本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。
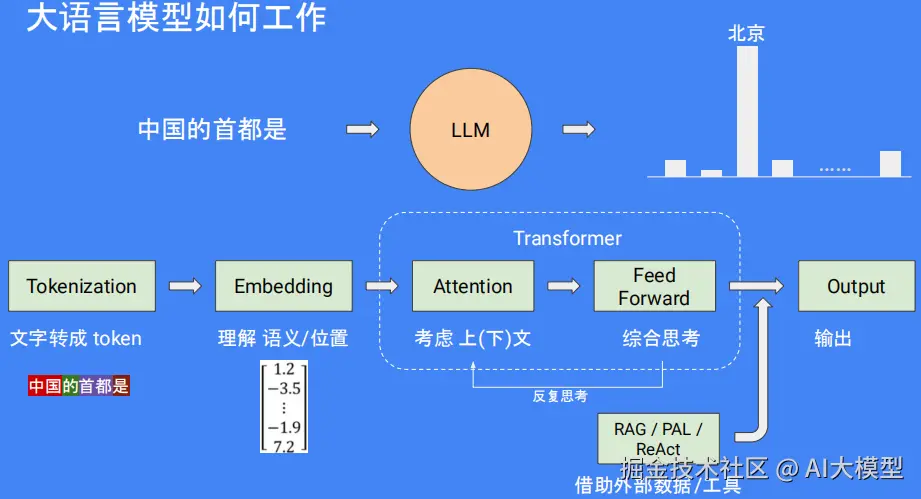
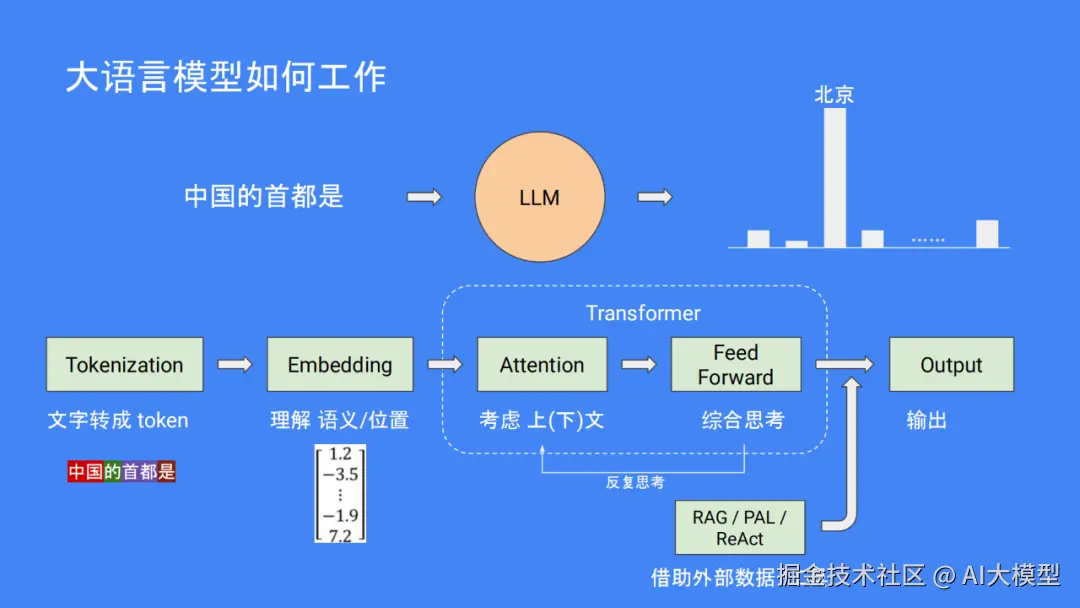
大语言模型(LLM),是一种能够理解并生成我们日常使用的语言的 AI工具。例如,如果你问中国首都的名字是什么?它的核心是通过大量的文本数据来"学"懂语言规则,并且能够预测接下来的单词和句子应该是什么,如"中国首都是北京。"

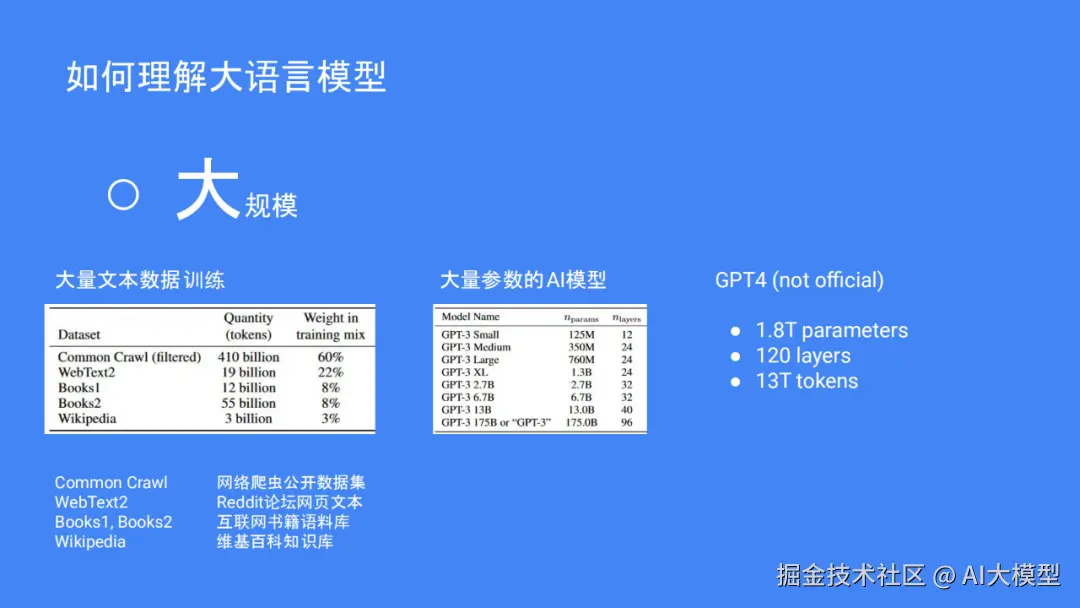
在了解 LLM之前,我们必须了解其"大"之处。一方面,训练数据量很大,主要是使用 Common Crawl网的过滤数据,仅此一项就占据了60%的训练数据,达到4100多亿次;然后是 Reddit论坛的WebText2,Books1和Books2两个在线图书收藏网站,还有维基百科,所有这些加在一起的数据是非常巨大的。另一方面,模型的参数较多,如GPT-3,参数最小为1250万,参数最大为1750亿,共96层;非官方的消息称GPT-4更加夸张,其参数多到1.8兆字节,120个层次,并且学习了13兆个单词。而且,由于是基于自然语言处理的方法,所以非常符合人的语言逻辑。
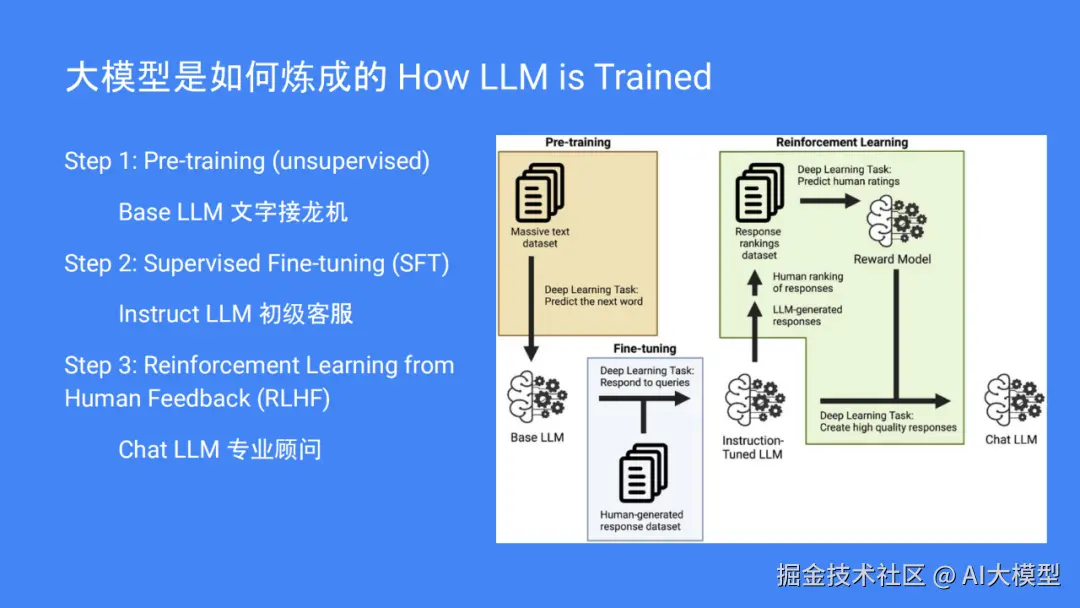
训练LLM有3个步骤。第一阶段是非监督式的预训练阶段,将大量的文本输入到模型中,先进行"文字接龙"的练习,其核心是猜测接下来的单词;第二步就是进行有监控的微调,训练机器人使用人工编写的答案来准确地回答用户的提问,就像一个初级客户服务人员一样;第三步就是通过人的反馈进行强化学习,按照人们对模型的响应等级来训练激励模型,最终将该模型完善为一名专业的咨询师。
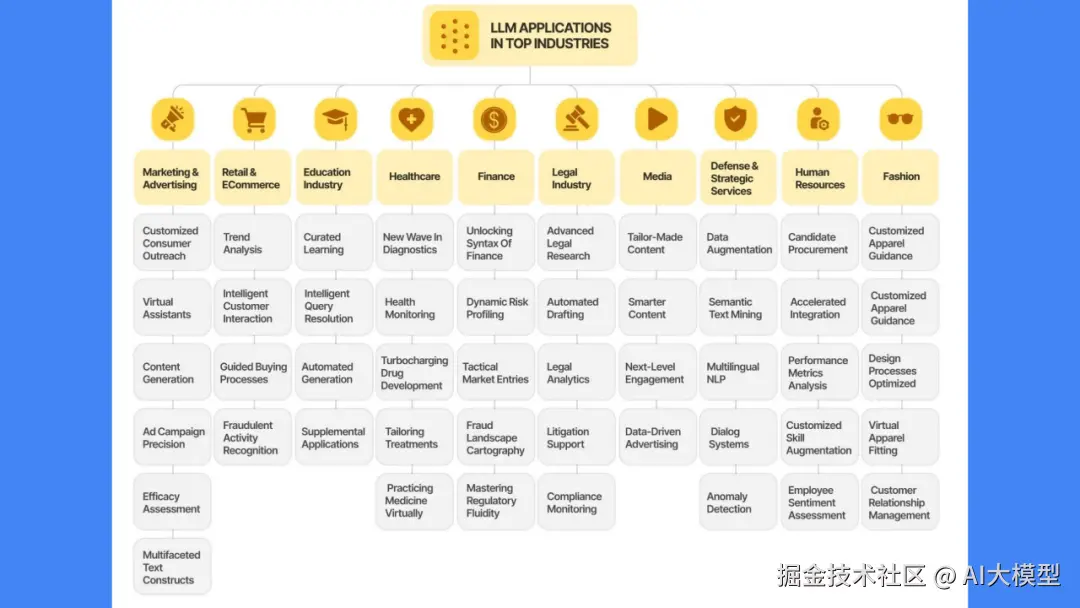
真正使用起来,LLM可以完成很多事情。基本功能包括编写内容,回答知识库中的问题,对文本进行分类,对文本进行情感分析,以及辅助检索,保证电脑安全等。在产业上也有广泛应用,比如广告业可以用它进行精准投放,教育界可以进行个性化教学,医学界可以用它进行辅助诊断,金融界可以用它进行动态风险监控。
如果你想尝试自己部署,可以使用谷歌标签。Llama3.1是 Meta在去年的4个月开放的一个模型,虽然95%的训练数据都是用英文的,但是 Llama3.1有很多版本。再使用开放源码的 LLM开发平台 Ollama,流程也不是很复杂,打开 Colab,选择 GPU支持的环境、安装 Ollama、下载 Llama3.1、运行 Lllama3.1,然后就可以和模型进行交互。如果硬件不够好,也可以尝试在本地部署或与 ngrok一起进行远程接入。
然而,使用 LLM需要考虑一些道德上的因素,例如保护数据隐私,避免产生虚假信息,降低模型偏差,以及 LLM的能源消耗并不小,会对环境造成一定的影响。未来, LLM将朝着多模式、强逻辑推理(OpenAIo1)、自治模型的方向前进,并且将更加有效地进行个性化的微调,更加密切地与人类进行合作,并且将逐渐完善相关的道德规范。












如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。