一、OCR 重回 C 位:大模型的"关键感知器"
这两天技术圈又炸了------DeepSeek 又双叒发布新模型,这次还带了个看似"熟悉"的技术关键词:DeepSeek-"OCR"。
如果最近有在关注视觉理解方向的朋友,会发现一个有趣的现象:整个 OCR 赛道突然热了起来。
近一个月内,DeepSeek、百度、上海 AI Lab 等团队几乎在同一时间抛出自家的新一代 OCR 模型,10 月 21 日,HuggingFace 全球模型趋势榜前三名全部被 OCR 模型包揽,一时间,"OCR" 成了新的技术高地。
其中,尤其引人注目的是,百度飞桨团队开源的 PaddleOCR-VL 模型持续登顶 Trending 榜首(连续5天登顶HF trending第一;同时登陆Modelscope trending全球第一;HuggingPaper Trending 全球第一;GitHub Python 总榜第3、全球总榜第9),成为当前全球开发者最关注的 OCR 系统之一。

PaddleOCR-VL 和 DeepSeek-OCR,虽然都是围绕着 OCR,细致了解之后,才发现他们原来大一不一样,本篇一起来看看两者侧重,以及讨论为什么大模型背景下 OCR 有着如此重要的地位?
二、PaddleOCR-VL 意在"精准识别",DeepSeek 意在"文本压缩",
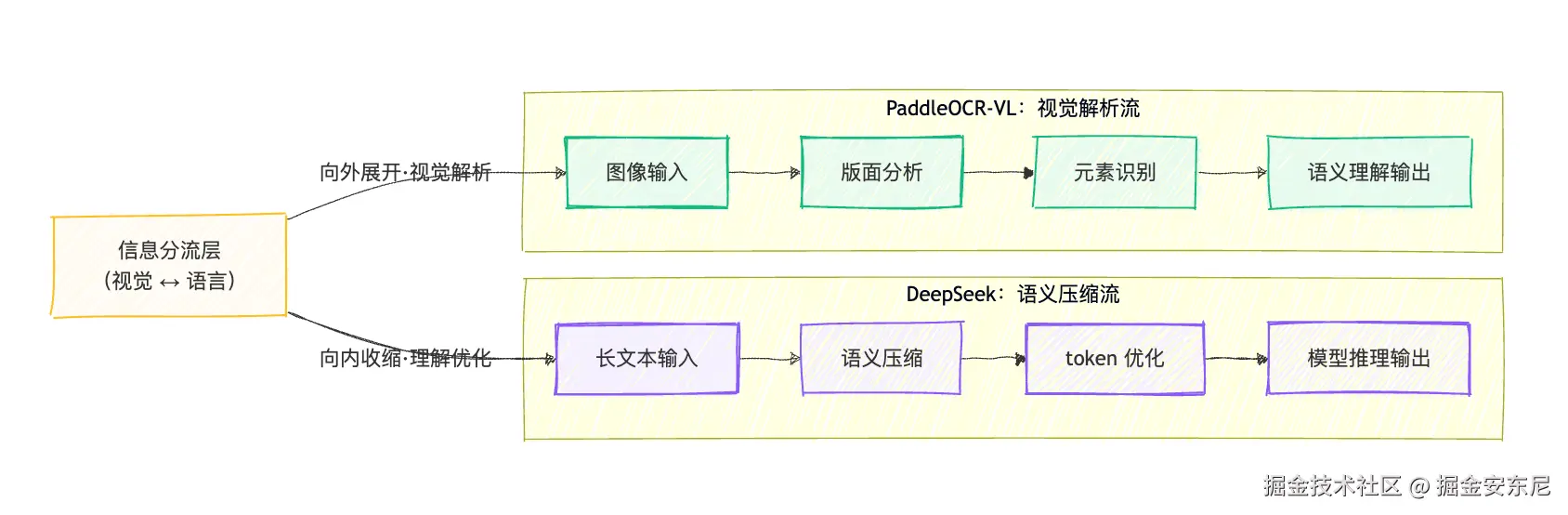
简单概括来说,DeepSeek 的目标,是压缩。 它想解决的,是大模型在处理长文本时的"语义冗余"问题------上下文太长、token 太多、推理链太杂,最终导致显存爆炸、成本激增。DeepSeek 希望通过"视觉模态压缩"让模型在保持语义连贯的同时,大幅减少输入 token,让它"少看但懂多"。
根据介绍,此次开源的 DeepSeek-OCR 由两个部分组成:核心编码器 DeepEncoder 和解码器 DeepSeek3B-MoE-A570M。DeepEncoder 专为在高分辨率输入下保持低计算激活而设计,同时实现高压缩比,以控制视觉 token 数量在可管理的范围内。
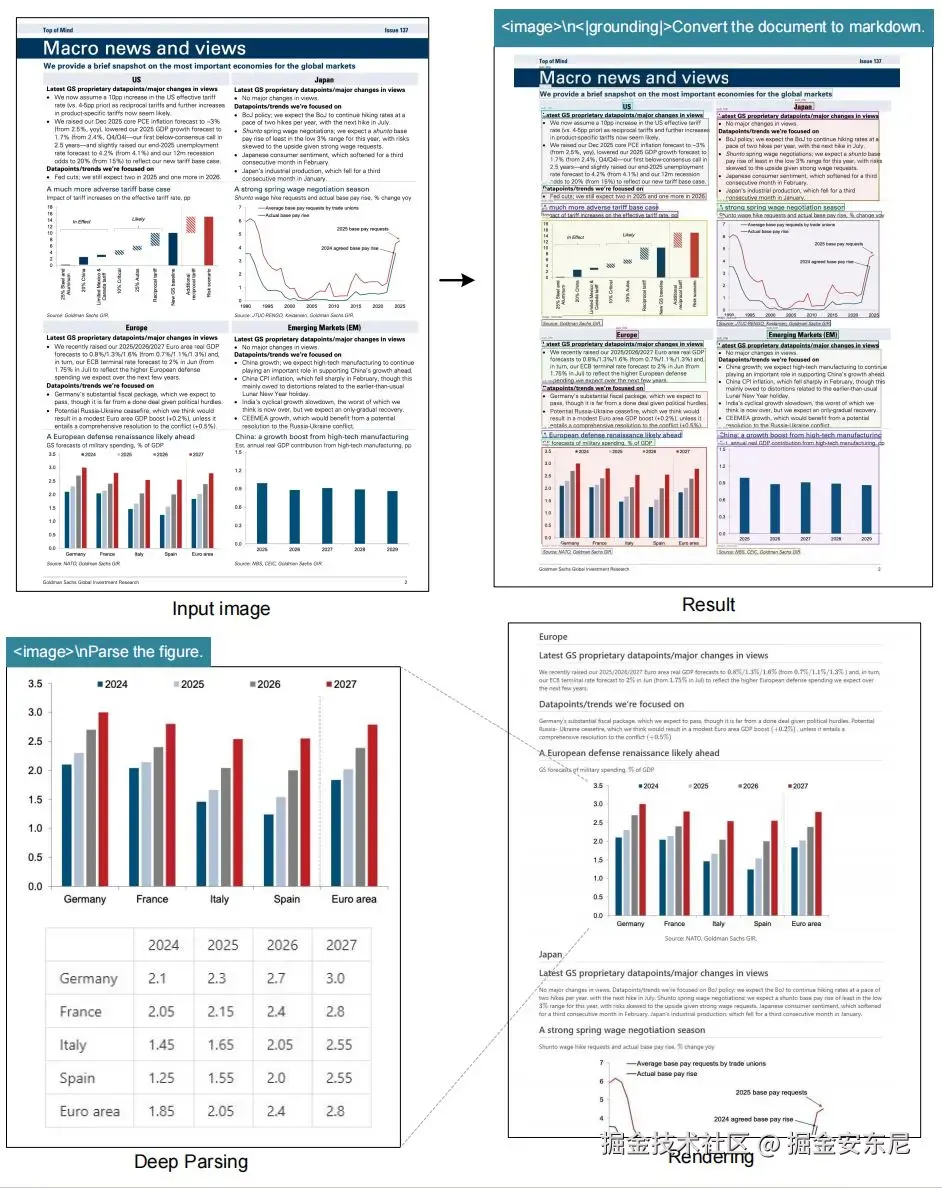
而 PaddleOCR-VL 的目标,则是识别。 它是一种 OCR SOTA方案,作为文心4.5的最强衍生模型,基于ERNIE-4.5-0.3B语言模型训练,参数仅0.9B,却爆发出惊人能量,它在OCR性能和实用产业价值上全球第一。PaddleOCR-VL 追求的是尽可能完整地还原图像视觉世界的信息结构。无论是票据、合同、表格、说明书,还是手写体、扫描件、低光照图片,PaddleOCR-VL 都希望在毫厘之间还原每个文字、表格、段落与版式关系。
PaddleOCR-VL 面对真实世界的各种光照、排版、模糊与噪点,让大模型真正"看清楚"。
现在几乎所有热门应用都离不开 OCR。不管是做 RAG 知识检索、Agent 自动办公,还是像"数字员工"那样去读合同、核对表格,甚至给大模型训练提供高质量语料,都得靠 OCR 打开入口。对于所有大模型来说,如果入口是模糊的、错误的,也只能输出垃圾结论。
我认为,精准且快速的识别是第一步、通过识别压缩降低成本是第二步,虽然我们要节约成本,但结果不能被"压"成幻觉,不然多少有点舍本逐末了。

三、PaddleOCR-VL 轻量又强大:开发者友好的全场景能力
我记得,大模型火热之前,百度的OCR技术就很超前,大家会用"百度识图"来识别"植物"等等,如今,百度的 OCR 技术早已不止是一个简单的"识别模型",而是一整套覆盖多模态感知与语义解析的系统。
第一代 PaddleOCR 已经成熟,很轻量,能在移动端、云端之间灵活部署,支持印刷体、手写体、多语种、票据、证件、表格等多种场景。并且它设计的相关生态也很完备,从最底层的 PP-OCR 文本检测与识别,到 PP-Structure 的版面结构分析,再到面向文档解析的完整链路,几乎覆盖了 OCR 的全生命周期。
现在,PaddleOCR 的进化版本 ------ PaddleOCR-VL,不再满足于识别字符,而是试图理解图像中的语义关系与空间结构。基于百度的 ERNIE-4.5-0.3B 模型训练,总参数量仅 0.9B,却具备解析复杂文档布局、表格结构、数学公式甚至阅读顺序的能力。
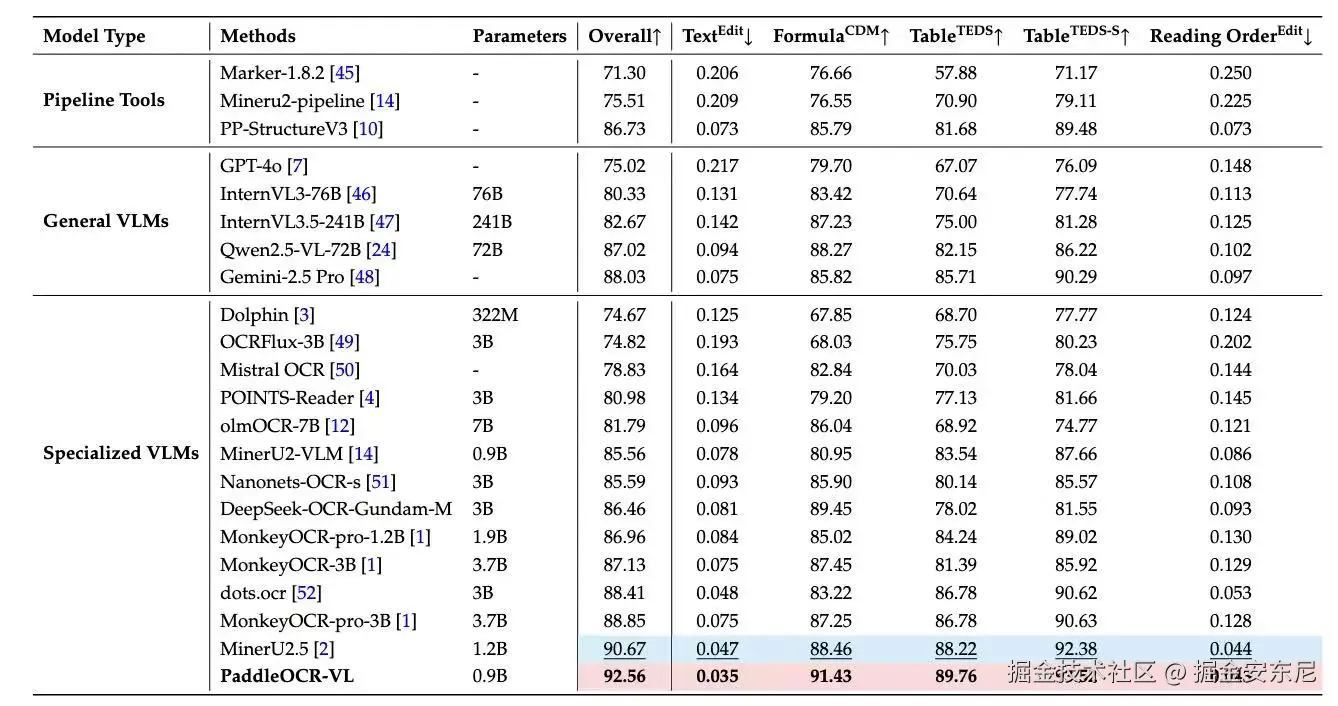
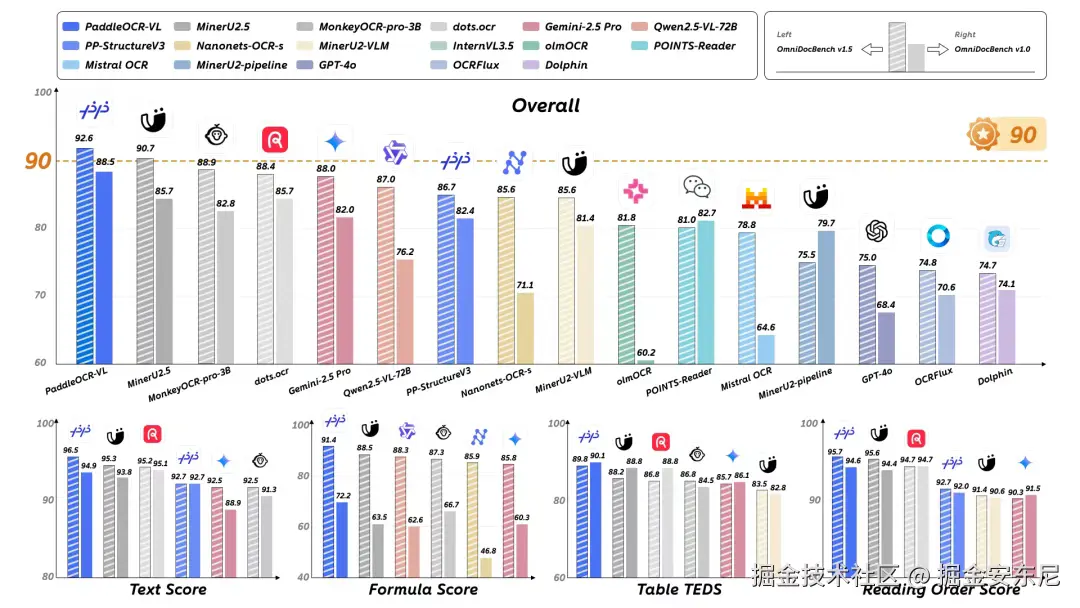
在权威评测基准 OmniBenchDoc V1.5 中,PaddleOCR-VL 以 92.56 分 的综合成绩刷新全球纪录:
- 📊 综合性能第一 :超越 DeepSeek-OCR-Gundam-M(3B)约 6 分;
- 📑 表格理解领先 :在表格结构理解(TEDS)与语义理解(TEDS-S)上分别领先 15.5 分 与 9.9 分;
- 🧩 阅读顺序更准 :编辑误差降低 54% ,符合人类逻辑;
- ⚡ 极致轻量化:仅 0.9B 参数,在文本、公式、表格、结构理解四大核心任务上实现全线 SOTA。
四、实测:PaddleOCR-VL 看"事实"
光看参数和榜单不如上手测试来得直接。我们用几个真实场景,让你直观感受 PaddleOCR-VL 与 DeepSeek-OCR 的差异。
- PaddleOCR-VL :aistudio.baidu.com/application...
- DeepSeek-OCR :huggingface.co/spaces/axii...
1、表格识别
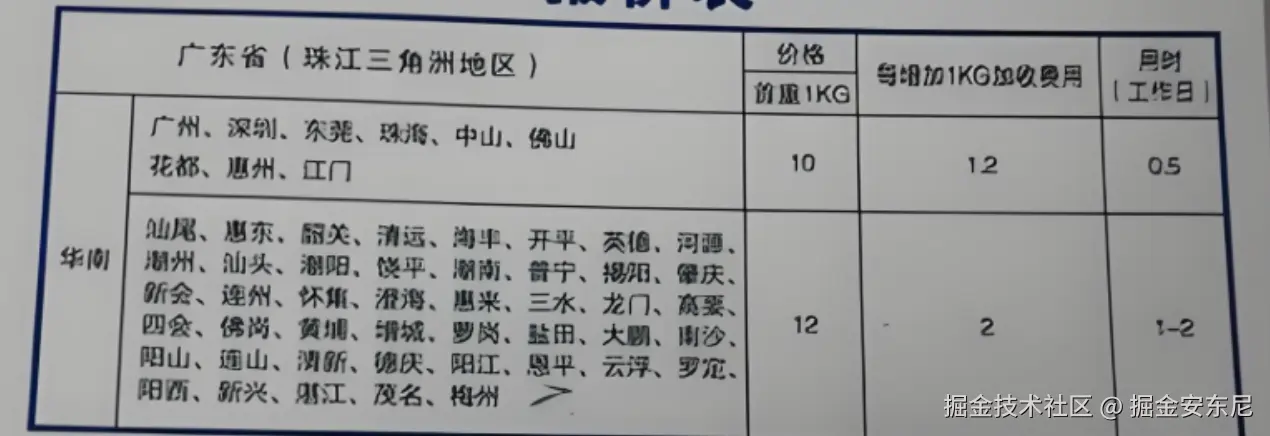
DeepSeek-OCR:

PaddleOCR-VL:
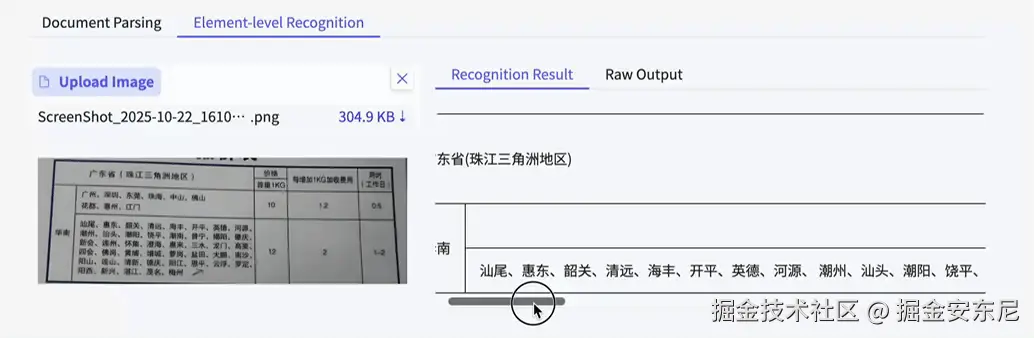
对于复杂表格的识别来说,Deepseek-OCR能识别出文字,但莫名其妙多了一列空列,而PaddleOCR-VL 能100%准确识别,太强了!
2、手写识别:谁更忠于原文

DeepSeek:
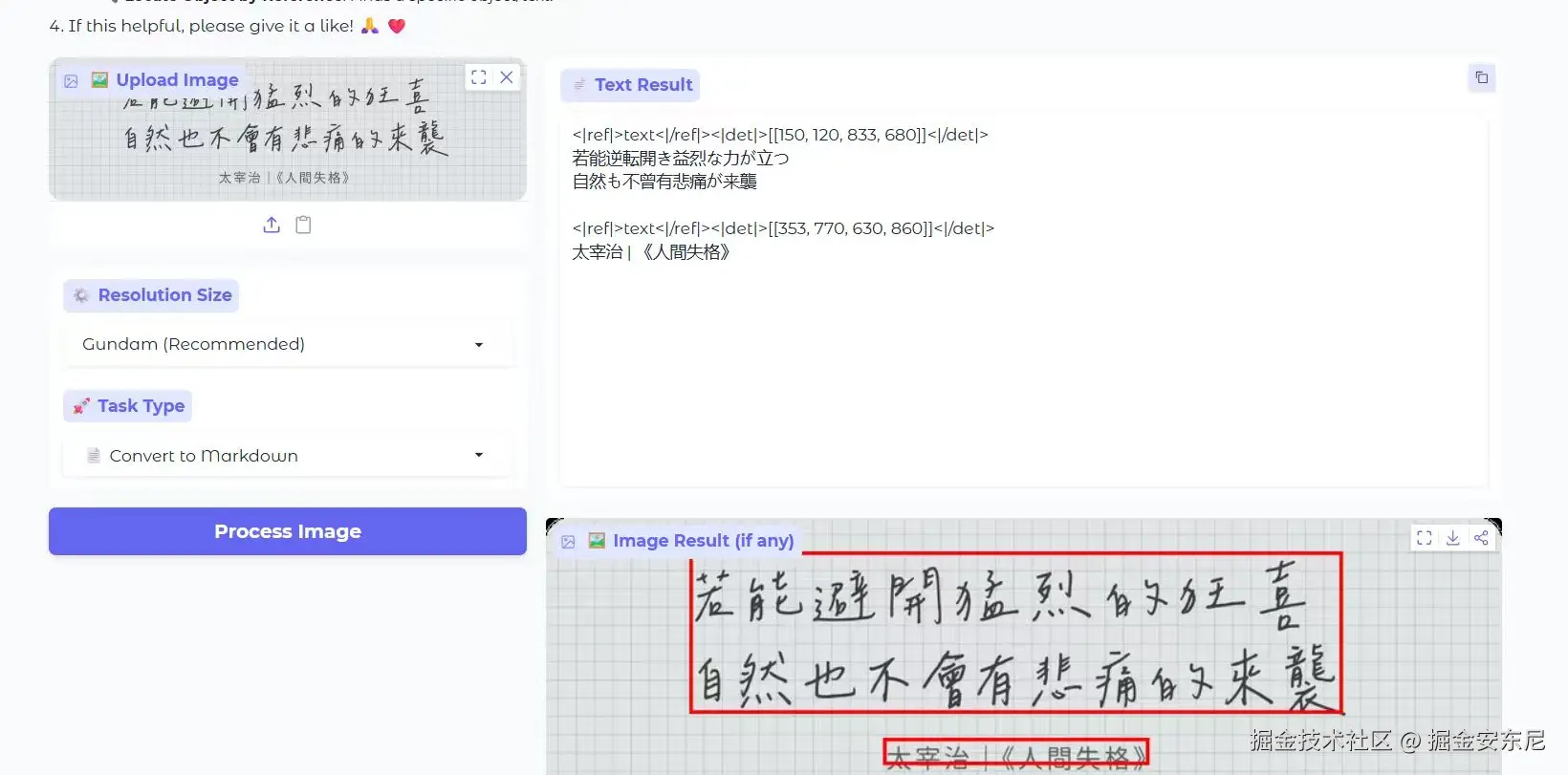
PaddleOCR-VL:
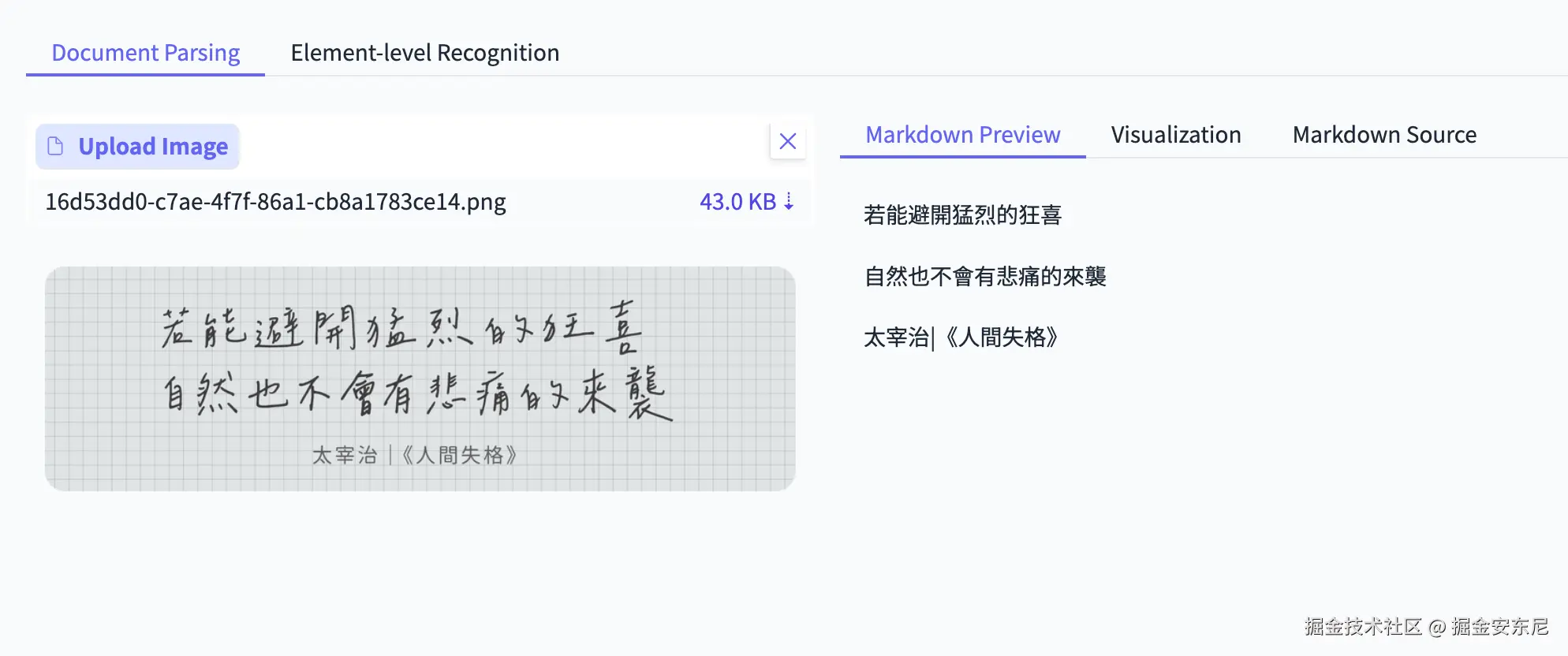
在手写文本识别中,PaddleOCR-VL 能精准地区分文字与方格背景,不仅识别出完整的文字内容,连标点符号也能准确还原。DeepSeek-OCR 则出现了识别偏差,将中文误判为日语。
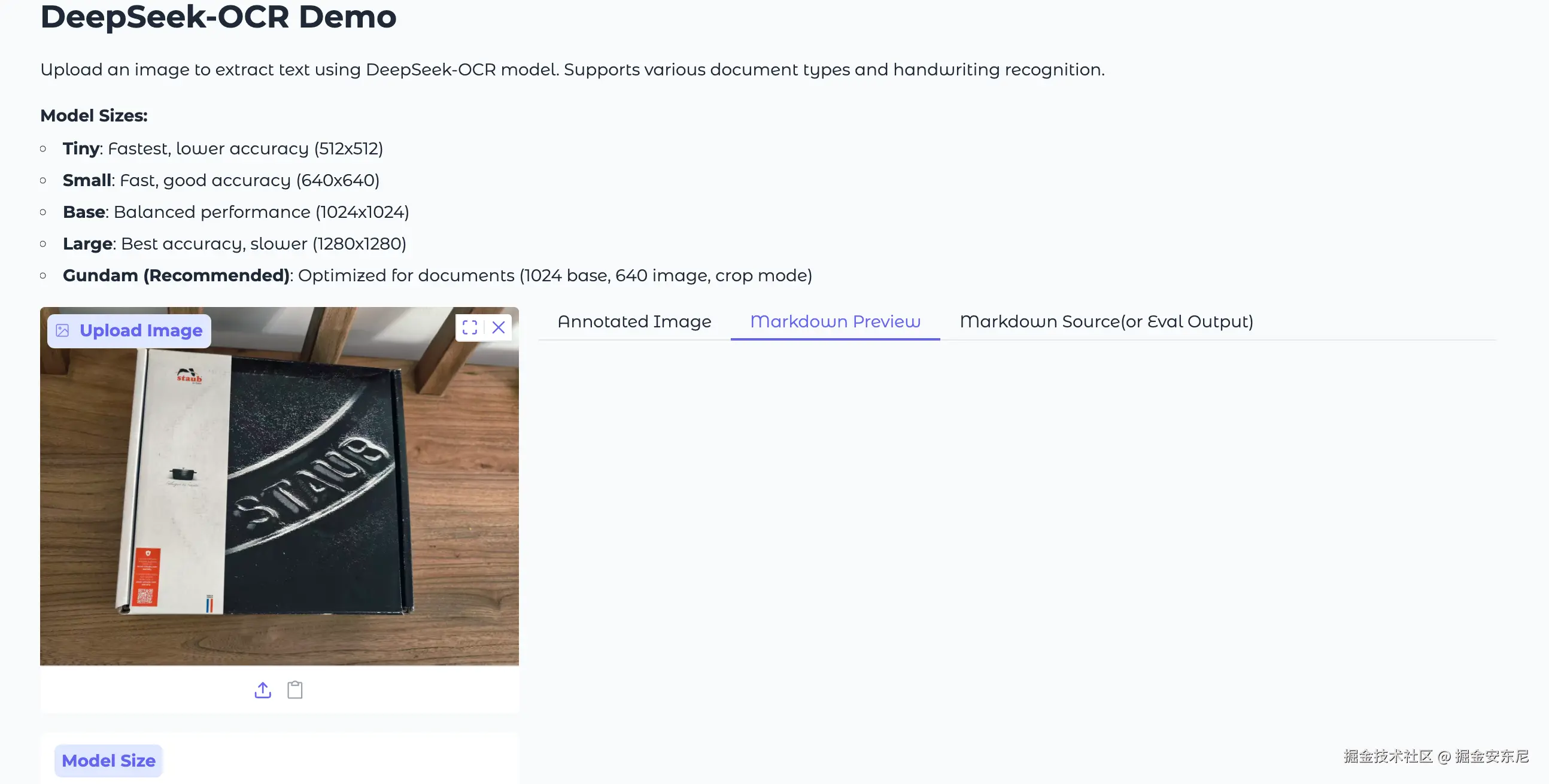
3、现实照片识别

Deepseek-OCR:
PaddleOCR-VL:
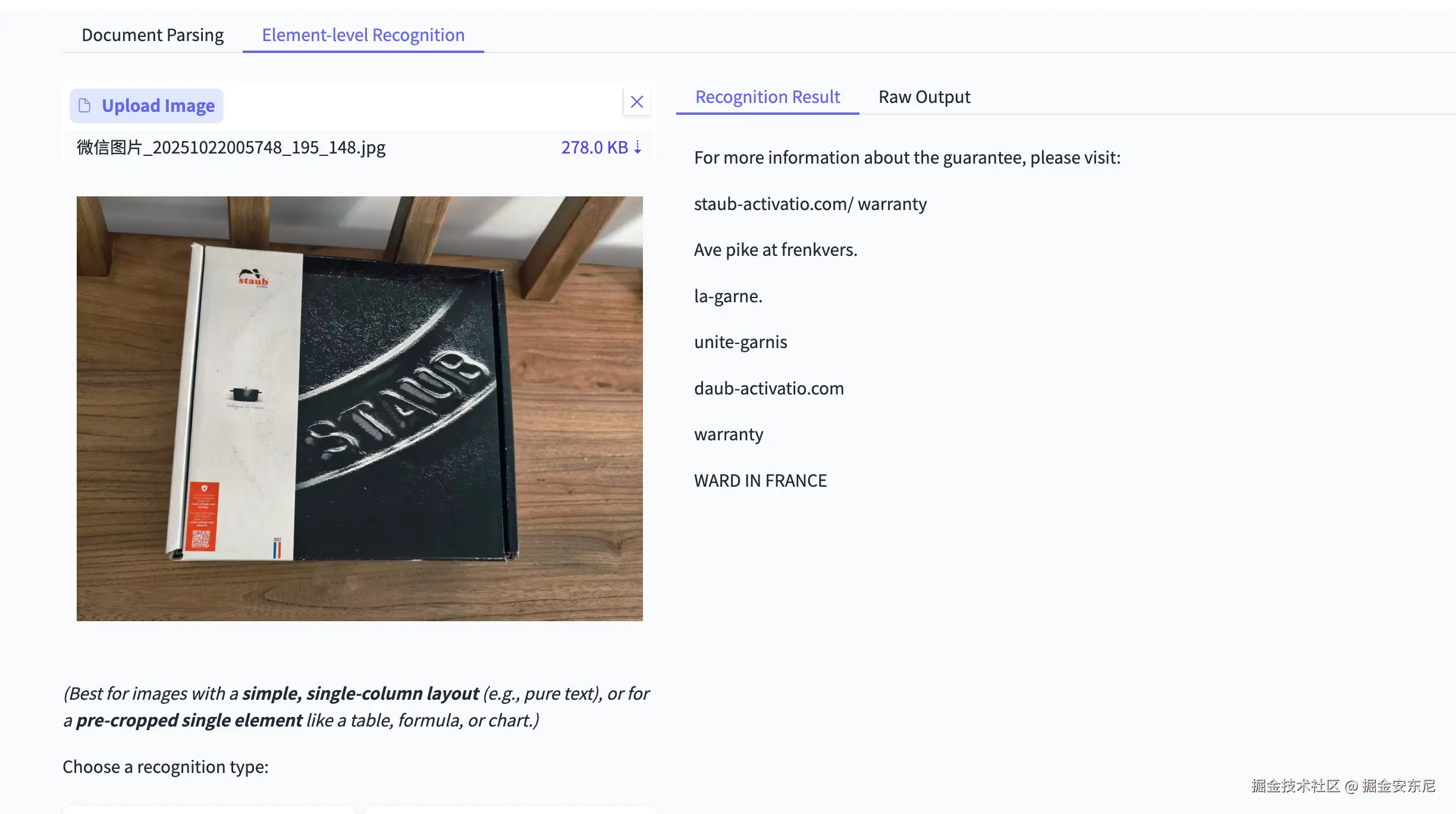
PaddleOCR-VL 能看清红底上的字,而 DeepSeek-OCR 没识别出来文字。
五、结语:OCR 让 AI 真正"看世界"
当我们把 DeepSeek-OCR 与 PaddleOCR-VL 放在一起比较时,其实看到的是两个完全不同方向的探索。
DeepSeek 在做"压缩",更像是在追求底层算法的极致效率;而 PaddleOCR-VL 在做"识别",聚焦的是真实场景的可用性,更适合开发者, 让模型"看得更准",为开发者提供一套真正能落地的OCR视觉理解方案。这两个方向对应当下 AI 发展的两个维度------"内在智能"与"外在感知"。DeepSeek 代表了语言空间的优化与压缩革命,追求更轻、更快、更省;而百度 PaddleOCR-VL 则代表了视觉理解的实用落地,从表格、合同、票据到漫画、照片。
不论怎样,我们看到了、意识到了 OCR 的重要性,未来的大模型格局,不再被局限于文字、语言的边界,它一定是多模态的,智能体不是参数的堆叠,也不是算力的规模,而是真的"看到、看准、看懂"!
六、体验地址
- 🔗 在线体验:aistudio.baidu.com/application...
- 🔗 GitHub:github.com/PaddlePaddl...
- 🔗 Hugging Face:huggingface.co/PaddlePaddl...