一、项目背景
公司:百度、搜狗、360搜索、头条新闻客户端 - 我们自己实现是不可能的!
实现站内搜索:搜索的数据更垂直,数据量其实更小
二、搜索引擎相关宏观原理
用户通过客户端(例如浏览器,应用程序)上传搜索关键字,客户端以HTTP请求方式进行搜索任务。服务端主机根据关键字通过已经建立好的索引(如果是全网搜索,搜索引擎会定期向全网网站进行爬虫,建立和更新索引;对于站内搜索,则时可以在服务启动前就建立好索引)进行检索得到相关html,拼接多个网页的 title + desc + url,构建一个新的网页,返回给用户。
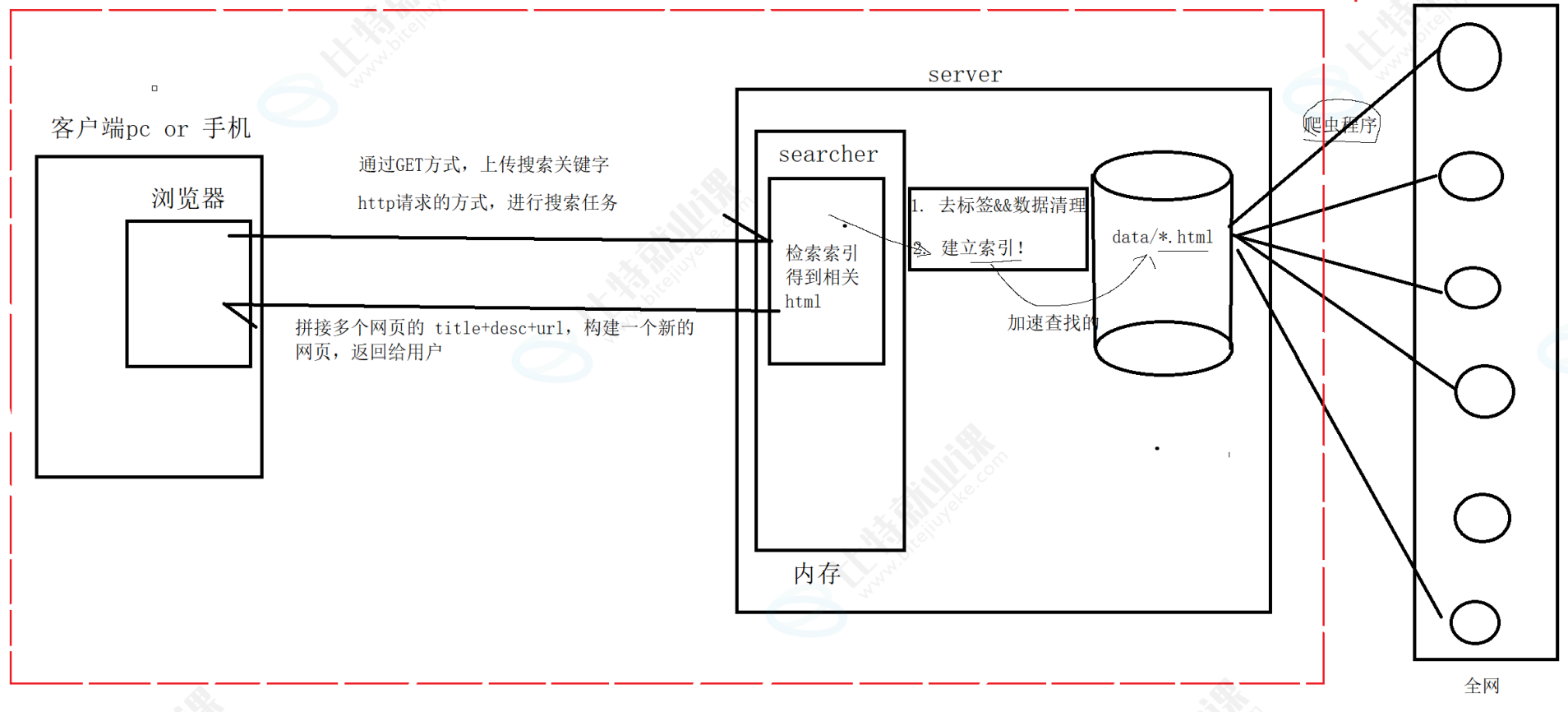
三、技术栈和项目环境
技术栈: C/C++ C++11, STL, 准标准库Boost,Jsoncpp,cppjieba,cpp-httplib ,
选学: html5,css,js、jQuery、Ajax项目环境: Centos 7云服务器,vim/gcc(g++)/Makefile , vs2019 or vs code
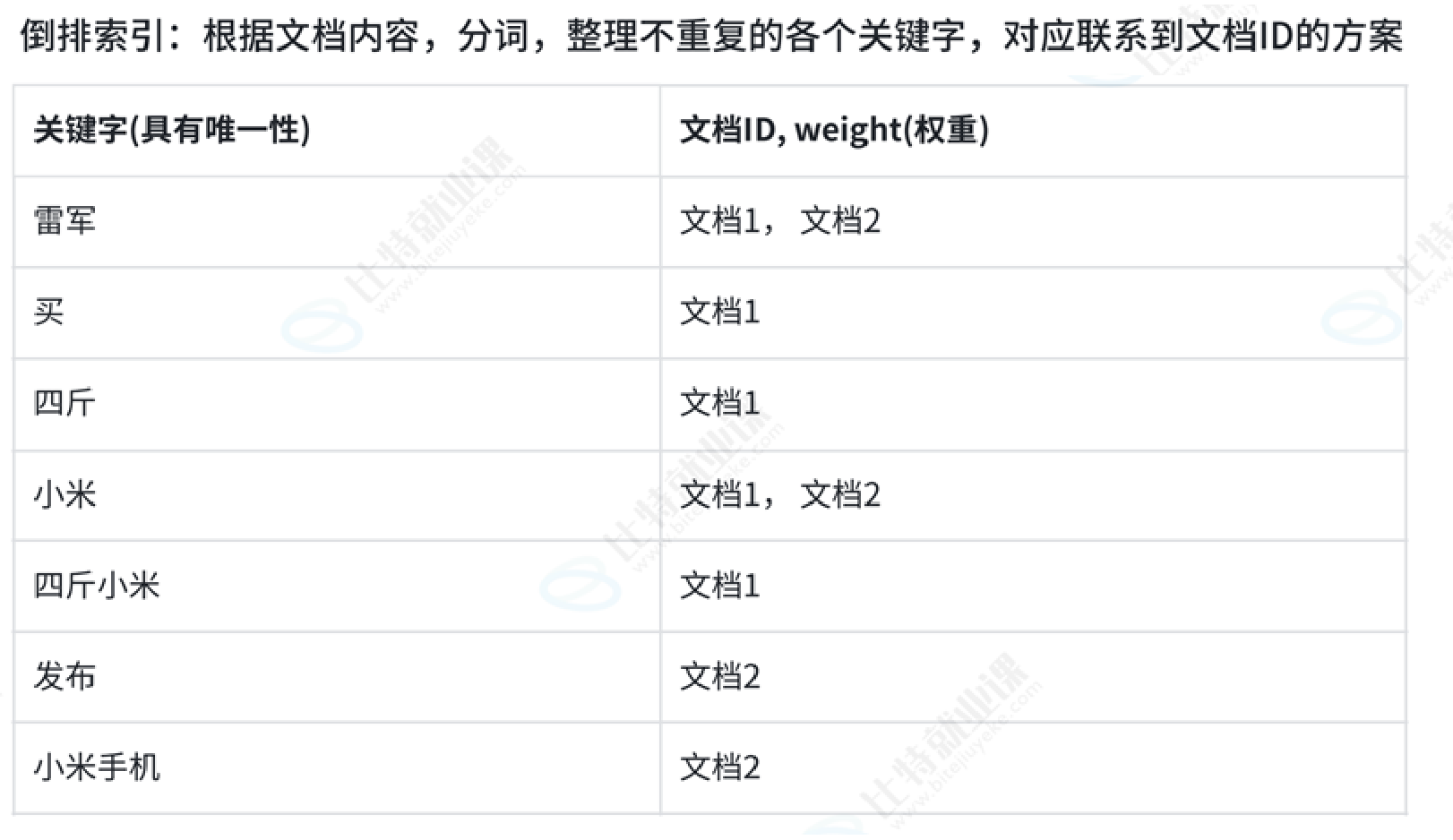
四、正排索引 和 倒排索引 - 搜索引擎具体原理
文档1: 雷军买了四斤小米
文档2: 雷军发布了小米手机正排索引:文档id 与 正文 映射关系
倒排索引:关键字 与 文档id,权重 映射关系
模拟一次查找的过程:
用户输入:小米 -> 倒排索引中查找 -> 提取出文档ID(1,2) -> 根据正排索引 -> 找到文档的内容 ->title+conent(desc)+url 文档结果进行摘要-> 构建响应结果

五、外部库使用
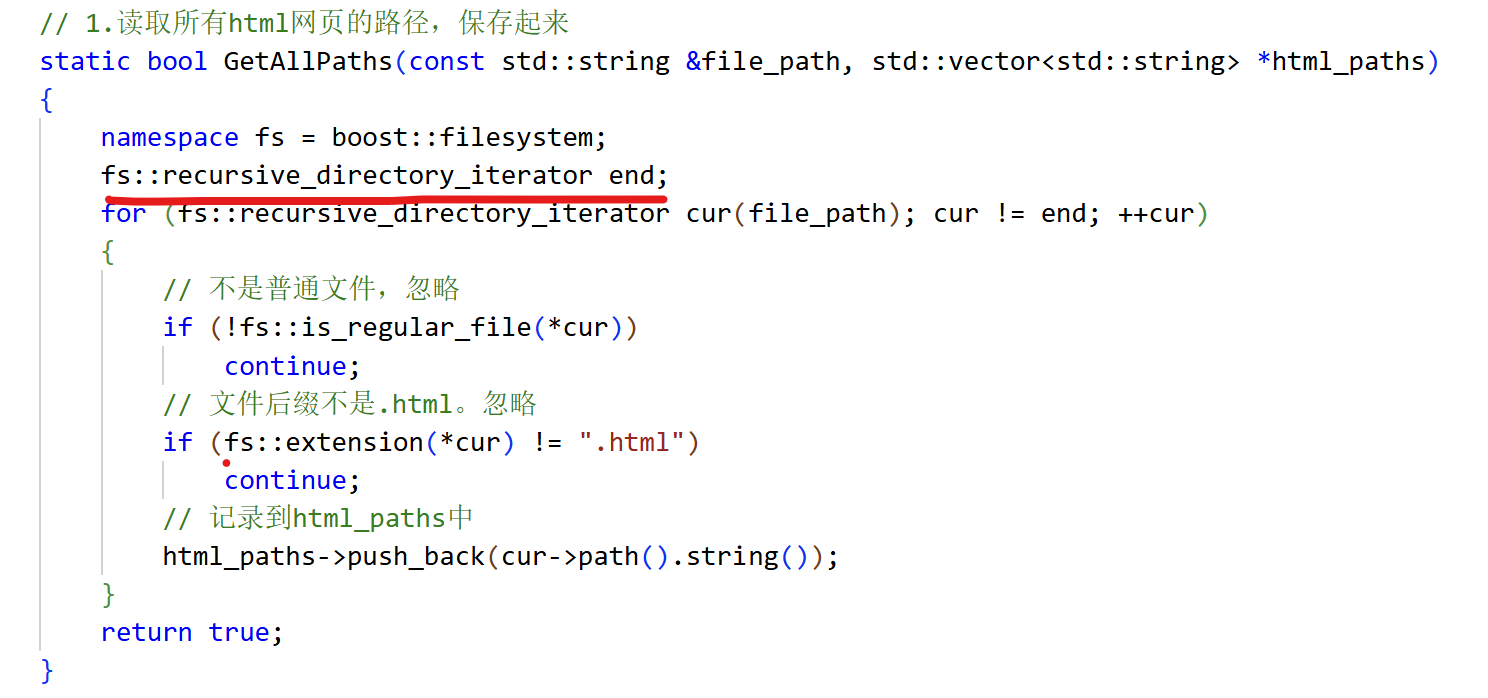
5.1 boost文件系统
boost文件系统filesystem使用:boost::filesystem 暂时取别名为fs
1)fs::recursive_directory_iterator 递归迭代器,默认构造可以代表end,传值构造的值要用目录。作用:递归式地遍历目录下所有的文件(包括目录)
2)fs::is_regular_file(路径),判断是否是常规文件
3)fs::extension(路径),获取拓展名,即文件后缀
4)反向迭代器->path().string(),获取当前路径字符串
5.2 boost切分字符串 和 大小写转换
头文件:<boost/algorithm/string.hpp>
boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on);
- std::vector<std::string> *out存放截取后的字符串
- target为要截取的字符串
- sep为分隔符,可以是多个
- token_compress_on表示连续分隔符中间的空串不保留;反之off保留
头文件:<boost/algorithm/string/case_conv.hpp>
to_lower 和 to_upper 大小写转换,会改变源字符串
copy_to_lower 和 copy_to_upper 不会改变源字符串
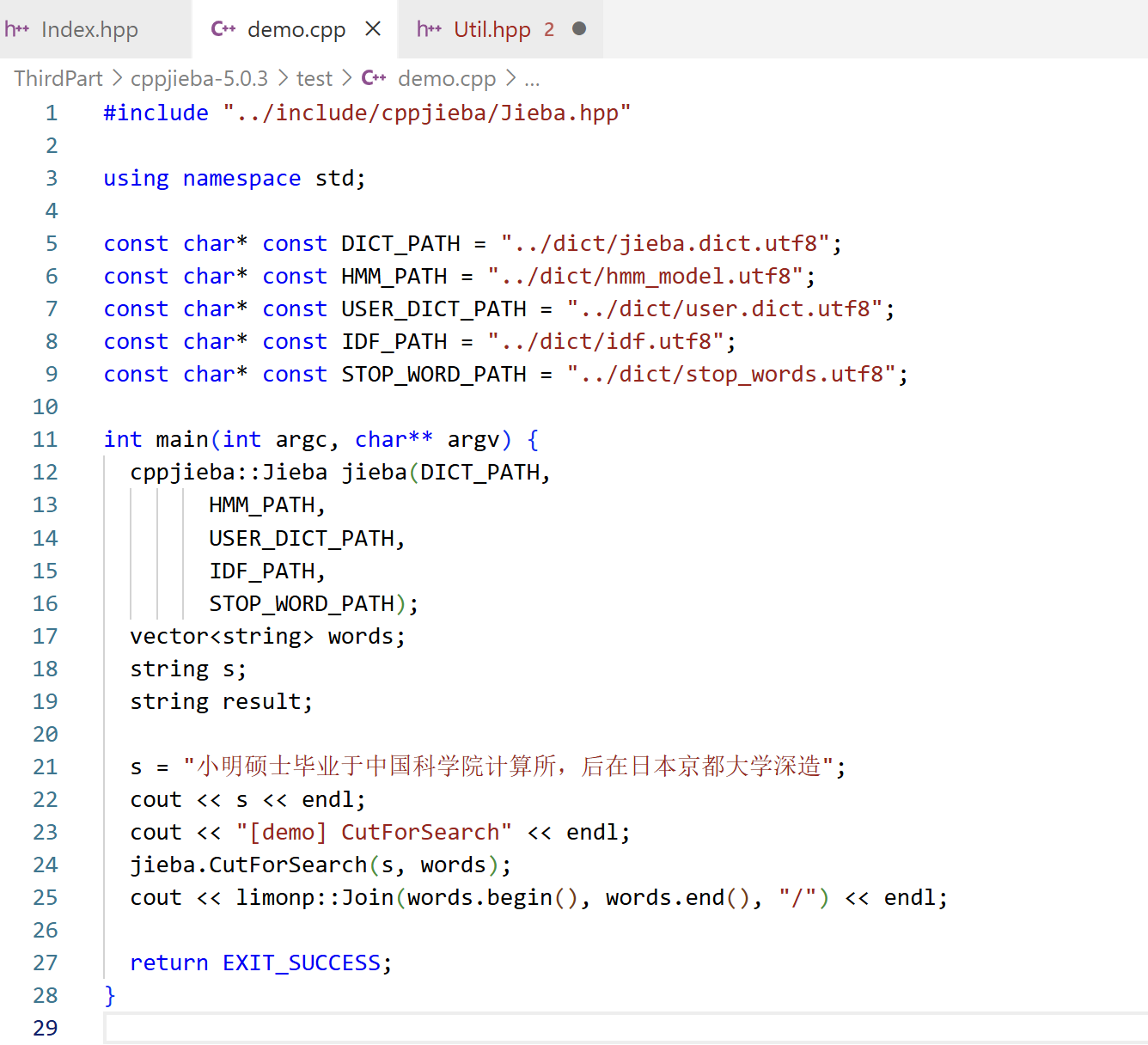
5.3 cppjieba使用
https://github.com/yanyiwu/cppjieba/archive/refs/tags/v5.0.3.tar.gz
选择使用5.0.3版本
注意事项:将cppjieba-5.0.3/deps/limonp目录拷贝到 cppjieba-5.0.3/include/cppjieba使用jieba.CutForSearch(string, vector<string>)
将原始str进行切词,放到vector<string>内部
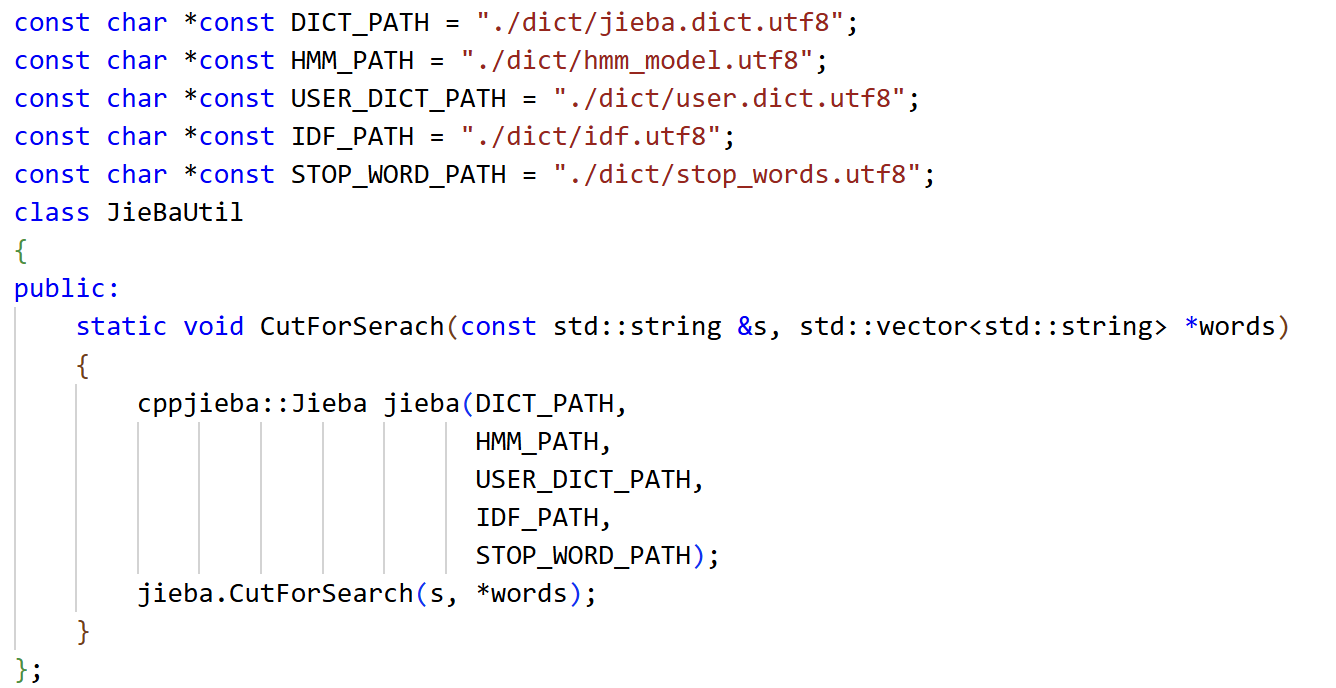
5.4 cpp-httplib库使用
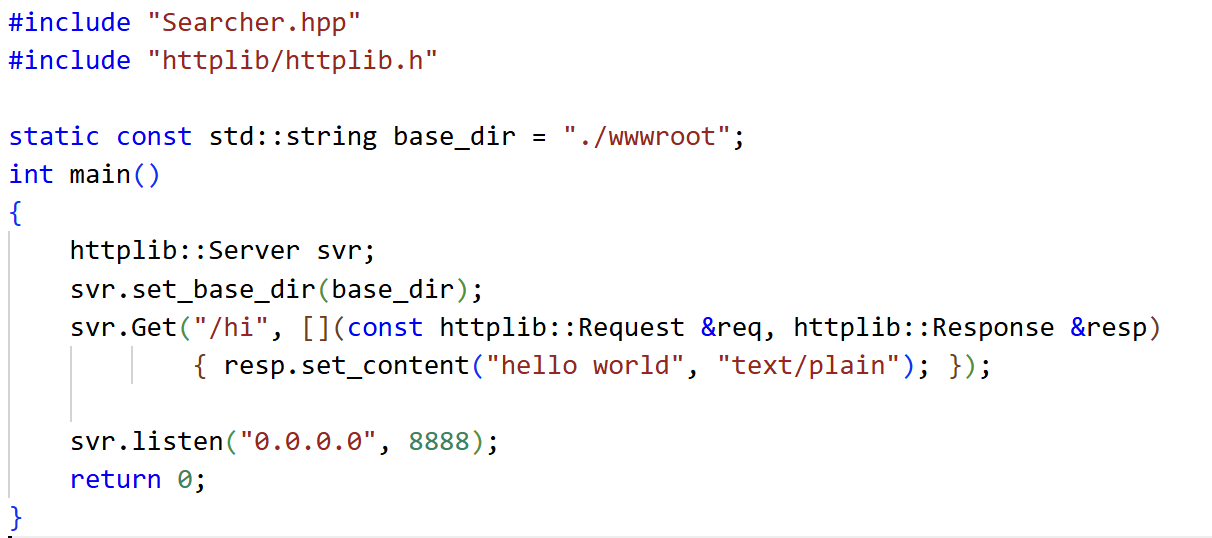
https://github.com/yhirose/cpp-httplib
高版本gcc,添加到启动脚本:~/.bash_profile特别注意:listen要放在最后面,listen启动
set_base_dir:设置web根目录
Get:设置http请求方法GET,第一个参数uri为"/hi",第二个参数回调std::function<void(const httplib::Request &, httplib::Response &)>
六、整体逻辑梳理
模块一:数据清洗
1)读取所有html文件路径
2)读取文件路径对应内容,进行数据清洗(取标题,去标签留内容,拼接url)
3)根据格式写到文件里
模块二:建立索引
建立单个索引逻辑:
1)根据一行内容,按格式分割出来,插入到正排索引数组,建立正排索引,返回刚插入的正排节点指针
2)对正排对象的title和content分别进行分词,记录到数组中
3)用哈希表,以分词作为key,
struct Cnt
{
size_t titleCnt = 0;
size_t contentCnt = 0
}; 作为value
对title分词和content分词数量分别进行统计(特别地,分词要转成小写)
4)遍历哈希表,Index中记录倒排拉链的哈希表(关键字,倒排拉链)用分词.push_back(倒排节点);倒排节点的id填1)正排节点指针对应的id,word填分词,weight = 标题关键字数量*10 + 正文关键字
建立所有索引:循环读取一行数据清洗后的文件结果,将这一行数据给建立单个索引
模块三:搜索模块
初始化逻辑:
1)获取index单例
2)建立index所有索引
搜索逻辑:
1)将query进行分词,结果记录到数组
2)创建umap(文档id,倒排打印节点),遍历分词结果,判断query分词是否有对应的倒排拉链
a.没有,continue
b.有,遍历倒排拉链,用umap倒排节点._id,赋值id,累加相同id的权值,尾插相同id的关键字(目的:query中出现两个及以上的关键字来自同一个文档时,结果会出现多份相同url,为了避免这种情况,使用umap让id作为key值,去重id)
3)将umap中倒排打印节点拷贝到数组中,按照totalWeight进行排序
4)遍历倒排打印节点数组,用id查正排,获得正排节点指针,将其id,分词数组第一个元素content摘要,url用cppjson库序列化成json串
5)输出型参数json_string带出json串
模块四:http服务模块
整体逻辑:
1)建立Searcher对象
2)建立http服务对象
3)设置web根目录,注册HTTP请求方式为Get方式的回调方法:由前端页面提供query字符串,后端调用Searcher对象的搜索方法得到结果json串,将json串返回给前端页面
4)设置监听任意IP,设置端口号,启动监听
细节点:
对于去掉暂停词:
1)建立unordered_set读上来cppjieba的停止词文件
2)将切分词后的结果拷贝到链表中
3)链表去比对停止词来进行删除
4)链表去除停止词后的结果拷贝回结果数组中
注:双向链表任意位置删除时间复杂度O(1),数组任意位置删除时间复杂度O(N),删除用链表可以大大提高建立索引的过程。
七、项目源码
Linux-remote: linux远程仓库
https://gitee.com/its-quite-six/linux-remote/tree/master/BoostProject