为什么需要微调?
在开始学习微调之前,大家首先还是要搞清楚为什么要微调?在什么情况下需要微调?
我们平常接触到的大模型如 Qwen、DeepSeek 等都是基于海量的通用数据训练而成的,它们都具备非常强大的语言理解和生成能力,能够处理多种自然语言任务。但是,这些模型在某些特定领域或任务上的表现可能并不理想,或者说还能够做到更好。下面是需要微调的几个主要原因:
领域专业化:
- 原因:通用模型的训练数据覆盖面广,但难以深入垂直领域的知识体系和专业术语。例如医学诊断需理解病理特征,法律咨询需熟悉法条逻辑。当模型在专业领域认知不够时,会出现比较严重的幻觉问题,也就是胡乱回答,微调可以很好的解决这个问题。
- 典型场景:
- 医学问答:输入症状描述,模型需结合医学知识库输出可信的初步诊断建议。
- 法律咨询:分析"未成年人合同效力"时,需准确引用《民法典》相关条款。
任务适配:调整模型的"输出模式"
- 原因:不同任务对模型能力的要求差异显著------分类任务需结构化输出,生成任务需语言创造力。
- 典型场景:
- 文案生成:训练模型以幽默风格撰写广告文案(如"这杯咖啡,比老板的早安更提神")。
快速低成本
比起从头训练一个模型(相当于重新培养一个大学生),微调就像让学霸参加一个短期培训班,省时省力。
长文本、知识库和微调的区别
现在各大模型都支持超长上下文,从最开始的 4K 到现在的 200K,我们不能用一个比较完善的提示词来解决这些问题吗?现在各种知识库工具这么灵活,我们不能自己搭建一个非常全面的数据库来解决这些问题吗?
这可能会是很多小伙伴存在的疑问,下面我们就来看看长文本、知识库、微调究竟有什么区别,我们又该在什么场景下做什么样的选择呢?
为了方便大家理解,我们后面把模型回答一个问题类比为 参加一场考试。
长文本
通俗理解:你参加了一场考试,题目是一篇超长的阅读理解。这篇文章内容很多,可能有几千字,你需要在读完后回答一些问题。这就像是"长文本"的任务。模型需要处理很长的文本内容,理解其中的细节和逻辑,然后给出准确的答案。比如,模型要读完一篇长篇小说,然后回答关于小说情节的问题。
知识库
优点:
- 准确性高:只要知识库中存在相关信息,模型均能准确回答。
- 灵活性高:支持随时更新知识库内容,确保模型获取最新信息。
- 扩展性强:无需重新训练模型,仅需更新知识库即可回答新问题。
缺点: - 依赖检索质量:若知识库信息不准确或不完整,模型回答会受影响。
- 实时性要求高:需快速完成知识库检索与信息整合,对系统性能有一定挑战。
适用场景: - 智能客服:快速检索解决方案,高效回应用户咨询。
- 问答系统:结合知识库处理需背景知识的复杂问题。
- 研究辅助:帮助研究人员快速定位相关文献或资料。
环境准备
硬件
GPU 4090 24G CPU 8C
软件
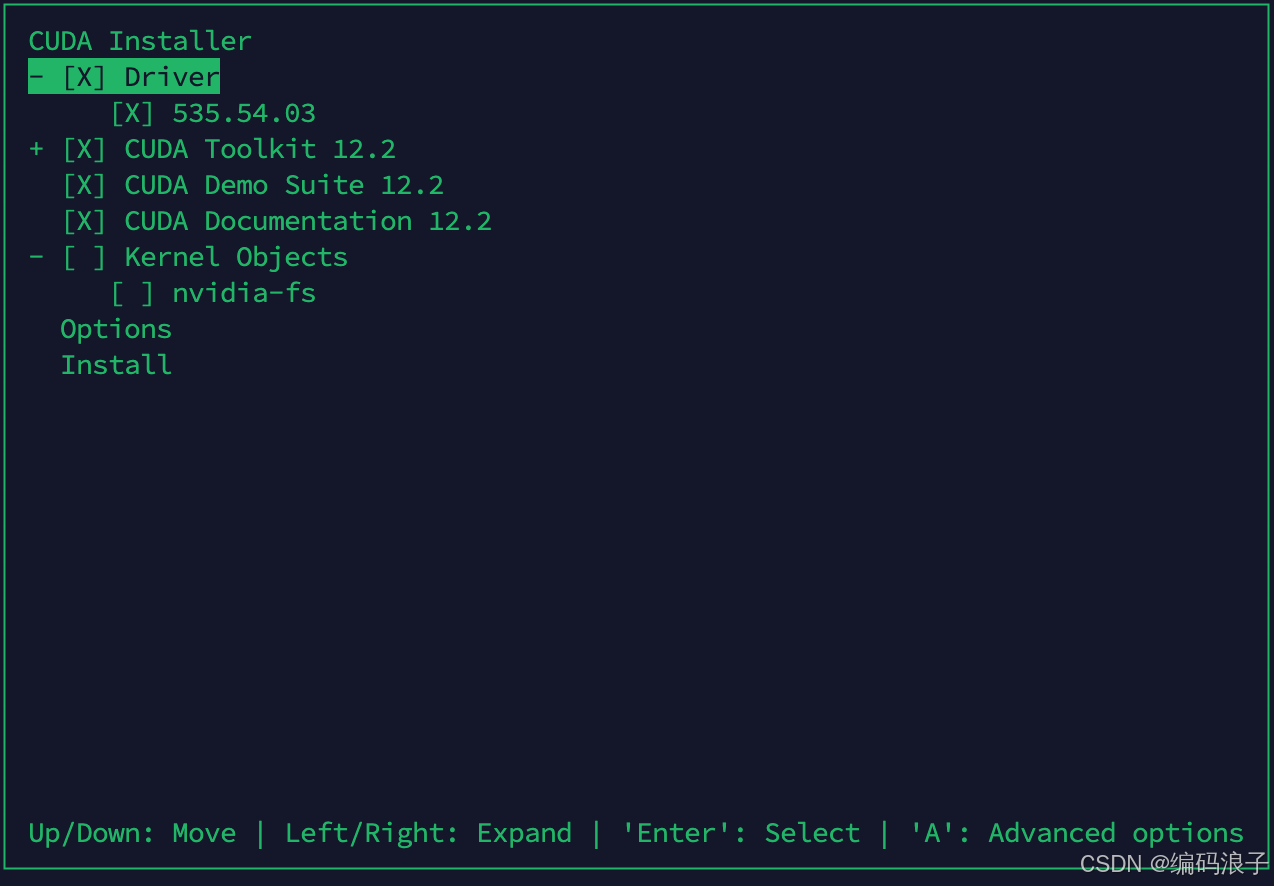
bash
=========== = Summary = =========== Driver: Not Selected Toolkit: Installed in /usr/local/cuda-12.2/ Please make sure that - PATH includes /usr/local/cuda-12.2/bin - LD_LIBRARY_PATH includes /usr/local/cuda-12.2/lib64, or, add /usr/local/cuda-12.2/lib64 to /etc/ld.so.conf and run ldconfig as root To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-12.2/bin ***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 535.00 is required for CUDA 12.2 functionality to work. To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file: sudo <CudaInstaller>.run --silent --driver Logfile is /var/log/cuda-installer.log配置环境变量
bash
=========== = Summary = =========== Driver: Not Selected Toolkit: Installed in /usr/local/cuda-12.2/ Please make sure that - PATH includes /usr/local/cuda-12.2/bin - LD_LIBRARY_PATH includes /usr/local/cuda-12.2/lib64, or, add /usr/local/cuda-12.2/lib64 to /etc/ld.so.conf and run ldconfig as root To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-12.2/bin
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 535.00 is required for CUDA 12.2 functionality to work. To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file: sudo <CudaInstaller>.run --silent --driver Logfile is /var/log/cuda-installer.logvim ~/.bashrc #最后一行添加 export PATH=/usr/local/cuda-12.2/bin:PATH export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:LD_LIBRARY_PATH #验证是否安装成功 nvcc -V
安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python=3.10 source /home/yege/opt/anaconda3/bin/activate root conda activate llama_factory pip install -e '.torch,metrics' #查看是否安装成功 (llama_factory) root@10-60-175-68:/opt/project/LLaMA-Factory# llamafactory-cli version
启动webUI
llamafactory-cli webui
数据处理
指令监督微调
可以理解为给AI模型"上补习班",专门训练它更准确地听懂和完成各种指令。就像学生已经学了各科基础知识后,再针对考试题型进行专项练习。具体来说:
- 基础阶段:模型先通过海量文本(如书籍、网页)自学,掌握通用语言能力,但还不擅长精确执行任务。
- 补习教材:准备大量"习题集"------由人类编写的【指令+标准答案】配对,例如:
- 指令:"用东北话夸这个蛋糕好吃"
- 答案:"哎妈呀这蛋糕也太得劲儿了,老吃了!"
- 专项训练:让模型反复学习这些例子,逐渐明白类似指令该用什么格式、语气、内容来回应。就像学生通过刷题掌握"写议论文需要论点,论据,论证等","诗歌题要注意押韵"等技巧。
- 效果提升:经过训练后,当收到"把'早上好'翻译成四川话"这种指令时,模型不再笼统回答,而是精准输出"早桑好噻",且能举一反三应对新指令。
这种方法让AI从"懂很多但不会做题"的杂学家,变成"听得懂要求、答得准需求"的贴心助手。就像教新人同事时,不仅告诉他知识,还演示"当客户说XX时,你应该按照YY格式回应"。
预训练
大语言模型的预训练,可以想象成让一个"小语言天才"泡在人类社会的语言海洋里疯狂"偷听"------虽然没人刻意教他,但他通过观察海量对话和文字,自己总结出了语言的规律。
- 学习方式:就像小孩听大人聊天学会说话一样,模型通过"偷看"互联网上所有能抓到的文字(比如新闻、小说、论坛吵架、菜谱、甚至冷笑话),自己琢磨出:
- 词语怎么搭配(比如"喝咖啡"对,"吃咖啡"错)
- 上下文如何关联("下雨了要带___"后面大概率是"伞")
- 甚至隐藏的常识("西瓜是水果"但"番茄沙拉"里番茄算蔬菜)
- 教材特点:用的全是未经人工标注的原始文本,相当于给模型一堆乱序的《新华字典》+《知网论文》+《微博热搜》+《外卖评论》的大杂烩,让它自己从中找规律。
- 为什么有效:互联网文本的多样性(科技、八卦、方言、专业术语...)相当于让模型见识了人类语言的所有"变化",使它不仅能看懂正经文书,还能理解"PUA","绝绝子"这种网络黑话。
举个栗子:模型读到100万次"猫爱吃鱼"和"狗爱啃骨头"这类句子后,就算没人明确告诉它"动物习性",它也会自动建立"猫→鱼""狗→骨头"的关联。下次你问"什么动物喜欢追老鼠?",它就能结合"猫抓老鼠"的常见文本组合给出答案。
这种训练让模型从"语言复读机"进化成"语言规律侦探",为后续的指令微调打下基础,相当于先让它成为"语言通才",再培养成"专项能手"。
偏好数据集
可以用"让AI参加人类审美培训班"来比喻。就像教人审美不能只背理论,而要不断对比好设计和烂设计 ,AI也需要通过成对的优劣答案来理解"人类究竟喜欢什么"。
通俗拆解:
- 数据集本质:相当于给AI准备无数组"审美判断题",每组包含:
- 题干:同一个问题(如"怎么婉拒同事借钱?")
- 选项A(优答):"最近手头紧,我也正想找你周转呢"(幽默转移矛盾)
- 选项B(差答):"我没钱,别找我"(生硬易得罪人)
→ 告诉AI:"A是高分答案,B是低分答案"
- 训练逻辑:让AI化身"语言的评委",通过海量对比练习,逐渐摸透人类的隐藏评分标准:
- 人类更喜欢有同理心的回答("我理解你急需用钱...")
- 排斥机械重复问题的回答("关于如何拒绝借钱,这是一个复杂的社会学问题...")
- 甚至能感知微妙偏好(用表情符号🤝比用句号显得更亲切)
- 为什么小模型能逆袭:这个就相当于两个学生备考:
- 死记硬背型学霸(大模型):背下整本《人类对话大全》,但考试时容易"掉书袋",答非所问
- 技巧型学渣(小模型):虽然知识量少,但通过分析历年真题参考答案(偏好数据),精准掌握"踩分点",反而更会"揣摩出题人意图"
举个栗子:
假设你要训练AI成为"奶茶点单助手": - 传统方法:让AI读遍所有奶茶配方文档 → 结果可能输出"根据流体力学,珍珠在波霸奶茶中的沉降速度..."
- 偏好训练:给AI看大量对比数据:
- 差评回答:"推荐经典珍珠奶茶"(太笼统)
- 好评回答:"您喜欢茶味浓还是奶味重?最近流行的'桂花乌龙鲜奶+脆波波'适合春秋季哦~"(主动追问需求+结合场景)
→ 经过训练后,小模型也能学会"像人类店员一样贴心推荐"
这种训练让AI从"百科全书复读机"进化成"人类心理揣摩大师",用质量换参数,就像优秀的厨师不需要拥有全世界食材,只要懂得如何组合有限原料做出米其林口感。
KTO 数据集
KTO 数据集与偏好数据集的核心区别可以用"单选评分" vs "双选对比"来理解。用一个生活化的比喻解释:
偏好数据集:像老师批改选择题,给你两篇学生作文(A和B),让你选出更好的一篇。模型通过大量"A比B好"或"B比A好"的对比样本,学会区分回答质量的高低。
KTO 数据集:像老师直接给单篇作文打分,只标"合格"或"不合格"。每个问题只对应一个回答,人类直接判定这个回答是否达标(true/false)。模型通过大量"对/错"标签直接学习人类的好恶标准。
- 数据结构差异:
- 偏好数据集:每行数据包含 问题, 回答A(较好), 回答B(较差),需人工比较两个回答。
- KTO 数据集:每行数据是 问题, 单个回答, kto_tag(true/false),只需人工判断该回答是否符合要求。
- 应用场景:
- 如果你有大量现成的用户反馈(比如聊天中的点赞/点踩),直接整理成 KTO 格式更简单,无需费力构造对比对。
- 如果你希望模型深入理解回答间的细微差距(比如法律文书措辞的严谨性),偏好数据更适合。
- 训练原理:
- 偏好数据训练:模型学习"好回答比差回答好多少"(类似排序学习)。
- KTO 训练:模型直接学习"什么样的回答会让人点赞,什么样的会让人点踩"(类似二分类)。
举个栗子:
- 问题: "如何泡绿茶?"
- 偏好数据集:
- 回答A(优):"80℃水冲泡3分钟,保留茶香。"
- 回答B(差):"开水直接煮茶叶5分钟。"
→ 标注:A > B - KTO数据集:
- 回答:"开水煮茶5分钟。" → kto_tag:
false - 回答:"80℃水冲泡3分钟。" → kto_tag:
true
关键优势:KTO 摆脱了必须构造对比对的束缚,更适合直接从真实用户反馈(点赞/举报等)中收集数据,成本更低。但代价是无法学习回答间的相对优劣,只关注绝对质量阈值。
多模态数据集
通俗版解释:
想象你教一个机器人当服务员,既要看懂顾客发的文字消息(比如"推荐这道菜"),又要能看顾客随手拍的菜单照片。这时候你的训练数据就得像这样:
| 文字指令 | 图片路径 | 理想回答 | |----------------|---------------|-----------------------| | "推荐这道菜" | ./images/1.jpg | "这是本店招牌红烧肉" | | "食材过敏吗?" | ./images/2.jpg | "图片中的虾饺含海鲜" |
关键点:
- 图片路径代替直接存图
→ 就像菜谱只写"参考第5页图",实际炒菜时才翻书看图,避免把整本菜谱背下来(节省内存) - 单图限制
→ 当前机器人像「单线程大脑」,一次只能分析一张照片(比如先看菜品图,暂时不能同时对比环境图和食材图)
类比日常:
你用微信点餐时发一句"要这个套餐"+随手拍菜单,客服结合你的文字和图片才能正确接单------多模态数据集就是在模拟这种「图文双线索」的对话模式。
模型下载
通过hugginface下载
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
通过modelScope下载
modelscope download --model Qwen/Qwen2.5-7B-Instruct README.md --local_dir /opt/models modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B README.md --local_dir /opt/models