
- 作者:Michael J. Munje1^{1}1,Chen Tang1^{1}1, Shuijing Liu1^{1}1, Zichao Hu1^{1}1, Yifeng Zhu1^{1}1, Jiaxun Cui1^{1}1, Garrett Warnell1,2^{1,2}1,2, Joydeep Biswas1^{1}1, Peter Stone1,3^{1,3}1,3
- 单位:1^{1}1德克萨斯大学奥斯汀分校计算机科学系,2^{2}2美国陆军研究实验室,3^{3}3索尼人工智能
- 论文标题:SocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
- 论文链接:https://arxiv.org/pdf/2509.08757v1
- 项目主页:https://larg.github.io/socialnav-sub/
- 代码链接:https://github.com/LARG/SocialNavSUB
主要贡献
- 提供了包含 4968 个独特问题及其对应人类回答(作为真实标签)的人类标注视觉问答(VQA)数据集,专门用于社交机器人导航任务。
- 引入了首个用于评估 VLMs 在社交机器人导航场景中能力的 VQA 基准测试,使用 SCAND 数据集中的 60 个独特场景,评估 VLMs 与人类回答的一致性。
- 对多个SOTA大型VLMs进行了实验,与人类和基于规则的基线进行了对比,揭示了当前 VLMs 在社交场景理解方面与人类和基于规则的方法之间的显著差距。
研究背景

- 社交机器人导航是指机器人在有人类活动的环境中有效且安全地移动,同时遵守社交规范。这一任务需要机器人能够理解人类的意图、遵循社交规范,并对动态环境做出反应。
- 近年来,大型视觉语言模型(VLMs)在对象识别、常识推理和上下文理解方面展现出强大的能力,这些能力与社交机器人导航的复杂需求相契合。然而,目前尚不清楚 VLMs 是否能够准确理解复杂的社交导航场景(例如,推断代理之间的时空关系和人类意图),这对于安全和符合社交规范的机器人导航至关重要。
- 尽管已有研究探索了 VLMs 在社交机器人导航中的应用,但这些研究大多局限于少量受控场景,缺乏对 VLMs 在社交导航中场景理解能力的系统性评估。
SocialNav-SUB
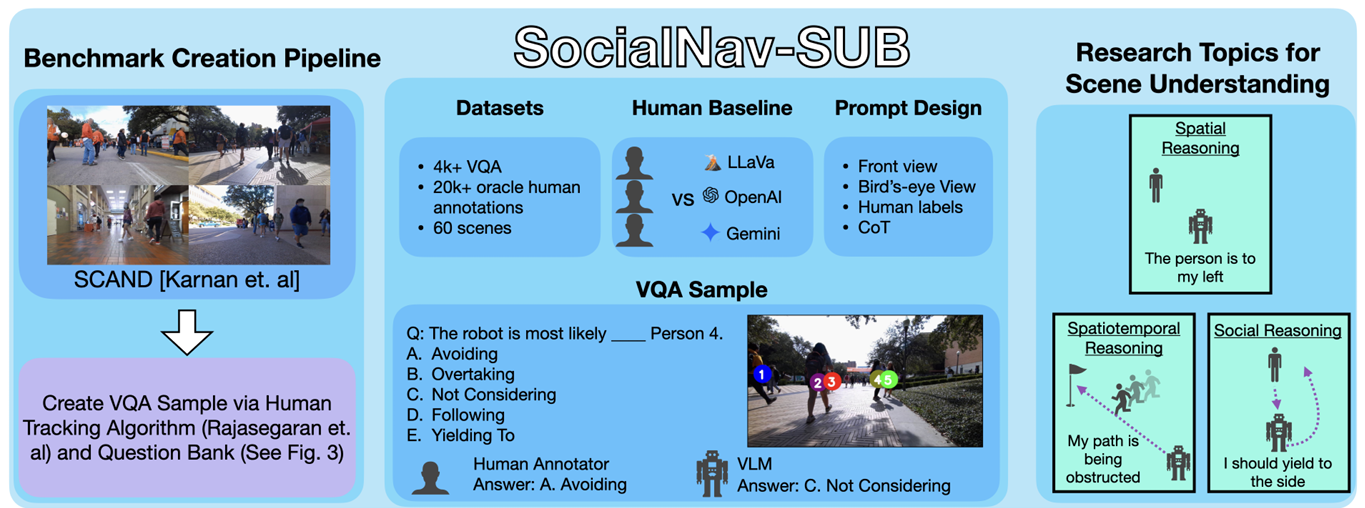
具有挑战性的社交导航场景
- 数据来源:SocialNav-SUB 基于 SCAND 数据集构建,该数据集包含了在多样化和可能拥挤的场景中,由遥控移动机器人收集的社交机器人导航数据。
- 场景特点:选取的场景具有中高人群密度(平均每个场景有 6.65 人,标准差为 2.80),近距离行人和动态变化的人类运动。这些场景通常涉及阻碍机器人直接路径的行人,因此需要机器人展示复杂的、符合社交规范的交互行为。
- 场景多样性:这些场景涵盖了多种环境类型,如户外走道、狭窄的门道/走廊、人行道和街道交叉口,以及不同的人群密度(1-13 名行人)。
丰富的对象中心视觉表示

- 视觉数据增强:为了弥补 VLMs 在从二维图像序列中提取空间或细粒度对象级信息方面的不足,研究者使用 PHALP 算法对行人进行跟踪,并提供相对相机框架的 3D 姿态估计。通过机器人里程计数据,将相对人类姿态转换为全局姿态,并应用卡尔曼平滑处理。
- 多视图表示:使用 SCAND 提供的相机内外参,将行人的 3D 坐标投影到前视图和鸟瞰图(BEV)图像中,并用编号和颜色编码的圆圈标注人类位置。这种多视图表示保留了原始场景上下文,同时提供了额外的空间和对象级信息。
- 实时应用:在实际机器人系统中,这种 BEV 表示可以通过学习方法或利用跟踪相机、深度传感器和相机矩阵实时构建。
多样化的场景理解问题
- 问题分类 :设计了一套涵盖空间推理、时空推理和社交推理的多样化问题,以全面评估 VLMs 在社交机器人导航中的场景理解能力。
- 空间推理:描述单帧中的空间关系。
- 时空推理:描述机器人和行人随时间的运动。
- 社交推理:推断机器人和行人之间的交互方式。
- 问题示例 :
- 空间推理:在视频开始时,人 X 在机器人的哪个方向?
- 时空推理:从视频开始到结束,人 X 与机器人的相对距离如何变化?
- 社交推理:机器人是否受到人 X 的影响?
基于人类受试者研究的稳健人类基线
- 人类基线研究:通过人类受试者研究收集人类回答作为真实标签,以衡量 VLM 输出与人类判断的一致性。研究者定义了两个评估指标:概率一致性(PA)和共识加权 PA(CWPA),用于衡量 VLM、人类或基于规则的基线的答案与人类回答的整体一致性。
- 评估指标 :
- PA(概率一致性):计算 VLM 答案与人类回答一致的比例。
- CWPA(共识加权概率一致性):对人类共识较高的问题给予更高的权重,对人类共识较低的问题给予较低的权重。
- 人类基线 :
- 平均人类基线:衡量一个随机人类回答与其他人类回答一致的平均概率。
- 人类共识基线:选择每个问题中人类回答的最常见答案作为基线。
实验
实验过程
- 实验目标:评估当前SOTA大型视觉语言模型(VLMs)在社交机器人导航场景中对空间推理、场景理解和社交推理的能力。
- 实验方法 :使用 SocialNav-SUB 基准测试框架,对多种 VLMs 进行评估,包括封闭源代码的通用 VLMs、推理 VLMs 和开源可部署 VLMs。
- 封闭源代码的通用 VLMs:如 GPT-4o 和 Gemini 2.0,这些模型在视觉问答(VQA)任务中表现出色。
- 推理 VLMs:如 OpenAI o4-mini 和 Gemini 2.5,这些模型经过微调,增强了视觉语言推理能力。
- 开源可部署 VLMs:如 LLaVa-Next-Video,这些模型可以在本地运行,适合机器人应用。
- 实验设置 :
- 使用链式思考(CoT)推理技术作为提示方法,将视觉和文本提示呈现给 VLM,确保与人类参与者接收的格式相似,以便进行公平比较。
- 使用概率一致性(PA)和共识加权 PA(CWPA)作为评估指标,衡量 VLM 答案与人类回答的一致性。
- 人类基线 :
- 平均人类基线:衡量一个随机人类回答与其他人类回答一致的平均概率。
- 人类共识基线:选择每个问题中人类回答的最常见答案作为基线。
- 基于规则的基线:使用场景中行人的位置数据,通过一组手工制定的规则生成 VQA 提示的答案。
基准测试结果
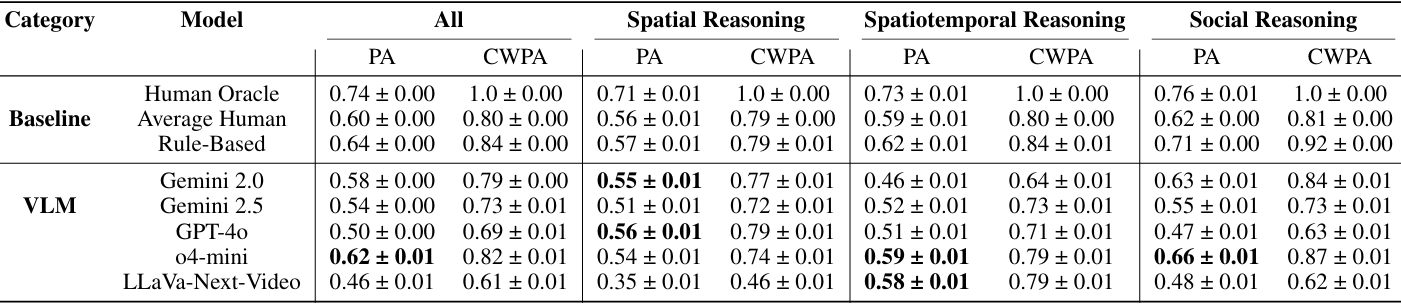
- 总体表现:在所有评估的模型中,OpenAI o4-mini 的整体表现最佳,但仍与人类共识和基于规则的基线存在显著差距。这表明,尽管当前SOTA大型 VLMs 在视觉问答任务中表现出色,但在社交机器人导航场景中,它们仍未能达到人类水平的理解和决策能力。
- 按问题类别划分的表现 :
- 空间推理:人类共识(人类共识基线)远高于最佳模型,表明当前大型 VLMs 在准确解释空间关系方面存在困难。
- 时空推理:模型在捕捉随时间动态变化方面表现出更大的困难。
- 社交推理:模型的表现相对更接近人类共识水平,甚至在某些情况下略微超过了平均人类基线。这表明大型 VLMs 在解释社交线索和互动方面相对更擅长,尽管仍存在明显差距。
- 具体模型表现 :
- Gemini 2.0:在空间推理方面表现较好,但在时空推理和社交推理方面表现稍弱。
- Gemini 2.5:在社交推理方面表现较好,但在时空推理方面表现较弱。
- GPT-4o:在所有类别中表现较为均衡,但整体性能低于 OpenAI o4-mini。
- LLaVa-Next-Video:在空间推理方面表现最弱,但在社交推理方面表现尚可。
- OpenAI o4-mini:在所有模型中表现最佳,尤其是在社交推理方面,但仍低于人类共识和基于规则的基线。
讨论
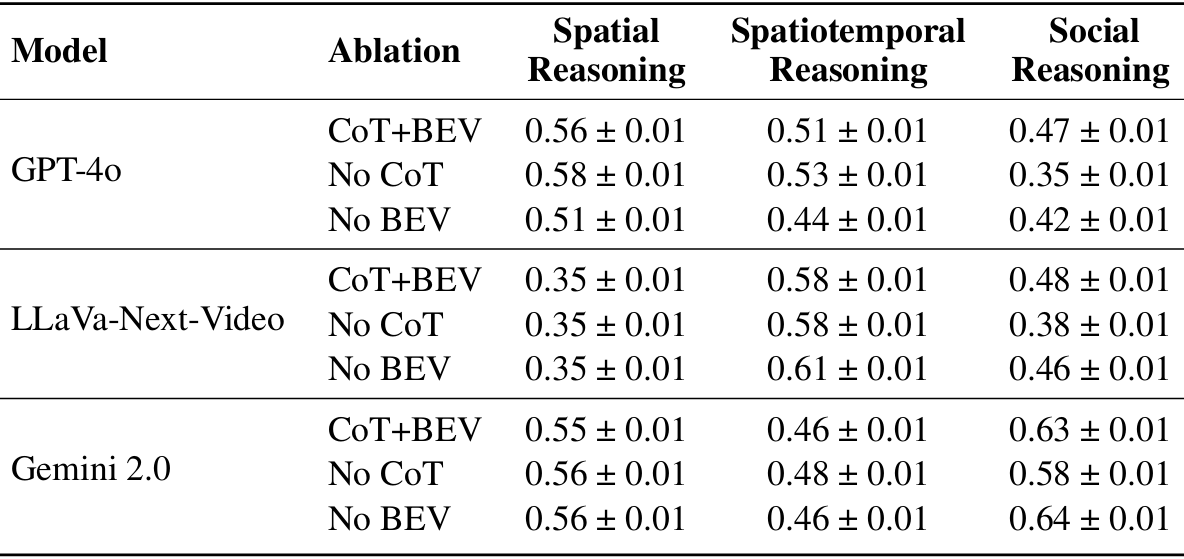
- VLMs 的局限性:尽管一些大型 VLMs(如 OpenAI o4-mini 和 Gemini 2.0)显示出有希望的进步,但它们在关键推理任务上仍落后于人类共识和基于规则的性能。尽管在社交推理任务中模型更接近人类共识表现,但结果表明,在这些大型 VLMs 可靠地支持复杂的真实世界社交机器人导航任务之前,仍需要进行显著改进。
- 查询策略的影响 :
- CoT 推理:显著增强了所有模型的社交推理性能,这可能是由于它为复杂任务提供了结构化的推理过程。
- BEV 场景表示:对某些模型有显著影响,而对其他模型影响较小。这表明 BEV 的有效性取决于 VLM,但可以通过 SocialNav-SUB 进行验证。
- 空间推理能力:实验表明,更好的空间和时空推理能力可以提高社交推理问题的表现,这表明当前 VLMs 受限于空间推理能力,但可以通过在空间推理数据上进行微调来改进,同时保持对高级场景理解的性能。
- 场景理解对导航任务的影响:为了验证准确的场景理解是否是 VLMs 在真实世界导航任务中实际使用的先决条件,研究者进行了实验,结果表明,提供额外的场景上下文可以提高模型答案与人类操作员选择的答案之间的一致性,尤其是在推理模型中。这些发现进一步强化了 SocialNav-SUB 基准测试在推动 VLMs 用于真实世界社交机器人导航中的价值。
结论与未来工作
- 结论 :
- SocialNav-SUB 基准测试框架揭示了当前 VLMs 在处理复杂社交场景时的具体优势和劣势,为未来的研究设定了明确的议程。
- 该基准测试使研究人员能够系统地比较模型、改进提示策略,并开发新方法以弥合机器和人类对社交导航场景理解之间的差距,从而推动 VLMs 在现实世界应用中的迭代改进,最终指导开发更具社交意识和可靠性的机器人系统。
- 未来工作 :
- 尽管 SocialNav-SUB 推动了 VLMs 在社交机器人导航中的评估,但它存在一些局限性,例如目前仅依赖于 SCAND 数据集中的场景,且实验基于有限的模型和场景。
- 未来的研究方向包括扩展数据集以包含更多的社交机器人导航数据集,以增强其多样性和鲁棒性;
- 在 SocialNav-SUB 提供的人类数据集上对 VLMs 进行微调,以提高其在社交机器人导航中的能力;
- 评估更多 VLM 模型,包括针对空间推理和社交机器人导航进行微调的 VLMs;
- 以及探索利用 VLMs 的特定方式(如社交推理)的混合方法,同时使用专门的模块来弥补其不足。
