LLMs之RAG之Benchmark:面向真实场景的检索嵌入基准(RTEB)---理论、设计与实践指南
导读: 本文整体呈现了 RTEB 作为一项面向检索嵌入模型的新标准基准的全貌。从"为什么需要新基准"出发,指出了现有评测的缺陷;又在"推出 RTEB"中说明了设计目标;通过"混合策略"展示了其核心方法创新;"面向真实世界领域构建"强调了其覆盖的语言与领域广度;"社区协作"体现了开放发展路径;最后"局限与未来"则展现了自我反思与演进方向。
总体来看,RTEB 的价值在于:
>> 提升检索模型评估的泛化真实性,而非仅靠已知测试集得分;
>> 更贴近企业/应用场景、涵盖多语言多领域,在真实检索任务中具备参考意义;
>> 利用公开+私有数据集合策略,平衡可复现性与泛化检测;
>> 鼓励社区共建,使基准具备长期演进与成长空间。
但也须注意:当前版本仍限定于文本检索、语言覆盖尚未完整、部分数据来源可能偏向 QA 改造,开发者需根据自身业务场景做补充评估。
对于模型开发者和检索系统建设者来说,RTEB 不仅是一个新的评测工具,更是检索模型设计与评估思路的"风向标":强调真正的泛化能力、强调场景贴合、强调语言与领域的多样性。未来若想在检索系统上取得稳健、可靠表现,推荐将 RTEB 作为一个重要参考,同时结合业务专用数据进行验证。
目录
面向真实场景的检索嵌入基准(RTEB)---理论、设计与实践指南
[1. 为什么现有基准测试存在不足](#1. 为什么现有基准测试存在不足)
[2. RTEB的简介](#2. RTEB的简介)
[3. 真正泛化的混合策略(A Hybrid Strategy for True Generalization)](#3. 真正泛化的混合策略(A Hybrid Strategy for True Generalization))
[4. 面向真实世界领域构建(Built for Real-World Domains)](#4. 面向真实世界领域构建(Built for Real-World Domains))
[5. 启动 RTEB:社区协作(Launching RTEB: A Community Effort)](#5. 启动 RTEB:社区协作(Launching RTEB: A Community Effort))
[6. 局限性与未来工作(Limitations and Future Work)](#6. 局限性与未来工作(Limitations and Future Work))
面向真实场景的检索嵌入基准 ( RTEB )--- 理论、设计与实践指南
|------------|---------------------------------------------------------------------------------------------------------|
| 地址 | https://huggingface.co/blog/rteb |
| 时间 | 2025年10月1日 |
| 作者 | Hugging Face |
1. 为什么现有基准测试存在不足
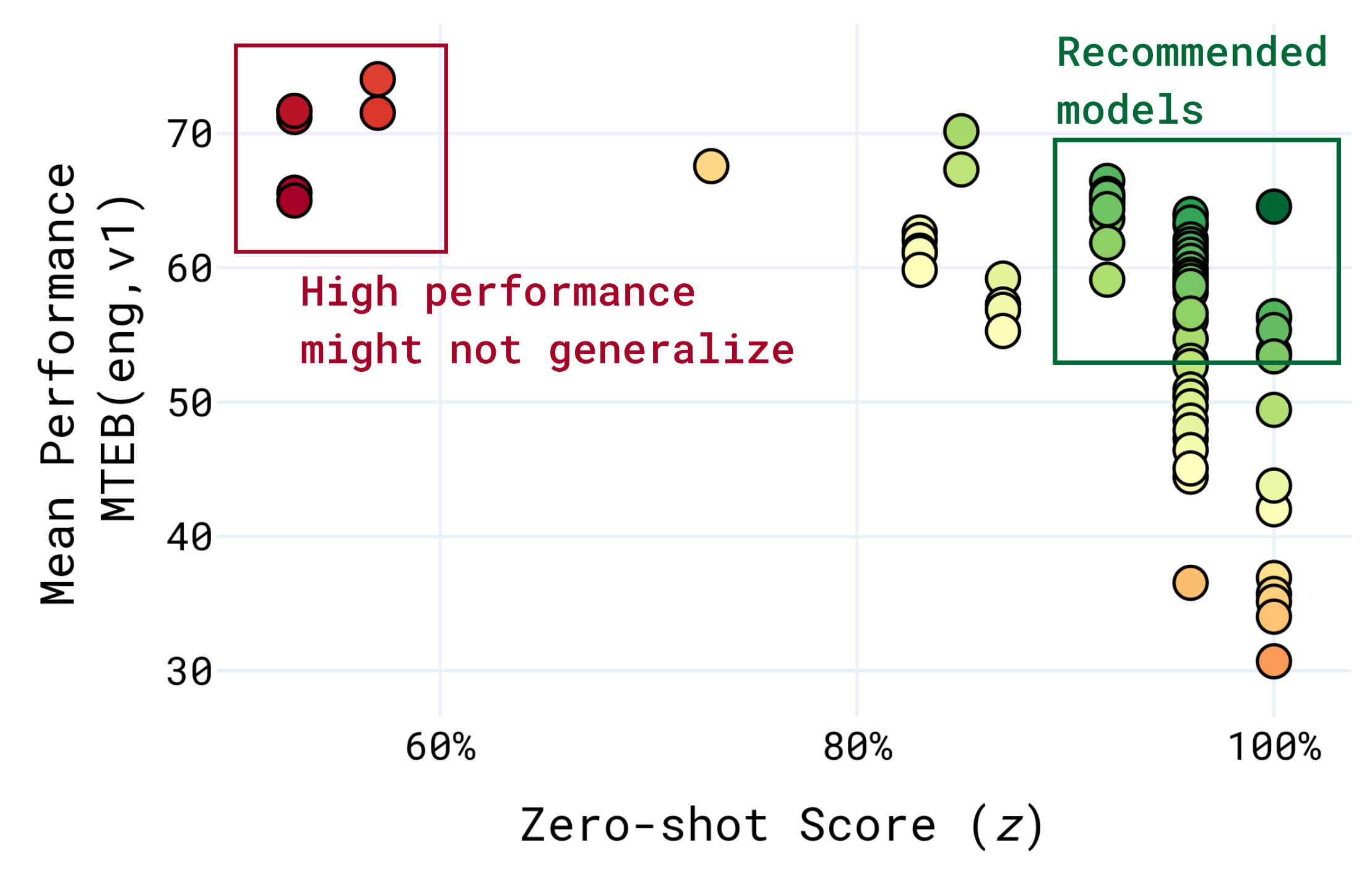
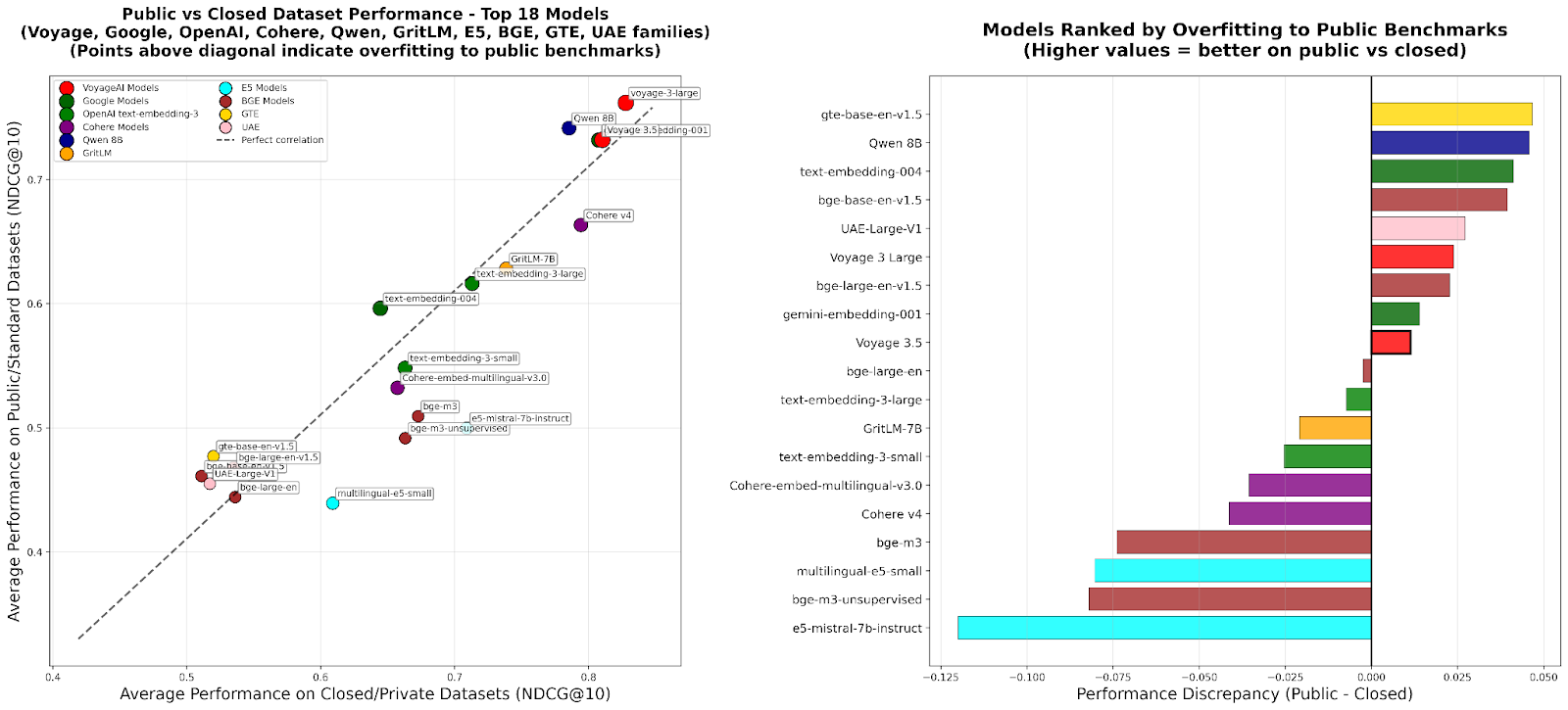
本节指出现有检索(retrieval)评估基准虽然在方法论上(如 NDCG@10 等)相对成熟,但在实际应用中仍存在两大关键问题:模型泛化能力不足,以及与现实企业/应用场景脱节。文章通过这两个角度阐述了现有基准测试的挑战。
核心要点
>> 泛化差距(Generalization Gap) :不少评测基准的数据源与训练、开发数据存在重叠,导致模型可能"学"到测试集特征,从而"教考"(teaching to the test)而非真正提升泛化能力。
>> 评价数据可靠性下降 :当训练数据与测试集有重叠时,模型在基准上得分可能很高,但在未见数据上表现差,说明基准的可靠性和代表性弱。
>> 与现实应用场景脱节 :许多基准来自学术环境或仅为 QA 任务改造的检索任务,缺乏对现实企业应用(如法律、金融、医疗、代码检索、多语言、多领域等)中的复杂性与分布偏差的覆盖。
>> 过于聚焦某单一领域 :少数基准虽然覆盖检索,但仅专注于某一领域(例如代码检索、英文单语)或简单场景,不利于评估通用检索模型在多领域、多语言场景下的表现。
经验/技巧
>> 在选择或设计检索评估基准时,优先考虑是否存在训练数据与测试数据的重叠,从而避免模型"投机"得分。
>> 当评估模型的真实部署能力时,不应只是看公开基准得分,更要考虑模型在未见、真实场景数据上的表现。
>> 企业级应用应优先关注与其业务对应的领域与语言覆盖,不宜仅依赖通用但脱离业务场景的基准。
>> 建议开发者保留模型在"公开标准数据"与"真实专用数据"上的评估对比,以检测是否存在"泛化下滑"现象。
2. RTEB 的简介
本节介绍 RTEB 的基本设计理念、目标定位和结构框架。RTEB 旨在成为一个新的、可靠的、高质量的检索嵌入模型评估基准,从而填补上述现有基准的不足。
核心要点
>> 目标定位 :评估嵌入模型(embedding models)在检索任务(retrieval)中的真实准确性,尤其在"未见数据"上的泛化能力。
>> 设计原则:公平、透明、聚焦应用。即公开数据让人可复现,私有数据用于检测泛化,下滑明显则提示模型过拟合。
>> 评估重点:不仅是学术任务,而是企业、现实场景中的检索,如 RAG(检索增强生成)、智能代理、推荐系统等。
经验/技巧
>> 若构建自己的检索模型评估流程,可以参考 RTEB 的"公开 + 私有"双轨评估策略。
>> 在基准评估之外,建议引入"部署后真实数据"反馈机制,以持续监控模型在生产环境中的检索质量。
>> 在公开基准得分优秀但私有/真实数据表现下滑时,须视为模型可能存在"过拟合公开数据"问题。
3. 真正泛化的混合策略(A Hybrid Strategy for True Generalization)
本节详细阐述 RTEB 采用的"混合策略":即利用一部分公开数据、另一部分保密私有数据,共同评估模型的泛化能力。该部分是 RTEB 的核心方法创新。
核心要点
>> 公开数据集(Open Datasets):语料库、查询、相关性标签全部公开,用户可复现测试流程。
>> 私有数据集(Private Datasets) :由 MTEB 维护方保管,评估由维护方执行,不向模型开发者公开,确保评估未见数据。
>> 检测泛化下滑:若模型在公开数据集上表现良好,但在私有数据集上显著下降,说明模型可能过拟合、泛化能力不足。
>> 社区可见性与透明度:虽然私有数据不可完全公开,但为保持透明性,RTEB 提供了描述统计、样本 (query, document, relevance) 三元对。
经验/技巧
>> 在实际评估中,建议将"公开基准得分"与"真实专用数据得分"并列展示,以识别得分差距。
>> 模型迭代时,若发现公开数据得分快速提升但专用数据得分无明显变化,可能说明在"教考"(teaching to the test)上投入过多。
>> 企业在选用嵌入检索模型时,建议考查其在私有/真实业务数据上的表现,而不单看公开benchmark得分。
>> 如果构建自己的评测体系,也可考虑类似"部分任务公开、部分任务内部保密"机制,以长期检测泛化趋势。
4. 面向真实世界领域构建(Built for Real-World Domains)
本节阐述 RTEB 在数据覆盖、应用领域、语言维度等方面所做的设计,以确保其更好契合真实场景应用。
核心要点
>> 多语言覆盖 :RTEB 涵盖约 20 种语言,从常见的英语、日语,到较少资源的孟加拉语、芬兰语等。
>> ****领域专用聚焦:****数据集涵盖法律(law)、医疗(healthcare)、金融(finance)、代码(code)等关键企业场景。
>> ****数据集规模控制:****每个数据集规模既要有意义(至少 1 k 文档、50 查询)又需避免评估时间过长、成本过高。
>> ****检索优先指标:****采用 NDCG@10 作为默认排行榜指标------这是评估排名型检索任务中常用的黄金标准。
>> ****数据集列表很丰富:****公开数据集与私有数据集均列出,说明 RTEB 的数据来源结构清晰。
经验/技巧
>> 在业务中采用检索模型时,应考虑它在实际 语言 和 领域 上的适配性:语言少、领域专业的数据往往更具挑战。
>> 模型选择时,不只是看"通用"的英文数据表现,也应关注"少资源语言"与"专用业务领域"上的能力。
>> 评估时采用 NDCG@10 等排名指标更贴合检索任务的真实表现,而不是只关注简单准确率或召回率。
>> 若构建数据集,建议在规模与成本间取得平衡:过大可能导致评估资源浪费,过小可能不具代表性。
5. 启动 RTEB:社区协作(Launching RTEB: A Community Effort)
本节强调 RTEB 启动为 beta 版本,并呼吁社区参与,包括反馈、数据集建议、问题报告等,从而推动基准的持续演进。
核心要点
>> RTEB 处在 Beta 阶段,开放给模型开发者用于提交评估。
>> 社区参与机会:开发者可以建议新的数据集、发现现有数据集的问题、通过 GitHub 提 issue。
>> 评价结果可在 Hugging Face 上 MTEB (新增 Retrieval 版块)排行榜中查看。
经验/技巧
>> 模型开发者应积极参与社区反馈,这不仅可以影响基准的发展,还能提升自身模型在未来基准上的表现。
>> 在提交模型评估时,应注意公开结果与私有数据集差异,这有助于发现模型弱点。
>> 利用 RTEB 的 beta 阶段,提前布局自身模型,使未来面对标准稳定时具有优势。
6. 局限性与未来工作(Limitations and Future Work)
本节诚实指出 RTEB 当前尚存一些限制,同时展望未来可能的发展方向。其目的是透明化基准的现状,并邀请社区参与补充完善。
核心要点
>> ****基准范围:****目前 RTEB 专注于"现实、检索优先"场景,尚未涵盖某些高度合成/挑战型数据集。
>> ****模态限制:****目前只评估文本-文本检索,不包括多模态(如文字-图像、图像-图像)检索任务。
>> ****语言覆盖仍待扩展:****尽管已覆盖 ~20 种语言,但仍有重要语言(如中文、阿拉伯语、更多低资源语言)缺失。
>> ****使用 QA 数据集改造的风险:****约 50% 的检索数据集是从 QA 任务改造而来,可能存在查询与上下文的高度词汇重叠,从而倾向于"关键词匹配"而非真正语义理解。
>> ****私有数据集公开受限:****为确保公正,私有数据集仅由维护方使用,不完全开放,这在某种程度限制了完全透明。
经验/技巧
>> 在使用 RTEB 得分时,应留意上述局限,不应将其得分视为"万能"指标。
若模型主要服务于多模态或汉语/阿语等低资源语言场景,当前 RTEB 的覆盖可能不足,应>> 同步构建或选用补充评估。
>> 从数据构建角度,建议未来检索数据集更少依赖 QA 改造,而更多来自真正检索场景,以减少"关键词匹配"偏差。
>> 在模型部署流程中,建议将 RTEB 评估与单位/业务专用评估结合起来,以覆盖基准尚未完全覆盖的维度。