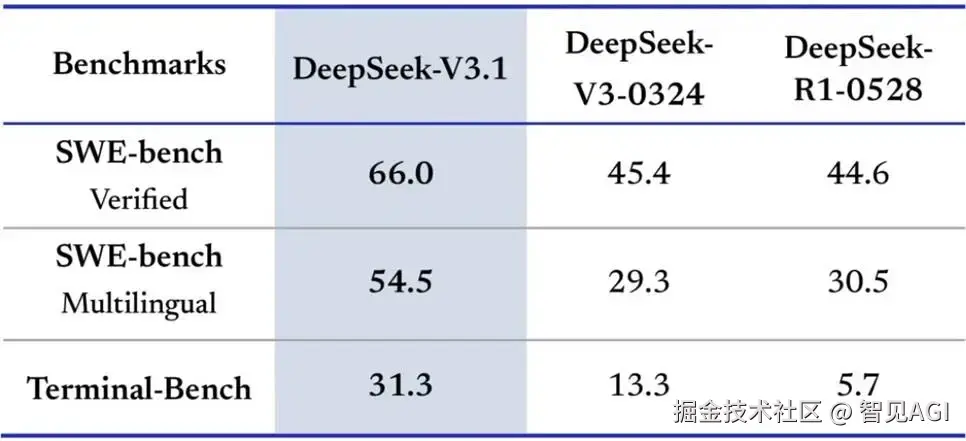
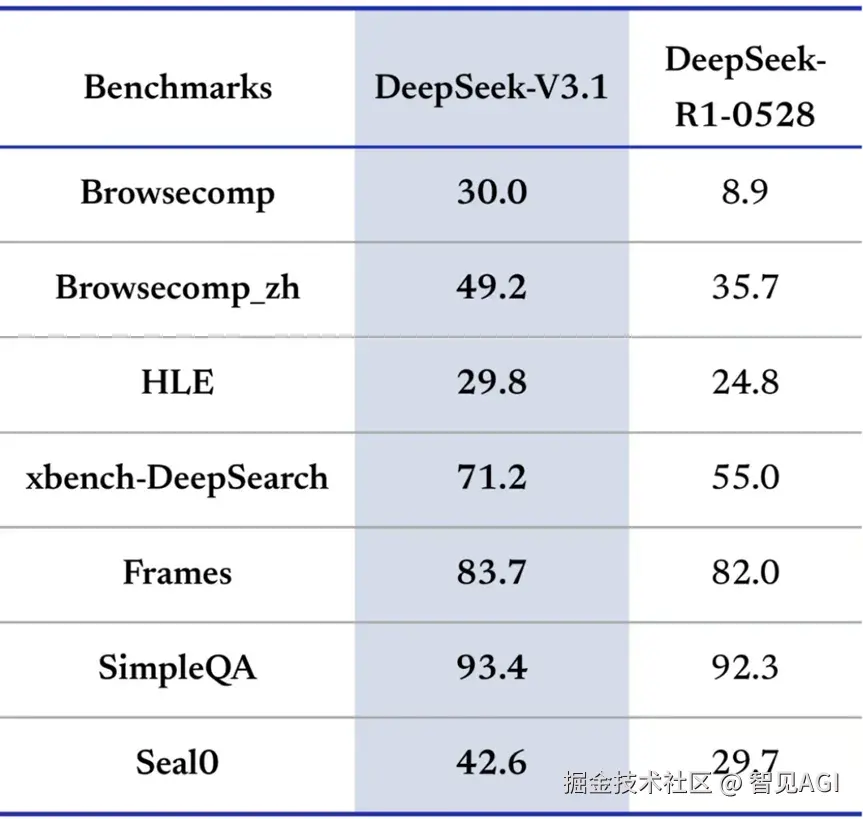
 最近深度求索公司发布了他们最先进的大模型DeepSeekV3.1,作为重要升级版本,其以混合推理架构作为核心,实现了一个模型同时支持思考模式和非思考模式,让用户可以根据需求自由切换,平衡效率与深度,其核心优势明显。
最近深度求索公司发布了他们最先进的大模型DeepSeekV3.1,作为重要升级版本,其以混合推理架构作为核心,实现了一个模型同时支持思考模式和非思考模式,让用户可以根据需求自由切换,平衡效率与深度,其核心优势明显。
而在模型推理加速领域,vLLM ****则是公认的"王牌引擎"。作为一个开源的高性能LLM推理和服务框架,vLLM凭借其核心技术创新------PagedAttention,从根本上解决了传统推理服务中显存浪费和吞吐量低下的痛点。它通过类似操作系统中虚拟内存的机制,实现了对GPU显存的精细化管理,将推理吞吐量提升了数倍之多,已成为业界部署LLM服务的事实标准之一。
尽管vLLM作为领先的开源推理框架为多节点部署提供了基础,但其在非NVLink互联的商品级硬件集群上存在明显的性能短板,主要体现在通信效率低下与核心算子适配 性差等方面。
为攻克此技术难题,我们在vLLM框架的基础上,实施了一系列针对性优化,专注提升其在小规模、无NVLink多节点环境下的通信与计算效率,致力于打造一个高效、经济的大模型普惠化部署解决方案。
1
问题定位
团队通过对vLLM源码的分析和实际推理过程的梳理,发现在三节点跨机推理表现低效,该性能瓶颈主要可归因于两个层面。一个是算子本身时间长,二是不同步而造成被动的造成通信时间长。
造成这种不同步有几种原因:
a.broadcast部分要进行通信六次,而且六次时间不固定,会偶发性拉长某一个rank的时间
b.在batch_size 比较小的时候会产生moe负载不均衡的问题,即本地专家命中有的命中了,时间长;有的没命中时间短,会让时间忙等。
c.Cuda kernel launch 有开销, python端launch kernel 有快有慢,在cuda端造成很多气泡,而这种气泡有长有短
算子本身时间长:
**
**
a. Attention decode 部分由许多trition小算子组成 和 效率比较低的fwd_grouped_kernel_stage_1和fwd_grouped_kernel_stage_2
b.broadcast本身时间很长,同一时间单向传播没有充分利用双向带宽
c.moe后的第一个all reduce 时间太长,原因是跨节点的全量数据进行all_redcue,造成浪费
2
计算图重排:从"先计算门控,再通信"到"先通信,再本地计算门控"
在MoE模型中,用于决定专家选择的router_logits的计算时机至关重要。原始流程中,巨大的hidden_states张量首先完成跨节点通信,形成全局hidden_states。然后,一个独立的、体积较小的router_logits张量也需要被广播,两者结合后才进行后续计算。这意味着网络中传输了不必要的router_logits,占用了宝贵的带宽。将 router_logits 放到hidden_states传输之后再本地计算,这样可以减少三次broadcast的调用
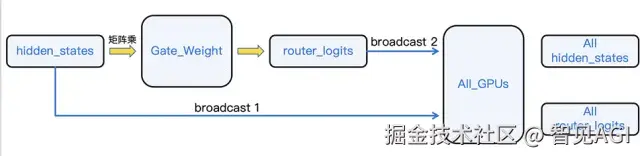
我们对计算与通信的顺序进行了调整,实现了router_logits的延迟计算。优化后的流程如下:
a.通信阶段: 仅传输核心的hidden_states张量,完成跨GPU的聚合。
b.本地计算阶段: 每张GPU在接收到完整的、全局的hidden_states后,在本地利用其独立的门控网络(Gating Network)自行计算出所需的router_logits。
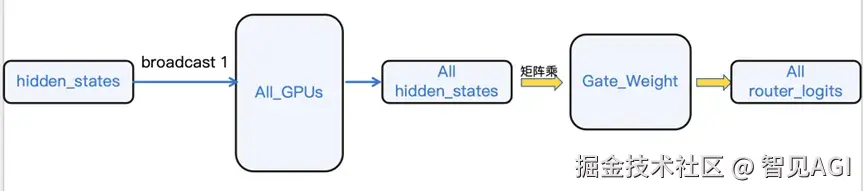
此项优化完全消除了router_logits张量的网络传输开销,极大地削减了该步骤的通信负载。通过将计算推迟到通信之后,我们将一个网络密集型操作转化为一个本地计算任务,省掉整体时间的10%到5%。
3
采用分层、多源的广播模式优化跨节点通信
原有的通信模型采用中心化广播模式。在该模式下,由单一源节点(例如 Node 1)向所有其他节点广播权重数据。这种"一对多"的模式存在两个主要缺陷:
a. 出口带宽瓶颈 (Egress Bottleneck): 源节点的网络出口带宽被迅速耗尽,成为整个系统的性能上限。
b.单向带宽浪费 (Unidirectional Waste): 高速互联网络(如 InfiniBand)的双向带宽能力未被充分利用,导致网络拥塞和资源闲置。
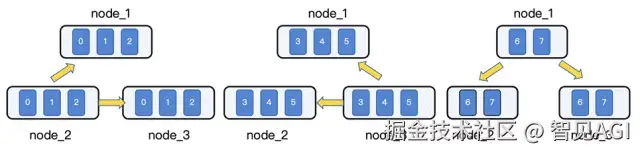
我们设计并实现了一种去中心化的分层、多源并行广播机制。此机制将广播任务分解,并分配给集群中的多个节点和GPU并行执行,将单点广播的压力均摊到整个集群。以一个包含3个节点、每节点8张GPU的集群为例,我们将广播任务拆分为多个轮次,每轮由不同节点上的GPU子集同时发起广播:节点内GPU分组: 将每个节点的8张卡动态划分为多个广播组(例如 3, 3, 2)。
• 多轮并行广播:
○第一轮: Node 1 的 GPU组1、Node 2 的 GPU组2、Node 3 的 GPU组3 同时向其他节点的对等GPU广播其本地数据分片。
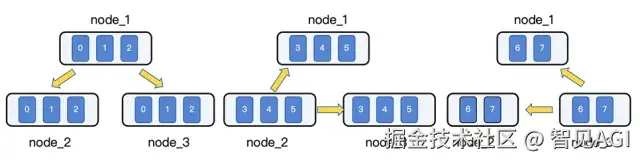
○第二轮: Node 1 的 GPU组2、Node 2 的 GPU组3、Node 3 的 GPU组1 同时执行并行广播。
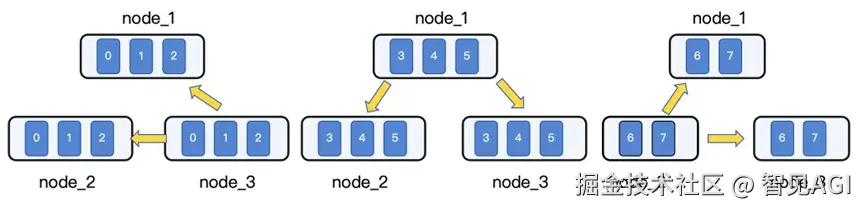
○第三轮: Node 1 的 GPU组3、Node 2 的 GPU组1、Node 3 的 GPU组2 同时执行并行广播。
4
节点间的通信优化:从 Broadcast 迁移至 Ring All-Gather
All-Gather 是一种"多对多"(many-to-all)的集合通信,其目标是让组内的每个进程都获得所有其他进程的数据。操作完成后,每个进程都拥有一个由所有进程的初始数据按序拼接(concatenate)而成的完整数据集。基于环状拓扑(Ring)的 All-Gather 是一种高效的实现算法,尤其适用于 GPU 节点内部这种物理连接紧密的场景。它通过将通信负载均匀分布到所有参与的 GPU 和链路上,实现了对带宽的最优利用。
优化措施:将节点内的Broadcast操作替换为Ring All-Gather操作。通过padding 将DP组内每台机器上的hiddenstates padding成相同形状。
Ring All-Gather 算法通过 N-1 个步骤完成这个任务。在每一步中,每个 GPU 都会:
拓扑构建: 首先,将节点内的 N 个 GPU 逻辑上组织成一个环形(Ring)拓扑,每个 GPU 都有一个明确的左邻居(接收源)和右邻居(发送目标)。
分片与迭代: 算法通过 N-1 个步骤完成。在每个步骤中,所有 GPU 同时进行数据的发送和接收。
○数据块 (Chunk): 每个 GPU 最初持有一块独有的数据分片。
○迭代过程: 在第 k 步(1 ≤ k ≤ N-1),每个 GPU 将它在上一步(k-1)从左邻居收到的数据块发送给它的右邻居。在第一步,它发送的是自己的初始数据块。
○数据聚合: 经过 N-1 步后,每个 GPU 都已接收到来自其他所有 N-1 个 GPU 的数据分片。
此时,每个 GPU 都拥有了完整的、由所有分片拼接而成的数据集。Ring 算法的核心优势在于它将通信任务分解为一系列并行的点对点传输,从而能够充分利用 GPU 间的双向互联带宽。在算法的每一步,环上的所有链路都在同时进行数据传输,有效利用了硬件的全部通信能力,能够有效减少通信时间30%。
5
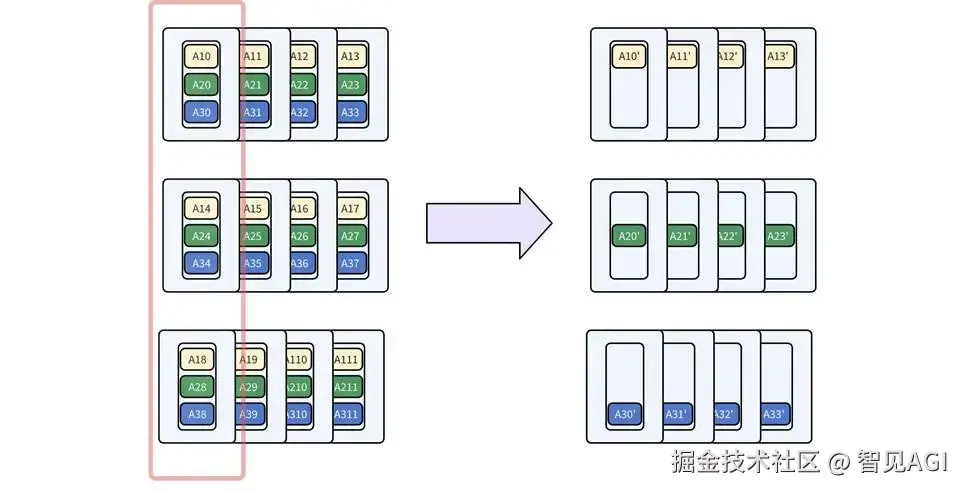
精准分发:从 两次All-Reduce 到 Reduce-Scatter + All-Reduce
在本地专家计算完成后,需要通过全局同步来聚合结果。原始方案采用两次 All-Reduce:首先在数据并行(DP)组内(跨所有节点)进行一次 All-Reduce,然后在每个节点内部再进行一次 All-Reduce。这种方式存在显著的通信冗余:第一次跨节点的All-Reduce将完整的、聚合后的数据 广播给了所有GPU ,但实际上每张GPU在后续计算中仅需要该完整数据的一部分。
我们将冗余的All-Reduce操作分解为一个更高效的两阶段过程:
a.跨节点 Reduce-Scatter: 在DP组内(跨节点),执行Reduce-Scatter操作。此操作会将所有GPU的数据相加(Reduce),然后将结果分割(Scatter),每个节点仅接收其后续计算所需的那一部分结果。这步操作精准地将数据分发到目标节点,避免了在慢速的跨节点链路上进行非必要的数据传输。
b.节点内 All-Reduce: 在每个节点内部,利用高速的节点内网络执行All-Reduce。节点内的每张GPU迅速拼接成节点内规约操作。
通过将一步臃肿的All-Reduce分解为Reduce-Scatter和All-Reduce的精妙组合,我们成功地将通信压力从缓慢的跨节点网络,转移到了高速的节点内部。这种从"全局漫灌"到"按需滴灌"的转变,极大地减少了网络拥塞,是提升大规模MoE模型训练和推理效率、实现极致扩展性的关键所在。
6
混合并行策略:重新规划"分工+协作"
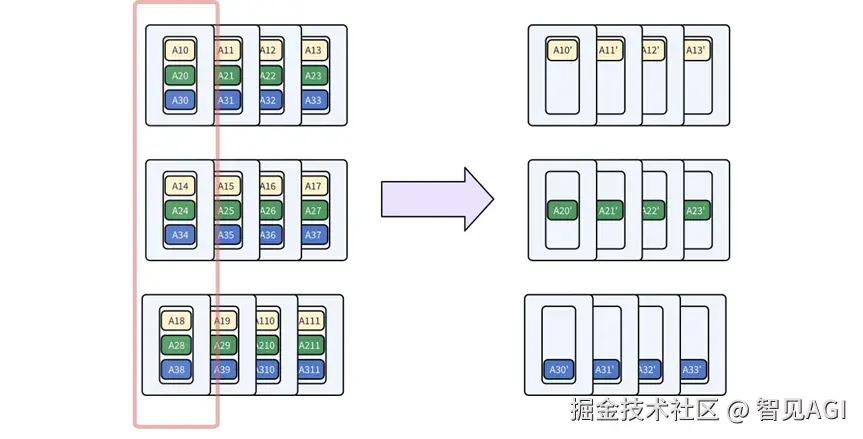
MoE架构虽然强大,但也带来了一个独特的挑战:负载均衡。想象一个拥有256位专家的"智囊团",每个任务(token)只会被派给其中8位专家。如果采用纯粹的专家并行(EP),即把专家分配给不同的GPU,就如同给每个专家指派一位专属助理。这会立刻引发两个问题:首先,热门专家(被频繁激活的专家)的助理会忙得不可开交,而冷门专家的助理则无所事事,导致严重的资源浪费和不同步。其次在vllm当中,当专家数量无法被助理团队(例如3个节点)整除时,任务分配会变得一团糟,进一步加剧了"忙的忙死,闲的闲死"的窘境。
面对这一难题,我们摒弃了简单的"一人盯一摊"模式,开创性地设计了一套"两级分发,内部协作"的混合并行体系:
•第一级(节点间):宏观上的"近似公平"
我们首先在节点之间对256位专家进行近似均匀的划分。比如在3个节点的情况下,我们会分配类似(85, 85, 86)位专家给每个单元,从宏观上确保了每个节点的任务量不会相差悬殊。
•第二级(节点内):微观上的"绝对协作"
在每个节点内部,我们利用张量并行(TP)将节点内的8张GPU变成一个整体高度协同的专家团队。在这套体系下,无论哪位专家接到任务,其计算工作都会被自动分解,由团队内的全部的八张GPU共同承担。这就彻底解决了"专家热门度不均"的问题。无论任务流如何变化,八张GPU始终保持着满负荷的均衡运转,将算力压榨到极致,减缓极端情况下的不同步现象。
最终蓝图: MoE与非MoE层 的 "双轨并行" 这套精密的"专家分发+内部协作"体系完美地解决了MoE层的负载问题。但对于模型中的其他部分,如多头注意力层(MLA),我们则采用了另一套高效策略:数据并行(DP)。
以一个3节点、24卡的集群为例,我们的混合并行策略是这样的:
○张量并行 (TP=8): 首先,我们将每个节点内的8张GPU构建为一个张量并行组。这是我们进行计算分摊的基础单元。
○数据/专家并行 (DP=3 / EP=3): 其次,我们将3个节点(即3个TP组)构建为一个数据并行与专家并行组。这意味着:
▪ 对于 MoE 层,256个路由专家被近乎均匀地划分给这3个节点(EP=3),每个节点负责约85个专家的计算。
▪对于 MLA 层,3个节点作为3个独立的DP副本,各自处理1/3的数据量,并行计算。
MLA层的DP和TP可以组合,一个DP组可以被分成多个TP Rank。MoE层的EP可以与MLA层的DP/TP组合。例如,在24台机器上,EP3 DP3 TP8意味着将路由专家分布在24个GPU上,每8个GPU形成一个DP组,总共3个独立的DP组。
7
计算维度的变化:All To All + All Gather
以注意力机制中的o_proj层为例,权重矩阵被"切"成数片,分发给每个GPU(即TP rank)。每个GPU完成自己那一部分矩阵乘法后,所有GPU需要将各自的计算结果汇总、求和,再广播给彼此,确保每个人都拿到最终的完整答案。这个过程虽然直接,但AllReduce操作就像一个繁忙的交通枢纽,常常成为整个计算流程中最拥堵的瓶颈,大量的通信开销拖慢了AI"思考"的速度。
面对这一瓶颈,我们没有选择常规的修修补补,而是发现了一套精妙的"解法"------一种优雅的数学等价变换。我们的核心洞察是:与其在计算之后费力地"拼凑"结果,不如在计算之前巧妙地"重排"数据。
我们引入了All-to-All操作,它就像一位技艺高超的牌手,在矩阵乘法开始前,就将数据(hidden states)进行了一次精准的洗牌和分发。这个操作将原本分散在各个GPU上的特征维度进行重组,使得每个GPU拿到的是一部分"更完整"的数据片段。
经过这次"预处理"后,奇迹发生了:o_proj层的权重矩阵不再需要被切分!每个GPU都可以独立、完整地进行矩阵乘法,像是在一条互不干扰的专属赛道上全力冲刺。由于不再需要AllReduce这个拥堵的"求和枢纽",各个GPU完成计算后,只需通过一次干净利落的AllGather操作,像拼接乐高积木一样,将各自的成果无缝组合成最终输出。
这场从AllReduce到All-to-All + AllGather的转变,本质上是一次计算维度的"降维打击"。它将原本复杂的通信模式,变成了一次高效的数据重排和一次简单的结果汇集。这就像解决交通拥堵,我们没有拓宽旧的十字路口(优化AllReduce),而是直接修建了一座高效的立交桥(新的通信方案),彻底重塑了数据流动的路径。最终,这套"维度魔法"让我们在保证结果分毫不差的前提下,极大地降低了通信开销,为DeepSeek模型的极速推理铺平了道路。
8
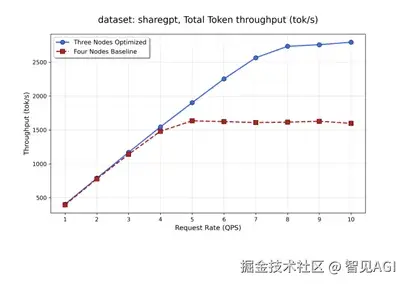
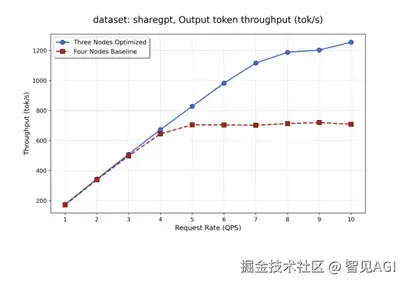
测试结果
测试情况为采用cuda graph条件下num_prompt为600,input长度为512 output为800 ,取完成prefill 进入decode阶段的10s,统计各部如下。
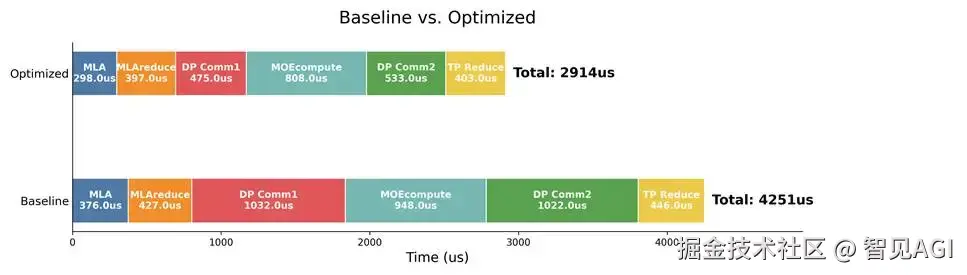
在三节点不同请求速率的测试结果:
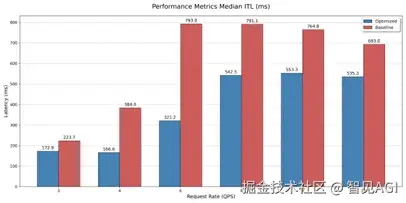
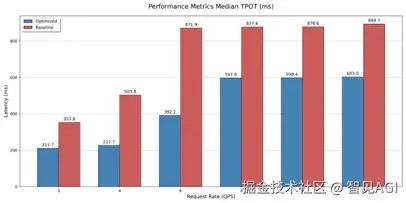
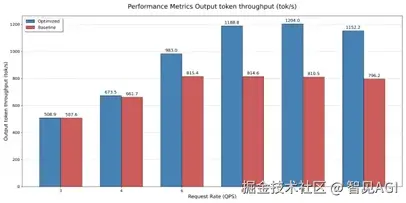
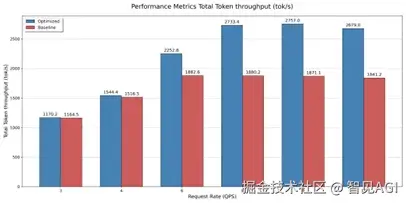
在四节点不同请求速率下的测试结果:
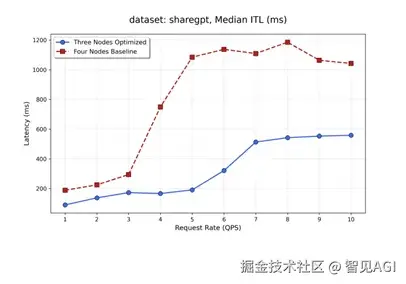
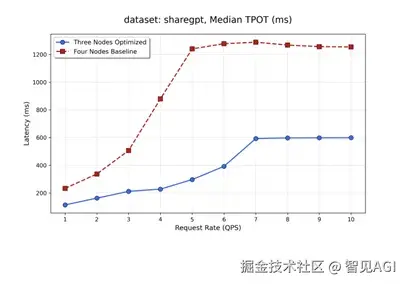
9
总结与展望
本次针对DeepSeek V3.1的优化,验证了我们在通信受限场景下提升超大MoE模型推理性能的有效性,最高100%的提升是我们探索的阶段性成果。
放眼长远,我们清晰地看到,MoE架构的演进正将两个核心矛盾推向台前:专家与Token的"不均衡性"与通信计算的"对称性"之间的冲突。 解决这一矛盾,不仅需要对All-to-All等通信模式进行深度优化,更要求我们在算力调度与资源协同上进行范式级的创新。
直面挑战,我们的目标将是设计一套极致灵活与高效的部署方案,致力于在复杂的约束下最大化释放每一分算力,真正实现资源利用的最优化,推动大模型技术稳步走向应用的深水区。