RAG是什么?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与文本生成的技术,旨在提升大语言模型在回答专业问题时的准确性和可靠性。
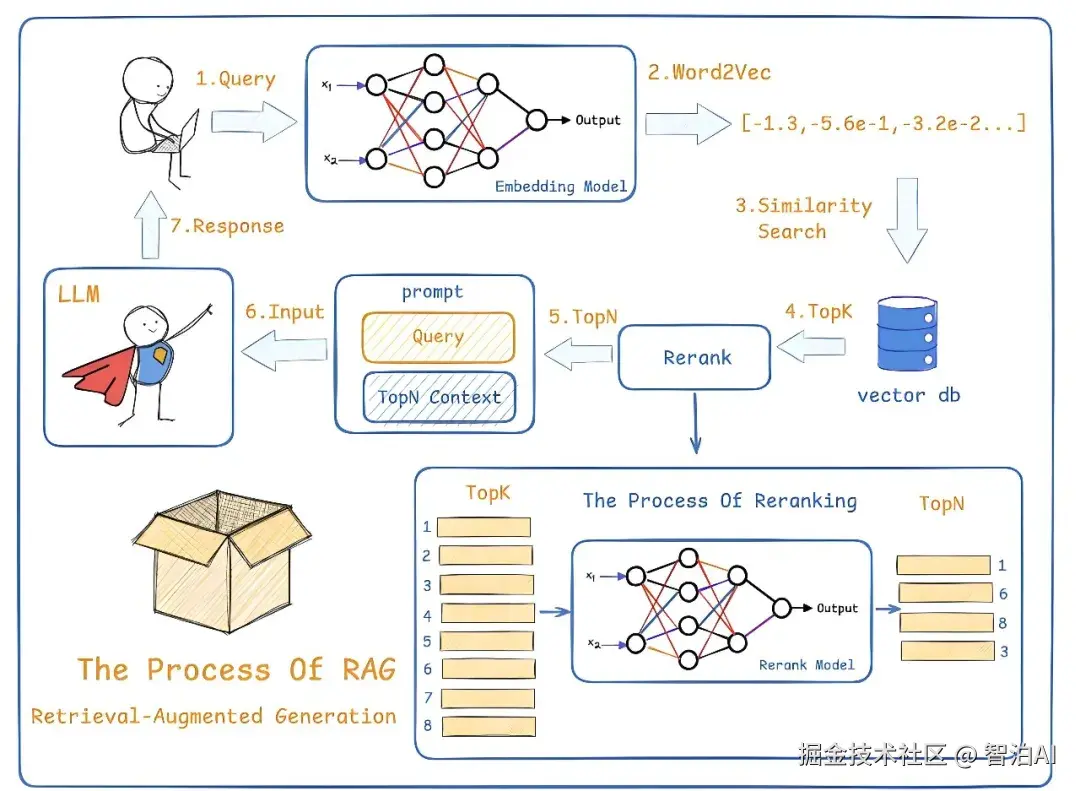
检索增强生成优化大型语言模型(LLM) 的交互方式,让模型根据指定的一组文件回应用户的查询,并使用这些信息增强模型从自身庞大的静态训练数据中提取的信息。检索增强生成技术促使大型语言模型能够使用特定领域或更新后的信息。
文章篇幅有限,不便展示AI大模型全部资源。更多AI大模型学习视频及资源,都在智泊AI。
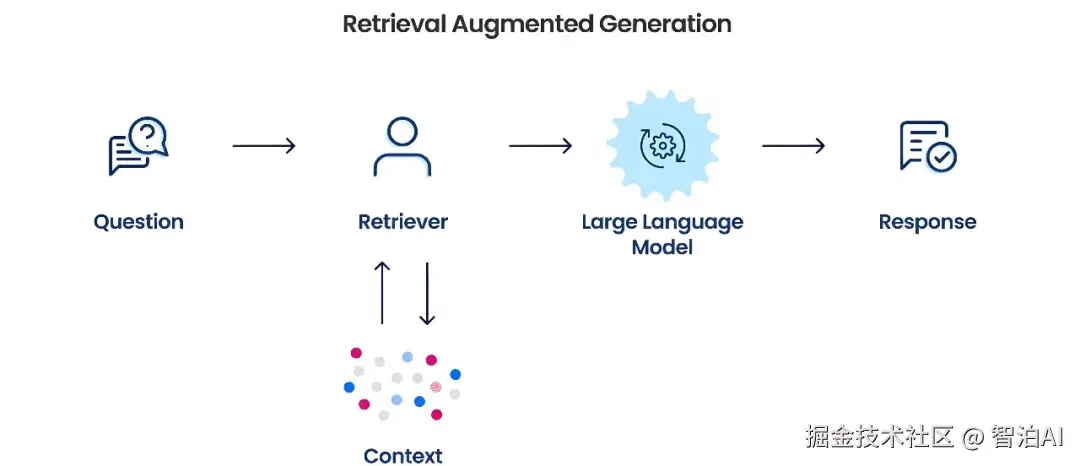
核心原理为 检索 + 生成 两阶段流程 :
检索阶段:将用户的问题转化为向量,从外部知识库或私有文档中(向量数据库)快速检索相关片段。
生成阶段:将检索到的信息输入大模型,生成结合上下文的具体回答。
RAG 过程
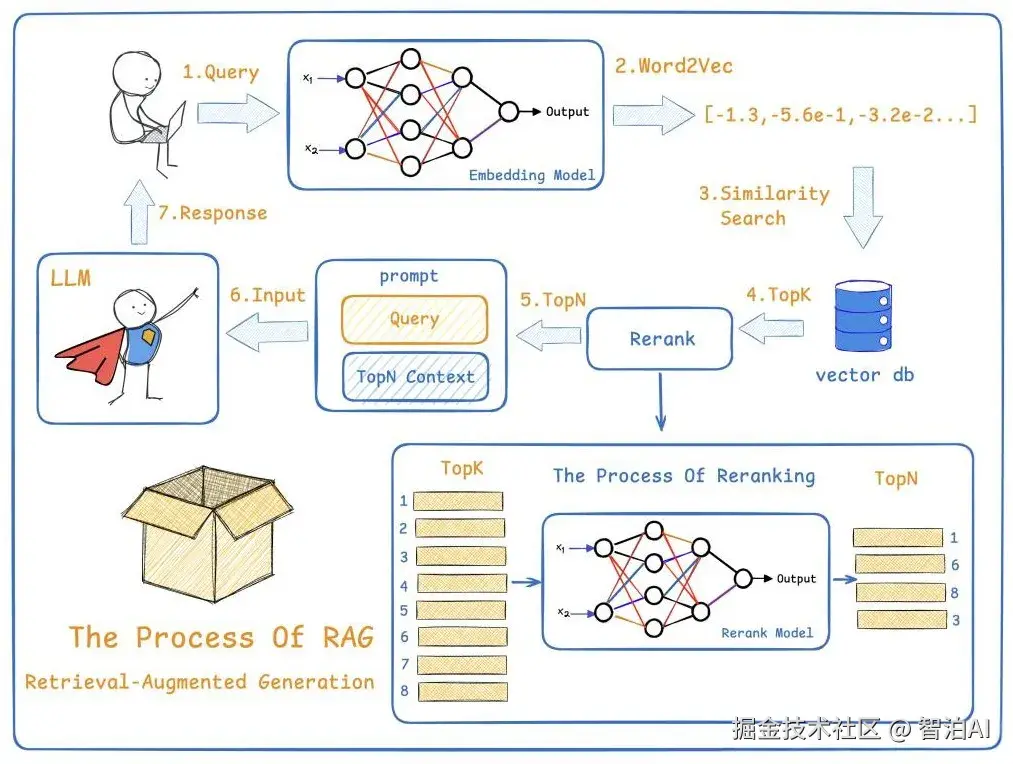
最简单的架构,只包含3个阶段:Indexing -> Retrieval -> Generation.
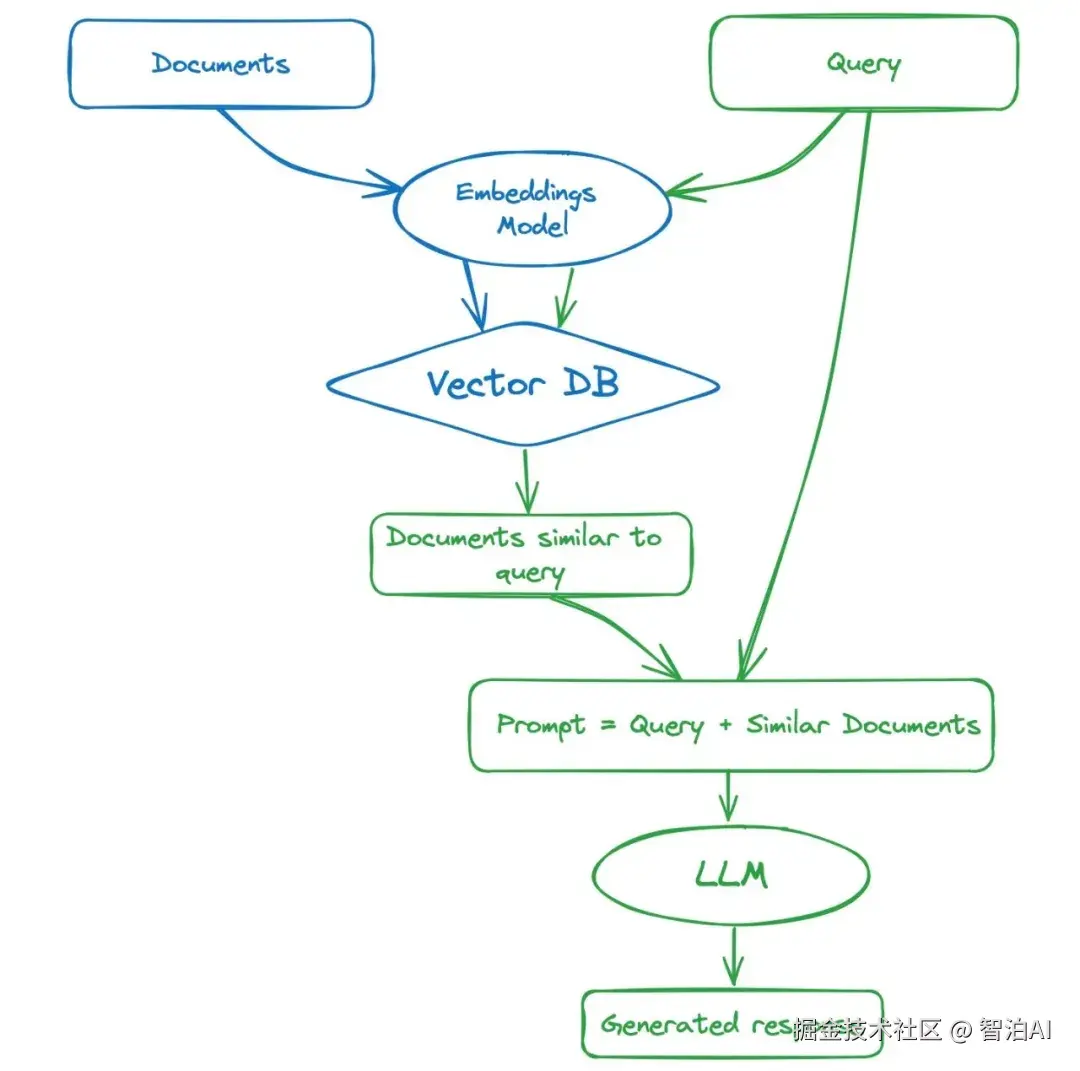
流程
1、索引构建(离线)
数据加载:从各个来源整合数据。
文档切块:按照一定策略切块文档,如固定大小,语义分块等。
向量化与存储:使用Embedding模型(bge系列等)将文档转换成向量,将向量即文档信息存储到向量数据库(腾讯云,Milvus,Faiss)等。
2、在线检索(在线)
检索:使用相同Embedding模型转换用户输入,并从向量数据库检索相似TopK文档(余弦相似度或者欧氏距离)。
生成:将用户输入与检索到的toK文档组织成Prompt,输入LLM生成回答。
关键技术
检索技术
1、混合搜索
目前RAG的Retrieval存在一些弊端,比如召回率低,准确率低,噪声大,存在冗余查询,效率和鲁棒性差等。
因此我们需要Hybrid Search。目前比较通用的混合搜索是三路混合检索:全文搜索 with BM25 + 稠密向量(语义匹配) + 稀疏向量(关键词增强)。
目前的混合搜索架构中,不同的数据存储和检索大都是通过异构数据库和存储介质来实现的,这会带来效率和精准度的问题,因此同时支持多种检索的数据库显得尤为重要,但是有较大挑战,目前市面上实现此类功能的数据库有Milvus(支持多模态向量+标量过滤) , Weaviate(内置混合搜索)。
2、DPR(Dense Passage Retrieval)
在RAG(Retrieval-Augmented Generation,检索增强生成)系统中,DPR(Dense Passage Retrieval,稠密段落检索)是检索模块的核心技术之一。
DPR通过使用密集向量表示来检索与查询最相关的文档或段落,是RAG系统的重要基础。由 Facebook AI Research 团队在2020年首次提出。
DPR是一种基于深度学习的检索方法,专注于将查询(query)和文档(passage)编码为稠密向量,并通过计算向量之间的相似度来检索与查询最相关的文档。
DPR是稠密向量检索在段落检索任务中的一个具体实现,它利用深度学习模型将查询和文档编码为稠密向量,并通过相似度计算来检索相关文档。
重排序 Ranking Models
排名是任何搜索系统的核心。排名涉及两个组件:一个是用于粗过滤的部分也就是粗排;另一个是用于微调阶段的重排序模型也叫重排或者精排。
混合检索能够结合不同检索技术的优势获得更好的召回结果,但在不同检索模式下的查询结果需要进行合并和归一化(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一起提供给大模型。
这时候我们需要引入一个评分系统:重排序模型(Rerank Model)。
重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果。
其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
Multimodal RAG 多模态RAG
目前,多模态检索增强生成(Multimodal RAG) 已成为 RAG 技术中最前沿和流行的方向之一,它通过整合文本、图像、音频、视频等多种模态数据,显著提升了 AI 系统的理解和生成能力。
对于多模态文档,传统方法是使用模型将多模态文档转换为文本,然后再进行索引以供检索。
另一种方法是直接多模态向量化,比如利用 视觉语言模型 VLM,直接生成向量,绕过复杂的 OCR 过程。2024 出现的 ColPali。ColPali 将图像视为 1024 个图像块,并为每个块生成嵌入,有效地将单个图像表示为张量。
如果我们可以使用 RAG 根据用户查询在大量 PDF 中查找包含答案的图像和文本,那么我们就可以使用 VLM 生成最终答案。
这就是多模态 RAG 的意义所在,它不仅仅是简单的图像搜索。检索过程需要一个 Versatile 的数据库,不仅支持基于张量的重新排序,而且还能在向量检索阶段容纳多向量索引。

强化学习
强化学习(Reinforcement Learning, RL)RAG 中的应用并不鲜见。RL能够优化RAG系统的检索策略、查询生成和答案推理过程,可以说,强化学习是 RAG 最好的军师。
Agentic RAG
LLM横行的年代,大多数人言则Agent,事实确实如此,LLM的落地一定是Agent,RAG也不例外。代理和 RAG 之间存在着不可分割的关系,RAG 本身是代理的关键组件,使它们能够访问内部数据。
相反,代理可以增强 RAG 功能,从而产生了所谓的 Agentic RAG,例如 Self RAG 和 Adaptive RAG,因此两者实际上你中有我,我中有你的关系。
这种高级形式的 RAG 允许以受控的方式在更复杂的场景中进行自适应更改。要实现 Agentic RAG,代理框架必须具备"闭环"功能。在 Andrew Ng 的四种代理设计模式中,这种"闭环"能力被称为反射能力。
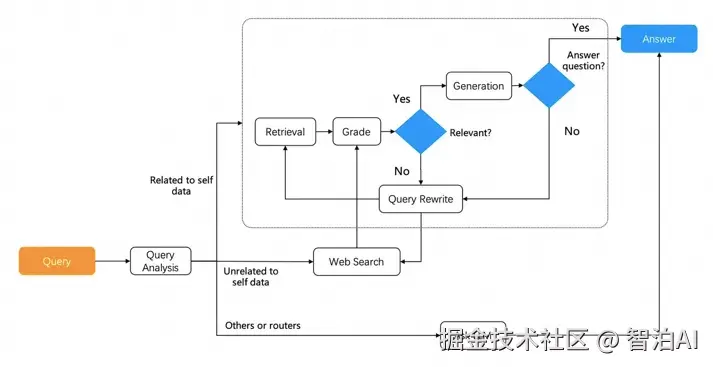
Agentic RAG(基于代理的检索增强生成)代表了RAG技术的最新发展方向,通过将人工智能代理(Agent)的自主规划与决策能力引入传统检索增强生成框架,实现了对复杂查询任务的高效处理。
文章篇幅有限,不便展示AI大模型全部资源。更多AI大模型学习视频及资源,都在智泊AI。