整个过程就是"先有预测结果→分析误差(损失)→用梯度优化参数→得到更贴合的结果"的循环,本质是通过不断 "试错 - 调整" 让模型逐步逼近最优解。
一、损失函数(Loss Function)
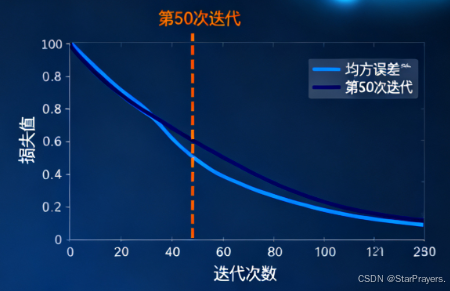
损失函数是衡量模型预测结果与真实标签之间差异的指标,差异越大,损失值越高,模型需要通过优化降低这个值。
python
loss = nn.CrossEntropyLoss() # 定义交叉熵损失函数这里使用的CrossEntropyLoss(交叉熵损失)是分类任务中最常用的损失函数之一,尤其适用于多分类问题(如代码中的 CIFAR10 有 10 个类别)。
损失计算过程
python
for data in dataloader:
imgs, targets = data # 从数据加载器中获取图片和真实标签(targets)
outputs = prayer(imgs) # 模型对图片的预测结果(10个类别的概率分布)
result_loss = loss(outputs, targets) # 计算预测结果与真实标签的损失
print(result_loss) # 输出损失值outputs:模型的预测结果,形状为(batch_size, 10),每个元素表示对应类别的 "得分"(未经过 softmax 的原始输出)。targets:真实标签,形状为(batch_size,),每个元素是 0-9 之间的整数(对应 10 个类别)。result_loss:损失值是一个标量(单个数字),表示当前批次数据的平均损失。初始时模型预测不准确,损失值通常较大(比如几以上),随着训练会逐渐减小。
二、反向传播(Backward Propagation)
反向传播是计算损失函数对模型参数(权重、偏置等)梯度的过程,是模型优化的核心步骤。有了梯度,才能通过优化器(如 SGD、Adam)更新参数,降低损失。
python
result_loss.backward() # 执行反向传播,计算梯度
print("ok")backward():调用损失值的backward()方法后,PyTorch 会自动沿着计算图(从损失值反向到模型的每个参数)计算梯度,并将梯度存储在每个参数的.grad属性中。- 例如,模型中的卷积层权重
Conv2d.weight、偏置Conv2d.bias,全连接层的权重Linear.weight等,都会在backward()后得到对应的梯度。
三、优化器(Optimizer)
优化器是"根据梯度调整模型参数"的工具。在反向传播计算出参数的梯度后,优化器会按照特定策略更新参数,最终实现 "降低损失、提升模型性能" 的目标。
++简单说:梯度告诉我们 "参数应该往哪个方向调整",优化器告诉我们 "具体调整多少(步长)、如何调整(策略)"。++
①定义优化器
python
optim = torch.optim.SGD(prayer.parameters(), lr=0.01)torch.optim.SGD:随机梯度下降(Stochastic Gradient Descent),最经典的优化器之一。- 第一个参数
prayer.parameters():需要优化的模型参数(如卷积层的权重、偏置,全连接层的权重等)。nn.Module的parameters()方法会自动收集所有可训练参数。 - 第二个参数
lr=0.01:学习率(Learning Rate),控制参数更新的步长(核心超参数)。
②训练循环中的优化器操作
python
for epoch in range(20): # 训练20轮(完整遍历数据集20次)
running_loss = 0.0 # 记录本轮总损失
for data in dataloader: # 按批次加载数据
imgs, targets = data
outputs = prayer(imgs) # 前向传播:预测结果
result_loss = loss(outputs, targets) # 计算损失
optim.zero_grad() # ① 清空上一轮的梯度(关键!)
result_loss.backward() # ② 反向传播:计算当前梯度
optim.step() # ③ 根据梯度更新参数(核心操作)
running_loss += result_loss # 累加本轮损失
print(running_loss) # 输出本轮总损失三个关键步骤的意义:
- ++① optim.zero_grad():清空所有参数的梯度。因为 PyTorch 的梯度会累积(backward()会在原有梯度上叠加新梯度),如果不清空,会导致梯度错乱,影响参数更新。++
- ++② result_loss.backward():计算当前损失对所有参数的梯度(存储在param.grad中)。++
- ++③ optim.step():优化器根据当前梯度(param.grad)和自身策略(如 SGD 的 "梯度反方向 + 学习率")更新参数(param.data)。++
③常用优化器及其特点
除了代码中的SGD,PyTorch 还提供了多种优化器,适用于不同场景:
| 优化器 | 特点与适用场景 | 核心优势 |
|---|---|---|
| SGD | 基础优化器,按 "参数 = 参数 - 学习率 × 梯度" 更新 | 简单、计算量小,适合大规模数据或简单模型 |
| SGD + 动量(momentum) | 在 SGD 基础上加入 "动量"(模拟物理惯性),加速收敛,减少震荡 | 比纯 SGD 收敛更快,避免陷入局部最优 |
| Adam | 结合动量和自适应学习率(对不同参数用不同学习率),无需手动调整学习率 | 收敛快、稳定性好,适用于大多数场景(推荐新手优先使用) |
| RMSprop | 自适应学习率优化器,解决梯度剧烈变化问题 | 适合非平稳目标函数(如序列预测任务) |
④关键超参数:学习率(lr)
学习率是优化器中最重要的超参数,直接影响模型训练效果:
- lr 太小:参数更新缓慢,训练时间长,可能陷入局部最优。
- lr 太大:参数更新幅度过大,可能跳过最优解,导致损失震荡甚至上升。
调优建议:
- 初始值通常设为
0.01、0.001(如代码中的0.01),根据损失变化调整。 - 若损失下降缓慢,可适当增大 lr;若损失震荡或上升,需减小 lr。
四、完整流程解析(结合代码)
- 数据准备 :使用 CIFAR10 测试集,通过
DataLoader按批次加载数据(图片 + 真实标签)。 - 模型定义 :
Prayer类是一个简单的卷积神经网络(CNN),用于对图片进行分类。 - 损失函数 :用
CrossEntropyLoss衡量分类误差。 - 前向传播 :将图片输入模型,得到预测结果
outputs(前向传播过程)。 - 计算损失 :通过
loss(outputs, targets)得到损失值result_loss。 - 反向传播 :
result_loss.backward()计算所有可训练参数的梯度,为后续参数更新做准备。 - 参数更新: "优化器根据梯度调整参数" 的过程,就像学生根据老师的建议修改答案,下次争取考得更好。
五、完整代码
python
import torchvision
from torch import nn
from torch._dynamo.variables import torch
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader, dataloader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train =False,transform=torchvision.transforms.ToTensor(),download=True)
dataset = DataLoader(dataset,batch_size=1)
class Prayer(nn.Module):
def __init__(self):
super(Prayer, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
prayer=Prayer
optim = torch.optim.SGD(prayer.parameters(),lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs,targets = data
outputs = prayer(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss = result_loss+running_loss
print(running_loss)