在Redis中,List类型是常用的数据结构之一,广泛应用于消息队列、最新消息展示、排行榜等场景。不同于传统编程语言中的链表实现,Redis的List底层采用了ziplist(压缩列表) 和quicklist(快速链表) 两种动态切换的存储方式。这种灵活的设计兼顾了内存利用率和操作性能,是Redis高性能特性的重要体现。本文将从数据结构、适用场景、核心优势及编码转换等方面,全面解析Redis List的底层实现逻辑。
一、设计初衷:为何需要两种存储方式?
在Redis 3.2版本之前,List的底层实现采用"ziplist + linkedlist"的混合模式:当数据量较小时使用ziplist节省内存,当数据量增大时切换为linkedlist保证操作性能。但这种模式存在明显缺陷:
- linkedlist的每个节点都需要存储前驱和后继指针,带来大量内存开销;
- 节点分散存储导致内存碎片增多,CPU缓存命中率低。
为解决这些问题,Redis 3.2版本后引入了quicklist,将ziplist的紧凑存储特性与linkedlist的高效操作特性相结合,形成了新的List底层实现方案。而ziplist则作为quicklist的"数据块"存在,两种结构协同工作,实现内存与性能的平衡。
二、ziplist:紧凑存储的"内存优化大师"
(一)数据结构定义

ziplist是一种连续内存的紧凑存储结构,并非传统意义上的链表。它通过特定的编码方式存储多个元素(字符串或整数),整个结构无需指针关联,极大地节省了内存空间。其整体结构及单个元素(entry)的存储格式如下:
- 整体结构:包含头部信息(存储总长度、元素数量等)、多个entry(元素数据)和尾部标记。
- 单个entry:存储元素的长度、编码类型及实际数据,根据元素的大小和类型采用不同的压缩编码。格式为:
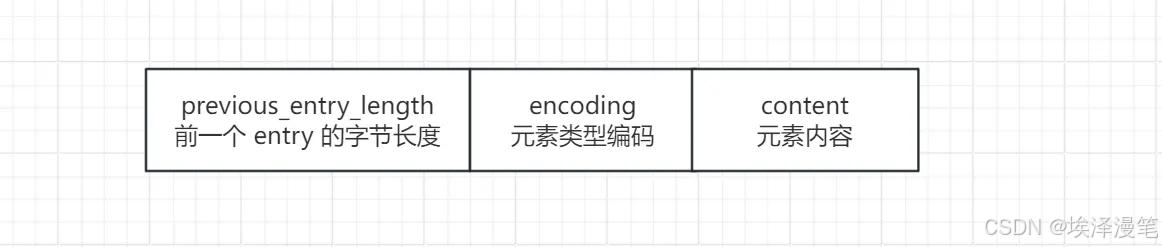
(二)触发条件与适用场景
当List满足以下两个条件时,会优先使用ziplist编码(可通过配置调整阈值):
- 元素数量≤512个(默认配置,由
list-max-ziplist-size控制); - 单个元素大小≤64字节(默认配置,由
list-max-ziplist-value控制)。
适用场景多为小数据集、低修改频率的场景,例如存储少量用户标签、简短的配置项列表等。
(三)核心优势
- 内存利用率极高:连续内存存储,无指针开销,且通过压缩编码进一步减少空间占用;
- 内存碎片少:整块内存分配,避免了离散节点导致的内存碎片问题;
- CPU缓存友好:连续的数据布局能提升CPU缓存命中率,加快数据读取速度。
(四)局限性
- 插入/删除性能差:由于是连续内存,插入或删除元素时需要遍历找到目标位置,并移动后续数据,时间复杂度为O(n);
- 扩展性不足:当元素数量或大小超出阈值时,频繁的内存重分配和数据移动会导致性能急剧下降。
三、quicklist:兼顾性能与内存的"终极方案"
(一)数据结构定义
quicklist是Redis 3.2版本后List的默认底层实现,其本质是由多个ziplist节点组成的双向链表。每个节点(quicklistNode)都指向一个ziplist,通过分块存储的方式平衡了内存占用和操作性能。核心结构体定义如下:
// 快速链表的整体结构
typedef struct quicklist {
quicklistNode *head; // 链表头节点
quicklistNode *tail; // 链表尾节点
unsigned long count; // List中的元素总数
unsigned long len; // 快速链表中的节点数量(quicklistNode个数)
int fill : 16; // 单个ziplist的最大容量(对应list-max-ziplist-size配置)
unsigned int compress : 16; // 压缩深度(对应list-compress-depth配置,控制中间节点压缩)
} quicklist;
// 快速链表的单个节点
typedef struct quicklistNode {
struct quicklistNode *prev; // 前驱节点指针
struct quicklistNode *next; // 后继节点指针
unsigned char *zl; // 指向当前节点对应的ziplist
unsigned int sz; // 当前ziplist的字节大小
unsigned int count : 16; // 当前ziplist中的元素数量
unsigned int encoding : 2; // 编码格式(0=原生ziplist,1=LZF压缩)
unsigned int container : 2; // 数据容器类型(预留字段,固定为ziplist)
unsigned int recompress : 1; // 标记是否被临时解压(用于读取压缩节点时)
} quicklistNode;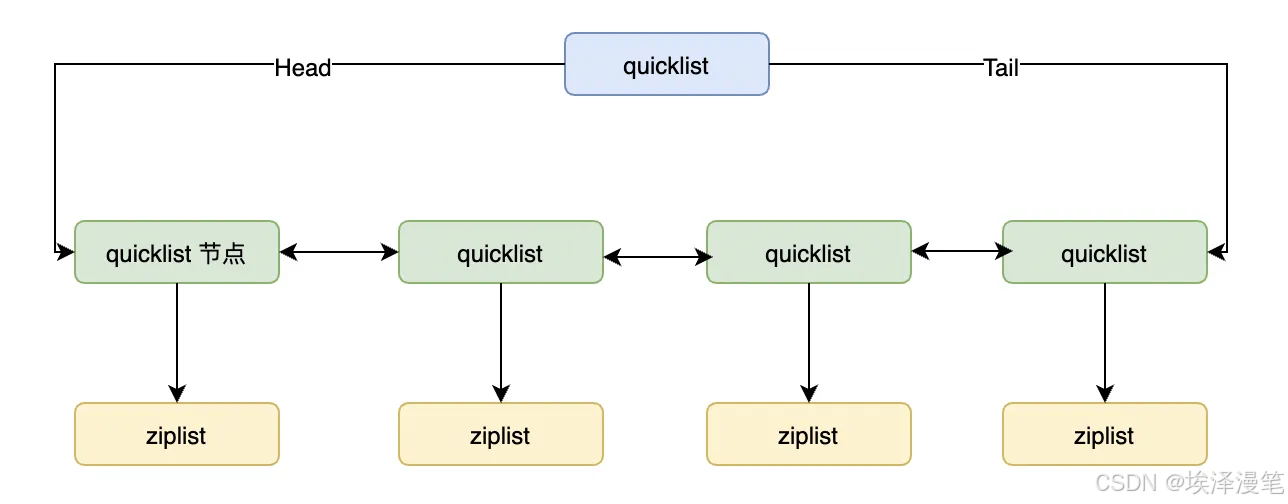
(二)核心设计思想
- 分块存储:将大数据集拆分为多个ziplist,每个ziplist的大小由配置限制,避免了单个ziplist过大导致的插入/删除性能问题;
- 双向链表特性:通过prev和next指针实现双向遍历,支持O(1)时间复杂度的头尾操作(如LPUSH、RPUSH、LPOP、RPOP),满足消息队列等高频头尾操作场景;
- 节点压缩优化 :可对中间节点进行LZF算法压缩(由
list-compress-depth配置控制),默认压缩深度为0(不压缩),若配置为1则表示头尾各1个节点不压缩,中间节点全部压缩,进一步节省内存。
(三)适用场景
适用于大数据集、高频头尾操作的场景,例如消息队列(通过LPUSH入队、RPOP出队)、用户动态列表(最新动态从头部插入,历史动态从尾部删除)等。
(四)核心优势
- 兼顾内存与性能:继承了ziplist的紧凑存储特性,同时通过双向链表优化了头尾操作性能;
- 插入/删除成本分摊:中间插入/删除操作仅需操作对应的数据块(ziplist),无需移动整个数据集,将O(n)的开销分摊到单个块中;
- 灵活配置:支持通过参数调整单个ziplist的大小和节点压缩深度,适配不同业务场景。
(五)局限性
- 内存碎片略多:相比单一ziplist,多个quicklistNode的分散存储会产生少量内存碎片;
- 指针开销:每个节点的prev和next指针会带来一定的内存开销,但远低于传统linkedlist。
四、编码转换规则
Redis会根据List的元素数量和元素大小,自动触发ziplist与quicklist之间的编码转换,转换规则如下:
- ziplist → quicklist:当满足以下任一条件时,自动从ziplist转为quicklist:
-
- 元素数量超过
list-max-ziplist-size(默认512); - 单个元素大小超过
list-max-ziplist-value(默认64字节)。
- 元素数量超过
- quicklist → ziplist:一旦转为quicklist编码,不会自动转回ziplist,即使后续元素数量或大小降至阈值以下(需手动重新创建List并插入数据才能触发ziplist编码)。
五、两种结构的核心对比
为了更清晰地展示ziplist和quicklist的差异,整理了以下对比表格:
|-----------|---------------|------------------------|
| 特性 | ziplist(压缩列表) | quicklist(快速链表) |
| 内存占用 | 低(连续紧凑,无指针开销) | 中等(分块存储 + 少量指针/压缩开销) |
| 头尾操作性能 | O(n)(需移动数据) | O(1)(直接操作首尾节点) |
| 中间插入/删除性能 | O(n)(移动整个数据集) | O(n)(仅移动对应ziplist内的数据) |
| 内存碎片 | 少 | 较多 |
| 适用场景 | 小数据集、低修改频率 | 大数据集、高频头尾操作 |
| 扩展性 | 差 | 好 |
六、总结
Redis List的底层实现从"ziplist + linkedlist"到quicklist的演进,充分体现了Redis对"内存效率"和"操作性能"的极致追求。ziplist以紧凑存储解决了小数据集的内存浪费问题,而quicklist则通过分块存储和双向链表的结合,兼顾了大数据集的性能需求。
在实际开发中,合理利用List的编码特性能优化Redis的使用效率:例如存储少量短元素时,尽量控制元素数量和大小以触发ziplist编码;实现消息队列等高频头尾操作场景时,依赖quicklist的O(1)头尾操作性能。