在Linux块设备驱动体系中,请求队列(Request Queue) 与BIO结构是连接上层文件系统与底层硬件的核心枢纽。请求队列负责管理I/O请求的调度与排序,BIO结构则封装了I/O操作的核心信息(如数据地址、设备偏移、操作类型)。理解二者的交互流程,是掌握块设备驱动工作原理的关键。本文将从数据结构解析入手,逐步拆解交互流程,并通过技术示例验证核心逻辑。
一、核心数据结构解析
在分析交互流程前,需先明确请求队列与BIO结构的核心字段及作用------二者通过指针关联,形成完整的I/O请求链。
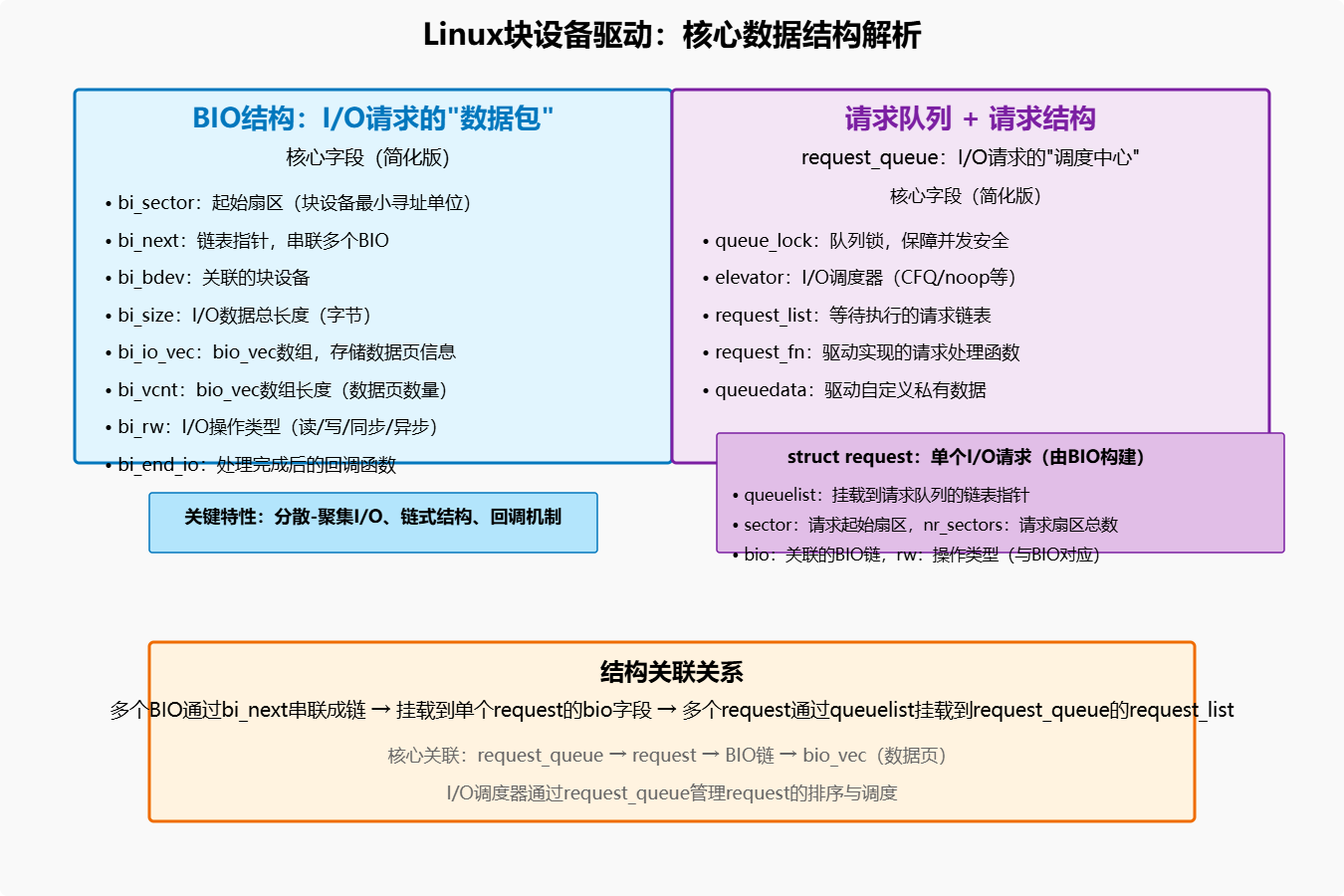
1.1 BIO结构:I/O请求的"数据包"
BIO(Block I/O)是Linux内核中描述块设备I/O请求的最小单元,它直接封装了"从哪里读/写"、"读/写到哪里"、"操作类型"等关键信息。其核心定义(简化版)如下:
struct bio {
sector_t bi_sector; // I/O操作的起始扇区(块设备最小寻址单位)
struct bio *bi_next; // 链表指针,用于将多个BIO串联成链
struct block_device *bi_bdev; // 关联的块设备
unsigned int bi_size; // I/O数据总长度(字节)
// 数据页描述:指向物理内存页及页内偏移
struct bio_vec *bi_io_vec; // bio_vec数组,存储数据页信息
unsigned int bi_vcnt; // bio_vec数组长度(数据页数量)
unsigned int bi_rw; // I/O操作类型(读:0,写:1,同步/异步标记等)
// 回调函数:BIO处理完成后触发
bio_end_io_t *bi_end_io;
void *bi_private; // 私有数据(驱动可自定义使用)
};
// 描述单个数据页的信息
struct bio_vec {
struct page *bv_page; // 指向数据所在的物理内存页
unsigned int bv_len; // 页内数据长度(字节)
unsigned int bv_offset; // 页内数据起始偏移(字节)
};关键特性:
- 分散-聚集(Scatter-Gather) :通过
bi_io_vec数组支持跨多个物理内存页的I/O操作,无需将分散的数据拷贝到连续内存。 - 链式结构 :通过
bi_next可将多个BIO串联,适配大尺寸I/O请求(如读取1GB文件需拆分多个BIO)。 - 回调机制 :
bi_end_io在BIO处理完成后调用,用于释放资源或通知上层(如文件系统)。
1.2 请求队列(request_queue):I/O请求的"调度中心"
请求队列是块设备驱动的核心调度组件,负责接收BIO、构建I/O请求(request)、调度请求执行顺序,并与底层硬件交互。其核心定义(简化版)如下:
struct request_queue {
// 队列锁:保护队列操作的并发安全
spinlock_t queue_lock;
// I/O调度器:负责请求排序(如CFQ、noop)
struct elevator_queue *elevator;
// 请求链表:等待执行的I/O请求
struct list_head request_list;
unsigned int nr_requests; // 队列中请求总数
// 设备能力:块设备的硬件限制
unsigned int max_sectors; // 单次I/O最大扇区数
unsigned int max_hw_sectors; // 硬件支持的最大扇区数
// 驱动回调:请求处理函数(由驱动实现)
request_fn_proc *request_fn;
make_request_fn *make_request_fn; // 自定义BIO处理逻辑(可选)
// 私有数据:驱动存储自定义信息(如硬件寄存器地址)
void *queuedata;
};
// 单个I/O请求(由BIO构建)
struct request {
struct list_head queuelist; // 用于挂载到请求队列
sector_t sector; // 请求起始扇区
unsigned int nr_sectors; // 请求扇区总数
struct bio *bio; // 关联的BIO链
unsigned int rw; // 操作类型(与BIO的bi_rw对应)
};关键特性:
- I/O调度器集成 :通过
elevator关联调度算法(如CFQ公平调度、noop无操作调度),优化磁盘I/O性能。 - 并发保护 :
queue_lock自旋锁防止多CPU同时操作队列,避免数据竞争。 - 驱动可定制 :
make_request_fn允许驱动绕过默认BIO处理逻辑,实现自定义请求构建(如SSD的IOPS优化)。
二、请求队列与BIO的完整交互流程
从上层发起I/O请求到硬件执行完成,请求队列与BIO的交互可分为5个核心阶段。以下以"用户读取块设备文件"为例,拆解完整流程。
 图1:请求队列与BIO交互的核心阶段
图1:请求队列与BIO交互的核心阶段
阶段1:上层发起I/O请求,构建BIO结构
当用户通过read()系统调用读取块设备文件时(如/dev/sda1),流程如下:
- 文件系统(如Ext4)通过
generic_file_read()检查页缓存:若数据未缓存,触发缺页异常。 - 缺页处理函数(如
filemap_fault())调用块设备层接口submit_bio(),并传入构建好的BIO结构。
BIO构建关键逻辑:
// 示例:文件系统构建BIO(简化版)
struct bio *bio_alloc(gfp_t gfp_mask, int nr_vecs) {
struct bio *bio = kmalloc(sizeof(struct bio), gfp_mask);
bio->bi_io_vec = kmalloc_array(nr_vecs, sizeof(struct bio_vec), gfp_mask);
bio->bi_vcnt = nr_vecs;
bio->bi_end_io = bio_end_io_fn; // 注册完成回调
return bio;
}
// 填充BIO数据(读取/dev/sda1的0-4095字节)
struct bio *bio = bio_alloc(GFP_KERNEL, 1);
bio->bi_bdev = bdget_disk(disk, partno); // 关联块设备
bio->bi_sector = 0; // 起始扇区(512字节/扇区,对应0-511字节)
bio->bi_rw = READ; // 读操作
// 填充数据页信息(用户缓冲区对应的物理页)
struct page *page = virt_to_page(user_buf);
bio->bi_io_vec[0].bv_page = page;
bio->bi_io_vec[0].bv_offset = 0;
bio->bi_io_vec[0].bv_len = 4096;
// 提交BIO到块设备层
submit_bio(bio);阶段2:BIO提交到请求队列,构建I/O请求
submit_bio()是块设备层的核心接口,负责将BIO提交到目标设备的请求队列,并触发请求构建:
- 查找请求队列 :通过BIO关联的
bi_bdev,找到块设备对应的request_queue(每个块设备对应一个请求队列)。 - 加锁保护 :获取请求队列的
queue_lock自旋锁,防止并发修改队列。 - 调用调度器接口 :通过
elevator->ops->elevator_merge_fn()尝试将当前BIO合并到已存在的请求中(如相邻扇区的I/O可合并,减少硬件操作次数)。 - 构建新请求 :若无法合并,调用
get_request()分配新的request结构,将BIO挂载到request->bio,并将请求添加到队列的request_list。
注意 :若驱动通过blk_queue_make_request()注册了自定义make_request_fn,则会跳过默认请求构建流程,直接调用驱动自定义逻辑(如直接提交BIO到硬件,适用于无机械臂的SSD设备)。
阶段3:I/O调度器排序请求
请求队列中的elevator(I/O调度器)负责对request_list中的请求进行排序,优化磁盘访问性能。以常用的**CFQ(完全公平调度器)**为例:
- 公平性:为每个进程维护一个请求队列,按进程I/O请求次数分配时间片,避免单个进程独占磁盘。
- 合并与排序:将相邻扇区的请求合并,减少磁盘寻道时间;对随机请求按扇区顺序重排,模拟顺序访问。
调度器通过elevator->ops->elevator_dispatch_fn()接口从队列中选择下一个要执行的请求,传递给驱动的request_fn。
阶段4:驱动处理请求,与硬件交互
驱动通过request_fn实现请求处理逻辑,核心是将request中的BIO数据传递给硬件,并触发I/O操作:
- 获取请求 :驱动从请求队列中通过
elv_next_request()获取下一个待处理的请求。 - 解析BIO链 :遍历请求的
bio链,提取每个BIO的bi_sector(扇区)、bi_io_vec(数据页)等信息。 - 硬件编程:将扇区、数据地址、操作类型等信息写入硬件寄存器,触发硬件I/O(如SATA控制器的读取命令)。
- 等待I/O完成 :硬件完成I/O后,通过中断通知驱动;驱动在中断处理函数中标记请求完成,并调用
end_request()。
驱动请求处理示例(简化版):
// 驱动请求处理函数
static void my_disk_request_fn(struct request_queue *q) {
struct request *req = elv_next_request(q);
struct my_disk_data *data = q->queuedata; // 驱动私有数据(如寄存器地址)
while (req) {
struct bio *bio = req->bio;
sector_t sector = req->sector;
unsigned int rw = req->rw;
// 遍历BIO链,处理每个BIO的数据
while (bio) {
// 1. 解析BIO的扇区和数据页
sector_t bio_sector = bio->bi_sector;
struct bio_vec *bvec = bio->bi_io_vec;
int i;
// 2. 遍历bio_vec,将数据地址写入硬件
for (i = 0; i < bio->bi_vcnt; i++, bvec++) {
dma_addr_t dma_addr = dma_map_page(&pdev->dev,
bvec->bv_page,
bvec->bv_offset,
bvec->bv_len,
rw == READ ? DMA_FROM_DEVICE : DMA_TO_DEVICE);
// 写入硬件寄存器(扇区、DMA地址、长度)
writel(bio_sector, data->reg_sector);
writel(dma_addr, data->reg_dma_addr);
writel(bvec->bv_len, data->reg_len);
writel(rw, data->reg_cmd); // 触发硬件I/O
bio_sector += bvec->bv_len / 512; // 扇区递增(512字节/扇区)
}
// 3. 等待硬件中断通知(简化:实际通过中断等待队列)
wait_for_completion(&data->completion);
// 4. 解除DMA映射,标记BIO完成
bvec = bio->bi_io_vec;
for (i = 0; i < bio->bi_vcnt; i++, bvec++) {
dma_unmap_page(&pdev->dev,
dma_map_page(&pdev->dev,
bvec->bv_page,
bvec->bv_offset,
bvec->bv_len,
rw == READ ? DMA_FROM_DEVICE : DMA_TO_DEVICE);
}
// 5. 调用BIO完成回调,释放BIO
bio_endio(bio, rw, bio->bi_size);
bio = bio->bi_next; // 处理下一个BIO
}
// 6. 释放请求,获取下一个请求
end_request(req, 1); // 1表示请求成功
req = elv_next_request(q);
}
}
// 中断处理函数:硬件完成I/O后触发
static irqreturn_t my_disk_irq_handler(int irq, void *dev_id) {
struct my_disk_data *data = dev_id;
complete(&data->completion); // 唤醒等待的请求处理函数
return IRQ_HANDLED;
}阶段5:BIO完成回调,通知上层
当硬件完成I/O操作后,流程进入收尾阶段:
- 驱动在中断处理函数中调用
complete(),唤醒等待的请求处理函数。 - 请求处理函数调用
bio_endio(),触发BIO的bi_end_io回调。 bi_end_io回调执行以下操作:- 释放BIO结构及其关联的
bio_vec数组。 - 更新页缓存:将读取到的数据标记为"有效"(如
SetPageUptodate())。 - 通知上层:唤醒等待I/O完成的进程(如通过
wake_up_page())。
- 释放BIO结构及其关联的
- 进程从
read()系统调用返回,获取到读取的数据。
BIO完成回调示例:
// BIO完成回调函数
static void bio_end_io_fn(struct bio *bio, int error) {
// 释放BIO资源
kfree(bio->bi_io_vec);
kfree(bio);
// 若为读操作,标记页缓存有效
if (bio->bi_rw == READ && !error) {
struct page *page = bio->bi_io_vec[0].bv_page;
SetPageUptodate(page);
wake_up_page(page); // 唤醒等待该页的进程
}
}三、关键技术细节与优化点
在实际驱动开发中,需关注以下技术细节,避免性能瓶颈或稳定性问题。
3.1 DMA映射:避免CPU拷贝
块设备I/O通常通过DMA(直接内存访问)实现,避免CPU参与数据拷贝。驱动需注意:
- DMA地址映射 :使用
dma_map_page()将物理内存页映射为DMA地址(硬件可直接访问),映射后需通过dma_unmap_page()释放。 - DMA方向 :读操作使用
DMA_FROM_DEVICE(数据从设备到内存),写操作使用DMA_TO_DEVICE(数据从内存到设备)。 - 缓存一致性 :若CPU缓存与DMA缓存不一致(如某些ARM架构),需使用
dma_sync_page()同步缓存数据。
3.2 请求队列参数配置
驱动需根据硬件能力配置请求队列参数,避免超出硬件限制导致I/O失败:
// 示例:配置请求队列参数(驱动初始化阶段)
struct request_queue *q = blk_init_queue(my_disk_request_fn, &lock);
if (!q) return -ENOMEM;
// 配置硬件限制(假设硬件支持最大8192扇区/请求)
blk_queue_max_sectors(q, 8192);
blk_queue_max_hw_sectors(q, 8192);
// 禁用分散-聚集(若硬件不支持)
// blk_queue_no_scatter_gather(q);
// 配置最小扇区对齐(如4K对齐)
blk_queue_physical_block_size(q, 4096);
// 关联驱动私有数据
q->queuedata = data;3.3 异步I/O与阻塞I/O的区别
块设备驱动需同时支持异步和阻塞I/O:
- 阻塞I/O :进程调用
read()后进入睡眠,直到I/O完成(如示例中的wait_for_completion())。 - 异步I/O :进程通过
aio_read()发起I/O后立即返回,I/O完成后通过信号或回调通知进程。驱动需在bi_end_io中调用io_complete()触发异步通知。
3.4 错误处理
驱动需妥善处理I/O错误(如磁盘扇区损坏):
- 在
end_request()中传递错误码(如end_request(req, 0)表示失败)。 - 在
bio_end_io()中设置bio->bi_error,并通知上层(如文件系统返回-EIO)。 - 支持硬件错误恢复(如重新尝试I/O、跳过坏扇区)。
四、总结
Linux块设备驱动中,请求队列与BIO的交互是连接软件与硬件的核心纽带:
- BIO作为I/O请求的"数据包",封装了数据地址、设备偏移等关键信息,支持分散-聚集操作。
- 请求队列作为"调度中心",负责接收BIO、构建请求、排序请求,并调用驱动处理逻辑。
- 交互流程涵盖BIO构建、提交、请求调度、硬件交互、完成回调5个阶段,每个阶段需关注并发安全、DMA映射、错误处理等细节。
掌握二者的交互原理,不仅能开发出稳定高效的块设备驱动,还能理解Linux内核I/O子系统的设计思想(如分层解耦、可扩展性)。对于高性能场景(如SSD、NVMe),还可通过自定义make_request_fn或I/O调度器,进一步优化I/O性能。