摘要
https://arxiv.org/pdf/2509.15642
联合RGB-红外感知对于在各种天气和光照条件下实现鲁棒性至关重要。尽管基础模型在单一模态内表现出色,但在跨模态应用时会遭受显著的性能下降------我们将这一问题归因于模式捷径(pattern shortcut),即一种偏向于优先考虑表面传感器模式而非底层语义的模态偏差。为解决这一问题,我们提出了UNIV(UNified foundation model for InfraRed and Visible modalities),一个面向红外和可见光模态的统一基础模型。UNIV的核心是补丁跨模态对比学习(PCCL),一种自监督对比学习策略,用于构建统一的跨模态特征空间。PCCL利用冻结的预训练模型基于语义相似性采样伪补丁对,并通过吸引语义相关的对同时排斥不相关的对来对齐红外-可见光表示。这一过程同时增强了跨模态对齐和类间语义可分性,引导模型关注语义结构而非陷入模式捷径。为进一步支持跨模态学习,我们引入了MVIP,迄今为止最全面的可见光-红外基准数据集,包含来自各种场景的98,992对精确对齐的图像对。大量实验表明,UNIV在红外任务上表现出卓越性能(语义分割+1.7 mIoU,检测+0.7 mAP),同时在RGB任务上保持了具有竞争力的准确性。代码将被发布。
1. 引言
近期预训练基础模型在可见光4,6,14,17和红外27,41,42模态中都取得了令人印象深刻的结果。然而,这些模型是独立训练的,当跨模态应用时,存在显著的跨域差距。这一差距限制了它们在多样感知设置下的泛化能力,包括仅RGB、仅IR和RGB-IR联合场景。因此,一个能为两种模态产生语义一致特征的统一编码器至关重要。
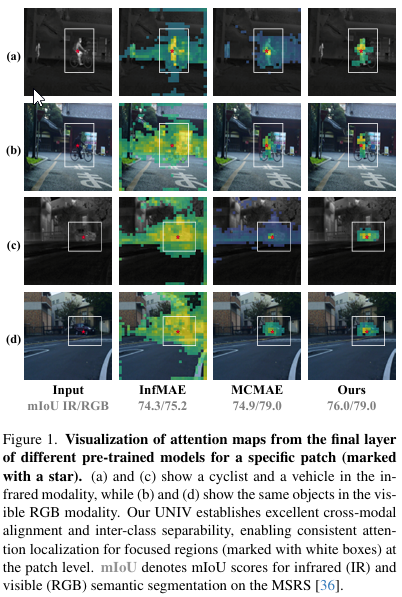
现有的单模态预训练存在模式捷径问题:模型严重依赖于模态特定线索------如RGB中的颜色和亮度,或IR中的热强度------而非语义结构。图1(b)显示,像InfMAE27这样的IR训练模型会将亮度敏感的注意力转移到RGB图像上,导致不正确的定位。相反,如MCMAE14这样的可见光训练编码器在IR场景中失效(图1©),因为缺少颜色和纹理。这些观察揭示了一个根本性限制:仅靠单模态预训练无法实现跨模态对齐和语义可分性。
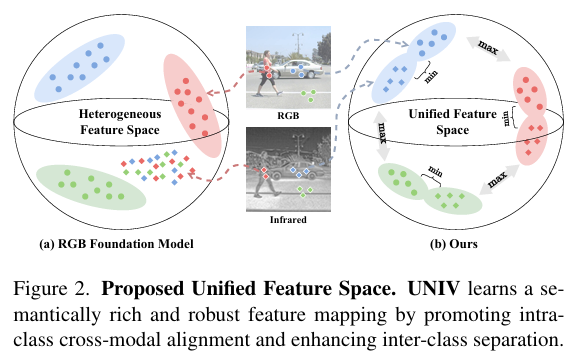
如图2所示,实现统一的RGB-IR表示需要塑造一个特征空间,其中同类样本聚集在一起,而不同类样本被良好分离。监督学习可以强加这种结构,但严重依赖于大规模标记的RGB-IR数据集。重要的是,我们需要的几何结构------语义相关样本之间的吸引和不相关样本之间的排斥------正是对比学习所构建的几何结构。对比学习通过直接优化正负关系来构建这样的空间,无需真实标签。利用这一特性,我们从预训练编码器中提取伪正负补丁对,并使用对比学习来优化RGB-IR对齐的共享表示空间。
本文中,我们提出了UNIV,一个面向红外和可见光模态的UNified基础模型。UNIV使用补丁级跨模态对比学习(PCCL)来缩小特征差距,同时增强类间语义。我们利用冻结的ImageNet预训练RGB模型中编码的语义先验:其最后一层注意力图提供补丁级相似性,我们将其二值化为伪正负标签。来自此冻结编码器的特征作为锚点。在训练期间,将RGB图像或其配对的IR图像输入到我们的可学习编码器中,对比学习根据伪标签将其表示与锚点对齐。这一过程将语义相关的补丁在跨模态间拉近,同时推开不相关的补丁,从而产生一个统一且具有判别性的特征空间。
为支持这种跨模态学习,我们引入了多场景可见光红外对数据集(MVIP),这是一个包含98,992对精确对齐的可见光-红外图像对的综合数据集,从五个公共数据集12,21,22,25,35中精选而来。涵盖城市驾驶、监控和空中无人机场景,MVIP为鲁棒的跨模态研究提供了坚实基础(详见附录A)。
我们的主要贡献是:
- 补丁跨模态对比学习:一种自监督方法,自适应地减少跨模态特征差距,同时增强类间判别能力。
- MVIP数据集:最大的可见光-红外基准数据集,包含98,992对跨各种场景对齐的图像对。
- 最先进性能:我们的模型在红外任务上取得顶级结果,包括语义分割(MSRS上+1.7 mIoU)和目标检测(M3FD上+0.7 mAP),同时保持RGB任务的下游性能。
2. 相关工作
2.1 基础模型
BERT10、ViTs11和CLIP32等预训练模型的成功展示了它们从大规模数据集中学习通用表示的能力。遵循这一范式,红外特定模型(例如,PAD41,InfMAE27)也得到了发展。然而,一个关键差距仍然存在:现有工作以模态专业化为特征,为RGB和红外使用不同的架构和预训练目标。这导致缺乏一个能在模态间泛化的统一基础模型,严重限制了实际应用。
2.2 对比学习
自监督表示学习在视觉识别领域取得了快速进展。对比学习8仍然是核心范式。DINO4利用教师-学生蒸馏进行无标签全局特征学习,而DINOv231扩展这一框架以获得高度可迁移的表示。iBOT44引入补丁级标记化以改进密集预测。最近的方法朝着更细粒度和更大规模预训练推进:I-JEPA2预测掩码补丁特征,SigLIP40采用sigmoid目标进行图像-文本训练,ViCMAE18在图像和视频间整合掩码自编码与对比学习。
2.3 跨模态对齐
跨模态对齐已从静态图像-文本匹配发展到视频、时间序列和光谱模态。CLIP32通过对比预训练建立了一个共享的潜在空间,随后的工作引入了跨帧、片段和短语的细粒度和分层视频-文本对齐23,30,37,39。最近的方法进一步探索了模态特定锚点和多粒度交互以实现更鲁棒的对齐7,29。这些进展激发了我们进行可见光-红外跨模态特征对齐的动机。
3. 方法论
3.1 核心思想
如图2所示,我们的核心思想是学习一个新的特征映射EEE,将输入图像投影到一个更具判别性的特征空间中,其中相同语义类的特征在跨模态时保持接近,而不同类的特征则被推开。我们形式化问题如下:给定配对的可见光RGB和红外图像,我们使用可训练编码器EtrainE_{train}Etrain提取它们的特征(如图3顶部所示):
FV=Etrain(ImgVisible)F^V = E_{train}(Img_{Visible})FV=Etrain(ImgVisible), (1)
FI=Etrain(ImgInfrared)∈Rdk×NF^I = E_{train}(Img_{Infrared}) \in \mathbb{R}^{d_k \times N}FI=Etrain(ImgInfrared)∈Rdk×N, (2)
其中dkd_kdk表示特征维度,NNN表示图像补丁的数量。红外特征FIF^IFI可以分解为FI={f1I,f2I,...,fNI}F^I = \{f^I_1, f^I_2, ..., f^I_N\}FI={f1I,f2I,...,fNI},其中每个fiIf^I_ifiI对应于第iii个补丁的特征。同样,FVF^VFV可以以相同方式分解。
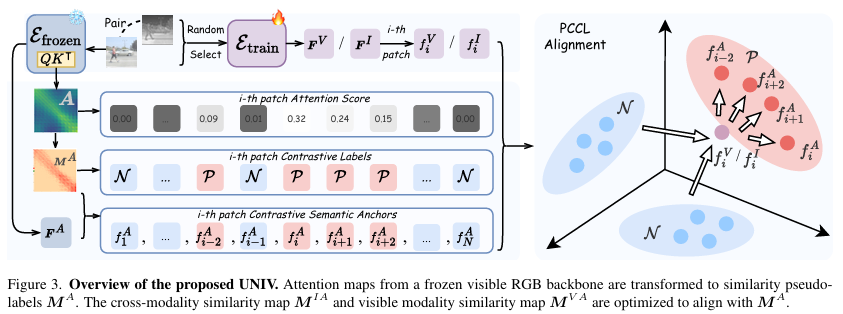
为指导特征学习,我们提出了注意力引导补丁锚点(Attention-Guided Patch Anchors)方法,该方法从注意力图中提取鲁棒的正负标签,并生成补丁对比语义锚点FAF^AFA(在3.2节中定义)。基于这些锚点,我们设计了一种有效的补丁跨模态对比学习(PCCL)优化策略来优化特征空间。
3.2 注意力引导补丁锚点
在初步实验中,我们观察到由冻结的预训练RGB编码器EfrozenE_{frozen}Efrozen提取的特征已经表现出近似的聚类行为。这启发我们使用这个预先存在的特征空间作为参考,其中补丁特征作为语义锚点。这避免了重新优化整个特征空间,加速了训练。
具体来说,我们利用EfrozenE_{frozen}Efrozen应用于可见光模态的最后一层注意力图。如图1(b)和(d)所示,这些注意力图对语义相似区域显示出高度相关性,对不相似区域则显示出低相关性。我们从EfrozenE_{frozen}Efrozen获取最后一层注意力图AAA:
A=softmax(QKTdk)∈RN×NA = \text{softmax}(\frac{QK^T}{\sqrt{d_k}}) \in \mathbb{R}^{N \times N}A=softmax(dk QKT)∈RN×N, (3)
其中QQQ和KKK是查询和键矩阵,dkd_kdk是特征维度。
然后,我们使用以下三个规则将AAA转换为二进制伪标签矩阵MAM^AMA:
- 自相似性强制:设置所有对角线元素MiiA=1M^A_{ii} = 1MiiA=1以保留补丁身份。
- 相关性选择:对于每一行iii,将元素{MikA}k=1N\{M^A_{ik}\}^N_{k=1}{MikA}k=1N按降序排序。设π(⋅)\pi(\cdot)π(⋅)是从排序索引到原始索引的映射,使得Miπ(1)A≥⋯≥Miπ(N)AM^A_{i\pi(1)} \geq \cdots \geq M^A_{i\pi(N)}Miπ(1)A≥⋯≥Miπ(N)A。找到满足∑k=1mMiπ(1)A,...,Miπ(m)A=1\sum^m_{k=1} M^A_{i\pi(1)}, ..., M^A_{i\pi(m)} = 1∑k=1mMiπ(1)A,...,Miπ(m)A=1的最小mmm。
- 不相似性抑制:将所有未选中的条目设置为0。
这一过程形式化表达为:
MijA={1if i=j,1if j∈{π(1),...,π(mthr)},0otherwise,M^A_{ij} = \begin{cases} 1 & \text{if } i = j, \\ 1 & \text{if } j \in \{\pi(1), ..., \pi(m_{thr})\}, \\ 0 & \text{otherwise}, \end{cases}MijA=⎩ ⎨ ⎧110if i=j,if j∈{π(1),...,π(mthr)},otherwise, (4)
其中mthr=min{m∣∑k=1mMiπ(k)A>γ}m_{thr} = \min\{m | \sum^m_{k=1} M^A_{i\pi(k)} > \gamma\}mthr=min{m∣∑k=1mMiπ(k)A>γ}。
因此,我们可以根据伪标签MAM^AMA将冻结的鲁棒RGB特征划分为补丁对比语义锚点FA={f1A,f2A,...,fNA}F^A = \{f^A_1, f^A_2, ..., f^A_N\}FA={f1A,f2A,...,fNA}。
3.3 补丁跨模态对比学习
为重构与图3右侧PCCL对齐相关的统一特征空间,我们首先讨论红外模态类间分离的优化。给定语义锚点FAF^AFA,我们定义以下目标:设PPP表示正样本对(即,属于同一类的补丁),NNN表示负样本对(即,来自不同类的补丁)。设SSS为不相似性函数,τ\tauτ为温度超参数。SSS的常见选择是余弦相似性:
S(zi,zj)=zi⊤zj∥zi∥∥zj∥S(z_i, z_j) = \frac{z_i^\top z_j}{\|z_i\|\|z_j\|}S(zi,zj)=∥zi∥∥zj∥zi⊤zj。 (5)
优化目标是:
minE(i,j)∼NS(fiA,fjI)/τ−E(i,j)∼PS(fiA,fjI)/τ\min \mathbb{E}{(i,j) \sim N}S(f\^A_i, f\^I_j)/\\tau - \mathbb{E}{(i,j) \sim P}S(f\^A_i, f\^I_j)/\\tauminE(i,j)∼NS(fiA,fjI)/τ−E(i,j)∼PS(fiA,fjI)/τ。 (6)
定义相似性矩阵:
MijIA=S(fiA,fjI)/τ,MIA={MijIA}i,j=1NM^{IA}{ij} = S(f^A_i, f^I_j)/\tau, M^{IA} = \{M^{IA}{ij}\}^N_{i,j=1}MijIA=S(fiA,fjI)/τ,MIA={MijIA}i,j=1N。 (7)
使用伪标签矩阵MAM^AMA,我们可以将公式(6)重写为:
minEMijA=0MijIA−EMijA=1MijIA\min \mathbb{E}{M^A{ij}=0}M\^{IA}_{ij} - \mathbb{E}{M^A{ij}=1}M\^{IA}_{ij}minEMijA=0MijIA−EMijA=1MijIA (8)
⇔minLdisc=∑MijA=0MijIA−∑MijA=1MijIA\Leftrightarrow \min L_{disc} = \sum_{M^A_{ij}=0} M^{IA}{ij} - \sum{M^A_{ij}=1} M^{IA}_{ij}⇔minLdisc=∑MijA=0MijIA−∑MijA=1MijIA。 (9)
我们提出一个损失函数LIAL_{IA}LIA,最小化MAM^AMA和σ(MIA)\sigma(M^{IA})σ(MIA)之间的KL散度,其中σ(⋅)=11+e−(⋅)\sigma(\cdot) = \frac{1}{1+e^{-(\cdot)}}σ(⋅)=1+e−(⋅)1是sigmoid函数。当一个补丁有多个正样本时,优化KL散度等同于优化MAM^AMA和σ(MIA)\sigma(M^{IA})σ(MIA)之间的二元交叉熵(BCE)损失,如下所示:
LIA≡DKL(MA∥σ(MIA))L_{IA} \equiv D_{KL}(M^A \| \sigma(M^{IA}))LIA≡DKL(MA∥σ(MIA))
=∑i=1N∑j=1NDKL(MijA∥σ(MijIA))= \sum^N_{i=1} \sum^N_{j=1} D_{KL}(M^A_{ij} \| \sigma(M^{IA}{ij}))=∑i=1N∑j=1NDKL(MijA∥σ(MijIA))
=∑i=1N∑j=1NLBCE(MijA,σ(MijIA))+H(MA)= \sum^N{i=1} \sum^N_{j=1} L_{BCE}(M^A_{ij}, \sigma(M^{IA}{ij})) + H(M^A)=∑i=1N∑j=1NLBCE(MijA,σ(MijIA))+H(MA)
∝LBCE(MA,σ(MIA))\propto L{BCE}(M^A, \sigma(M^{IA}))∝LBCE(MA,σ(MIA)), (10)
其中H(MA)H(M^A)H(MA)是MAM^AMA的熵,是常数。
因此,KL散度LIAL_{IA}LIA等于公式(11)中定义的LBCE(MA,σ(MIA))L_{BCE}(M^A, \sigma(M^{IA}))LBCE(MA,σ(MIA))加上熵项H(MA)H(M^A)H(MA),后者相对于模型参数是常数。因此,最小化KL散度等同于最小化BCE损失。
LBCE(MA,σ(MIA))=−∑i=1N∑j=1N(MijAlog(σ(MijIA))+(1−MijA)log(1−σ(MijIA)))L_{BCE}(M^A, \sigma(M^{IA})) = -\sum^N_{i=1} \sum^N_{j=1} (M^A_{ij} \log(\sigma(M^{IA}{ij})) + (1 - M^A{ij}) \log(1 - \sigma(M^{IA}_{ij})))LBCE(MA,σ(MIA))=−∑i=1N∑j=1N(MijAlog(σ(MijIA))+(1−MijA)log(1−σ(MijIA)))。 (11)
尽管BCE定义在sigmoid输出σ(MijIA)\sigma(M^{IA}{ij})σ(MijIA)上,但其优化方向与公式(9)中的判别目标完全一致。对于正对(MijA=1M^A{ij} = 1MijA=1),最小化BCE增加σ(MijIA)\sigma(M^{IA}{ij})σ(MijIA),这需要增加相似性MijIAM^{IA}{ij}MijIA。对于负对(MijA=0M^A_{ij} = 0MijA=0),最小化BCE减少σ(MijIA)\sigma(M^{IA}{ij})σ(MijIA),推动MijIAM^{IA}{ij}MijIA向更小的值。这种行为直接匹配公式(9),后者扩大正相似性同时抑制负相似性。因此,BCE为由LdiscL_{disc}Ldisc定义的相同对比方向提供了稳定的优化替代。通过这种等价性,我们优化红外特征以自适应地在特征空间中与语义锚点对齐。
为进一步增强跨模态对齐,我们将此方法扩展到RGB模态。由于我们使用配对图像,RGB和红外模态的语义应该高度对齐。对于RGB输入,我们类似地定义LVA≡DKL(MA∥σ(MVA))L_{VA} \equiv D_{KL}(M^A \| \sigma(M^{VA}))LVA≡DKL(MA∥σ(MVA)),使用相同的语义锚点优化RGB特征。在实践中,我们随机选择输入模态(RGB或IR)。由于两种模态都优化为相同的语义锚点,它们在特征空间中逐渐对齐,实现跨模态对齐。最后,PCCL训练中使用的总优化损失函数定义如下:
总损失结合了两个目标:
LPCCL=α⋅LIA+β⋅LVAL_{PCCL} = \alpha \cdot L_{IA} + \beta \cdot L_{VA}LPCCL=α⋅LIA+β⋅LVA, (12)
其中α\alphaα和β\betaβ是LIAL_{IA}LIA和LVAL_{VA}LVA的权重。
4. 实验
4.1 实验设置
4.1.1 数据集
为促进PCCL训练,我们构建了多场景可见光-红外对(MVIP)数据集,包含197,984对对齐的可见光-红外图像对(每种模态98,992对),从五个公开可用的基准12,21,22,25,35中精选而来。MVIP涵盖多样真实世界场景,包括城市驾驶、监控和空中无人机视图,包含车辆和行人等常见物体,使其适用于各种环境中的跨模态感知。为减少序列数据中的冗余,我们应用帧下采样以确保代表性样本子集。详细数据集构建过程见附录的数据集部分。
4.1.2 实现细节
预训练:我们用ImageNet-1K(IN1K)9预训练的MCMAE14(ViT-B骨干)初始化模型(EtrainE_{train}Etrain和EfrozenE_{frozen}Efrozen),利用其鲁棒的特征和注意力图,并在MVIP数据集上使用PCCL训练EtrainE_{train}Etrain分支以增强统一特征提取。我们还使用LoRA微调骨干网络。LoRA适配器具有默认秩8和dropout率0.1,集成到ViT的前馈层、QKV线性变换和投影层中。我们为LoRA集成版本训练400个epoch,为全参数预训练训练200个epoch,批量大小为256。默认损失系数设置为α=β=1\alpha = \beta = 1α=β=1,γ=0.6\gamma = 0.6γ=0.6,温度τ=0.04\tau = 0.04τ=0.04。更多训练细节见附录的实现细节部分。
4.2 与最先进的红外预训练模型比较
为评估我们提出的UNIV的有效性,我们与几种基线方法进行了全面比较。这些包括从零训练的模型、仅在大规模红外数据集上预训练的模型,以及仅在可见光RGB数据集上预训练的模型。
我们在两个红外子数据集上评估我们的模型:用于语义分割的MSRS36和用于目标检测的M3FD28,使用UperNet38头进行语义分割,使用MaskRCNN16头进行目标检测。
"从零训练"和"在红外数据集上预训练"的结果来自27。所有方法在相同设置下训练至收敛,以确保公平比较。详细信息和可视化见附录。
4.2.1 语义分割
表1显示了在MSRS-IR数据集上红外图像语义分割的结果。一个关键观察是,从零训练的模型性能始终低于预训练模型,强调了预训练在学习模态不变语义特征中的重要性。例如,在IN1K上预训练的MCMAE比在Inf30上预训练的同一模型实现了2.8 mIoU的增益。这一性能差距突显了强大预训练在构建鲁棒红外表示中的关键作用。
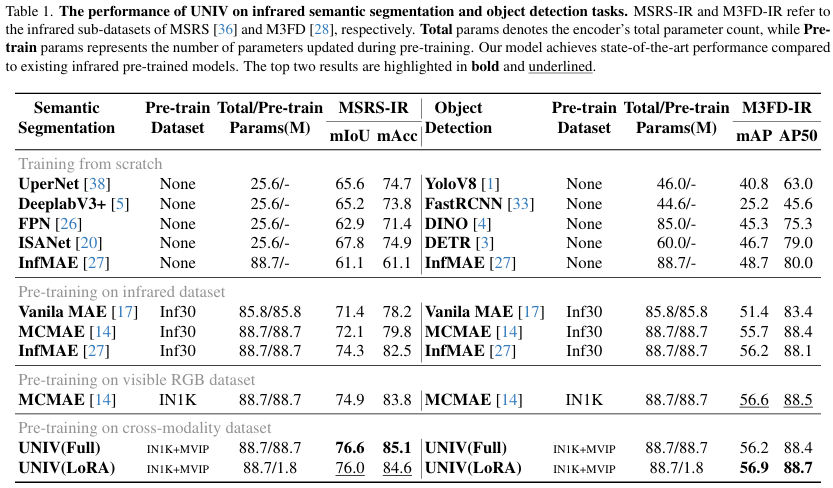
基于这一观察,我们提出的UNIV模型在MSRS-IR上实现了最先进的性能。使用基于LoRA的预训练,UNIV达到76.0 mIoU,超过先前的SOTA InfMAE 1.7 mIoU,同时仅更新2%的参数。全参数变体进一步提升至76.6 mIoU。这些结果验证了我们的PCCL和LoRA预训练策略在平衡准确性和效率方面的有效性,并证明在统一特征空间中,红外特征的类间语义可分性显著增强,从而带来显著的下游改进。
4.2.2 目标检测
表1展示了在M3FD-IR数据集上红外目标检测的结果。使用LoRA微调时,提出的UNIV模型达到56.9 mAP和88.7 AP50,超过先前的最先进InfMAE 0.7 mAP和0.6 AP50,证明了其强大的检测能力。有趣的是,在IN1K上预训练的MCMAE的跨模态微调也产生了有竞争力的性能,表明单模态预训练仍能捕获部分共享的跨模态特征。
相比之下,UNIV的全参数预训练变体产生了次优结果(56.2 mAP,低于MCMAE-IN1K的56.6 mAP)。我们的分析表明,全参数UNIV在预训练期间倾向于过度优化补丁相似性,牺牲了单个补丁内语义的丰富性。这一限制在目标检测中尤为明显,因为重叠的边界框导致高度纠缠的补丁级信息。LoRA微调通过应用低秩更新,更好地保持了补丁间语义,同时有选择地调整补丁关系,使检测任务的学习更有效。
4.3 UNIV在RGB下游任务上的表现
为评估在RGB模态上的类间分离能力,我们将UNIV模型性能与几种基线方法进行比较。如表2所示,我们在ADE20K43和MSRS-RGB36数据集上评估下游语义分割性能。所有方法在相同设置下训练,以确保公平比较。详细信息见附录的实现细节部分。
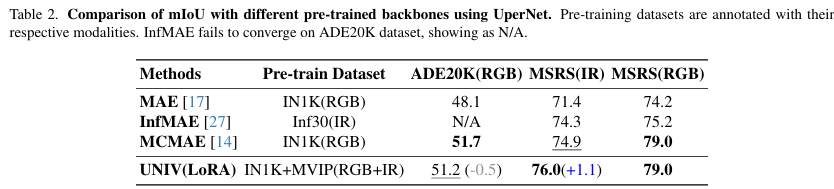
来自红外特定InfMAE的异构特征空间在可见光RGB下游任务中遇到模态崩溃,突显了跨模态适应的挑战。然而,UNIV产生统一的语义特征空间,在保持原始RGB性能的同时,实现了高效的红外适应。在MSRS-RGB数据集上,UNIV保持了原始竞争性能(79.0 mIoU),与基线匹配,并进一步验证了其在跨模态任务中的有效性。在ADE20K上,UNIV达到51.2 mIoU------保留了原始MCMAE(IN1K预训练)能力的99%。这些结果共同证明,UNIV有效构建了一个统一的语义特征空间,实现了鲁棒的跨模态迁移,同时在原始模态上保持了强大的性能。
4.4 与基于微调方法的比较
为进一步评估我们的微调策略的有效性,我们将UNIV与PAD41进行比较,PAD是一种基于MIM预训练的适配器微调方法。为公平比较,UNIV在PAD的MSIP数据集的一个子集上预训练(仅46%红外图像),并在相同设置下在SODA-IR24和MFNet-IR15上进行微调。
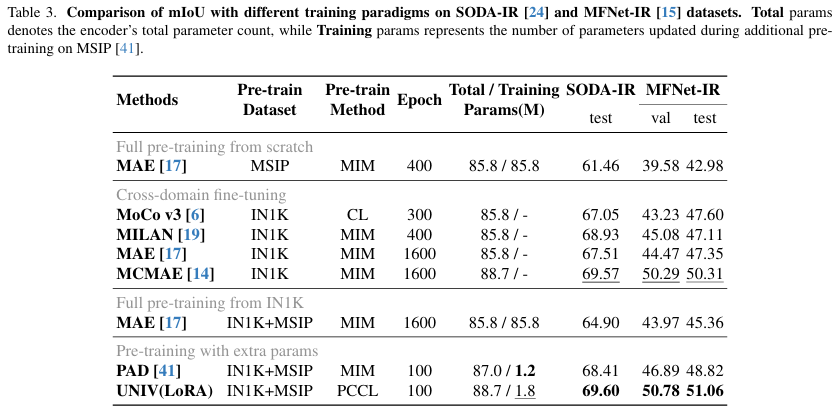
如表3所示,具有MAE骨干的PAD证实,跨域预训练比直接跨域微调或从零训练更有优势。然而,使用我们的PCCL范式训练的UNIV在mIoU上优于MCMAE基线14和PAD,表明PCCL提取了更具判别性的红外语义特征。
关键的是,PCCL的优势来自于构建一个由可见光和红外模态共享的统一特征空间。与仅关注域特定红外线索的基于MIM的方法27不同------通常限于亮度,缺乏颜色-纹理语义------PCCL明确将IR特征与更丰富的可见光特征语义结构对齐。这种对齐保留了可见光模态的固有类间几何结构,并将其转移到红外表示中。结果,在重构的统一空间中,UNIV为红外特征保持了强大的类间可分性,即使在有限IR数据的情况下,也能实现更有效的下游微调。
4.5 特征空间分析
我们在MSRS数据集上对统一特征空间进行定量和定性分析。我们采用Earth Mover's Distance(EMD)34评估跨模态对齐和类间分离,使用t-SNE可视化特征分布。
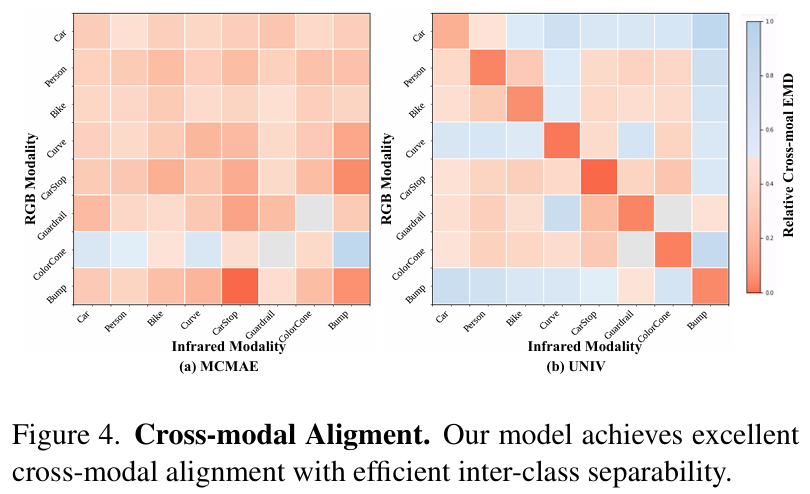
4.5.1 跨模态对齐
如图4所示,我们计算跨模态语义特征分布之间的EMD距离。在图4(a)中,未对齐的MCMAE特征空间中RGB和IR模态之间的类别级距离矩阵显示,同类特征(对角线条目)并不比不同类特征更接近,表明对齐效果差。相比之下,图4(b)展示了我们统一特征空间中强大的同类对齐,其中对角线条目显示出比非对角线条目显著更高的相似性。
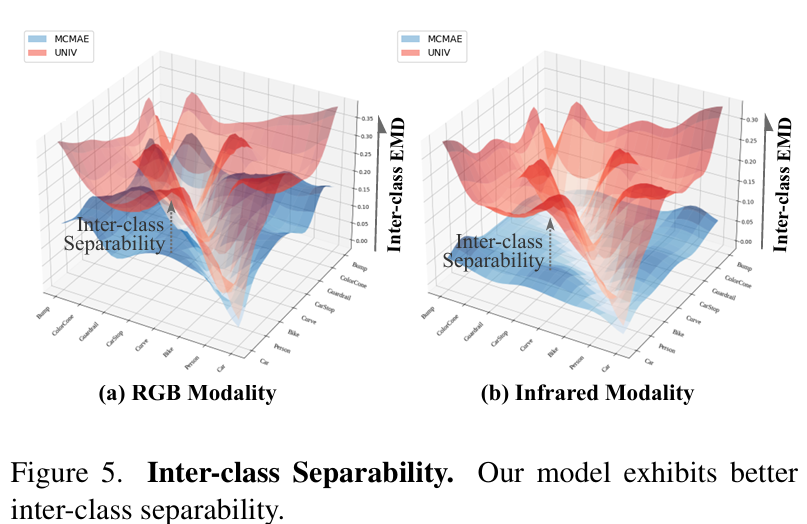
4.5.2 类间可分性
类间可分性通过计算每种模态内类别级距离来量化。图5中的比较分析显示,我们的UNIV空间(红色表面)在所有模态中始终实现比MCMAE(蓝色)更大的类间距离。这一明显改进证明了我们对比学习优化的卓越判别能力。
4.5.3 特征空间可视化
图6中的t-SNE分析评估了从图2实现的统一特征空间。我们的方法成功分离了不同语义的特征,同时聚类跨模态对应物。这与图2(a)形成鲜明对比,其中RGB特征部分可分离,但红外特征在语义上纠缠,突显了我们的方法实现的更连贯的语义组织。

4.6 消融研究
4.6.1 统一特征是否有利于语义学习?
灾难性遗忘------即学习新概念干扰先前获得的知识13------是跨模态预训练中的主要挑战。相比之下,我们重构的统一特征空间使可见光和红外表示能够联合结构化,而不是顺序覆盖,有效保留模态特定知识,同时促进共享语义。这个统一空间作为一个稳定的几何支架,两种模态都保持其固有的语义拓扑,从而提高模型学习类别判别特征的能力。
为验证这种统一空间是否确实有利于语义学习,我们使用UperNet分割头在MSRS-IR和MSRS-RGB数据集上微调UNIV。如表4所示,结果直接证明统一特征学习在两种模态上都产生了更强的语义表示。
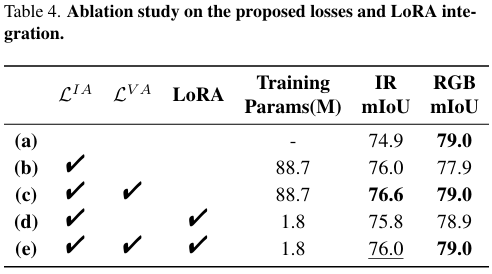
引入LIAL_{IA}LIA(比较(a)和(b))将红外模态性能提高1.1 mIoU,但略微降低了RGB性能。这种降低表明,将红外特征与可见光特征对齐可能会在可见光特征空间中引入轻微偏移。然而,在©中添加LVAL_{VA}LVA将RGB性能恢复到基线水平(79.0 mIoU),同时进一步将红外性能提升至76.6 mIoU。这表明LVAL_{VA}LVA通过优化过程中的自然跨模态对齐有效缓解了灾难性遗忘。
在(d)中集成LoRA将可训练参数数量减少到1.8M,同时保持竞争性能(IR: 75.8 mIoU, RGB: 78.9 mIoU)。最小的RGB下降表明LoRA约束参数更新,从而保留模态特定表示。当LVAL_{VA}LVA和LoRA在(e)中结合时,模型实现了平衡的权衡,红外达到76.0 mIoU,RGB保持79.0 mIoU。这一结果强调了LVAL_{VA}LVA和LoRA与统一特征空间优势的互补性。
4.6.2 损失函数
为验证所提出的LPCCLL_{PCCL}LPCCL的有效性,我们将其与两种常用损失函数进行比较:LMSEL_{MSE}LMSE公式(13)和LNCEL_{NCE}LNCE公式(14)。
LMSE=∥FI−FA∥22+∥FV−FA∥22L_{MSE} = \|F^I - F^A\|^2_2 + \|F^V - F^A\|^2_2LMSE=∥FI−FA∥22+∥FV−FA∥22, (13)
LNCE=CE(MIA,1,...,N)+CE(MVA,1,...,N)L_{NCE} = CE(M^{IA}, 1, ..., N) + CE(M^{VA}, 1, ..., N)LNCE=CE(MIA,1,...,N)+CE(MVA,1,...,N), (14)
其中CECECE表示交叉熵损失。如表5所示,结果突显了PCCL相对于这些基线的优势。
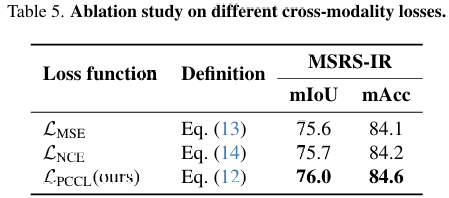
LMSEL_{MSE}LMSE最小化跨模态特征之间的L2距离,实现快速收敛,但未能充分利用红外模态特定表示,限制了其有效性。LNCEL_{NCE}LNCE增强配对实例内的特征相似性,同时减少非配对实例间的相似性,如CLIP32等模型所示。在我们实现中,LNCEL_{NCE}LNCE优化相同空间位置的补丁相似性(例如,MIAM^{IA}MIA的主对角线)。然而,它忽略了不同位置补丁之间的语义关系,这在具有重叠语义的非标志性场景中至关重要。
为解决这些限制,我们提出LPCCLL_{PCCL}LPCCL,它同时考虑对应补丁的语义对齐和多个相似补丁之间的相关性,实现更鲁棒和判别性的特征学习。
如表5所示,PCCL有效平衡了模态特定和跨模态特征学习,为跨模态预训练提供了卓越的解决方案。
5. 结论
在本工作中,我们提出了UNIV,一个统一基础模型,桥接红外和可见光模态。通过集成PCCL,UNIV重构了一个有效的统一语义特征空间,实现了鲁棒的跨模态对齐和强大的类间语义可分性。大量实验展示了UNIV的优越性。消融研究进一步验证了我们框架的效率和所提出的PCCL优化统一特征空间构建的有效性。总体而言,UNIV为构建统一跨模态语义特征空间提供了一个通用且可扩展的解决方案。