创建并为RAG添加结构的技术及实现方法:
1. 为数据添加简单结构:
为数据添加结构涉及多个步骤。但它始于分类法构建,随后是分类法的充实、实体提取和知识图谱创建
按回车键或点击以查看全尺寸图像
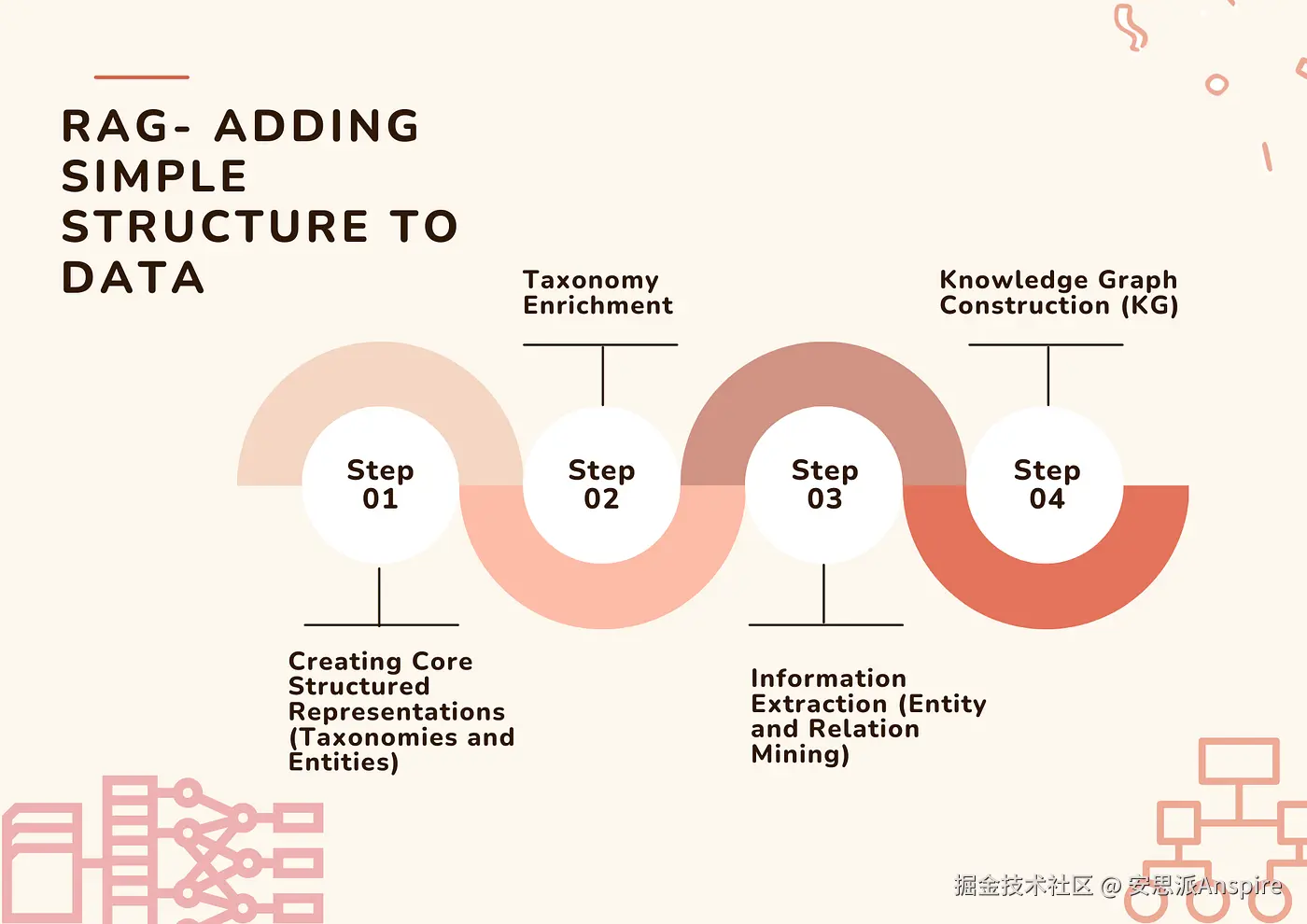
为数据添加简单结构的步骤 - 图片由作者(Vivedha Elango)提供
步骤1:创建核心结构化表示(分类法和实体)
此阶段为领域知识建立组织结构。因此,我们可以采取的第一步是构建分类法。
什么是分类法?
分类法是一种树状结构。它将概念从顶部的宽泛类别(父节点)组织到下方更具体的类别(子节点)。在文本挖掘中,分类法有助于构建标签和组织信息。
分类法构建始于一个基本结构,称为"种子"。不同的方法会在广度和深度上扩展这个种子,随后再调整整体结构。
**HiExpan**通过扩展实体来发展分类法,然后使用词类比进行细化。它旨在从专注于特定领域的文本语料库中创建特定任务的分类法。用户可以提供一个种子分类法来指导这个过程,确保结果与他们的需求相关。
首先,它会自动从语料库中生成关键术语列表。然后,从种子分类法开始,逐步扩展分类法。对于每个节点,HiExpan将其子节点视为一个集合,并递归地扩展它们,确保每组子节点保持连贯和相关。HiExpan还包括一个弱监督关系提取模块。
按回车键或点击以查看全尺寸图像
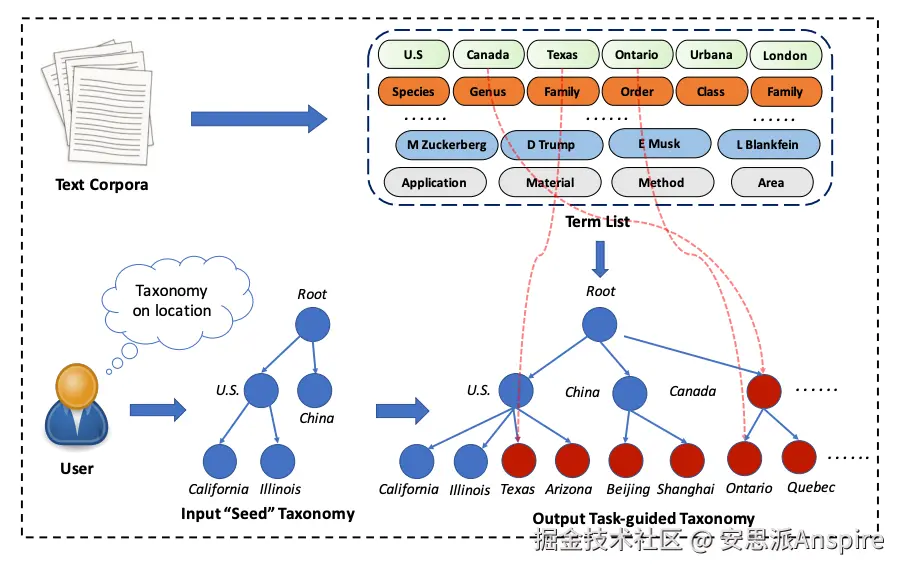
任务引导的分类法构建。用户提供一个"种子"分类树作为任务指导,我们将从原始文本语料库中提取关键术语,并自动生成所需的分类法。[来源](https://link.juejin.cn?target=https%3A%2F%2Farxiv.org%2Fabs%2F1910.08194 "https://arxiv.org/abs/1910.08194")
按回车键或点击以查看全尺寸图像
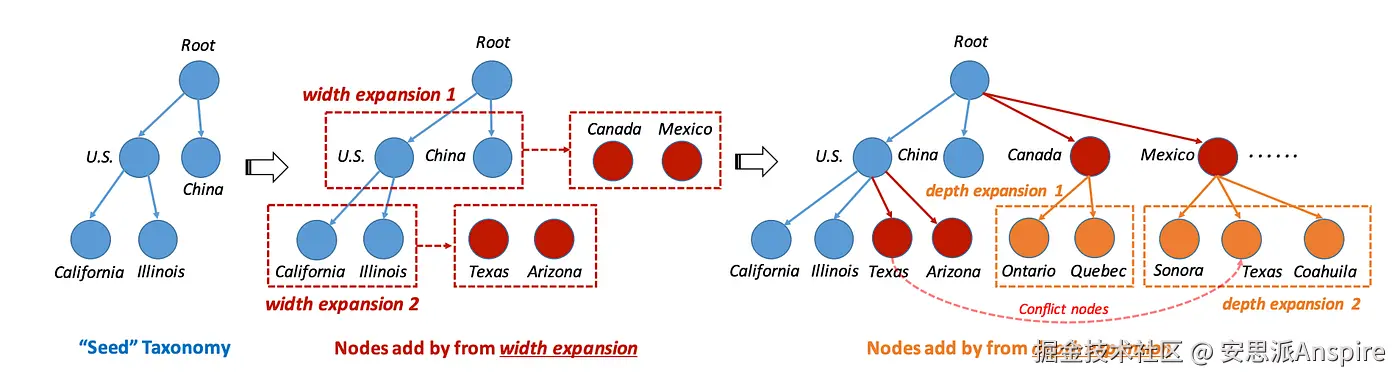
我们的分层树扩展算法概述 --- [来源](https://link.juejin.cn?target=https%3A%2F%2Farxiv.org%2Fabs%2F1910.08194 "https://arxiv.org/abs/1910.08194")
CoRel****: CoRel利用预训练语言模型来学习如何归纳亲子关系。ColRel提供了一种新的构建分类法的方法,使其能更好地匹配用户兴趣。ColRel不是仅使用宽泛的词对,而是从用户提供的种子分类法和文本语料库入手。然后,它会生成一个覆盖范围更广的定制分类法。在这里,每个节点不只是一个词,而是一组相关术语,这使得分类法更有意义,也更符合用户需求。
ColRel使用两个主要模块:
-
**关系转移:**该模块学习用户关心的关系。它在分类法的不同路径间转移这些关系,扩展其广度和深度。这意味着你将获得一个更详细、更广泛的结构,以满足你的兴趣。
-
**概念学习:**该模块强化了每个节点的含义。它通过嵌入分类法和文本语料库来实现这一点,因此每个概念都由一组连贯、相关的术语表示。
按回车键或点击以查看全尺寸图像
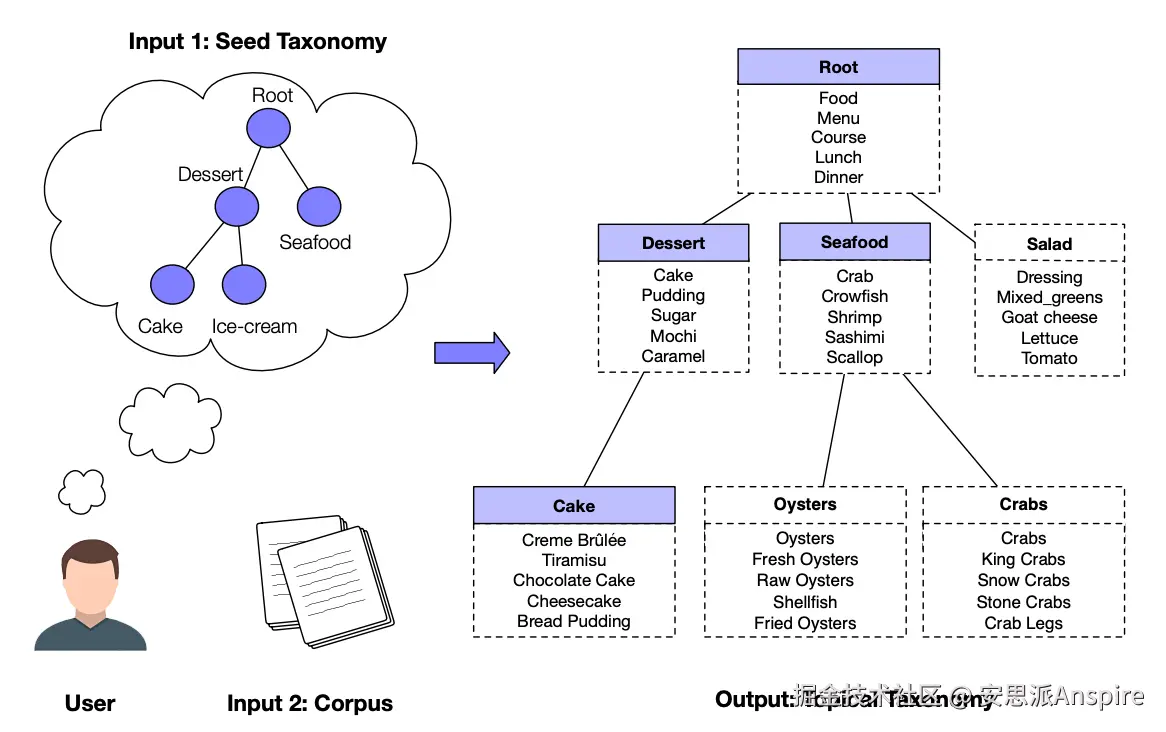
种子引导的主题分类法构建 - [来源](https://link.juejin.cn?target=https%3A%2F%2Farxiv.org%2Fabs%2F2010.06714 "https://arxiv.org/abs/2010.06714")
步骤2:分类法充实
此步骤通过将已构建的分类法节点与描述性文本(如关键词)关联起来,增强这些节点的功能。
在这一步中,我们使结构内的每个节点更具信息性和区分性。这里使用的技术在丰富过程中试图对树状结构进行建模。
**TaxoGen:**TaxoGen递归地对词嵌入进行聚类,并使用局部语料库对聚类进行细化。
TaxoGen将相关术语归为一个单一主题,使分类法更具信息性。它首先将术语转换为嵌入向量以捕捉其含义,然后使用一种特殊的聚类方法,逐步将宽泛的主题细分为更具体的主题,同时确保通用术语位于较高层级,具体术语位于较低层级。为了在较小主题的术语之间做出更精细的区分,TaxoGen仅使用与该主题相关的文档来学习新的嵌入向量,从而能够区分细微差异。这种方法完全自动化,比以前的方法创建的分类法更清晰、更有用,有助于用户和系统更好地浏览和理解大型文本数据集。
按回车键或点击以查看全尺寸图像
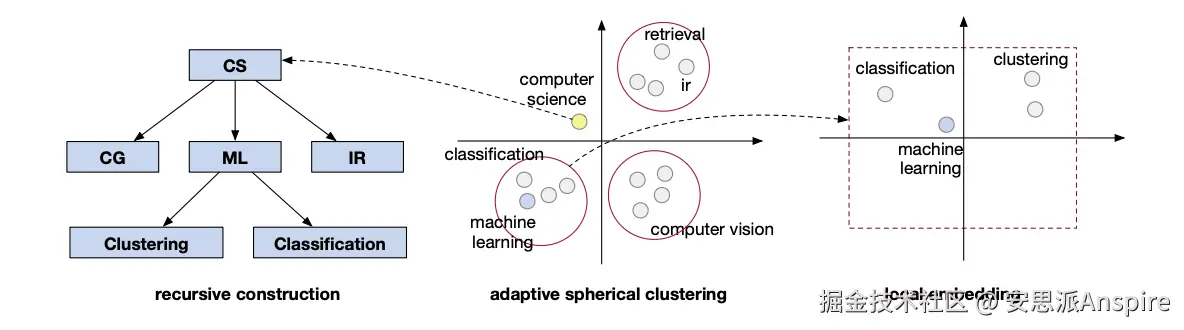
TaxoGen概述[来源](https://link.juejin.cn?target=https%3A%2F%2Farxiv.org%2Fpdf%2F1812.09551 "https://arxiv.org/pdf/1812.09551")
**NetTaxo:**NetTaxo通过整合网络结构信息对TaxoGen进行了扩展。其主要思路是让文档之间的关联和文本的实际内容共同发挥作用,以创建更丰富、更准确的主题层次结构。这使得发现主要主题及其子主题变得更加容易和精确,有助于人们快速找到信息并理解不同主题之间的关联。总体而言,NetTaxo通过同时利用文本及其关系网络,超越了旧系统,从而生成更具信息量和实用性的主题分类法
按回车键或点击以查看全尺寸图像
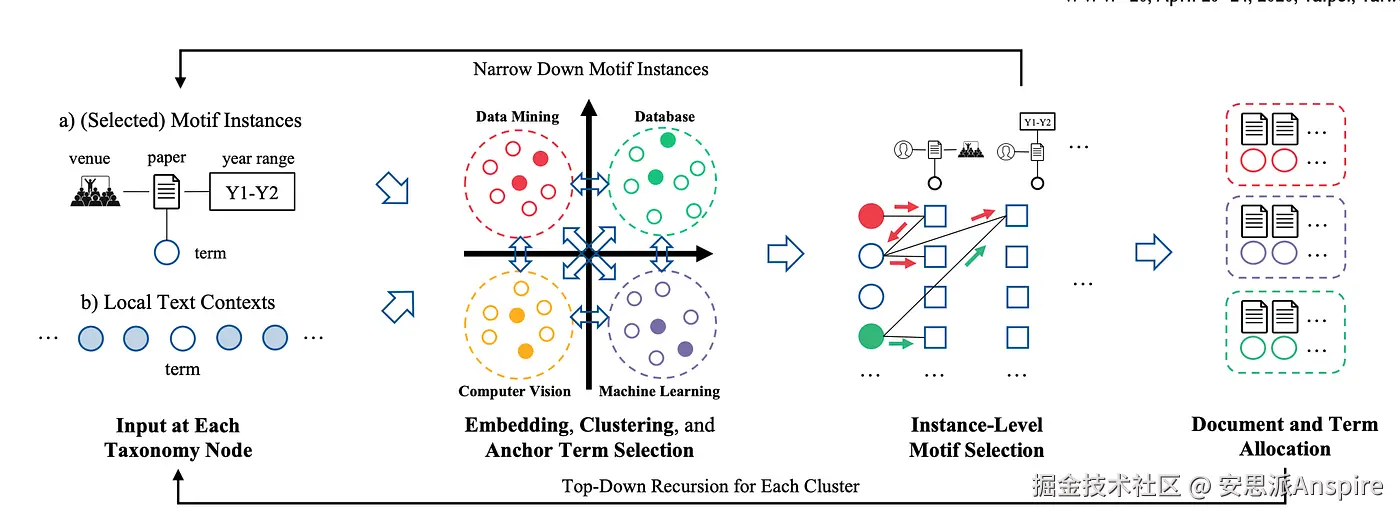
NetTaxo概述[来源](https://link.juejin.cn?target=https%3A%2F%2Fdl.acm.org%2Fdoi%2Fpdf%2F10.1145%2F3366423.3380259 "https://dl.acm.org/doi/pdf/10.1145/3366423.3380259")
步骤3:信息提取(实体和关系挖掘)
信息抽取(IE)专注于抽取实体级别的信息,这些信息是知识结构化的基石。
在这一步中,我们识别现实世界中的实体以及它们之间的关系,这些对于知识图谱的构建至关重要。
此步骤中使用的技术包括实体挖掘(命名实体识别 - NER,用于提取实体)和细粒度实体分类(FET) (用于将实体分类到本体论中),关系提取。
步骤4:知识图谱构建(KG)
在这一步中,提取的信息被实体化为知识图谱(KG)。在这里,我们尝试将现实世界中的实体表示为节点,将它们之间的关系表示为边。
创建知识图谱的一些关键技术和框架包括:
**流水线方法:**历史上使用开放信息抽取(OpenIE)工具抽取三元组,然后对其进行过滤和合并。
开放信息抽取(OpenIE)标注器提取开放领域的关系三元组,代表一个主语、一个关系和该关系的宾语。
除了提取关系三元组之外,标注器还会生成一些句子片段,这些片段对应于给定原始句子中的蕴含片段。这些片段存储在EntailedSentencesAnnotation键下的CoreMap(即句子)中。
按回车键或点击以查看全尺寸图像
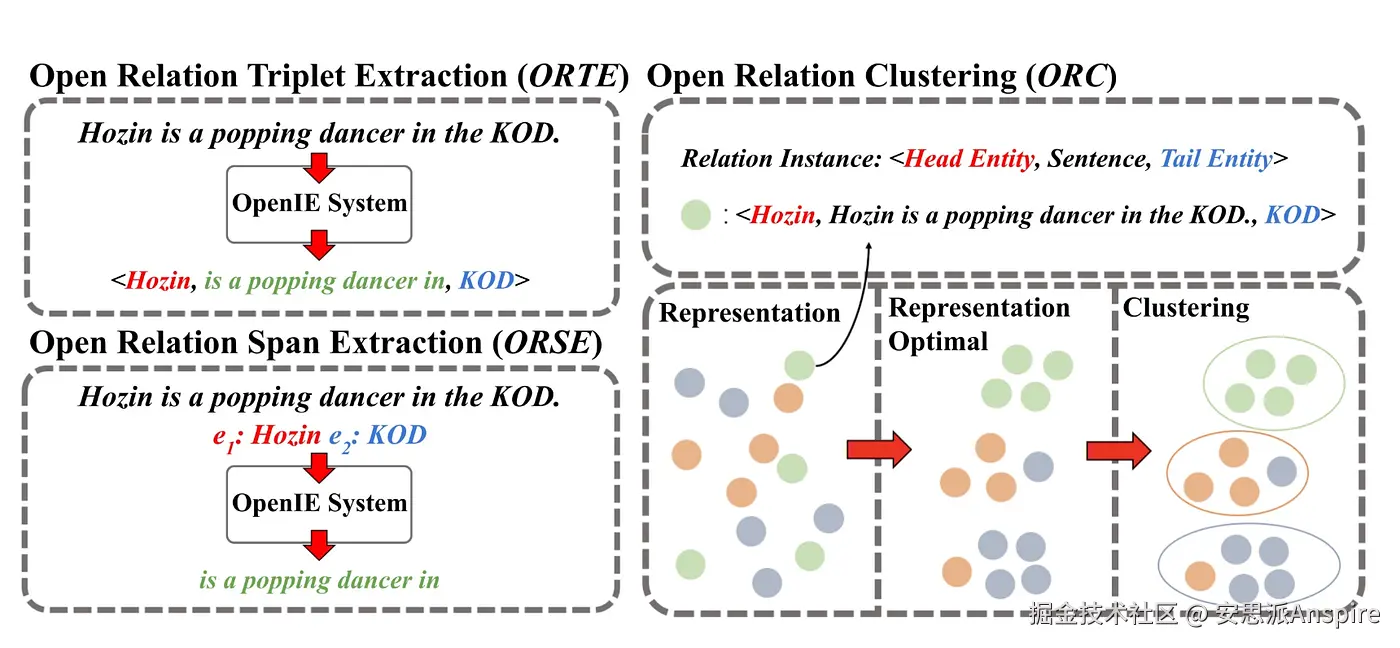
OpenIE任务设置中工作流流程概述[来源](https://link.juejin.cn?target=https%3A%2F%2Farxiv.org%2Fpdf%2F2211.15987 "https://arxiv.org/pdf/2211.15987")
端到端模型:像REBEL这样的框架和专门的模型利用预训练语言模型将原始文本直接转换为结构化知识。
基于大语言模型的构建:现代方法如知识图谱GPT直接提示大语言模型(如GPT-4)将纯文本转换为知识图谱。
因此,总结简单RAS循环中的所有步骤以及可能使用的框架。下面的流程将有助于更好地理解该过程和步骤。
按回车键或点击以查看全尺寸图像

为RAG数据添加简单结构的步骤 --- 图片由作者提供(Vivedha Elango)
向RAG添加简单结构的实现:
《kg-gen》包为该问题提供了一个简单的实现方案。它是一个文本到知识图谱(KG)的生成器,使用大语言模型(LLM)直接从纯文本构建高质量的图谱。kg-gen将相关实体组合在一起,有助于减少稀疏性,使图谱更具实用性。该包易于使用,可通过pip install kg-gen作为Python库获取。
ini
from kg_gen import KGGen
# Initialize KGGen with optional configuration
kg = KGGen(
model="openai/gpt-4o", # Default model
temperature=0.0, # Default temperature
api_key="YOUR_API_KEY" # Optional if set in environment or using a local model
)
# EXAMPLE 1: Single string with context
text_input = "Linda is Josh's mother. Ben is Josh's brother. Andrew is Josh's father."
graph_1 = kg.generate(
input_data=text_input,
context="Family relationships"
)
# Output:
# entities={'Linda', 'Ben', 'Andrew', 'Josh'}
# edges={'is brother of', 'is father of', 'is mother of'}
# relations={('Ben', 'is brother of', 'Josh'),
# ('Andrew', 'is father of', 'Josh'),
# ('Linda', 'is mother of', 'Josh')}对于大文本,您可以指定一个chunk_size参数,以较小的块处理文本:
ini
graph = kg.generate(
input_data=large_text,
chunk_size=5000 # Process in chunks of 5000 characters
)您可以在生成过程中或之后对相似的实体和关系进行聚类:
ini
# During generation
graph = kg.generate(
input_data=text,
cluster=True,
context="Optional context to guide clustering"
)
# Or after generation
clustered_graph = kg.cluster(
graph,
context="Optional context to guide clustering"
)聚合多个图
您可以使用聚合方法组合多个图表:
ini
graph1 = kg.generate(input_data=text1)
graph2 = kg.generate(input_data=text2)
combined_graph = kg.aggregate([graph1, graph2])明天我们将继续介绍高级:动态添加结构