之前的理论文章中介绍过大模型部署方面的相关知识,也从推理优化的角度讲过了vllm的优化原理,但受资源限制,之前一直没有实际跑过(当然,可以去算力平台购买算例,但是在没有实际需求的场景下去租算力玩vllm部署感觉有点不太合适),最近的电脑上配上了一块显卡,因此可以尝试实践部署下vllm来玩一下。本文主要记录下可复现的安装过程,如果你也有类似的需求,可以少踩坑。
安装并启动WLS
由于vllm不支持windows平台,为了能够在windows上使用vllm,我们需要使用WSL来进行部署。安装完成之后,需要在WLS上安装ubuntu的发行版本。这里建议安装Ubuntu-22.04版本(之前安装老一点的版本存在很多问题),然后通过wsl进入ubuntu。
安装Mini conda(可选)
这一步是为了对python环境进行管理,当然现在也有很多的包管理方式,比如uv等。根据个人喜好来,不装也行,主要把python环境安装好。如果要进行这一步,可以按以下命令操作:
bash
sudo apt update && sudo apt upgrade -y
sudo apt install -y wget bzip2
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
#如果下载慢可以使用清华版本
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行下载下来的安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
#初始化conda环境
source ~/.bashrc
# Ubuntu/Debian 安装C编译器
sudo apt update
sudo apt install build-essential -y安装过程中会有各种提示,可以一直enter下去,最后yes即可。安装成功后,创建python环境:
ini
conda create -n vllm-env python=3.10 -y
conda activate vllm-env亲测:3.10是一个合适的版本,之前使用3.9折腾了好久,手动安装很多包还是存在各种包版本冲突的问题。最后升级Ubuntu并升级python版本,最终解决。
安装并启动VLLM
接着继续安装依赖,安装支持 CUDA 12.1 的 PyTorch(注意看你的本地安装的cuda版本是多少)。
perl
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121之后就可以安装vllm了
bash
pip install vllm
# 如果国内速度慢可以切换镜像
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple之后就可以启动llm了。这里我使用的是qwen3-4B。注意启动的时候可能会由于显存不够出现失败(我的设备是12G显存的3060),直接启动起不起来,需要通过一些优化方式来启动:
css
python -m vllm.entrypoints.openai.api_server --model /home/wyk/models/Qwen3-4B --host 0.0.0.0 --port 8000 --gpu-memory-utilization 0.9 --max-model-len 14000 --dtype half --max-num-seqs 128 --enable-chunked-prefill --max-num-batched-tokens 14000 --served-model-name Qwen3-4B --api-key sk-abc123def456启动成功。
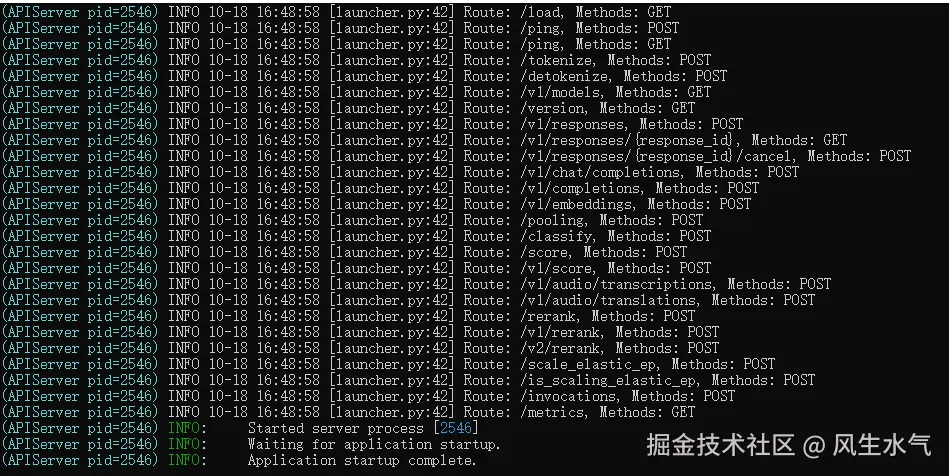
手动下载模型
如果由于网络问题你无法直接通过命令下载模型(无法使用huggingface相关的指令),这种情况你就需要手动下载模型。
bash
# 模型地址
https://hf-mirror.com/Qwen/Qwen3-4B
# 在 Windows PowerShell 中
git lfs install
git clone https://hf-mirror.com/Qwen/Qwen3-4B C:\models\Qwen3-4B
# 或者直接在ubuntu中
mkdir -p /home/wyk/models/Qwen3-4B
cd /home/wyk/models/Qwen3-4B
wget https://hf-mirror.com/Qwen/Qwen3-4B/resolve/main/config.json
wget https://hf-mirror.com/Qwen/Qwen3-4B/resolve/main/model-00001-of-00002.safetensors
wget https://hf-mirror.com/Qwen/Qwen3-4B/resolve/main/model-00002-of-00002.safetensors
wget https://hf-mirror.com/Qwen/Qwen3-4B/resolve/main/tokenizer.json
wget https://hf-mirror.com/Qwen/Qwen3-4B/resolve/main/tokenizer_config.json之后在wsl上启动的时候指定模型对应的下载位置即可,例如:
bash
--model /mnt/c/models/Qwen3-4B一些参数优化
一开始的时候max_model_len直接设置成32k,然后提示KV Cache内存不足,启动不起来,所以这个参数一开始不要设置的太大,可以从8192开始往上。另外如果有量化的版本,可以考虑使用量化的版本(GPTQ/AWQ)进行部署。这样可以将模型+KVcache的内存占用控制在合理的内存大小之内。另外一些可选的参数如下:
--dtype half |
强制使用 float16 加载模型,避免意外使用 float32 导致显存爆炸。 |
|---|---|
--enable-chunked-prefill |
允许处理长输入时分块推理,提升大输入稳定性。 |
--max-num-seqs 128 |
控制最大并发请求数,防止 OOM |
--max-num-batched-tokens 8192 |
防止大 batch 导致显存溢出 |
| served-model-name | 如果是手动下载的模型,这个参数需要指定一下,否则访问api调用时访问不到:Qwen3-4B |
测试
我们编写一个测试脚本来测试一下调用它的单次请求耗时:
ini
import time
import asyncio
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="sk-abc123def456"
)
def test_single_request():
print("🔄 测试单次请求延迟...")
start_time = time.time()
response = client.chat.completions.create(
model="Qwen3-4B",
messages=[{"role": "user", "content": "请用中文写一首关于春天的诗"}],
max_tokens=256,
stream=False
)
total_time = time.time() - start_time
num_tokens = len(response.choices[0].message.content.split())
speed = num_tokens / total_time
print(f"✅ 总耗时: {total_time:.2f}s")
print(f"✅ 生成 {num_tokens} 个 token")
print(f"✅ 速度: {speed:.2f} tokens/s")
# 运行测试
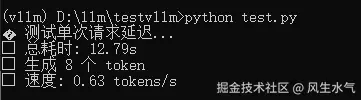
test_single_request()它的结果如下,可以看到,我们成功使用vllm部署了模型并对外提供服务,对于非流式接口,生成速度是0.63token/s:
总结
本文主要记录了一下在windows上使用vllm部署大模型并对外提供服务的过程。从使用上来说,如果我们真的要使用模型,我们完全可以有其他的选择(比如ollma部署或者调用三方api),但是作为vllm的实践探索,自己本机部署是一个好的开始。