本文作者:摘星,TRAE 开发者用户

项目背景
面对陌生语言的菜单,如何快速识别菜品并准确下单?这一痛点长期困扰着跨国旅行者和留学生。基于此,我开发了"AI 识菜通"------一款融合多模态感知、跨语言理解与生成式视觉的智能点餐助手。
用户只需上传一张任意语言的菜单图片,即可在数秒内获得结构化、本地化(中文)的菜品列表,每道菜附带精准描述与逼真图像,并支持一键加入购物车、生成可直接向服务员展示的点餐字符串。
这看似简单的功能背后,涉及图像识别、多语言翻译、AI 图像生成等多项技术的协同工作。本文将重点介绍我们如何运用 TRAE SOLO 的上下文工程能力,协同豆包大模型 Version 1.6 和 Seedream 4.0,构建这个端到端的智能点餐系统。

从 Prompt Engineering 到 Context Engineering 的演进
过去几年,大家都在谈论 Prompt Engineering(提示词工程),通过精心设计输入文本来引导 AI 模型输出期望的结果。但随着 AI 应用场景越来越复杂,单纯的 prompt 已经不够用了。
想象一下,如果你要开发一个智能客服系统,它不仅要理解用户当前的问题,还要记住之前的对话内容,知道用户的身份信息,甚至要根据不同的业务场景调用不同的处理流程。这时候,静态的 prompt 就显得力不从心了。
上下文工程(Context Engineering)正是为了解决这个问题而生。它不再把 AI 调用看作一次性的"黑箱请求",而是将其放在一个结构化、可演化、可追溯的上下文空间中。简单来说,就是要在正确的时间,给正确的模型,提供正确的上下文信息。

技术选型:豆包大模型生态
本项目所用的视觉理解大模型和文生图大模型均采用火山引擎 Mass 平台,分别是 doubao-seed-1-6-vision-250815 和 doubao-seedream-4-0-250828,主要基于两个考量:
doubao-seed-1-6-vision 具备强大的视觉理解能力,适用于视频理解、Grounding、GUI Agent 等高复杂度场景。相比 Doubao-1.5-thinking-vision-pro,它在教育、图像审核、巡检与安防和 AI 搜索问答等场景下展现出更强的通用多模态理解和推理能力,支持 256k 上下文窗口,输出长度支持最大 64k tokens。
doubao-seedream-4.0 基于领先架构的 SOTA** 级多模态图像创作模型,打破传统文生图模型的创作边界。它原生支持文本、单图和多图输入,用户可自由融合文本与图像,在同一模型下实现基于主体一致性的多图融合创作、图像编辑、组图生成等多样玩法。
接入指南
通过火山引擎 Mass 平台(www.volcengine.com/)可以快速接入这些模型...
点击所需的 AI API 进入,进行快捷 API 接入即可。

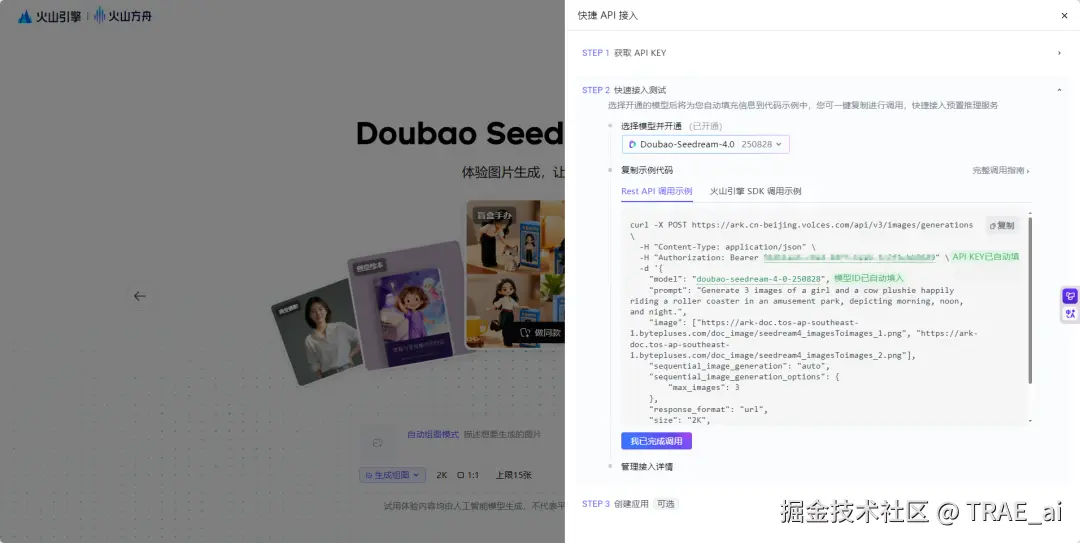
以下是调用示例:
doubao-seed-1-6-vision 调用示例:
arduino
curl https://ark.cn-beijing.volces.com/api/v3/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your api key" \
-d $'{
"model": "doubao-seed-1-6-vision-250815",
"messages": [
{
"content": [
{
"image_url": {
"url": "https://ark-project.tos-cn-beijing.ivolces.com/images/view.jpeg"
},
"type": "image_url"
},
{
"text": "图片主要讲了什么?",
"type": "text"
}
],
"role": "user"
}
]
}'doubao-seedream-4.0 调用示例:
arduino
curl -X POST https://ark.cn-beijing.volces.com/api/v3/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your api key" \
-d '{
"model": "doubao-seedream-4-0-250828",
"prompt": "Generate 3 images of a girl and a cow plushie happily riding a roller coaster in an amusement park, depicting morning, noon, and night.",
"image": ["https://ark-doc.tos-ap-southeast-1.bytepluses.com/doc_image/seedream4_imagesToimages_1.png", "https://ark-doc.tos-ap-southeast-1.bytepluses.com/doc_image/seedream4_imagesToimages_2.png"],
"sequential_image_generation": "auto",
"sequential_image_generation_options": {
"max_images": 3
},
"response_format": "url",
"size": "2K",
"stream": true,
"watermark": true
}'
基于 TRAE SOLO 的开发实践
开发流程概述
整个开发过程始于一个简单的需求描述:
bash
我要做一个AI识菜通应用。功能是:用户可以上传一张任何语言菜单图片,调用视觉理解模型doubao-seed-1-6-vision-250815,分析菜单中的内容并翻译为中文,之后进入第二个页面:点菜页面,点菜页面会将AI翻译后的中文菜单一一展示,并且用户可以点菜。每一道菜都包含它的名字、它的介绍和一张图片,图片调用doubao-seedream-4-0-250828模型的生成图片,然后用户点加号可以把这道菜加入他的购物车,最后点提交生成一个一串字符,上面写他想要点哪些菜,方便他跟服务员说他要点哪些。这个字符应该包合中文名和他元语言的名字。项目需要使用react 实现,使用 shadcn、redix 组件库。AI模型的API KEY放在local storage,通过网页右上角的齿轮按钮输入。输入到 TRAE SOLO 对话框中,TRAE SOLO 不会直接开始开发,而是会先设计两份文档,待我们确认之后才会开始开发。
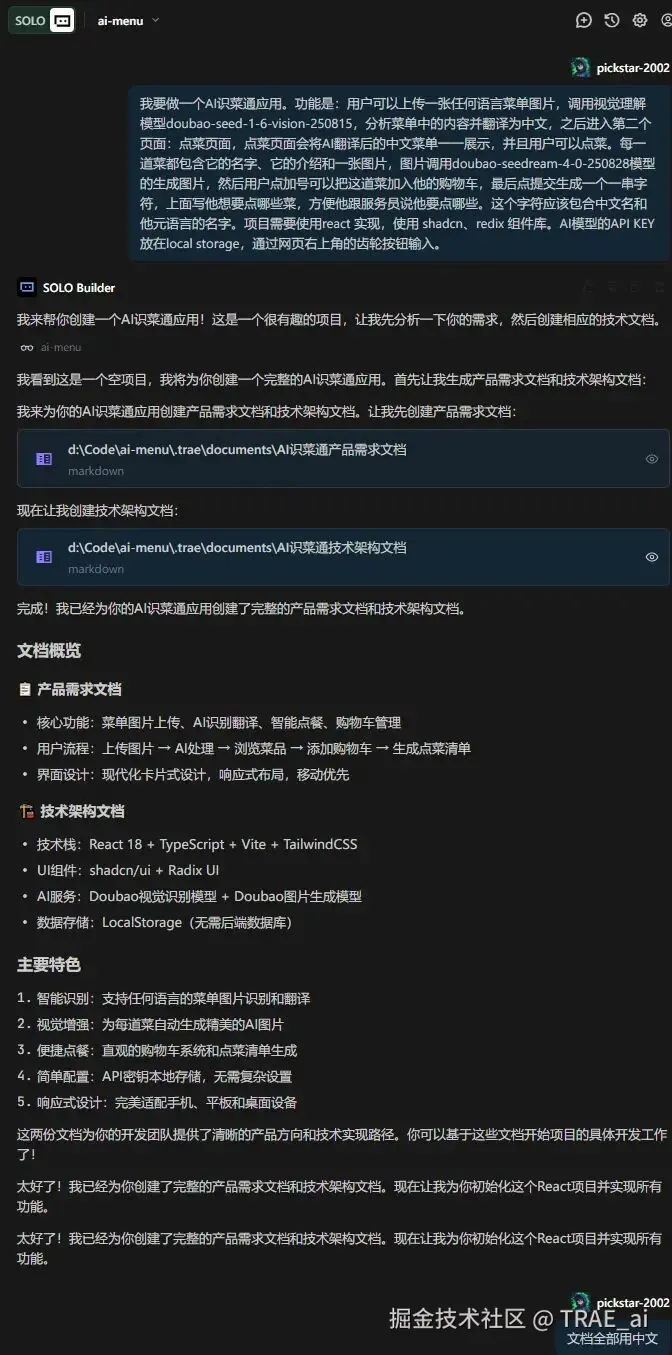
自动生成的项目文档
TRAE SOLO 会自动帮你创建两份文档,分别是需求文档和架构文档:
AI 识菜通产品需求文档
产品需求文档涵盖了产品概述、核心功能、用户流程和界面设计等方面。文档详细描述了三个主要页面:首页(菜单上传功能)、点餐页面(菜品展示列表、购物车管理)、设置页面(API 密钥配置),并绘制了完整的用户操作流程图。
makefile
# AI识菜通产品需求文档
## 1. 产品概述
AI识菜通是一款智能菜单识别与点餐应用,帮助用户快速理解任何语言的菜单内容并完成点餐。
用户只需上传菜单图片,AI即可自动识别并翻译菜单内容,生成精美的菜品图片,让用户轻松完成点餐流程。
该产品主要面向出国旅游、商务出差或在多语言环境用餐的用户,解决语言障碍带来的点餐困扰。
## 2. 核心功能
### 2.1 用户角色
本产品无需用户注册,所有功能对所有用户开放。
### 2.2 功能模块
我们的AI识菜通应用包含以下主要页面:
1. **首页**:菜单上传功能、应用介绍、导航菜单
2. **点餐页面**:菜品展示列表、购物车管理、订单生成
3. **设置页面**:API密钥配置、应用设置
### 2.3 页面详情
| 页面名称 | 模块名称 | 功能描述 |
| ---- | ------ | --------------------------------- |
| 首页 | 菜单上传区域 | 支持拖拽或点击上传菜单图片,显示上传进度和预览 |
| 首页 | 应用介绍 | 展示应用功能特色和使用说明 |
| 首页 | 导航栏 | 包含设置按钮和应用标题 |
| 点餐页面 | 菜品列表 | 展示AI识别的菜品信息,包含中文名称、原文名称、描述和AI生成图片 |
| 点餐页面 | 购物车 | 显示已选菜品数量和总览,支持增减数量 |
| 点餐页面 | 订单生成 | 生成包含中文和原文的点餐清单字符串 |
| 设置页面 | API配置 | 输入和保存Doubao API密钥 |
| 设置页面 | 应用设置 | 语言偏好、主题设置等基础配置 |
## 3. 核心流程
**主要用户操作流程:**
1. 用户进入首页,点击或拖拽上传菜单图片
2. 系统调用视觉识别AI分析菜单内容并翻译为中文
3. 跳转到点餐页面,展示识别结果和AI生成的菜品图片
4. 用户浏览菜品,点击加号将心仪菜品加入购物车
5. 确认选择后,生成包含中文和原文的点餐清单
6. 用户可将清单展示给服务员完成点餐
```mermaid
graph TD
A[首页] --> B[上传菜单图片]
B --> C[AI识别处理]
C --> D[点餐页面]
D --> E[浏览菜品]
E --> F[添加到购物车]
F --> G[生成点餐清单]
A --> H[设置页面]
H --> I[配置API密钥]
```
## 4. 用户界面设计
### 4.1 设计风格
* **主色调**:现代蓝色 (#3B82F6) 和温暖橙色 (#F59E0B)
* **辅助色**:中性灰色系 (#6B7280, #F3F4F6)
* **按钮样式**:圆角设计,悬停效果,阴影层次
* **字体**:中文使用思源黑体,英文使用 Inter 字体,主要字号 16px
* **布局风格**:卡片式设计,顶部导航,响应式网格布局
* **图标风格**:线性图标,统一的视觉语言,支持深浅主题
### 4.2 页面设计概览
| 页面名称 | 模块名称 | 界面元素 |
| ---- | ---- | -------------------------- |
| 首页 | 上传区域 | 虚线边框的拖拽区域,上传图标,进度条,图片预览卡片 |
| 首页 | 导航栏 | 应用Logo,标题,设置齿轮图标按钮 |
| 点餐页面 | 菜品卡片 | 圆角卡片,AI生成图片,菜名标题,描述文本,加号按钮 |
| 点餐页面 | 购物车 | 浮动购物车图标,数量徽章,侧边栏展开面板 |
| 设置页面 | 配置表单 | 输入框,保存按钮,状态提示,分组设置项 |
### 4.3 响应式设计
应用采用移动优先的响应式设计,完美适配手机、平板和桌面设备。在移动端优化触摸交互体验,确保按钮大小适合手指操作。
4.4 API调用示例
doubao-seedream-4-0-250828调用示例如下
curl -X POST <https://ark.cn-beijing.volces.com/api/v3/images/generations> \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your api key" \
-d '{
"model": "doubao-seedream-4-0-250828",
"prompt": "Generate 3 images of a girl and a cow plushie happily riding a roller coaster in an amusement park, depicting morning, noon, and night.",
"image": [" <https://ark-doc.tos-ap-southeast-1.bytepluses.com/doc_image/seedream4_imagesToimages_1.png> ", " <https://ark-doc.tos-ap-southeast-1.bytepluses.com/doc_image/seedream4_imagesToimages_2.png> "],
"sequential_image_generation": "auto",
"sequential_image_generation_options": {
"max_images": 3
},
"response_format": "url",
"size": "2K",
"stream": true,
"watermark": true
}'
doubao-seed-1-6-vision-250815调用示例
curl <https://ark.cn-beijing.volces.com/api/v3/chat/completions> \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your api key" \
-d $'{
"model": "doubao-seed-1-6-vision-250815",
"messages": [
{
"content": [
{
"image_url": {
"url": " <https://ark-project.tos-cn-beijing.ivolces.com/images/view.jpeg> "
},
"type": "image_url"
},
{
"text": "图片主要讲了什么?",
"type": "text"
}
],
"role": "user"
}
]
}'AI 识菜通技术架构文档
技术架构文档则从系统架构、技术选型、路由定义、API 接口、数据模型等维度进行了全面设计。架构采用纯前端方案,使用 React + TypeScript + Vite + TailwindCSS** 技术栈,集成 shadcn/ui 和 Radix UI 组件库,所有数据存储在 LocalStorage 中确保安全性。
php
# AI识菜通技术架构文档
## 1. Architecture design
```mermaid
graph TD
A[用户浏览器] --> B[React前端应用]
B --> C[Doubao Vision API]
B --> D[Doubao Image Generation API]
B --> E[LocalStorage]
subgraph "前端层"
B
F[shadcn/ui组件]
G[Radix UI组件]
H[状态管理]
B --> F
B --> G
B --> H
end
subgraph "外部服务"
C
D
end
subgraph "本地存储"
E
end
```
## 2. Technology Description
* Frontend: React@18 + TypeScript + Vite + TailwindCSS
* UI Components: shadcn/ui + Radix UI
* State Management: React Context + useState/useReducer
* HTTP Client: Fetch API
* Storage: LocalStorage
* Icons: Lucide React
* External APIs: Doubao Vision API, Doubao Image Generation API
## 3. Route definitions
| Route | Purpose |
| --------- | --------------------- |
| / | 首页,菜单图片上传和AI处理 |
| /menu | 点菜页面,显示翻译后的菜品列表和购物车功能 |
| /settings | 设置页面,配置API密钥和应用设置 |
## 4. API definitions
### 4.1 Core API
#### Doubao Vision API 调用
```
POST https://ark.cn-beijing.volces.com/api/v3/chat/completions
```
Request Headers:
| Header Name | Value | Description |
| ------------- | ----------------- | ----------- |
| Authorization | Bearer {API_KEY} | API密钥认证 |
| Content-Type | application/json | 请求内容类型 |
Request Body:
```json
{
"model": "doubao-seed-1-6-vision-250815",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "请识别这张菜单图片中的所有菜品,并翻译为中文。请按照以下JSON格式返回:{"dishes": [{"originalName": "原文名称", "chineseName": "中文名称", "description": "菜品描述", "estimatedPrice": "预估价格"}]}"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
}
```
#### Doubao Image Generation API 调用
```
POST https://ark.cn-beijing.volces.com/api/v3/images/generations
```
Request Headers:
| Header Name | Value | Description |
| ------------- | ----------------- | ----------- |
| Authorization | Bearer {API_KEY} | API密钥认证 |
| Content-Type | application/json | 请求内容类型 |
Request Body:
```json
{
"model": "doubao-seedream-4-0-250828",
"prompt": "高质量的{菜品名称}美食摄影,专业餐厅级别,自然光线,精美摆盘",
"n": 1,
"size": "1024x1024",
"quality": "standard"
}
```
### 4.2 数据类型定义
```typescript
// 菜品信息
interface Dish {
id: string;
originalName: string;
chineseName: string;
description: string;
estimatedPrice?: string;
imageUrl?: string;
isGeneratingImage?: boolean;
}
// 购物车项目
interface CartItem {
dish: Dish;
quantity: number;
}
// API配置
interface ApiConfig {
visionApiKey: string;
imageApiKey: string;
}
// 应用状态
interface AppState {
dishes: Dish[];
cart: CartItem[];
isProcessing: boolean;
processingStep: 'uploading' | 'analyzing' | 'translating' | 'generating_images' | 'completed';
apiConfig: ApiConfig;
}
```
## 5. Data model
### 5.1 LocalStorage 数据结构
由于这是一个纯前端应用,所有数据都存储在浏览器的LocalStorage中:
```typescript
// API配置存储
localStorage.setItem('ai-menu-api-config', JSON.stringify({
visionApiKey: string,
imageApiKey: string
}));
// 最近处理的菜单缓存
localStorage.setItem('ai-menu-recent-dishes', JSON.stringify({
timestamp: number,
dishes: Dish[]
}));
// 用户偏好设置
localStorage.setItem('ai-menu-preferences', JSON.stringify({
language: 'zh-CN',
imageQuality: 'standard',
autoGenerateImages: true
}));
```
### 5.2 组件状态管理
```typescript
// 全局应用状态 Context
const AppContext = createContext<{
state: AppState;
dispatch: React.Dispatch<AppAction>;
}>();
// 状态更新动作
type AppAction =
| { type: 'SET_DISHES'; payload: Dish[] }
| { type: 'ADD_TO_CART'; payload: Dish }
| { type: 'REMOVE_FROM_CART'; payload: string }
| { type: 'UPDATE_CART_QUANTITY'; payload: { dishId: string; quantity: number } }
| { type: 'SET_PROCESSING'; payload: boolean }
| { type: 'SET_PROCESSING_STEP'; payload: AppState['processingStep'] }
| { type: 'UPDATE_DISH_IMAGE'; payload: { dishId: string; imageUrl: string } };
```
## 6. 项目结构
```
ai-menu/
├── src/
│ ├── components/
│ │ ├── ui/ # shadcn/ui组件
│ │ ├── ImageUpload.tsx # 图片上传组件
│ │ ├── DishCard.tsx # 菜品卡片组件
│ │ ├── Cart.tsx # 购物车组件
│ │ ├── OrderSummary.tsx # 订单摘要组件
│ │ └── ApiKeySettings.tsx # API密钥设置组件
│ ├── pages/
│ │ ├── HomePage.tsx # 首页
│ │ ├── MenuPage.tsx # 点菜页面
│ │ └── SettingsPage.tsx # 设置页面
│ ├── hooks/
│ │ ├── useApiConfig.ts # API配置管理
│ │ ├── useImageUpload.ts # 图片上传处理
│ │ └── useCart.ts # 购物车逻辑
│ ├── services/
│ │ ├── doubaoApi.ts # Doubao API调用
│ │ └── imageService.ts # 图片处理服务
│ ├── context/
│ │ └── AppContext.tsx # 全局状态管理
│ ├── types/
│ │ └── index.ts # TypeScript类型定义
│ ├── utils/
│ │ ├── storage.ts # LocalStorage工具
│ │ └── imageUtils.ts # 图片处理工具
│ └── App.tsx
├── public/
├── package.json
├── tailwind.config.js
├── vite.config.ts
└── tsconfig.json
```上下文工程开发
如果对于 SOLO 生成的文档不满意,或者有部分地方需要修改的话,是可以直接在文档中进行编辑的,这一点做得非常丝滑,SOLO 给我的整体体验就是整个项目开发过程全在你的掌控中。
文档就是 TRAE 对整个项目的理解,这个修正过程是很有必要的。确认文档无误后,TRAE SOLO 开始按照文档进行开发。整个过程展现了上下文工程的强大能力:
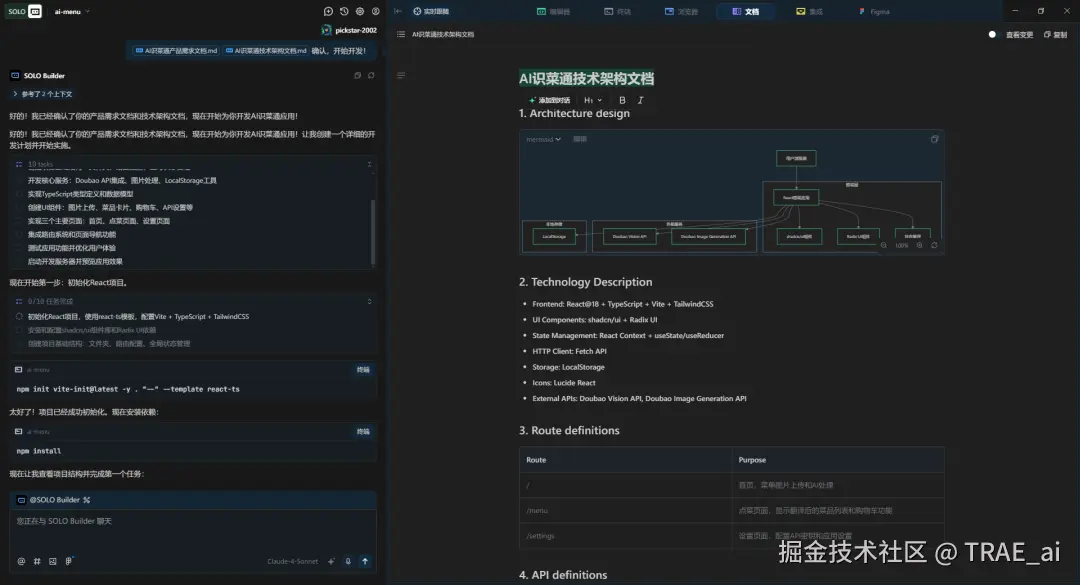
智能依赖管理
SOLO 会在开发的过程中自动下载依赖、创建配置文件、生成函数、运行终端,遇到的问题也都会被当做上下文继续完善开发。
实时错误处理
遇到编译错误时可以一键添加到上下文中进行修复,系统会根据上下文自动测试,比传统的复制控制台错误再手动调试要高效得多。
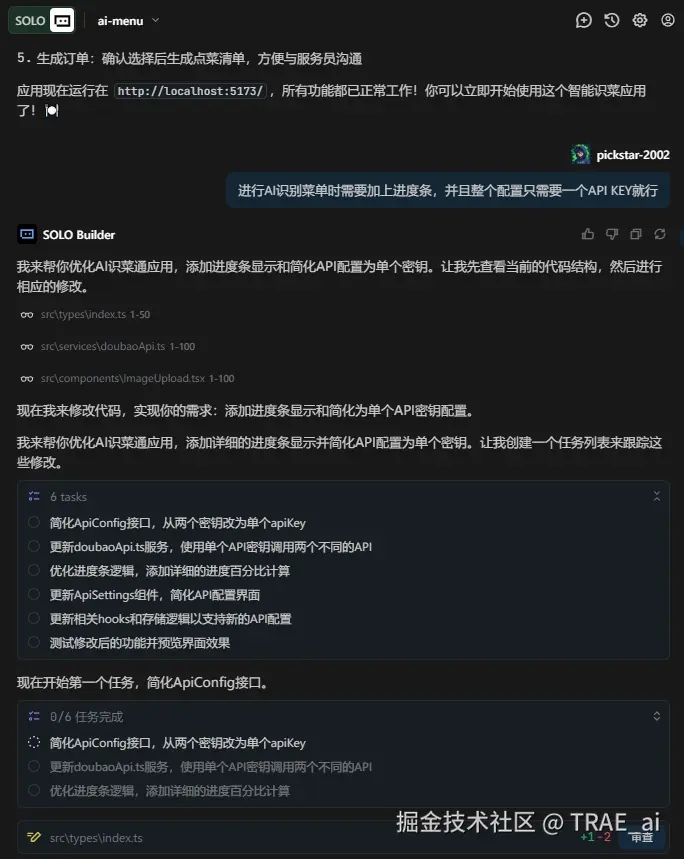
动态需求调整
开发过程中可以随时打断并提出问题或修改需求,TRAE SOLO 会根据上下文重新思考,结合已生成的内容和新提出的内容进行综合考量,确保逻辑连贯。

成果展示
部署体验
项目部署选择了 Vercel 平台,Vercel 以其卓越的开发者体验和对现代前端框架的深度支持,极大简化了部署流程,整个部署流程仅需一句话即可完成。
如果缺少 API 密钥或依赖,TRAE SOLO 会及时提醒补充信息。
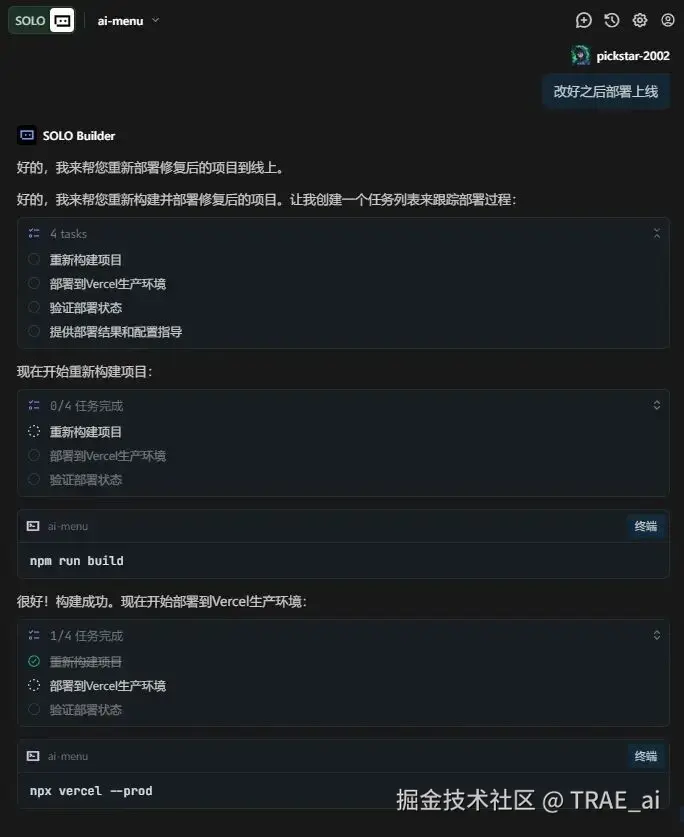
功能演示
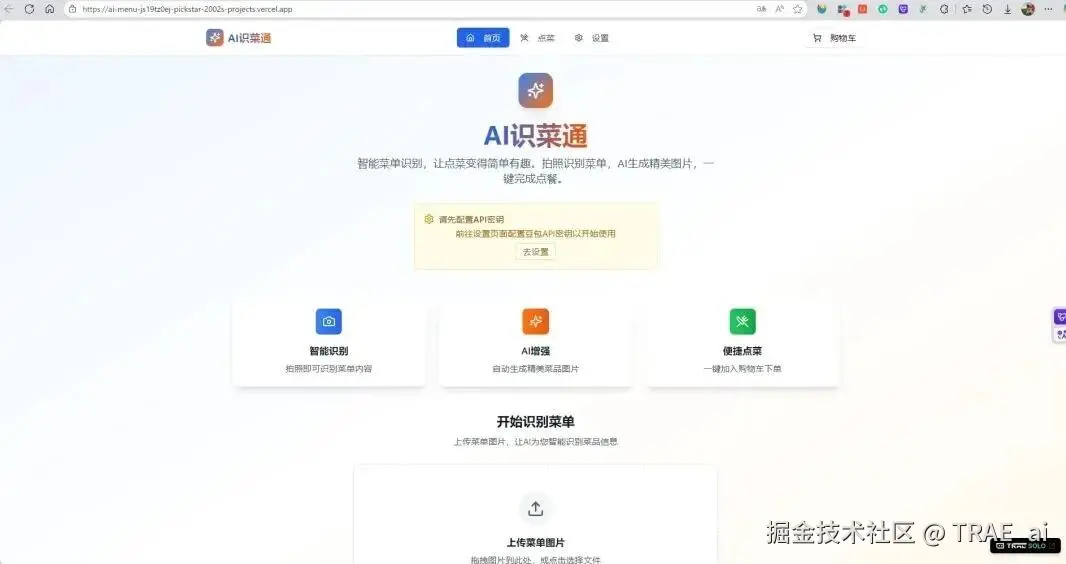
首页界面
在部署完毕之后访问 AI 识菜通网址的第一印象就是首页,界面整洁,重点突出,作为初版生成效果还是符合预期的,后续可以给 TRAE 更多参考再优化。
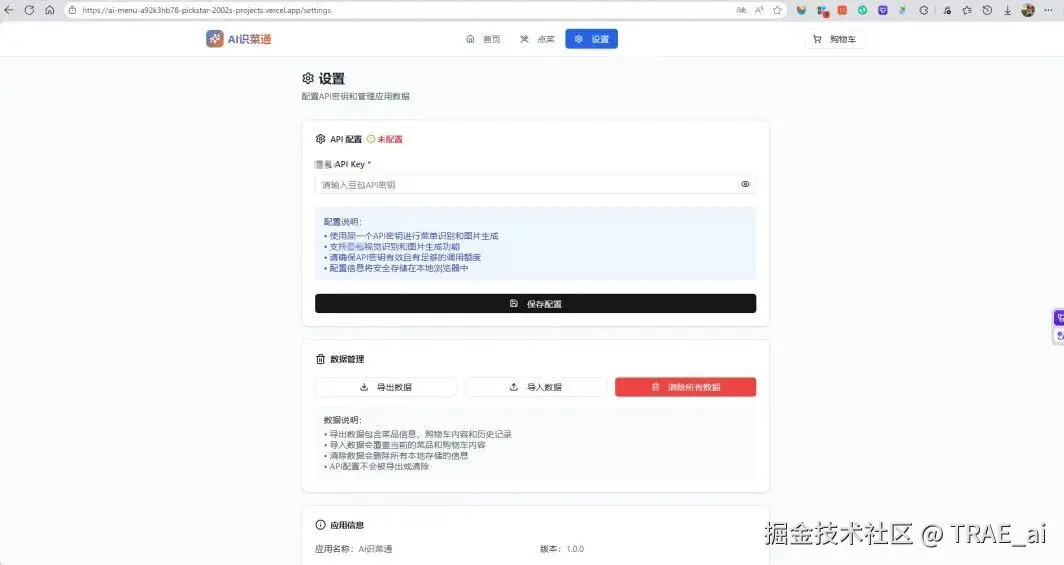
API 密钥设置
想要使用本项目的话,第一件事就是设置豆包大模型的 API 密钥,这里声明一下:用户自己的 API 密钥存放在本地的 storage 中,并不会上传到云端,确保用户的密钥安全。
菜单识别流程
我从网上下载了一份英文菜单进行测试,看看项目到底能不能打:

上传图片之后项目就会调用豆包大模型进行分析,整体的时间根据菜单内容的多少会有些出入,静静等待几分钟就好:
菜单识别完毕之后,首页会提示,点击去点菜即可看到生成的中文菜单。
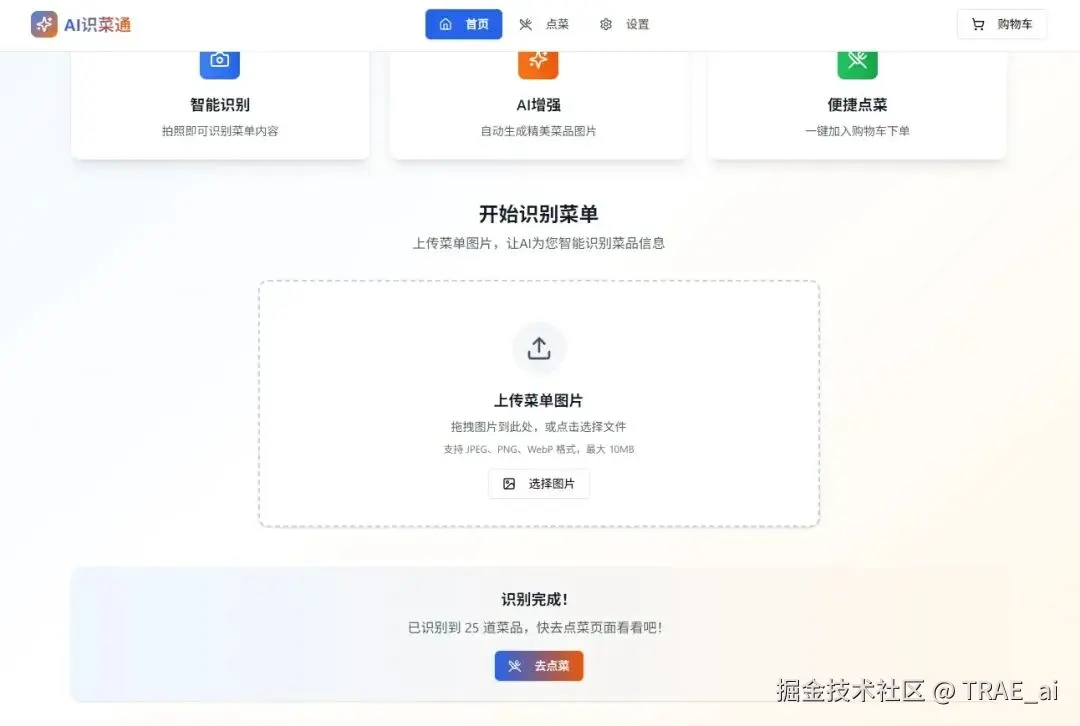
以下是生成后的结果,可以看到,生成的图片是很符合菜单中的样子的,这样让本来晦涩难懂的菜单有了活力,这也许就是科技带给我们的意义吧,服务生活,然后这样就可以顺利点菜了:
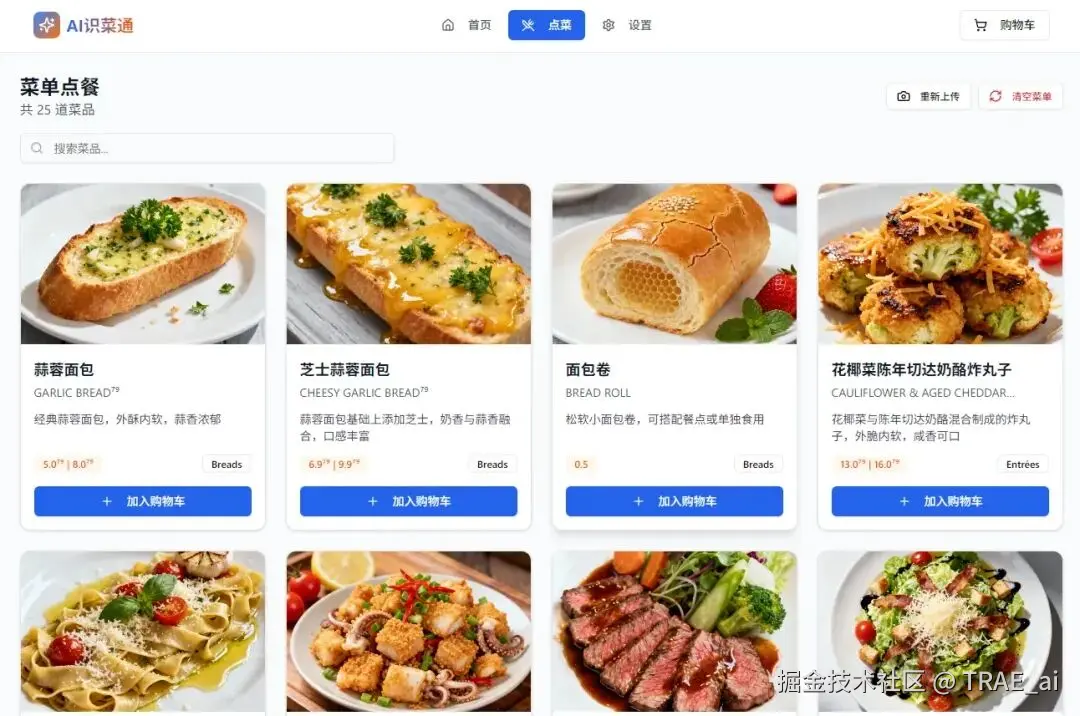
购物车管理
支持添加菜品、调整数量、删除操作,最终生成包含中文和原文的双语点餐清单,可直接展示给服务员。
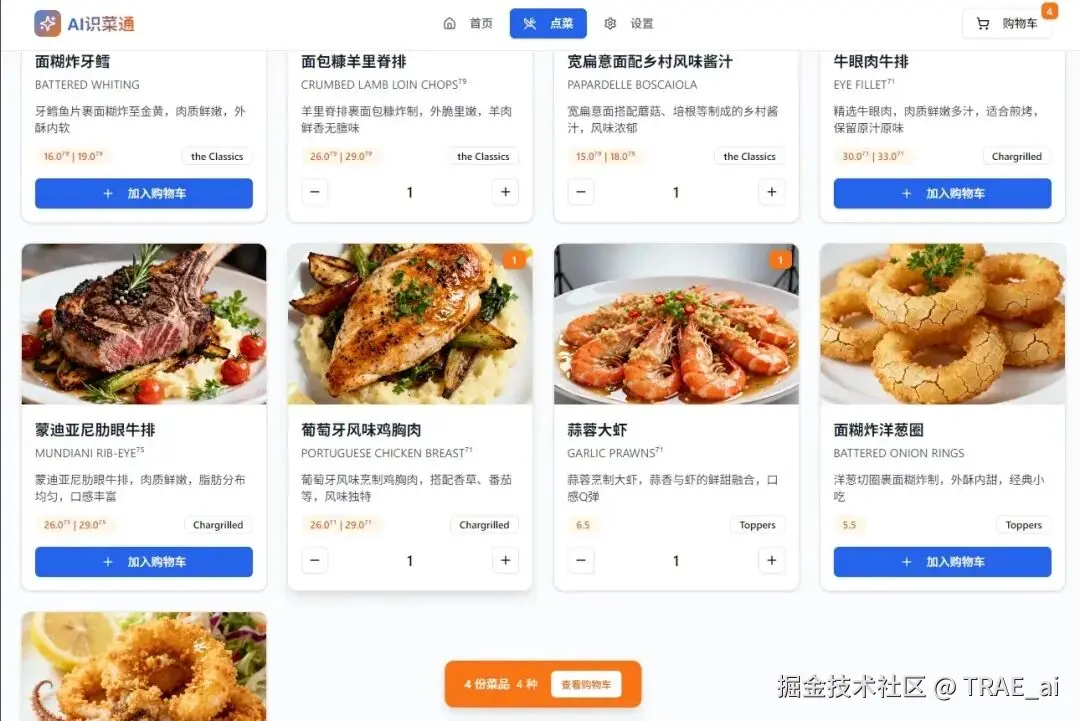
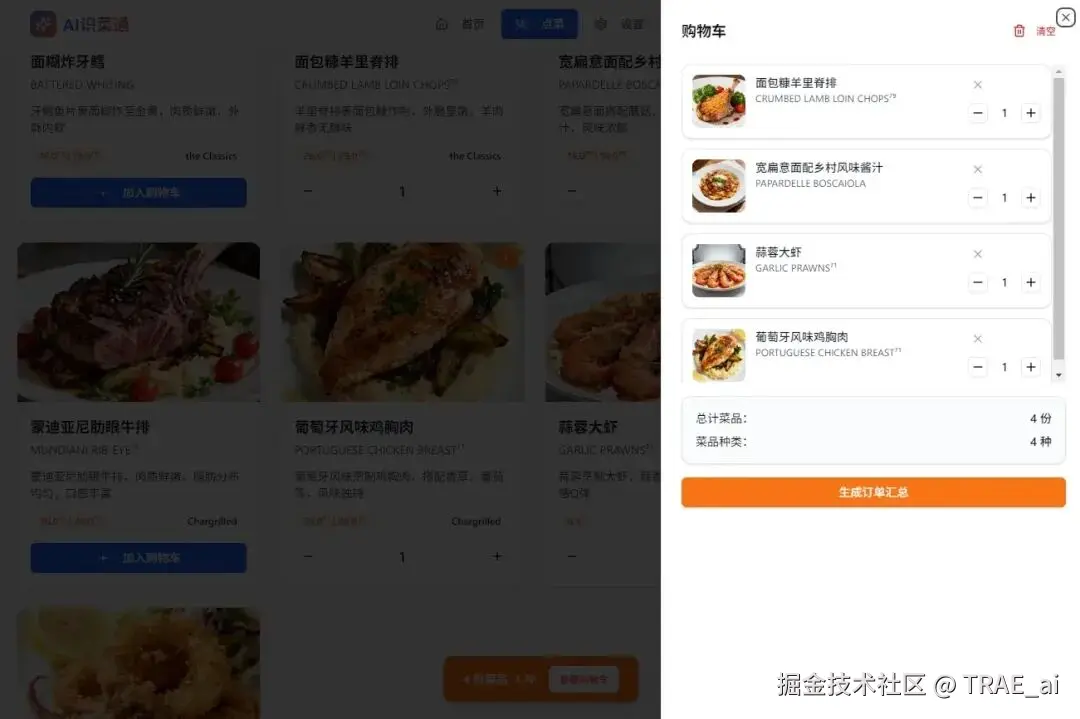
点击生成订单汇总,会生成一份刚刚的点菜 TXT 格式的清单:


总结
"AI 识菜通"是一个融合多模态 AI 能力的智能点餐应用,通过用户上传任意语言的菜单图片,自动调用豆包大模型(doubao-seed-1.6-vision)进行视觉识别与翻译,再结合 Seedream 4.0 生成高质量菜品图像,最终实现结构化中文菜单展示、购物车管理与点餐清单生成。整个项目采用 React + TypeScript 技术栈,集成 shadcn/ui 与 Radix UI 组件库,所有数据(包括 API 密钥)均本地存储于浏览器 LocalStorage,无需后端依赖。项目通过 Vercel 实现一键部署,具备完整的响应式设计与流畅的用户交互体验。
在这个过程中,TRAE SOLO 不仅是一款开发工具,更像一位"全栈 AI 工程师搭档" 。它从需求理解开始,自动生成产品文档与技术架构,再逐步完成项目初始化、依赖安装、组件开发、错误修复与部署上线,全程丝滑流畅。其上下文感知能力极强------即使中途打断或修改需求,也能基于已有上下文智能调整,确保逻辑连贯。更难得的是,它对开发者体验极度友好:自动处理依赖冲突、一键修复语法错误、实时预览效果,真正实现了"Talk。 Think. Ship."的开发哲学。