文章目录
- 前言
- 一、混合注意力模型中"为什么要缓存这么多东西?"
-
- [1.1 为什么 S&Conv 也需要缓存?](#1.1 为什么 S&Conv 也需要缓存?)
- [1.2 为什么 S&Conv 是固定大小的,不会随着序列增长?](#1.2 为什么 S&Conv 是固定大小的,不会随着序列增长?)
- [1.3 为什么说 S&Conv 是跨 token 的?](#1.3 为什么说 S&Conv 是跨 token 的?)
- [1.4 "每个请求"是什么意思?](#1.4 “每个请求”是什么意思?)
- [二、推理框架(vLLM/SGLang)如何管理传统 KV Cache?](#二、推理框架(vLLM/SGLang)如何管理传统 KV Cache?)
-
- [2.1 逻辑层(logical layer)](#2.1 逻辑层(logical layer))
- [2.2 物理层(physical layer)](#2.2 物理层(physical layer))
- [三、混合注意力到来:S&Conv Cache 如何管理?](#三、混合注意力到来:S&Conv Cache 如何管理?)
-
- [3.1 两个设计原则](#3.1 两个设计原则)
- [3.2 S&Conv 数据如何存放?(两种设计)](#3.2 S&Conv 数据如何存放?(两种设计))
- [3.3 KV Cache vs S&Conv Cache:什么时候哪个更省?](#3.3 KV Cache vs S&Conv Cache:什么时候哪个更省?)
- 四、总结
- 参考
前言
近年来,大模型结构快速演进,从传统自注意力(Standard Attention)走向更高效的混合注意力(Hybrid Attention)。例如:
- Qwen3-Next 引入 GDN(线性注意力)
- Kimi-Linear 引入 KDA(线性注意力)
- Mamba/S4 系列引入 SSM(状态空间模型)
这些结构都在部分层中保留传统注意力(GQA/MLA),并与线性注意力模块混合组成 Hybrid Attention。
然而,这种结构的引入,也给推理框架(如 vLLM / SGLang)带来了一个全新的系统挑战:
不仅需要传统的 KV Cache,还需要为线性注意力提供 S&Conv 状态缓存。
如何统一、兼容、高效地管理两类缓存?
本文将从模型原理、缓存需求、本次对话中的关键问题、推理系统设计、工程挑战等方面,为你构建一个清晰的完整体系。
一、混合注意力模型中"为什么要缓存这么多东西?"
在标准注意力中,你只需要缓存两样东西:
- K:Key
- V:Value
推理时为了避免重复计算,需要将所有历史 token 的 K/V 存起来,这就是 KV Cache。
但在线性注意力与 SSM 模块中,注意力结构发生变化:
(传统) Attention 依赖所有历史 K/V
(线性 Attention / SSM) 依赖内部的递推状态 S、局部卷积状态 Conv因此模型除了 KV Cache 外,还需要管理:
- S:递推状态(SSM 类结构的状态 S t S_t St)
- Conv:短卷积(depthwise conv)的历史窗口输入
这两个合称为 S&Conv Cache。
1.1 为什么 S&Conv 也需要缓存?
因为线性注意力依赖"之前的 token 状态"
例如 GDN、KDA 采用如下递推公式:
S t = f ( S t − 1 , x t ) S_t = f(S_{t-1}, x_t) St=f(St−1,xt)
意味着:
- 当前状态 必须依赖前一个状态
- 新 token 想要快速预测 → 必须要保存 S t − 1 S_{t-1} St−1
短卷积 Conv 也一样:
- 需要"最近固定个数的 token 的隐状态"
- 不缓存就必须回头重新计算整个序列 → 极度低效
因此,S&Conv 就像 KV Cache 一样,必须缓存起来用于增量推理(incremental decoding)。
1.2 为什么 S&Conv 是固定大小的,不会随着序列增长?
线性注意力与 SSM 的关键特性是:
只依赖固定窗口的历史信息,而不是所有历史 token。
例如:
- Conv 只需要最近 4~8 个 token 的 hidden states
- SSM 状态维度是固定的(例如 512 或 1024)
因此:
S&Conv Cache Size = O ( 1 ) \text{S\&Conv Cache Size} = O(1) S&Conv Cache Size=O(1)
与 KV Cache 完全不同:
| 缓存类型 | 是否随序列增长? |
|---|---|
| KV Cache | ✔ 是,O(n) |
| S&Conv Cache | ❌ 否,固定大小 |
这是混合注意力缓存管理的第一个关键差异。
1.3 为什么说 S&Conv 是跨 token 的?
- S(递推状态)必须从 S t − 1 S_{t-1} St−1 推断
- Conv 必须包含前几个 token 的 hidden state
- 这些状态必须连续跨 token 保存
如果不跨 token 缓存这些状态,就无法实现增量推理,只能重新计算整个序列。
1.4 "每个请求"是什么意思?
推理框架并不是按 token 维度管理缓存,而是按 请求 request 管理。
例如:
Prompt → 模型生成 300 token 的回答这个完整过程 = 一个 request。
在一个 request 内:
- 每生成一个 token → 会读写 S&Conv Cache / KV Cache
- request 结束 → 缓存整个释放
因此:
- token 是使用粒度(每 token 用一次)
- request 是管理粒度(整个请求一份状态)
二、推理框架(vLLM/SGLang)如何管理传统 KV Cache?
vLLM 提出了著名的 Paged Attention 机制(类似操作系统中的虚拟内存管理中的分页技术):
结构分两层:
2.1 逻辑层(logical layer)
- 由调度器(scheduler)管理 block 的使用情况
- 使用"页表"映射至物理内存
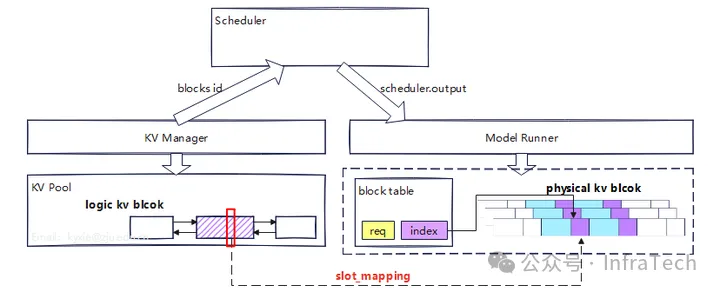
2.2 物理层(physical layer)
- KV Cache 按照 layer 分配
- 所有请求共享页(page)
常见的模块是MQA和MLA,虽然其页的分配存在差异,但block使用方式相同。
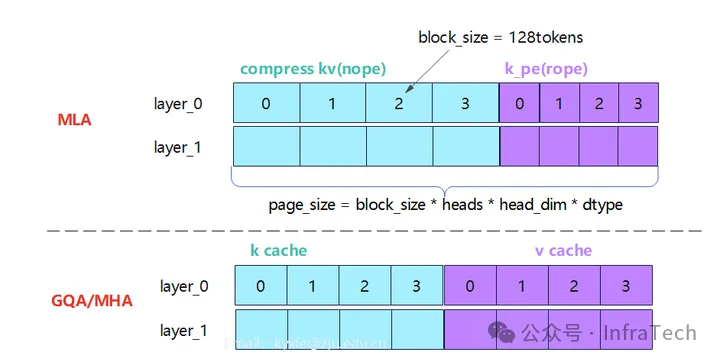
这是现代推理框架的基础设施。
三、混合注意力到来:S&Conv Cache 如何管理?
3.1 两个设计原则
原则 1:不要创建新的缓存系统
否则框架复杂度爆炸,所以:
S&Conv Cache 必须与 KV Cache 使用同一套管理机制。
原则 2:尽量让 S&Conv 与 KV Cache 的 page 大小一致
为了统一框架调度:
- 将 S&Conv 的 block 大小对齐到 KV 的 page 大小
- 必要时 padding 补齐
- 使得两类缓存都能"分页管理"
这就是文章中"让框架对两种缓存一致化处理"的核心思想。
3.2 S&Conv 数据如何存放?(两种设计)
两种排布方式
方案 A:按层独立(Layer-wise)
对于单个请求,每一层一个 block,例如:
request 1:
layer1 → S&Conv block
layer2 → S&Conv block
layer3 → S&Conv block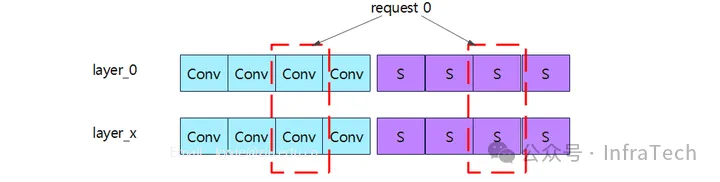
优点:简单
缺点:块多、不连续、Cache 管理复杂
方案 B:按请求独立(Request-wise)
一个 request 所有 S&Conv 放入一块连续内存中:
[S1 | Conv1 | S2 | Conv2 | S3 | Conv3 | ...]
优点:
- 内存访问连续,高效
- 页表更简单
- 更适用于加速算子(如 FlashAttention)
- 更容易扩展
目前 vLLM/SGLang 逐步采用该方案。
3.3 KV Cache vs S&Conv Cache:什么时候哪个更省?
S&Conv Cache 只有在序列足够长时才比 KV Cache 更省显存/带宽。
两者大小变化趋势:
- KV Cache → 随 token 线性增长
- S&Conv → 固定大小
因此出现一个交汇点:
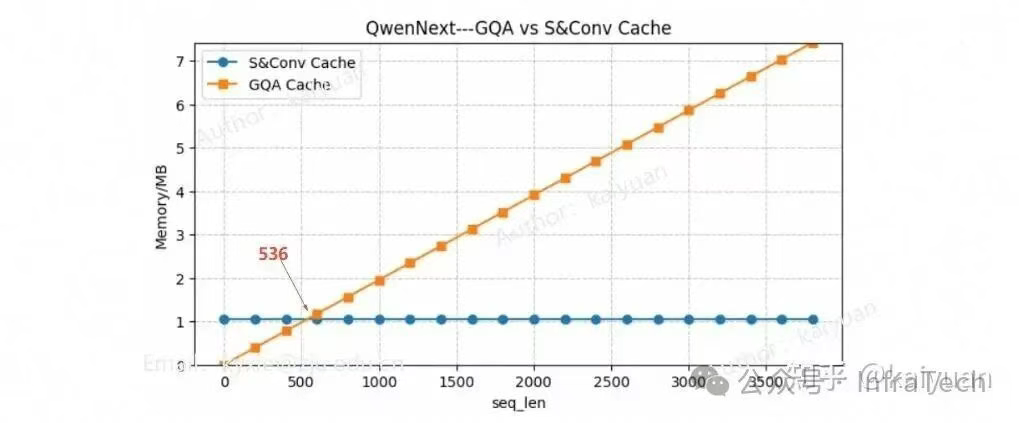
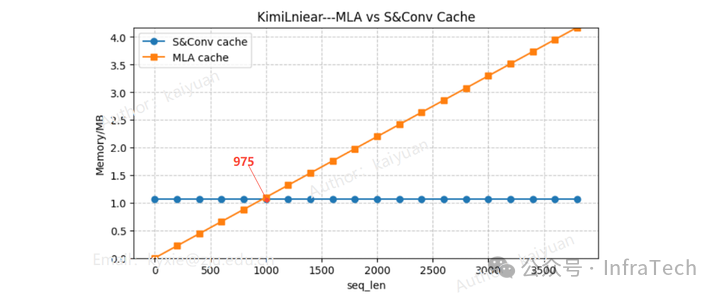
| 模型 | 序列长度交汇点 |
|---|---|
| Qwen3-Next-80B | ~536 tokens |
| Kimi-Linear-48B | ~975 tokens |
这意味着:
- prompt 短 → KV Cache 更省
- prompt 长 → 线性注意力更省
这一点对框架设计和模型选择非常关键。
四、总结
混合注意力的到来,让推理框架的缓存系统必须同时管理:
- O(n) 增长的 KV Cache
- 固定大小的 S&Conv Cache
文章给出的解决方案是:
用相同页面大小(page size)、相同分配逻辑、相同调度机制统一管理两类缓存。
这样做可以:
- 大幅减少框架复杂度
- 更好支持 Hybrid Attention
- 支持 FlashAttention、Speculative 等功能
- 支持未来更多 SSM/linear attn 结构
这是推理框架走向适配下一代模型架构的关键一步。