EMR 发展历程回顾
自 2016 年首次发布以来,阿里云 EMR 始终以开源生态为基石,逐步构建起覆盖 Hadoop、Hive、Spark、StarRocks 等主流开源计算和存储引擎的公有云大数据平台。九年间,EMR 产品技术不仅支撑了阿里巴巴集团内部如淘宝闪购、A+等核心业务的海量数据处理需求,也服务了互联网、金融、零售、制造等众多行业的公有云客户。从最初的开源组件版本和服务管控,到如今面向湖仓一体、实时智能场景的企业级数据平台,EMR 的演进轨迹,本质上是在"开源开放"的基础上向"高效智能"的持续跃迁。 
AI 时代对大数据处理系统的新挑战
随着大模型和生成式 AI 的普及,数据系统的边界正在被重新定义。用户不再满足于编写 SQL 或配置作业,而是期望通过自然语言直接表达分析意图;系统也不再仅处理结构化表格,还需融合流数据、文本、向量、半结构化日志等多模态信息。更重要的是,传统的批处理、OLAP、机器学习、全文检索等能力,正被要求在一个统一平台内协同工作。这种融合趋势对底层架构提出了更高要求:既要极致性能,又要高度自治;既要开放兼容,又要开箱即用。而当前的大数据系统在存算分离架构下面临的元数据风暴、串行 I/O、低效读取等问题,已成为制约 AI 时代数据价值释放的关键瓶颈。
高效:开箱即用,极致性能
面对上述挑战,EMR 将"高效"作为核心突破方向 。我们对 EMR on ECS 产品的 I/O 路径进行了全链路优化,重点解决存算分离架构下的三大性能瓶颈。针对元数据风暴问题,通过批量并发处理机制,将元数据获取时间从分钟级降至秒级;针对计算与 I/O 串行等待,引入向量化异步预取和动态自适应预读策略,使计算与数据加载并行执行;针对小文件和离散列读带来的零散 I/O,实现请求合并与并行预打开,显著提升吞吐能力。实测表明,TPC-DS 1TB 查询开箱性能提升 40%,小文件密集型场景算力节省高达 90%,真正实现"开箱即用"的高性能体验。 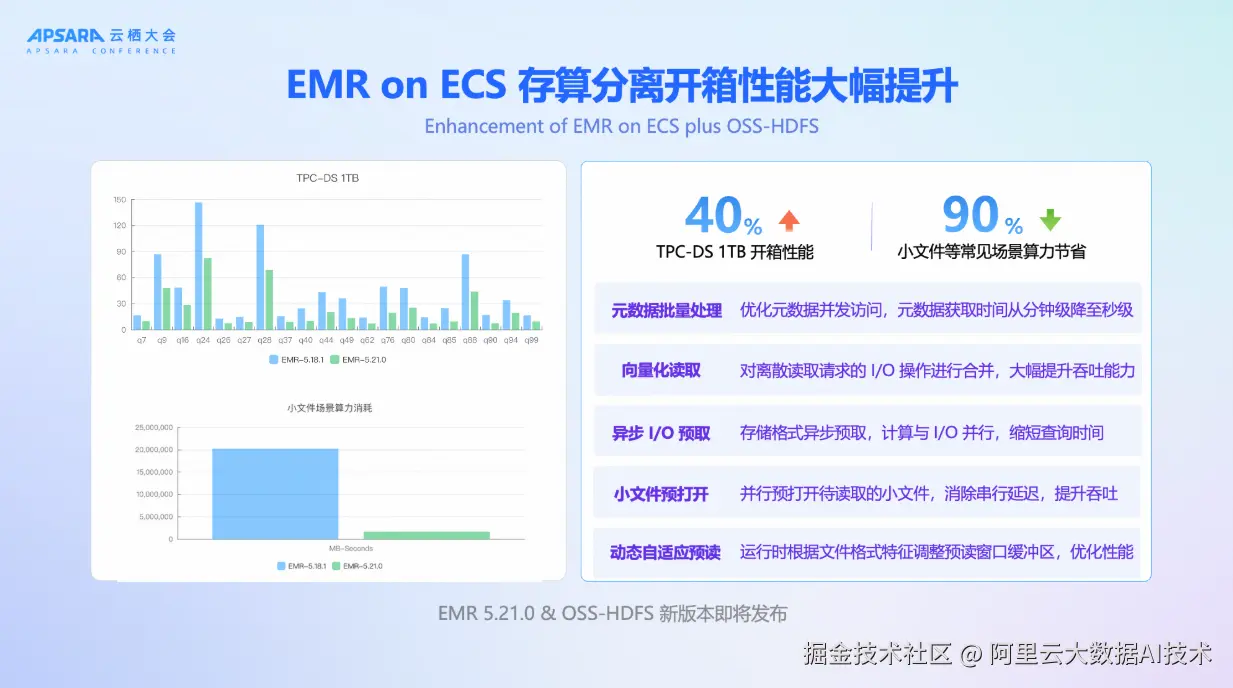
在此基础上,Stella------阿里云自研的企业级 StarRocks 内核正式发布。 Stella 深度协同 DLF 与 Paimon,全面优化湖仓读写路径,内表与湖表查询性能均提升 100%,DV 表查询性能更是提升 300%。在淘宝闪购业务中,系统支撑万级 QPS,查询耗时减少 80%;阿里爱橙业务整体性能提升 150%。尤为突出的是,EMR Serverless StarRocks 凭借 Stella 内核登顶 TPC-H 10TB 世界性能榜单,相较第二名性能提升 111%,性价比提升 90%,数据加载效率提升 6200%。 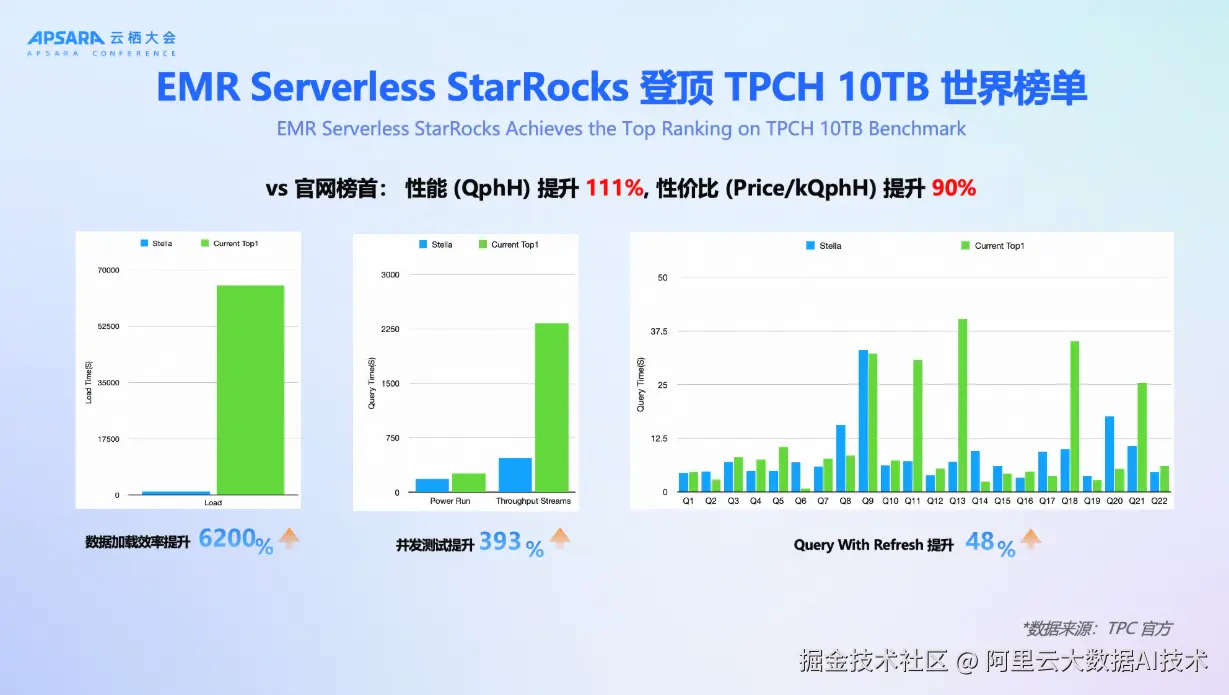
与此同时,Fusion ------企业级 Spark 内核也完成 2.0 版本重大升级。 其向量化算子与表达式覆盖率达 100%,JSON 解析性能提升 78%,Paimon 读写性能翻倍,数据倾斜场景性能提升 10 倍。在 TPC-DS 10TB 测试中,性能领先开源 Spark 高达 500%。更进一步,EMR Serverless Spark 凭借 Fusion 2.0 登顶 TPC-DS 100TB 世界榜单,相较 Databricks 2021 年纪录,性能提升 100%,性价比提升 500%,充分验证了其在超大规模数据湖分析中的领先优势。 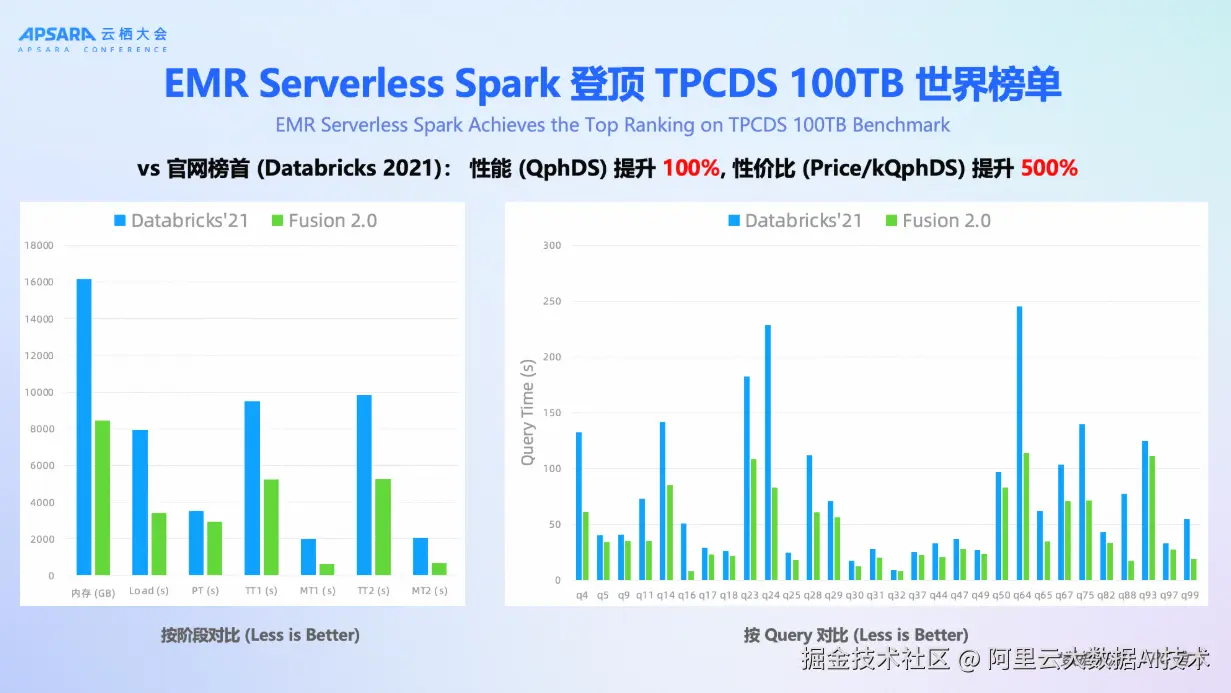
智能:AI 升级,高度自治
如果说"高效"解决了性能问题,那么"智能"则致力于降低使用门槛。**EMR AI 助手正式进入公测阶段,旨在通过自然语言交互简化运维与分析流程。**用户可直接提问"集群为什么变慢了?"或"今天凌晨三点的弹性扩容为什么出现了部分失败的情况",系统将自动分析日志、指标与执行计划,提供精准诊断与修复建议。该助手覆盖EMR on ECS 集群组件异常、资源瓶颈、集群性能等常见问题,支持 7×24 小时自助服务,大幅减少对专业运维人员的依赖。
EMR Serverless StarRocks 智能平台也同步升级,集成健康诊断、业务洞察、事件通知与 AI 中心四大模块。平台不仅提供集群维度的 T+1 全局健康评估,还能实时定位问题组件并给出优化建议;SQL 诊断功能可生成详细 Profiling 报告,辅助用户理解执行瓶颈;业务洞察则将查询延迟、缓存效率等技术指标与业务结果关联,帮助用户量化数据对实际业务的影响。 
EMR AI Function:让 SQL 拥抱大模型
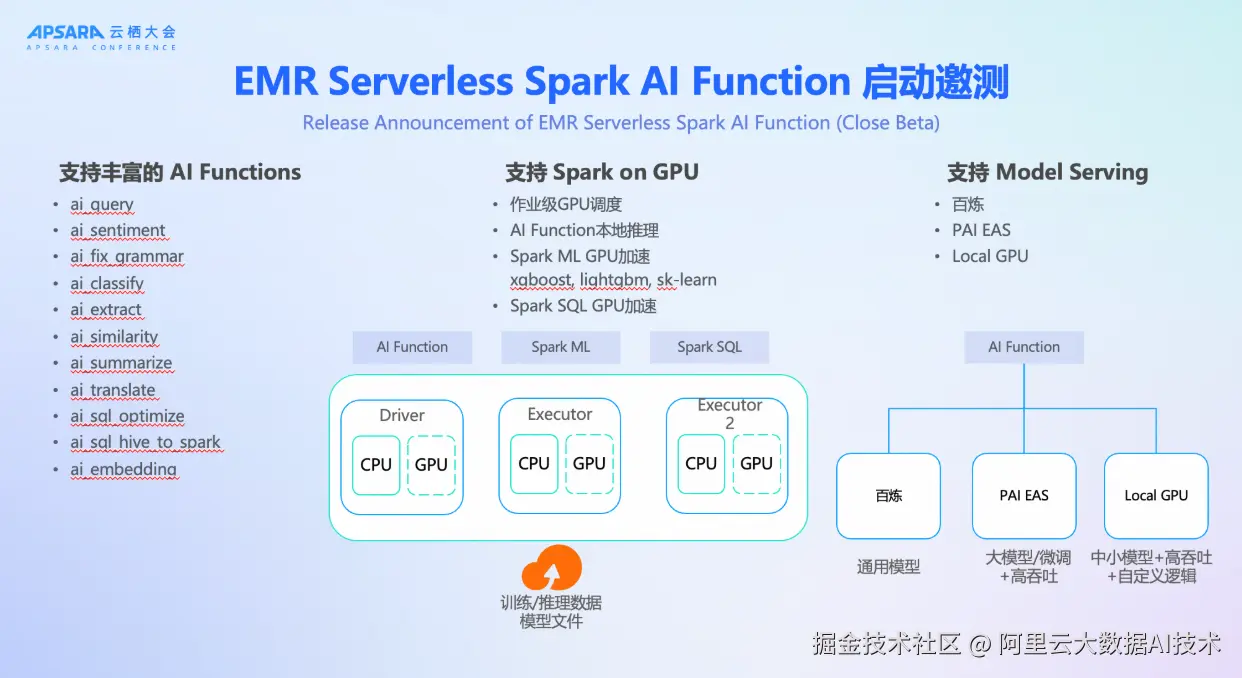
为打通数据分析与 AI 能力的最后一公里,EMR Serverless StarRocks 与 Spark 同步启动 AI Function 邀测。用户可在 SQL 中直接调用大模型函数,实现情感分析、敏感信息脱敏、文本摘要、语言翻译、工单分类等常见任务。
例如,SELECT ai_mask('John Doe lives in New York. His email is john.doe@example.com.', ['person', 'email']) 可自动返回脱敏结果。这些函数默认集成阿里云百炼通用模型,也支持用户接入自定义模型,灵活适配不同场景需求。

EMR Serverless Spark 还全面支持 GPU 调度,实现作业级 GPU 资源分配、AI Function 本地推理、Spark ML(如 XGBoost、LightGBM)与 Spark SQL 的 GPU 加速,并支持对接百炼、PAI EAS 或本地 GPU 模型服务,构建端到端的 AI 数据处理闭环。