例、样例含义相近,指数据集中的单个数据项。
- 属性(attribute)、特征(feature) :描述样本的某个特性,如西瓜的 "色泽""根蒂""敲声"。
- 属性值:属性的具体取值,如 "色泽" 的 "青绿""乌黑" 等。
- 属性空间、样本空间、输入空间:由所有属性张成的空间,样本在这个空间中是一个点。
- 特征向量(feature vector) :将样本的属性值作为向量的分量,形成的向量,用于数学上的表示和计算。
- 标记空间、输出空间:类别标记的取值范围,如 "好瓜" 的 "是" 和 "否" 构成的空间。
- 模型:通过学习算法从训练数据中得到的,用于预测或分析的函数或结构,如决策树、神经网络、支持向量机等。
- 新数据样本:没有类别标记,需要模型进行预测的样本,如示例中的(浅白,蜷缩,浊响,?)。
- 分类:预测样本属于哪个离散类别,如判断西瓜是好瓜还是坏瓜。
- 回归:预测样本的连续数值,如预测房价。
- 二分类:类别只有两个,如正类和反类。
- 多分类:类别有多个。
- 正类、反类:在二分类中对两个类别的称呼,通常将关注的类别称为正类,其他为反类。
- 未见样本(unseen instance) :模型在训练过程中没有见过的新样本。
- 未知 "分布" :未见样本的概率分布是未知的,模型需要具备泛化能力来处理。
- 独立同分布(i.i.d.) :假设样本是从同一个概率分布中独立抽取的。
三、典型的机器学习过程
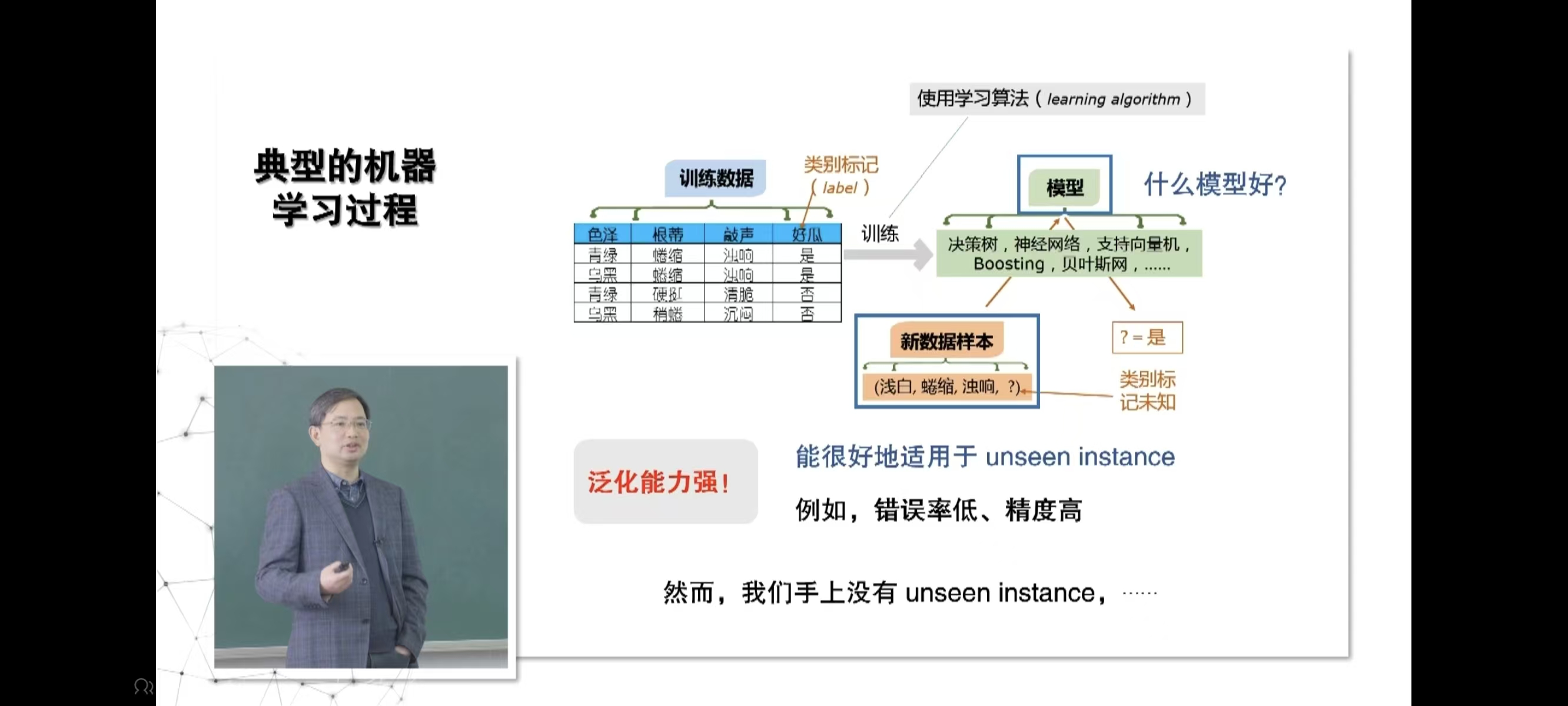
四、现实中的机器学习应用
最优方案往往来自:按需设计、量身定制

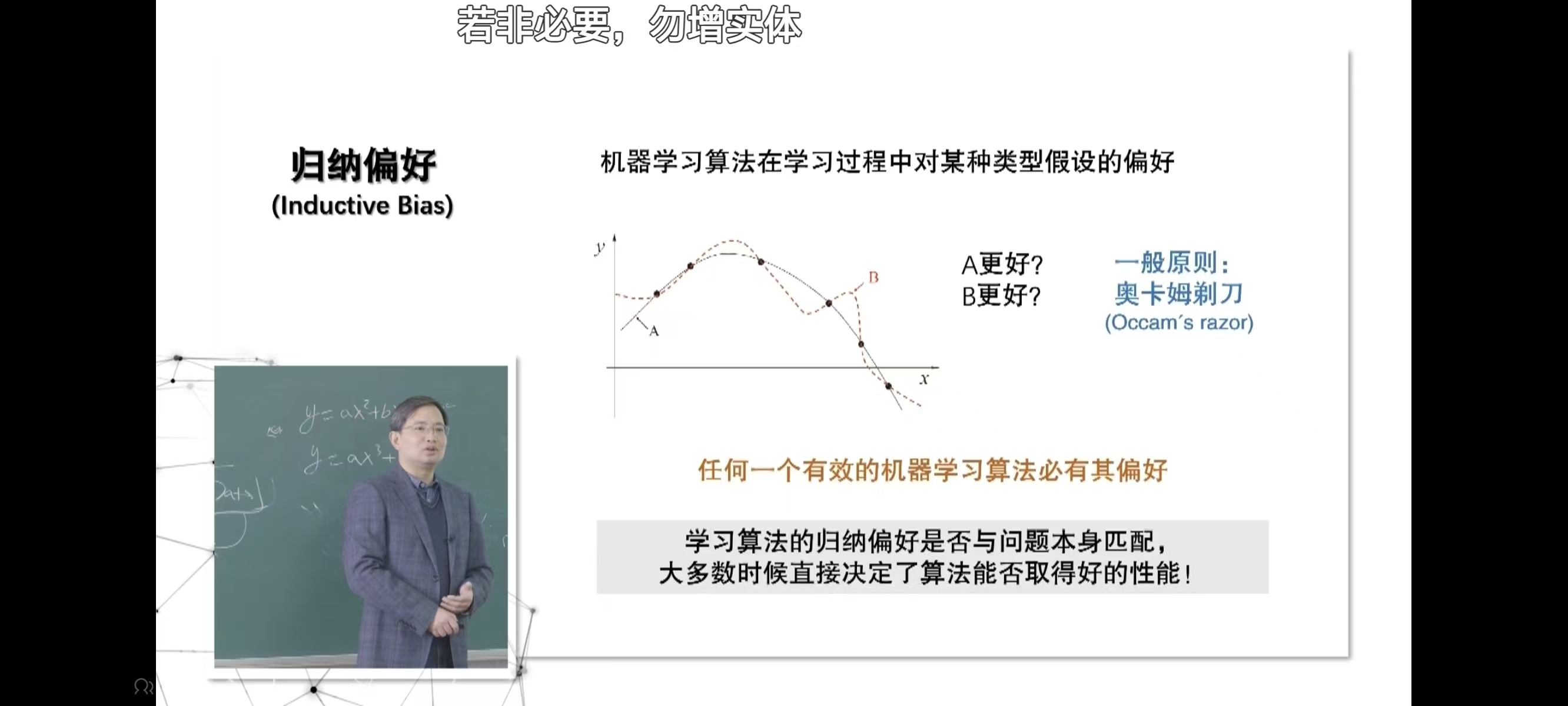
五、归纳偏好
任何一个有效的机器学习算法必有其偏好
学习算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能!
一般原则 :奥卡姆剃刀(Occam's razor)核心思想是: "如无必要,勿增实体"
在机器学习语境中,这一原则通常理解为:在多个性能相近的模型中,应选择更简单的那个。这里的 "简单" 可指模型参数更少、结构更简洁(如更浅的决策树、更低阶的多项式拟合等)。其背后的逻辑是:简单模型更不易过拟合训练数据中的噪声,更可能捕捉数据的本质规律,从而在未见样本上具有更好的泛化能力。例如,当用曲线拟合数据时,若一次函数(直线)与高次多项式的拟合效果相近,优先选择直线,因为它更简单,更可能反映数据的真实趋势。