引言:从"重启服务"到"秒级生效"的进化
在互联网时代,配置变更已不再是简单的"改个参数、重启服务"的简单操作。当某电商平台的运营人员在营销后台将"新用户注册奖励从10金币调整为20金币"时,系统需要立即 生效,而不是等待10分钟的重启过程。这背后,是大厂级企业后端架构的深度演进------从手动干预 到自动化闭环的质变。
本文将深入探讨大厂如何实现配置变更后API接口秒级生效,不使用旧缓存,而是使用最新配置。这不是简单的代码逻辑,而是一套融合了架构设计、中间件能力、自动化流程和监控体系的工程实践。
一、问题深度剖析:为什么需要自动化处理?
1. 传统方式的痛点
| 方案 | 问题 | 适用场景 |
|---|---|---|
| 重启服务 | 服务中断,用户体验差,无法实时生效 | 低频变更、非核心业务 |
| 手动清除缓存 | 依赖人工操作,易出错,延迟高 | 小型系统、测试环境 |
| 依赖缓存TTL | 生效延迟,无法保证实时性 | 非关键配置变更 |
在大型系统中,一次配置变更可能影响成百上千个服务实例,手动操作 不仅效率低下,还极易导致数据不一致 和业务故障。
2. 大厂面临的实际挑战
- 高并发场景:千万级QPS的系统,缓存失效延迟可能导致大量请求穿透数据库
- 多级缓存架构:本地缓存(Caffeine) + 分布式缓存(Redis) + 数据库
- 多环境管理:开发、测试、预发、生产环境配置隔离
- 灰度发布需求:需要按用户、地域、设备等维度渐进式生效
二、大厂级解决方案架构:三位一体
大厂普遍采用"配置中心 + 多级缓存 + 事件驱动"的架构,实现配置变更的秒级生效。以下是典型架构图:
┌─────────────────────┐ ┌───────────────────┐ ┌─────────────────────┐
│ │ │ │ │ │
│ 配置管理平台 │ │ 事件/消息队列 │ │ 应用服务实例 │
│ (Apollo/Nacos) │────▶│ (Kafka/RocketMQ) │────▶│ (Spring Boot + Caffeine + Redis) │
│ │ │ │ │ │
└────────┬────────────┘ └────────┬──────────┘ └────────┬────────────┘
│ │ │
▼ ▼ ▼
┌─────────────────────┐ ┌───────────────────┐ ┌─────────────────────┐
│ │ │ │ │ │
│ 配置变更操作 │ │ 配置变更事件 │ │ 缓存清除/刷新 │
│ (运营/开发人员) │ │ (推送至所有实例) │ │ (本地缓存 + Redis) │
│ │ │ │ │ │
└─────────────────────┘ └───────────────────┘ └─────────────────────┘三、深度实现方案:从理论到实践
1. 配置中心:核心枢纽
为什么选择Apollo/Nacos?
- 热更新机制:支持长轮询、WebSocket等实时推送
- 版本管理:记录每次变更历史,支持回滚
- 灰度发布:支持按环境、按实例、按用户维度发布
- 权限控制:细粒度的配置访问权限
配置中心最佳实践:
# 配置中心配置示例
# 业务场景:新用户注册奖励
user.register.reward:
value: 10
description: 新用户注册奖励金币
version: 1
release: prod2. 多级缓存架构设计:从L1到L3
大厂采用多级缓存策略,确保性能与一致性的平衡:
| 缓存层级 | 技术实现 | 作用 | TTL | 适用场景 |
|---|---|---|---|---|
| L1:本地缓存 | Caffeine/Guava | 高性能访问,避免网络开销 | 5-30分钟 | 高频读、低更新、可容忍短暂不一致 |
| L2:分布式缓存 | Redis/Tair | 跨实例共享,高可用 | 10-60分钟 | 热点数据、会话管理 |
| L3:数据库/配置中心 | MySQL/配置中心 | 最终数据源 | 永久 | 无缓存穿透场景 |
缓存Key设计规范:
java
// 业务域:数据类型:主键:版本号
String cacheKey = "config:reward:user_register:" + configVersion;✅ 优势:配置变更后,
configVersion变化,缓存Key自动变化,旧缓存自然失效。
3. 事件驱动机制:配置变更的"神经网络"
核心流程:
- 配置变更提交到配置中心
- 配置中心生成新版本并推送事件
- 应用实例接收事件,触发缓存清除
- 重新加载最新配置,重建缓存
代码实现示例(Spring Boot + Apollo):
java
@Configuration
public class ConfigListenerConfig {
@Bean
public ConfigListener configListener() {
return new ConfigListener() {
@Override
public void receiveConfigInfo(String configInfo) {
// 1. 清除本地缓存
localCache.invalidate("user_register_reward");
// 2. 清除Redis缓存
redisTemplate.delete("config:reward:user_register");
// 3. 预热新配置
String newValue = configInfo;
cacheConfig(newValue);
}
};
}
private void cacheConfig(String value) {
// 将新配置缓存到Redis
redisTemplate.opsForValue().set(
"config:reward:user_register",
value,
Duration.ofMinutes(30)
);
}
}关键点:
- 事件处理是异步的,避免阻塞主线程
- 清除操作必须成功,失败需重试或告警
- 预热新配置,避免冷启动穿透
4. 消息队列兜底:确保事件不丢失
为什么需要MQ?
- 配置中心推送可能因网络抖动丢失
- 事件处理失败需要重试机制
- 高并发场景下,长轮询可能压力过大
实现方案:
图表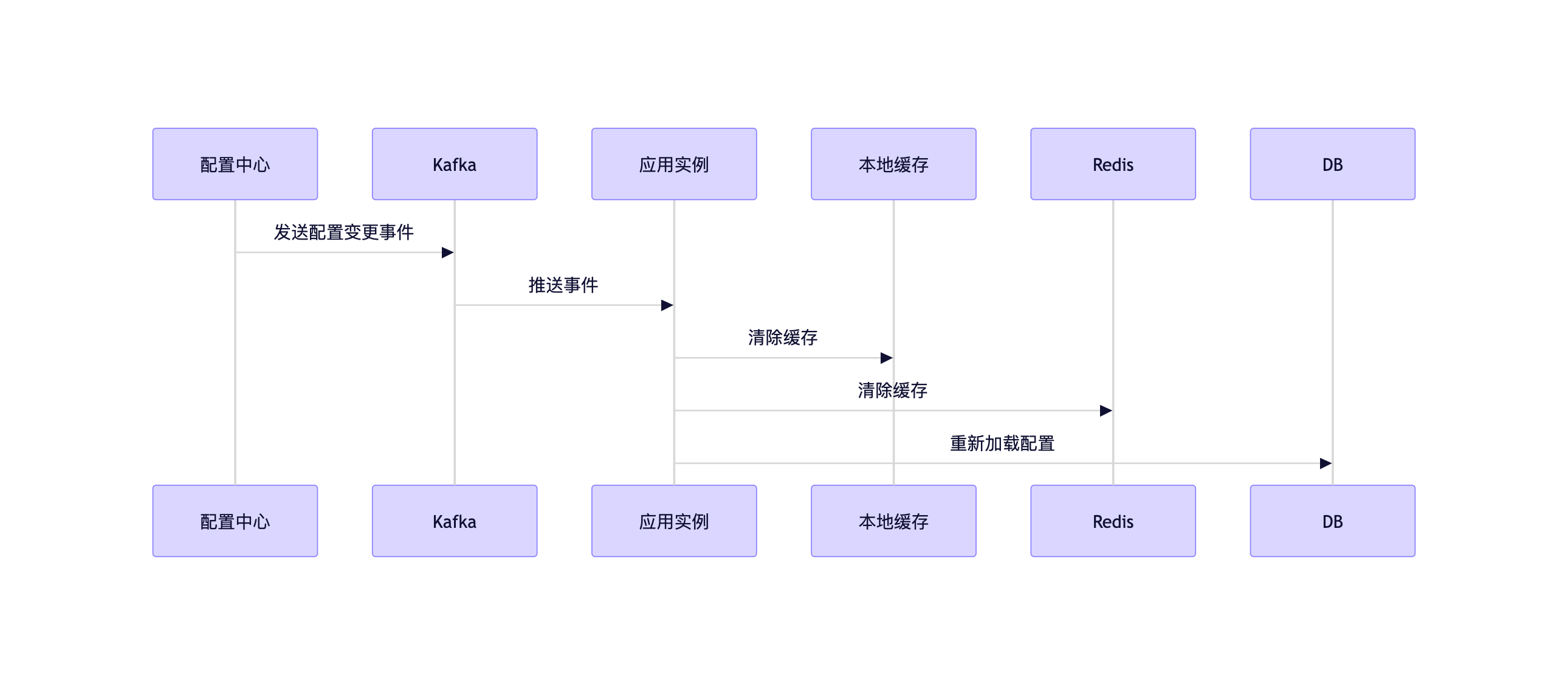
代码实现:
java
@Component
public class ConfigConsumer {
@KafkaListener(topics = "config-updates")
public void handleConfigUpdate(String configEvent) {
try {
// 解析配置事件
ConfigEvent event = parseEvent(configEvent);
// 清除缓存
localCache.invalidate(event.getKey());
redisTemplate.delete("config:" + event.getKey());
// 重新加载配置
String newValue = configService.loadConfig(event.getKey());
cacheConfig(event.getKey(), newValue);
} catch (Exception e) {
// 记录日志并重试
log.error("Failed to process config update: {}", event, e);
retryService.retry(event);
}
}
}四、真实案例:某电商平台的优惠券配置变更
1. 业务场景
- 电商平台运营人员在营销后台将"新用户注册优惠券金额"从10元调整为20元
- 需要秒级生效,避免用户看到过期的10元优惠券
2. 传统方式 vs 大厂方案
| 方案 | 效果 | 问题 |
|---|---|---|
| 重启服务 | 10分钟生效 | 服务中断,用户无法下单 |
| 手动清除缓存 | 5分钟生效 | 依赖人工操作,易出错 |
| 大厂方案 | 1秒生效 | 无感知,无业务中断 |
3. 大厂方案落地细节
- 配置变更:运营人员在营销平台修改优惠券金额
- 配置中心 :Apollo记录变更,生成新版本
v2,推送事件 - 应用实例 :
- 收到事件后,清除本地缓存和Redis缓存
- 重新加载最新配置,预热缓存
- 用户请求:新用户注册时,直接返回20元优惠券,无缓存残留
✅ 整个过程无需重启服务 ,无缓存脏数据 ,用户无感知。
五、高级实践:保障最终一致性
1. 双保险机制:配置中心 + 消息队列
- 配置中心推送:主通道,秒级生效
- MQ广播:兜底通道,确保事件不丢失
java
// 事件处理逻辑
public void handleConfigUpdate(ConfigEvent event) {
try {
// 1. 清除缓存
clearCache(event.getKey());
// 2. 重新加载配置
String newValue = loadConfigFromDB(event.getKey());
// 3. 预热缓存
cacheConfig(event.getKey(), newValue);
// 4. 发送MQ确认消息
kafkaTemplate.send("config-updates-confirm", event);
} catch (Exception e) {
// 重试或告警
log.error("Failed to handle config update: {}", event, e);
retryService.retry(event);
}
}2. 缓存预热:避免冷启动
- 配置变更后,主动将新值加载进缓存
- 避免用户首次请求时的缓存穿透
java
private void cacheConfig(String key, String value) {
// 预热本地缓存
localCache.put(key, value);
// 预热Redis
redisTemplate.opsForValue().set(
"config:" + key,
value,
Duration.ofMinutes(30)
);
}3. 监控与告警:保障系统健康
| 监控项 | 目标 | 告警阈值 |
|---|---|---|
| 缓存命中率 | >95% | <90% |
| 配置变更处理成功率 | 100% | <99.9% |
| 配置变更到生效时间 | <1秒 | >5秒 |
| 缓存清除失败率 | 0% | >0.1% |
实现方式:
- Prometheus + Grafana 监控指标
- 业务日志记录配置变更和缓存清除
- 链路追踪(SkyWalking)查看全链路影响
六、最佳实践与避坑指南
1. 缓存Key设计
- 必须包含版本号 :
config:reward:user_register:v12345 - 避免使用固定Key:防止配置变更后缓存未失效
- 统一命名规范 :
{业务域}:{数据类型}:{主键}:{版本号}
2. 事件处理可靠性
- 幂等处理:确保重复事件不会导致重复操作
- 重试机制:失败后自动重试,避免数据不一致
- 失败告警:关键事件失败需实时告警
3. 性能优化
- 批量处理:配置变更时,批量清除缓存
- 异步处理:事件处理不阻塞主线程
- 预热机制:配置变更后,主动预热缓存
4. 配置回滚
- 版本管理:配置中心支持版本回滚
- 自动回滚:配置变更后,若监控指标异常,自动回滚到上一版本
七、总结:大厂的真正实力
大厂不是靠"改完配置再清缓存"这种手动操作,而是通过一套自动化、可监控、高可靠的闭环系统,实现:
- 配置变更 → 配置中心自动记录并推送
- 事件处理 → 应用实例自动接收并处理
- 缓存失效 → 本地缓存 + Redis 无感清除
- 配置生效 → API 接口返回最新数据
- 监控告警 → 全链路监控,确保系统健康
一句话总结 :大厂的真正实力,不在于技术选型,而在于将配置变更与缓存失效处理,从手动操作升级为自动化闭环。
附录:技术栈推荐
| 组件 | 推荐技术 | 适用场景 |
|---|---|---|
| 配置中心 | Apollo、Nacos、自研配置平台 | 企业级配置管理 |
| 本地缓存 | Caffeine、Guava Cache | 高频读、低更新 |
| 分布式缓存 | Redis Cluster、Tair、Pika | 高并发读、跨实例共享 |
| 消息队列 | Kafka、RocketMQ、自研消息系统 | 事件驱动、可靠性保障 |
| 监控系统 | Prometheus + Grafana、SkyWalking | 全链路监控 |
结语
配置变更与缓存失效的自动化处理,是企业级后端系统从"可用"到"优秀"的关键分水岭。它不仅仅是一个技术问题,更是一个工程能力 的体现。当你能在配置变更后,让API接口秒级生效,不使用旧缓存,你已经在企业级系统的道路上迈出了坚实一步。
记住 :在大厂,我们不等待配置生效,我们让配置立即生效。