Linux系统--信号(4--信号捕捉、信号递达)陌生概念篇
前言:
- 时钟中断
- 时钟系统
- 用户空间,用户栈,内核空间,内核栈
- 调度器
- 可重入函数
- volatile关键字
时钟中断
我们来简单了解一下时钟中断这个操作系统的心脏跳动机制。它是现代操作系统实现多任务、实时响应和系统调度的基石。
什么是时钟中断?
时钟中断(Timer Interrupt)是一种由硬件定时器 周期性触发的硬件中断。它就像系统的心脏起搏器,以固定频率(如每秒100次、1000次)向CPU发送电信号,强制打断当前执行流,让CPU执行特定的中断处理程序。
核心作用 :为操作系统提供时间基准 和强制调度点,使系统能够:
- 实现多任务分时复用("同时"运行多个程序)
- 跟踪系统运行时间
- 实现超时控制
- 支持定时器功能
时钟中断的作用
uptime:含义: 指的是系统自上次启动(或重启)以来已经持续运行了多长时间。它表示系统不间断工作的时间长度。
| 作用领域 | 具体功能 |
|---|---|
| 进程调度 | 检查进程时间片是否耗尽,触发调度器切换进程(如Linux的 CONFIG_HZ=1000) |
| 系统计时 | 更新系统时间(jiffies计数器),维护uptime(uptime是运行时间/在线时间) |
| 定时器管理 | 触发用户空间的alarm()、setitimer(),内核的timer_list软定时器 |
| 性能统计 | 计算CPU利用率、进程运行时间 |
| 看门狗 | 检测系统卡死(长时间不响应中断可能触发重启) |
| 节能管理 | 在空闲时调度CPU进入低功耗状态(C-states) |
时钟中断的原理与工作流程
硬件层:中断信号的产生
生成基准频率 配置中断频率 发送INTR信号 晶体振荡器 可编程间隔定时器 PIT 高级可编程中断控制器 APIC CPU核心
- 基准时钟源:主板上的石英晶体振荡器(如14.318MHz)提供稳定频率
- 可编程定时器 :
- 传统PIT (Intel 8254):通过端口
0x40-0x43配置 - 本地APIC定时器(现代CPU内置):更精确,支持每核独立定时
- 传统PIT (Intel 8254):通过端口
- 中断控制器:APIC将定时器中断路由到目标CPU核心
- 中断信号:以电信号形式通过INTR引脚通知CPU
频率设置示例:
若设置100Hz(每秒100次中断):
定时器初值 = 基准频率 / 目标频率 = 14,318,000 / 100 = 143,180
软件层:中断处理流程
c
// 简化版Linux时钟中断处理流程
void timer_interrupt(struct pt_regs *regs)
{
// 1. 更新计时基准
jiffies_64++; // 全局64位计时器(自启动以来的滴答数)
// 2. 更新进程时间统计
update_process_times(user_mode(regs));
// 3. 触发调度检查
scheduler_tick();
// 4. 处理软定时器
run_timer_list();
// 5. 通知高精度定时器(若有)
hrtimer_run_queues();
}详细步骤:
-
硬件自动动作:
- CPU保存当前上下文(RIP, RFLAGS等)到内核栈
- 根据中断号(如APIC定时器中断为
0x20)查找IDT - 跳转到预设的中断处理程序(如Linux的
apic_timer_interrupt)
-
中断上半部(Top Half):
-
更新全局时间 :递增
jiffies计数器 -
进程时间统计:
cvoid update_process_times(int user_tick) { current->utime += user_tick; // 用户态时间 current->stime += !user_tick; // 内核态时间 current->sched_time++; // 总时间片计数 } -
调度器心跳:
cvoid scheduler_tick(void) { curr->sched_class->task_tick(rq, curr, 0); // 调用调度类方法 if (need_resched()) set_tsk_need_resched(curr); // 标记需要调度 }
-
-
中断下半部(Bottom Half):
- 软定时器处理 :执行到期的内核定时器(
timer_list) - 唤醒工作队列 :延迟任务(如
schedule_delayed_work())
- 软定时器处理 :执行到期的内核定时器(
-
中断返回:
- 检查是否有待处理信号或需要调度
- 通过
iretq指令恢复被中断的上下文
时钟中断与硬件中断的关系
包含关系
硬件中断 外部设备中断 时钟中断 处理器异常 键盘中断 网络包到达 周期性时钟中断 高精度定时器中断
-
时钟中断是硬件中断的子集:
- 所有硬件中断都通过中断控制器(APIC)传递
- 时钟中断有专用中断号(如x86的IRQ 0或APIC定时器中断)
-
关键区别:
特性 时钟中断 其他硬件中断 触发方式 周期性(固定频率) 事件驱动(异步发生) 可预测性 严格周期 随机性高 系统依赖度 操作系统核心功能 设备特定功能 处理延迟要求 中等(微秒级) 高速设备需极低延迟(如网络) -
协作关系:
- 时钟中断驱动调度:当网卡中断处理耗时过长时,时钟中断会强制打断它,防止一个进程垄断CPU
- 其他中断依赖计时:网络协议栈的重传定时器、磁盘I/O超时都依赖时钟中断维护的时间基准
现实案例:Linux的调度时钟
假设配置 CONFIG_HZ=1000(每秒1000次中断):
-
每1ms触发一次中断
-
调度器决策:
-
检查当前进程时间片:
c// CFS调度器的时间片检查 if (--curr->time_slice <= 0) { resched_curr(rq); // 标记需要重新调度 } -
若进程时间片耗尽,设置
TIF_NEED_RESCHED标志
-
-
调度时机:
- 中断返回用户态前
- 系统调用返回时
- 进程主动调用
schedule()
效果 :即使一个进程执行死循环
while(1);,时钟中断也会每1ms夺回CPU控制权,给其他进程运行机会。
总结:时钟中断的核心价值
- 时间基石 :维护系统唯一的时间基准(
jiffies) - 公平卫士:通过强制中断实现进程间CPU时间共享
- 系统脉搏:驱动定时任务、超时检测、性能监控
- 节能助手:在空闲时调度CPU休眠
正如计算机科学家David Wheeler所说:
"计算机科学中的任何问题,都可以通过增加一个间接层来解决。"
时钟中断正是这个"间接层"------它通过硬件强制的周期性打断,让操作系统这个"交通警察"得以重新分配道路(CPU时间),确保整个系统流畅运行。
时钟系统
我们来简单了解一下操作系统的时钟系统,它远不止是"时钟中断"那么简单,而是整个操作系统的时间管理和心跳机制。
一、时钟系统是什么?
时钟系统是操作系统内核中负责所有时间相关功能的子系统 。它由硬件计时设备 和内核时间管理软件共同构成,为系统提供从纳秒到年度的全方位时间服务。
核心组件:
c
// Linux时钟系统主要模块
linux/kernel/time/
├── timekeeping.c // 核心时间维护
├── tick-common.c // 时钟中断处理
├── hrtimer.c // 高精度定时器
├── itimer.c // 间隔定时器
└── posix-timers.c // POSIX定时器二、时钟系统的作用:操作系统的时间基石
uptime(运行时间/在线时间):
含义: 指的是系统自上次启动(或重启)以来已经持续运行了多长时间。它表示系统不间断工作的时间长度。
wall clock time(挂钟时间/墙上时间/真实时间):
含义: 指的是我们日常生活中使用的、从钟表或日历上读到的实际时间。它就是我们通常所说的"现在几点"、"今天是几号"。
| 功能领域 | 具体应用 |
|---|---|
| 进程调度 | 时间片轮转、CPU时间统计、公平调度 |
| 系统计时 | 维护uptime、wall clock时间(年月日时分秒) |
| 定时器服务 | 用户空间alarm()、setitimer(),内核timer_list |
| 性能剖析 | 进程运行时间统计、系统负载计算 |
| 网络协议 | TCP超时重传、连接保持计时 |
| 文件系统 | 文件时间戳(atime/mtime/ctime)、缓存超时 |
| 多媒体 | 音视频同步、帧率控制 |
| 电源管理 | 休眠唤醒调度 |
三、时钟系统的架构:硬件与软件的协同
1. 硬件层:时间源的多层次结构
晶体振荡器 TSC
时间戳计数器 HPET
高精度事件定时器 ACPI PM Timer
电源管理定时器 PIT
可编程间隔定时器 时钟源选择 jiffies
系统滴答计数 ktime
纳秒精度时间
硬件时钟源对比:
| 时钟源 | 精度 | 功耗 | 适用场景 |
|---|---|---|---|
| TSC | 纳秒级(CPU周期) | 极低 | 高性能时间戳 |
| HPET | 100纳秒 | 中 | 通用高精度定时 |
| ACPI PM Timer | 1微秒 | 低 | 电源管理敏感场景 |
| PIT | 1毫秒 | 高 | 传统兼容(逐步淘汰) |
jiffies与硬件计时器的关系
jiffies本身不是硬件计时器。 它是一个软件维护的计数器。- 硬件计时器驱动
jiffies: 系统有一个硬件计时器(通常是 CPU 上的高精度事件定时器 HPET、ACPI PM Timer 或旧的 PIT)。这个硬件计时器被配置为以HZ指定的频率周期性地向 CPU 发送中断信号。 - 中断处理程序: 每当接收到这个定时器中断 (也称为 timer interrupt 或 timer tick )时,内核的定时器中断处理程序就会被调用。
- 更新
jiffies: 这个中断处理程序的核心任务之一就是递增jiffies的值 (通常是加 1)。这就是jiffies计数值增长的来源。 - 执行定时任务: 除了更新
jiffies,定时器中断处理程序还负责检查是否有到期的内核定时器需要执行,更新进程时间统计信息(用户态时间、内核态时间),计算系统负载平均值等。
2. 软件层:Linux时间子系统架构
c
// 简化版时钟系统初始化
void __init time_init(void)
{
// 1. 选择最佳硬件时钟源
clocksource_default_clockevent_init();
// 2. 初始化jiffies计数器
tick_init();
// 3. 设置周期性时钟中断
init_timers();
// 4. 初始化高精度定时器
hrtimers_init();
// 5. 启动时间保持子系统
timekeeping_init();
}四、时钟系统工作流程:从硬件中断到时间服务
1. 时钟中断处理完整流程
硬件定时器 CPU核心 时钟中断处理 调度器 定时器子系统 时间保持核心 周期性中断触发(如1000Hz) 执行tick_handle_periodic() 更新时间基准 更新jiffies_64计数器 维护monotonic/wall time 触发调度器tick 更新进程时间统计 检查时间片耗尽 处理软件定时器 执行到期的timer_list 中断返回 硬件定时器 CPU核心 时钟中断处理 调度器 定时器子系统 时间保持核心
2. 时间维护核心:timekeeping.c
c
// 简化版时间更新逻辑
void update_wall_time(void)
{
// 读取硬件时钟源
cycle_t cycle_now = clocksource_read(clock);
// 计算经过的纳秒数
nsec = (cycle_now - cycle_last) * clock->mult >> clock->shift;
// 更新各种时间基准
tk->tkr_mono.cycle_last = cycle_now;
tk->tkr_mono.xtime_nsec += nsec;
// 处理秒进位
while (tk->tkr_mono.xtime_nsec >= NSEC_PER_SEC) {
tk->tkr_mono.xtime_nsec -= NSEC_PER_SEC;
tk->xtime_sec++;
}
}3. 定时器管理:从秒到纳秒的精度覆盖
c
// Linux定时器层次
struct timer_list { // 传统定时器(毫秒级)
unsigned long expires; // 到期jiffies值
void (*function)(...); // 回调函数
};
struct hrtimer { // 高精度定时器(纳秒级)
ktime_t expires; // 到期ktime值
enum hrtimer_restart (*function)(...);
};
// 用户空间定时器接口
// 秒级:alarm(), sleep()
// 毫秒级:usleep(), poll()
// 微秒级:nanosleep(), select()
// 纳秒级:clock_nanosleep()五、时钟中断 vs 时钟系统:部分与整体的关系
1. 包含关系
时钟系统 硬件时间源 时间维护子系统 定时器管理 用户时间接口 时钟中断发生器 周期性tick中断 高精度定时器 传统定时器 gettimeofday等系统调用
2. 功能对比
| 特性 | 时钟中断 | 时钟系统 |
|---|---|---|
| 范围 | 单一机制(中断产生) | 完整子系统(硬件+软件) |
| 主要功能 | 提供周期性心跳 | 全方位时间服务 |
| 精度 | 依赖配置(通常1ms-10ms) | 从纳秒到年的全范围精度 |
| 组件 | 中断处理函数 | 时钟源、定时器、时间维护等模块 |
| 关系 | 时钟系统的"驱动引擎" | 包含时钟中断的完整生态 |
3. 协作示例:一次setitimer()的完整旅程
c
// 用户程序设置定时器
setitimer(ITIMER_REAL, &value, NULL);
// 内核处理流程:
SYSCALL_DEFINE3(setitimer) {
// 1. 参数验证和转换
struct itimerval kvalue;
copy_from_user(&kvalue, value);
// 2. 计算到期时间(基于时钟系统的时间基准)
expires = kvalue.it_value.tv_sec * NSEC_PER_SEC
+ kvalue.it_value.tv_usec * NSEC_PER_USEC;
expires += ktime_get_real_ts64(); // 获取当前时间
// 3. 设置高精度定时器
hrtimer_start(¤t->signal->real_timer,
expires, HRTIMER_MODE_ABS);
}
// 定时器到期时:
void it_real_fn(struct hrtimer *timer) {
// 4. 发送SIGALRM信号
send_sig(SIGALRM, current, 0);
// 5. 如需重复,重新设置定时器
if (current->signal->it_real_incr) {
hrtimer_forward(timer, timer->base->get_time(),
current->signal->it_real_incr);
return HRTIMER_RESTART;
}
}六、现代时钟系统的演进:从tick到tickless
1. 传统周期性时钟的问题
c
// 固定频率tick(如1000Hz = 每1ms中断一次)
void tick_handle_periodic(struct clock_event_device *dev)
{
// 即使CPU空闲,也每1ms被中断一次
if (idle_cpu(cpu)) {
// 浪费电力:唤醒CPU→处理中断→返回休眠
return;
}
// ...正常处理
}2. NOHZ(动态时钟)技术
c
// 当CPU进入空闲时:
void tick_nohz_idle_enter(void) {
// 停止周期性时钟中断!
clockevents_switch_state(dev, CLOCK_EVT_STATE_ONESHOT);
// 设置下一个唤醒时间(如最近定时器到期)
next_timer = get_next_timer_interrupt();
clockevents_program_event(dev, next_timer, true);
}
// 有任务需要CPU时:
void tick_nohz_idle_exit(void) {
// 恢复周期性tick
clockevents_switch_state(dev, CLOCK_EVT_STATE_PERIODIC);
}节能效果 :现代服务器可减少60-80% 的时钟中断,显著降低功耗。
七、时钟系统的重要性:真实世界案例
1. 金融交易系统
c
// 高频交易需要微秒级精度
ktime_t start = ktime_get_ns();
execute_trade();
ktime_t latency = ktime_get_ns() - start;
// 必须<50微秒,否则失去竞争优势2. 多媒体同步
c
// 视频帧同步:每16.67ms显示一帧(60fps)
ktime_t next_frame = ktime_add_ns(last_frame, 16666666);
hrtimer_sleeper_init(&sleeper, next_frame, HRTIMER_MODE_ABS);
schedule_hrtimeout(&sleeper); // 精确睡眠到下一帧3. 网络协议栈
c
// TCP重传定时器
struct tcp_sock *tp = tcp_sk(sk);
hrtimer_start(&tp->retransmit_timer,
timeout, HRTIMER_MODE_ABS_REALTIME);总结:时钟系统 = 操作系统的心跳 + 生物钟
- 时钟中断 是心脏的跳动(提供基础节律)
- 时钟系统 是完整的循环系统(输送时间到每个角落)
关键洞察:
- 硬件多样性:TSC/HPET/PIT等提供不同精度/功耗的时钟源
- 软件层次性:从jiffies到ktime的多粒度时间管理
- 功耗敏感性:NOHZ技术让时钟系统"该静则静,该动则动"
- 全栈覆盖:服务于从内核调度到用户应用的各个层面
内核栈,用户栈、内核空间、用户空间
我们抛开物理内存的细节,专注于虚拟地址空间(Virtual Address Space, VAS)的视角,来清晰定义和理解这些核心概念。
核心概念:虚拟地址空间 (VAS)
每个进程都拥有一个独立的、连续的虚拟地址空间 。这个空间是CPU通过页表(Page Table) 映射到物理内存的。操作系统将这个庞大的虚拟空间划分为不同的区域,服务于不同的目的。
一、用户空间 (User Space)
-
定义:
进程虚拟地址空间中专供进程自身代码和数据使用的区域。进程在用户态(Ring 3)下只能访问这部分空间。
-
典型布局 (x86-64 Linux):
plaintext0x0000000000000000 - 0x00007FFFFFFFFFFF (128TB) ├── Text Segment : 程序代码(只读) ├── Data Segment : 全局变量(初始化/未初始化) ├── Heap : 动态内存(malloc/new) ├── ... : 共享库(动态库)映射区 └── Stack : 用户栈(向下增长) -
关键特性:
- 进程私有性:每个进程有自己的用户空间映射(即使代码相同,变量地址也不同)。
- 访问权限:用户态代码可读写(部分区域只读如代码段)。
- 隔离性:进程A无法直接访问进程B的用户空间(页表隔离)。
二、内核空间 (Kernel Space)
-
定义:
虚拟地址空间中保留给操作系统内核使用 的区域。所有进程共享同一份内核空间映射。
-
典型布局 (x86-64 Linux):
plaintext0xFFFF800000000000 - 0xFFFFFFFFFFFFFFFF (128TB) ├── Direct Mapping : 物理内存1:1映射(用于快速访问) ├── VMALLOC Area : 虚拟连续但物理不连续的内存 ├── Kernel Code : 内核代码段(text, data) ├── Kernel Stack : 每个进程的内核栈(独立) └── Page Tables : 进程页表存储区 -
关键特性:
- 全局共享:所有进程看到的内核空间内容相同(映射到同一物理内存)。
- 特权访问 :仅在内核态(Ring 0) 可访问。
- 固定映射:内核启动时初始化,不随进程切换改变。
为什么共享?
进程切换时,内核代码(如调度器)必须随时可用。若每个进程映射不同内核副本,切换时需重载整个内核空间------效率极低!
三、用户栈 (User Stack)
-
定义:
位于用户空间 的栈结构,用于支持进程用户态下的函数调用。
-
位置:
用户空间顶部(高地址向低地址增长),如
0x7ffeefbff000。 -
存储内容:
- 函数返回地址
- 局部变量
- 函数参数
- 临时寄存器值
-
操作指令:
assembly; 用户栈操作示例 push rax ; 栈顶下移8字节,写入rax pop rbx ; 从栈顶读取到rbx,栈顶上移8字节 -
特性:
- 进程私有:每个进程有自己的用户栈。
- 自动管理:编译器生成代码维护栈指针(RSP)。
- 溢出风险 :无限递归或大局部变量导致
Stack Overflow。
四、内核栈 (Kernel Stack)
-
定义:
位于内核空间 的栈结构,专用于进程陷入内核态时的临时操作。
-
位置:
内核空间中的独立区域(通常8KB~16KB),如
0xFFFFA000C1A00000。 -
存储内容:
- 中断/系统调用时的用户态上下文(RIP, RSP, RFLAGS...)
- 内核函数调用的返回地址和局部变量
- 临时保存的寄存器值
- 当前进程的
thread_info结构(含指向task_struct的指针)
-
关键特性:
- 进程绑定 :每个进程有独立的内核栈(切换进程时自动切换内核栈)。
- 内核专用:用户态代码无法直接访问。
- 小且安全 :固定大小(如16KB),溢出会触发内核Oops(安全防护)。
五、虚拟地址空间中的体现
1. 用户空间 vs 内核空间
plaintext
进程A的VAS:
0x0000...0000 ┌───────────────────────┐
│ User Space │ ← 进程A的代码、堆、栈
0x7FF...FFFF ├───────────────────────┤
│ │
│ GUARD │ ← 不可访问的隔离带
│ │
0xFFFF...0000 ├───────────────────────┤
│ Kernel Space │ ← 所有进程共享同一映射!
0xFFFF...FFFF └───────────────────────┘2. 用户栈 vs 内核栈
plaintext
进程A的用户空间:
0x7FFE...0000 ┌───────────────────────┐
│ Heap │ ← 动态分配区(向上增长)
├───────────────────────┤
│ ... │
├───────────────────────┤
│ Stack │ ← 用户栈(向下增长)
0x7FFE...FFF0 └───────────────────────┘
进程A的内核空间:
0xFFFFA000... ┌───────────────────────┐
│ Kernel Stack (A) │ ← 进程A专用内核栈
├───────────────────────┤
│ Kernel Stack (B) │ ← 进程B的内核栈(物理隔离)
├───────────────────────┤
│ Kernel Code │ ← 所有进程共享的代码
0xFFFFFFFF... └───────────────────────┘六、执行流中的切换:一次系统调用之旅
用户代码 CPU寄存器 内核栈 用户栈 调用函数foo() → push参数 执行write系统调用 自动保存用户态上下文 (RIP,CS,RFLAGS,RSP,...) 切换RSP指向内核栈 push内核函数局部变量 sys_write()执行中... 函数返回 → pop返回地址 恢复用户栈指针RSP 恢复用户寄存器 返回用户态继续执行 用户代码 CPU寄存器 内核栈 用户栈
关键点:
- 栈指针切换 :
syscall指令自动将RSP从用户栈切换到内核栈。 - 上下文保存 :CPU硬件将关键寄存器压入当前进程的内核栈。
- 内核栈隔离:即使进程A和B同时执行系统调用,各自的内核栈互不干扰。
- 返回复原 :
iretq指令从内核栈弹出上下文,切回用户栈。
总结:核心概念对比表
| 概念 | 所在空间 | 特权要求 | 进程间关系 | 主要用途 |
|---|---|---|---|---|
| 用户空间 | 用户VAS区域 | Ring 3 | 每个进程独立 | 存储进程私有代码、数据、堆 |
| 内核空间 | 内核VAS区域 | Ring 0 | 所有进程共享映射 | 存储内核代码、数据结构、设备映射 |
| 用户栈 | 用户空间内 | Ring 3 | 每个进程独立 | 支持用户态函数调用 |
| 内核栈 | 内核空间内 | Ring 0 | 每个进程独立实例 | 支持内核态执行时的临时操作 |
最终理解:
用户空间是进程的"私人公寓",内核空间是物业(操作系统)的"管理办公室"。用户栈是公寓里的记事本,记录私人事务;内核栈是物业人员上门服务时带的"临时工作板",每次服务(系统调用/中断)都带一块新板子,记完就走,绝不留下痕迹。物业办公室(内核空间)在同一栋楼里,但只有物业人员(CPU在内核态)有钥匙进入。
调度器:操作系统的进程指挥家
调度器(Scheduler)是操作系统内核的核心组件,负责在多个进程/线程间分配CPU时间,决定哪个任务在何时运行。它如同乐队的指挥,协调各个"演奏者"(进程)有序使用有限的"乐器"(CPU资源)。
一、调度器的核心作用
| 作用 | 说明 |
|---|---|
| 公平性 | 确保每个进程公平获得CPU时间(如CFS调度器的虚拟时间机制) |
| 响应速度 | 快速响应交互式任务(如键盘输入) |
| 吞吐量 | 最大化CPU利用率(科学计算任务) |
| 实时性 | 满足截止时间要求(无人机控制系统) |
| 优先级管理 | 执行nice值设定的优先级策略 |
| 多核负载均衡 | 在CPU核心间迁移任务避免热点 |
二、调度器本质:内核中的决策算法
调度器是操作系统内核的一部分代码,主要存在于:
c
// Linux内核调度器核心位置
kernel/sched/
├── core.c // 通用调度逻辑
├── fair.c // CFS完全公平调度器
├── rt.c // 实时调度器
└── deadline.c // 截止时间调度器它不是:
- 独立的硬件模块
- 用户空间程序
- 可卸载的驱动
三、调度器工作原理:状态机与决策循环
1. 进程状态转换
Ready: 创建进程 Ready Running: 被调度器选中 Running 时间片用完 Blocked: 等待I/O Blocked I/O完成 : 进程退出
2. 调度触发时机
| 触发场景 | 具体原因 |
|---|---|
| 主动让出 | 进程调用sleep()或等待锁 |
| 时间片耗尽 | 时钟中断发现进程时间片用完 |
| 高优先级进程就绪 | 等待硬盘数据的VIP进程恢复就绪 |
| 中断唤醒 | 网卡数据到达唤醒阻塞的socket进程 |
3. 核心决策流程
c
// 简化版调度流程
void schedule(void) {
// 1. 关闭抢占
preempt_disable();
// 2. 选择下一个进程
next = pick_next_task(rq); // 关键算法!
// 3. 执行上下文切换
if (next != current) {
context_switch(rq, current, next);
}
// 4. 重新启用抢占
preempt_enable();
}四、调度算法实例:Linux CFS(完全公平调度器)
1. 设计哲学
-
虚拟时间(vruntime) :记录进程已运行时间,经优先级加权
cvruntime = 实际运行时间 * NICE_0_LOAD / 进程权重 -
红黑树排序:所有可运行进程按vruntime排序,选择vruntime最小的进程
2. 工作流程
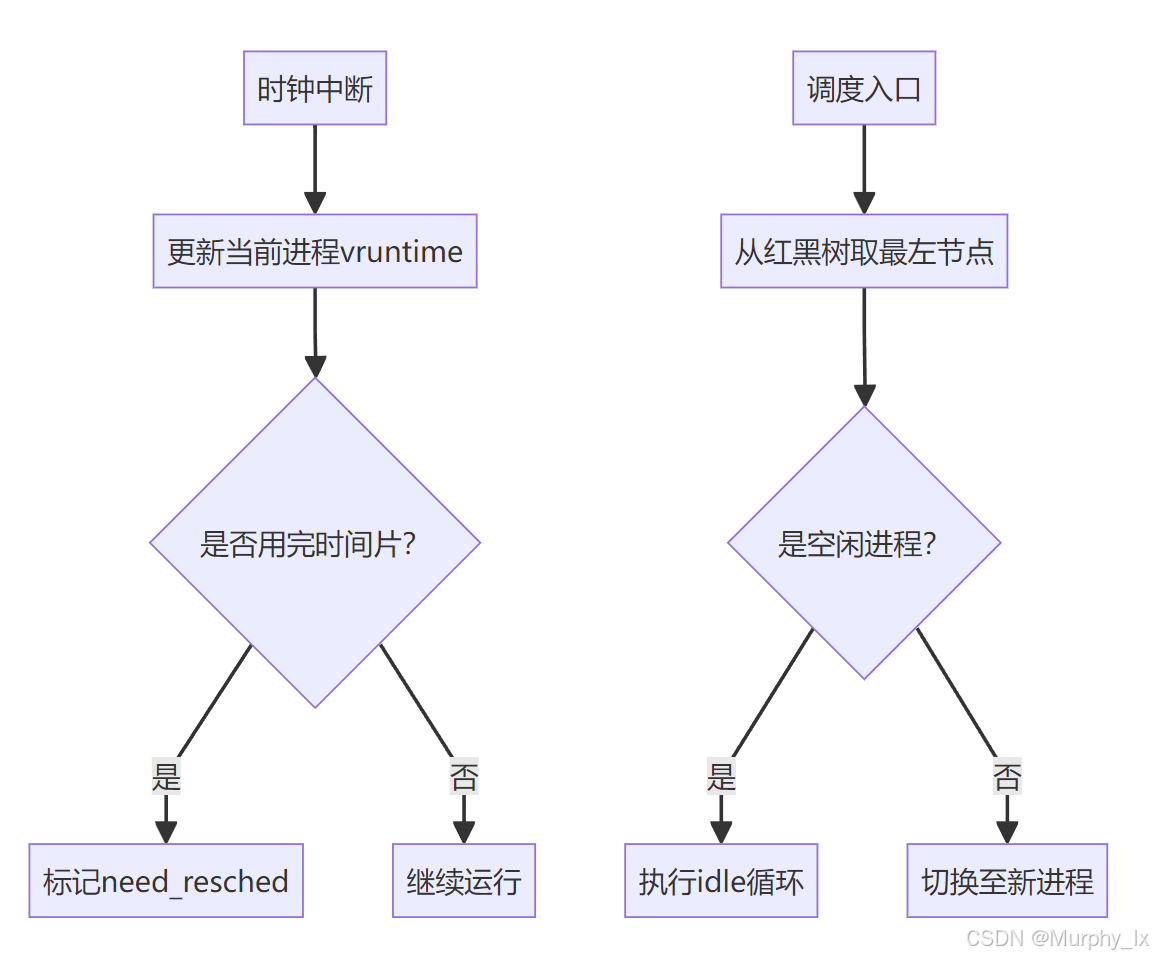
3. 动态优先级示例
c
// 动态调整优先级(交互式进程提升)
if (进程等待时间 > 阈值) {
vruntime -= 补偿值; // 使进程更快被调度
}五、多核调度:负载均衡的艺术
1. 调度域(Scheduling Domains)
plaintext
Socket 0 Socket 1
├── Core 0 (CPU0, CPU1) ├── Core 2 (CPU4, CPU5)
└── Core 1 (CPU2, CPU3) └── Core 3 (CPU6, CPU7)2. 负载均衡策略
| 策略 | 触发条件 | 操作 |
|---|---|---|
| Pull迁移 | 当前CPU队列空闲 | 从忙CPU"偷"任务 |
| Push迁移 | 某个CPU负载超过阈值 | 将任务推给空闲CPU |
| 周期性均衡 | 每1ms检查一次 | 调整跨核心任务分布 |
六、调度器在系统调用中的体现
当进程执行read()系统调用时:
用户进程 内核 调度器 硬盘驱动 read(fd, buf, size) 发起磁盘I/O请求 标记进程为TASK_UNINTERRUPTIBLE 从运行队列移除进程 选择新进程运行 I/O完成中断 唤醒进程并加入就绪队列 下次调度时恢复执行 用户进程 内核 调度器 硬盘驱动
七、调度器本质的终极诠释
调度器是操作系统的决策引擎,通过三个维度实现控制:
- 空间维度 :通过
task_struct管理进程元数据 - 时间维度:通过时钟中断驱动调度周期
- 算法维度:通过公平/实时等策略平衡系统目标
如同城市交通控制系统:
- 红绿灯 = 时钟中断
- 交通规则 = 调度策略(CFS/RT)
- 交警 = 调度器代码
- 车辆 = 进程
- 道路 = CPU核心
可重入函数
我们来简单了解一下可重入函数(Reentrant Function) 这个概念。这是编写健壮的多线程程序、信号处理程序以及操作系统内核代码的关键基石。
一、什么是可重入函数?
定义:
一个函数在被未执行完前再次被调用 (无论同一线程还是不同线程),且能正确执行 而不产生副作用或数据损坏,则该函数是可重入的。
核心特征:
- 无状态依赖:不依赖静态变量、全局变量等共享状态
- 仅用局部数据:所有数据来自参数或栈上局部变量
- 不调用非可重入函数:避免调用链污染
二、为什么需要可重入函数?
典型场景
| 场景 | 风险案例 |
|---|---|
| 信号处理函数 | 主程序执行malloc()时被信号中断,处理函数也调用malloc()→ 堆管理数据损坏 |
| 多线程并发 | 线程A和B同时调用strtok()解析字符串 → 解析结果错乱 |
| 递归调用 | 递归函数修改全局计数器 → 递归层间数据污染 |
| 操作系统中断 | 进程执行库函数时被中断,ISR调用相同函数 → 硬件状态冲突 |
不可重入的灾难性后果
c
// 危险的非可重入函数示例
char *strtok(char *str, const char *delim) {
static char *last; // 静态变量!多调用共享状态
if (str) last = str;
// ...解析逻辑依赖last
}若线程A解析"hello.world"时被中断,线程B调用strtok(NULL, ".")解析"foo.bar",将导致:
- 线程A的
last指针被篡改 - 返回结果变为"bar"而非预期"world"
- 数据彻底错乱且难调试
三、可重入函数的原理:状态隔离
1. 关键设计原则
输入参数 可重入函数 局部变量 输出结果
- 无共享状态 :函数像数学函数
f(x) = y,输出仅依赖输入 - 执行原子性:单次调用不遗留任何"中间状态"
- 资源独占:若需访问外部资源(如文件),由调用者通过参数传递句柄
2. 与线程安全函数的区别
| 特性 | 可重入函数 | 线程安全函数 |
|---|---|---|
| 重入安全性 | ✅ 支持任意嵌套/并发调用 | ⚠️ 仅保证多线程调用不崩溃 |
| 状态管理 | 完全无状态 | 可能用锁保护共享状态 |
| 性能 | 无锁开销 | 可能有锁竞争开销 |
| 典型实现 | strtok_r() |
malloc()(带全局锁) |
关键洞察:所有可重入函数都是线程安全的,但线程安全函数未必可重入!
四、可重入函数的工作流程
场景:信号处理函数中使用可重入函数
主程序 信号处理函数 可重入库函数 调用非可重入函数func_A() 修改全局变量X 信号到达!中断主程序 调用可重入函数func_B() 仅使用局部变量和参数 安全返回 信号处理完成 继续执行func_A() 全局变量X未被破坏 主程序 信号处理函数 可重入库函数
关键步骤解析
- 主程序陷入风险区 :主程序调用非可重入函数
func_A(),该函数修改了全局变量X - 信号中断:时钟中断触发信号处理
- 处理函数避险 :信号处理函数调用可重入 的
func_B(),该函数:- 不读取/修改全局变量
X - 不使用静态缓冲区
- 所有计算在栈上完成
- 不读取/修改全局变量
- 安全返回:全局状态未被污染,主程序继续执行无副作用
五、如何编写可重入函数:实战法则
1. 禁用以下元素
c
// 禁止清单
static int counter; // 静态变量
extern FILE *logfile; // 全局变量
malloc(1024); // 堆内存分配(非线程安全版本)
printf(); // 标准I/O(内部用全局锁)2. 推荐模式
c
// 可重入函数模板
int reentrant_func(int param1, char *output_buf, size_t buf_size) {
// 规则1:所有变量在栈上
int local_var = param1 * 2;
// 规则2:输出通过参数传递缓冲区
if (buf_size > 0) {
snprintf(output_buf, buf_size, "Result: %d", local_var);
}
// 规则3:只调用已知可重入函数
int fd = open("/tmp/file", O_RDONLY); // 文件操作需谨慎!
return local_var;
}3. POSIX标准中的可重入函数
| 不可重入函数 | 可重入替代版本 | 改进点 |
|---|---|---|
strtok() |
strtok_r() |
用参数传递状态指针 |
gmtime() |
gmtime_r() |
输出存放到调用者提供的结构体 |
getpwnam() |
getpwnam_r() |
避免静态存储密码条目 |
rand() |
rand_r() |
种子状态由调用者管理 |
六、深入原理:编译器与硬件的支持
1. 编译器的角色
-
局部变量优化:编译器确保局部变量仅存在于栈帧或寄存器中
assembly; x86汇编示例 reentrant_func: push rbp mov rbp, rsp sub rsp, 16 ; 在栈上分配局部变量空间 mov [rbp-4], edi ; 参数存入局部变量 ... ; 无全局内存访问 -
纯函数(Pure Function)标记 :GCC的
__attribute__((const))声明函数无副作用,可做激进优化
2. 硬件机制保障
-
独立的栈空间:每个线程/中断上下文有私有栈
- 函数局部变量存储在线程栈中 → 天然隔离
-
寄存器存储:临时值存于寄存器(如x86的RAX/RDI等)
assembly; 函数调用间寄存器使用 call func_A ; func_A使用RAX作临时寄存器 call func_B ; func_B复用RAX → 但func_B可重入设计保证不冲突
七、经典案例剖析:strtok()vs strtok_r()
1. 非可重入实现(危险!)
c
char *strtok(char *str, const char *delim) {
static char *last; // 静态变量存储状态
if (str) last = str; // 首次调用初始化
char *end = find_delim(last, delim);
if (!end) return NULL;
*end = '\0';
char *ret = last;
last = end + 1;
return ret;
}问题 :多线程调用时last被竞争修改。
2. 可重入实现(安全)
c
char *strtok_r(char *str, const char *delim, char **saveptr) {
char *end;
if (str) *saveptr = str; // 状态通过参数传递
end = find_delim(*saveptr, delim);
if (!end) return NULL;
*end = '\0';
char *ret = *saveptr;
*saveptr = end + 1;
return ret;
}用法:
c
char str[] = "hello;world";
char *state;
char *token1 = strtok_r(str, ";", &state); // "hello"
char *token2 = strtok_r(NULL, ";", &state); // "world"关键改进 :调用者通过
state参数维护状态,实现完全隔离。
总结:可重入性的本质
可重入函数是函数式编程思想在命令式语言中的实践:
- 无状态性 ≈ 纯函数(Pure Function)
- 局部变量 ≈ 闭包环境隔离
- 参数传递 ≈ 显式状态管理
在以下场景必须使用可重入函数:
- 信号处理程序(Signal Handler)
- 实时操作系统(RTOS)任务
- 高性能并发库(如无锁数据结构)
- 递归算法实现
记住黄金法则:
"当你听到中断铃声(信号/中断)时,放下手中的全局数据,只处理局部事务。"
这便是可重入函数的设计哲学------在不可预测的并发世界中,保持每个执行流的自包含性和安全性。
volatile关键字
我们来简单了解一下 volatile关键字------这个在嵌入式开发、驱动编程和多线程中至关重要的修饰符。它看似简单,实则微妙,是程序员与编译器、硬件之间的一份"特殊协议"。
一、volatile是什么?
定义:
volatile是 C/C++ 中的类型修饰符,用于声明一个变量的值可能在程序控制之外被意外修改。它告诉编译器和硬件:
"不要对这个变量做任何假设,每次访问都必须老老实实读/写内存!"
二、为什么需要 volatile?------ 消失的变量之谜
场景1:硬件寄存器映射
c
// 假设0x1000是温度传感器的寄存器地址
uint32_t *temp_reg = (uint32_t*)0x1000;
void read_temp() {
while (*temp_reg == 0) {
// 等待传感器就绪
}
uint32_t temp = *temp_reg; // 读取温度值
}问题:
编译器发现循环内 *temp_reg未被修改,将其优化为:
assembly
read_temp:
mov eax, [0x1000] ; 只读一次寄存器
loop:
test eax, eax ; 检查初始值
jz loop ; 死循环!永远等不到变化结果: 程序卡在死循环,因为硬件寄存器的变化被忽略!
场景2:信号处理函数
c
int flag = 0;
void handler(int sig) {
flag = 1; // 信号处理中修改
}
int main() {
signal(SIGINT, handler);
while (flag == 0) { } // 等待信号
printf("Signal received!\n");
}问题:
编译器将 while (flag == 0)优化为:
assembly
cmp [flag], 0
jz .loop但若 flag在内存中变为1,CPU缓存中仍是0 → 看不到变化!
三、volatile的救赎:禁用优化的指令
解决方案:
c
volatile uint32_t *temp_reg = (volatile uint32_t*)0x1000; // 场景1
volatile int flag = 0; // 场景2编译器行为变化:
| 操作 | 普通变量 | volatile变量 |
|---|---|---|
| 读取 | 可能用寄存器缓存值 | 每次从内存重新加载 |
| 写入 | 可能延迟或合并写入 | 立即写入内存 |
| 优化假设 | 认为程序是唯一修改者 | 承认外部可能修改 |
四、底层原理:内存可见性与顺序性
1. 编译器屏障
volatile在编译层面禁止以下优化:
c
// 优化前代码
int a = *ptr;
... // 无修改ptr的代码
int b = *ptr; // 被优化为 b = a
// volatile版本
volatile int *ptr;
int a = *ptr;
int b = *ptr; // 必须生成两条加载指令!2. 硬件层面的影响
-
缓存一致性:现代CPU(如x86)通常自动维护缓存一致性,但嵌入式设备(如ARM)可能需要额外指令:
assembly; ARM汇编读取volatile变量 ldr r0, [r1] ; 强制从内存地址r1加载,绕过缓存 -
内存映射I/O :对
volatile指针的访问直接生成设备读写指令:assembly; x86访问硬件寄存器 mov eax, [0x1000] ; 不是普通内存读,而是总线操作!
五、工作流程:从代码到硬件
程序代码 编译器 CPU执行 内存/硬件 volatile int* p = ... 禁用所有优化假设 生成直接内存访问指令 执行LOAD/STORE指令 返回最新值(可能来自其他硬件) loop 每次访问 程序代码 编译器 CPU执行 内存/硬件
六、volatile的正确使用场景
必须使用场景:
| 场景 | 示例 |
|---|---|
| 内存映射硬件寄存器 | volatile uint32_t *reg = 0xFFFF0000; |
| 信号处理共享变量 | volatile sig_atomic_t flag; |
| 多线程共享变量 | (注意:需配合原子操作或锁) |
| 禁止优化的延时循环 | volatile int i; for(i=0; i<10000; i++); |
常见误用:
c
// 错误1:以为volatile能替代锁
volatile int balance = 1000;
void withdraw(int amount) {
balance -= amount; // 非原子操作!可能被中断打断
}
// 错误2:以为volatile保证执行顺序
volatile int a = 1;
volatile int b = 2;
a = 3;
b = 4; // 编译器仍可能重排指令顺序!关键警示 :
volatile不提供原子性 ,不阻止指令重排 (需内存屏障),不解决多线程竞争(需锁或原子变量)。
七、与 atomic和内存屏障的对比
| 特性 | volatile |
std::atomic(C++11) |
内存屏障 |
|---|---|---|---|
| 编译器优化 | 禁用缓存优化 | 禁用缓存优化 | 依赖编译器实现 |
| 原子性 | ❌ 不保证 | ✅ 保证 | 需配合原子指令 |
| 顺序一致性 | ❌ 不保证 | ✅ 可指定内存序 | ✅ 强制排序 |
| 适用场景 | 硬件寄存器 | 多线程共享变量 | 高性能并发控制 |
联合使用示例:
c
// 多线程安全标志位
std::atomic<bool> ready(false);
// 硬件事件等待
volatile uint32_t *status_reg = (volatile uint32_t*)0x1000;
while (!ready.load(std::memory_order_acquire)) {
// 防止空循环被优化掉
asm volatile("" ::: "memory"); // 编译器屏障
}八、深入理解:volatile的语义边界
C/C++ 标准中的定义
-
C99标准(6.7.3):
"访问
volatile对象的行为是严格按照实现定义的抽象机的规则执行的。"即:每次访问都对应一个可观测的副作用(Observable Side Effect)。
与 const的联合使用
c
// 只读的硬件寄存器
volatile const uint32_t *ro_reg = (volatile const uint32_t*)0x1000;
uint32_t value = *ro_reg; // 允许读取
*ro_reg = 0; // 编译错误!const禁止写入总结:volatile的本质
-
它是编译器指令:
"别优化,每次都要真实访问内存!"
-
它是硬件契约:
"这个地址可能被外部修改,别用缓存糊弄我!"
-
它不是万金油:
- ❌ 不能替代锁或原子操作
- ❌ 不能阻止CPU指令重排
- ❌ 不能自动解决并发问题
黄金使用法则:
当你需要与硬件、信号处理、或其他独立执行环境 共享数据时,才使用
volatile。在多线程编程 中,优先使用
std::atomic或锁。