概述
超文本协议,可以传输文本和二进制数据(字符串)以及多媒体数据,典型的"一问一答"的模型
HTTP的应用场景
1)网页前端和服务器后端的通信
2)移动端app和服务器后端的通信
3)分布式系统服务器之间的调用
利用抓包工具,抓包是读取网卡上的内容从而让你看到请求和响应的数据明细,抓包就是相当于它们之间的代理
请求格式
|-----------------------------------------------------------------------------------------------------|
| 请求行:method URL version |
| 请求报头(header): key: value key: value .............. 有若干行,每一行都是键值对,此处的键值对都有特定含义,HTTP规定好的,键和值之间用:空格来分割 |
| 空行:说明header结束 |
| 请求正文 |
URL
唯一资源定位符,标识一个网络上的资源位置
|------------------------------------------------------------|
| http://user:pass@www.example.jp:80/dir/index.htm?uid=1#ch1 |http:// :协议方案名
user:pass :登陆信息认证
www.example:服务器地址(IP地址,通常是域名,当然写IP地址也是可以的)
80:服务器端口号,如果没有端口号会给一个默认值,浏览器根据协议类型按照对应的分配知名端口号,这里并不是操作系统分配由空闲的端口号
dir/index.htm:带层次的文件路径,但这个目录结构可能是真实存在的,也有可能是通过代码逻辑虚构的目录结构,但你按照目录结构访问服务器也会返回数据
uid=1:查询字符串(query string),&:分割键值对,=:分割键和值,这里的键值对是程序员自定义的
ch1:片段标识符,一般用来区分一个页面上的不同部分
URL uncode
对于query string有时候是需要进行转码的,因为URL中有很多特殊符号有特定的含义,但是query string是由程序员自定义的,万一里面包含了特殊符号呢
转码规则:标点符号和中文字符一般要进行转义,把要转义的内容,把字节拿出来转换成十六进制,然后再每个字节前面加上%
方法 method
是为了表示这个请求要做什么动作
GET:从服务器上获取资源,这个方法通常没有正文
POST:把数据发送到服务器上,一般有正文
POST和GET的区别:
本质上没有区别,就是能使用GET的时候也能使用POST,反过来同理,在使用习惯上有所区别
1)GET通常表示"获取数据"的语义,POST通常表示"提交数据"的语义
2)GET通常给服务器传递的数据放到query string,POST通常放到body当中
关于POST和GET之间的说法
1)GET的请求一般实现成幂等,POST没有幂等的要求,如果请求的结果是幂等的话是可以做缓存的,
幂等就是如果这个请求多次重复产生的结果是明确的
2)GET请求不安全,POST请求更安全**(错误的)**
GET实现登录,用户名密码出现URL的query string,显示在浏览器的地址栏里,POST会显示在body中不会在界面上,但是安全的关键是加密
3)GET请求单词的数据量比POST要小++(不准确)++
4)GET请求只能传输文本数据,POST可以传输文本和二进制++(不准确)++
二进制数据可以通过base64/urlencode转成文本,GET就可以传输了,但URL中确实不能放置二进制数据
请求报头
HOST:服务器主机和端口
Content-Length:表示body的数据长度,单位是字节
Content-Type:表示请求中body的数据格式,告诉服务器/浏览器怎么理解数据
Content-Length和Content-Type也可能出现在响应头中
Content-Type常见的取值:
text/html渲染网页的骨架
text/css渲染网页的样式
application/JavaScript执行js中的逻辑
application/json浏览器一般不自主处理,由浏览器的js负责
强制刷新(Ctrl+F5):涉及到浏览器缓存,强制刷新就可以从网络中获取,不读缓存了,浏览器通常会把变动频率低的数据保存到本机的硬盘上作为"缓存",下一次再访问同一个网站,就不必通过网咯获取这些数据,直接从硬盘上都就可以了
Uer-Agent:Mozilla/5.0 (Windows NT 10.0 ; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.8151 SLBChan/112 SLBVPV/64-bit
UA功能:
通过UA描述浏览器和操作系统的版本,对应着返回只有文本还是多媒体的网页
区分用户设备PC和手机
Refer:表示这个页面是从哪个页面跳转过来的,让服务器知道,和浏览器的前进后退没有关系
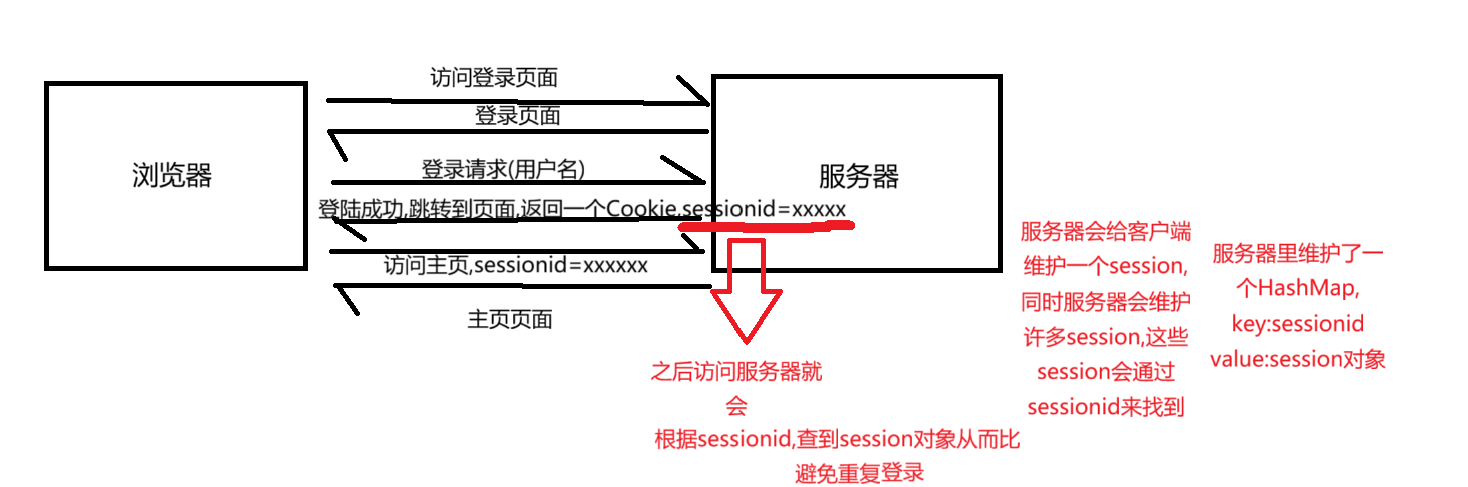
Cookie:一系列键值对,键值对用;分割,键和值用=分割
浏览器给网页提供的本地存储数据的方式,但对网页访问本地硬盘做出了限制
Cookie从服务器当中来,以键值对方式存储,根据域名划分,,每个域名都有自己的cookie,本地存储之后,访问同一个域名的网站,就会把cookie的内容通过请求报头传递给服务器
通过Cookie保护用户的登录状态:
响应格式
|--------------------------------------------|
| 状态行:version 状态码 状态码描述 |
| 响应报头: key: value key: value .............. |
| 空行 |
| 响应正文 |
状态码
301永久重定向(可以做缓存)
302临时重定向
重定向就是类似于呼叫转移,例如访问u1,就会跳转到访问u2
浏览器作为HTTP客户端虽然很强但是并不能够随性所欲的构造HTTP请求
HTTPS
在HTTP基础上,引入了一个加密层
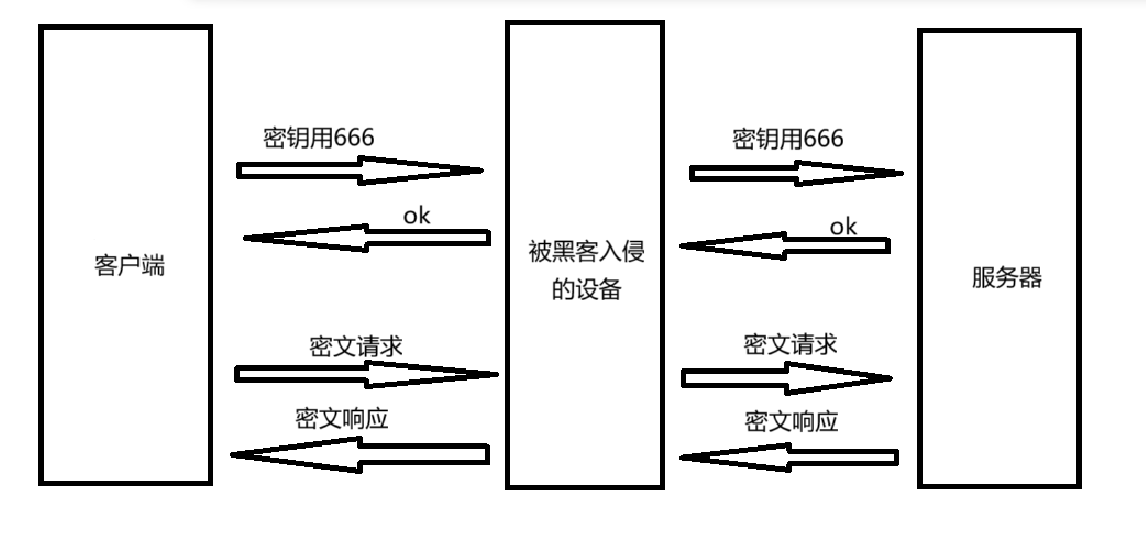
对称密钥
一个密钥既可以加密也可以解密
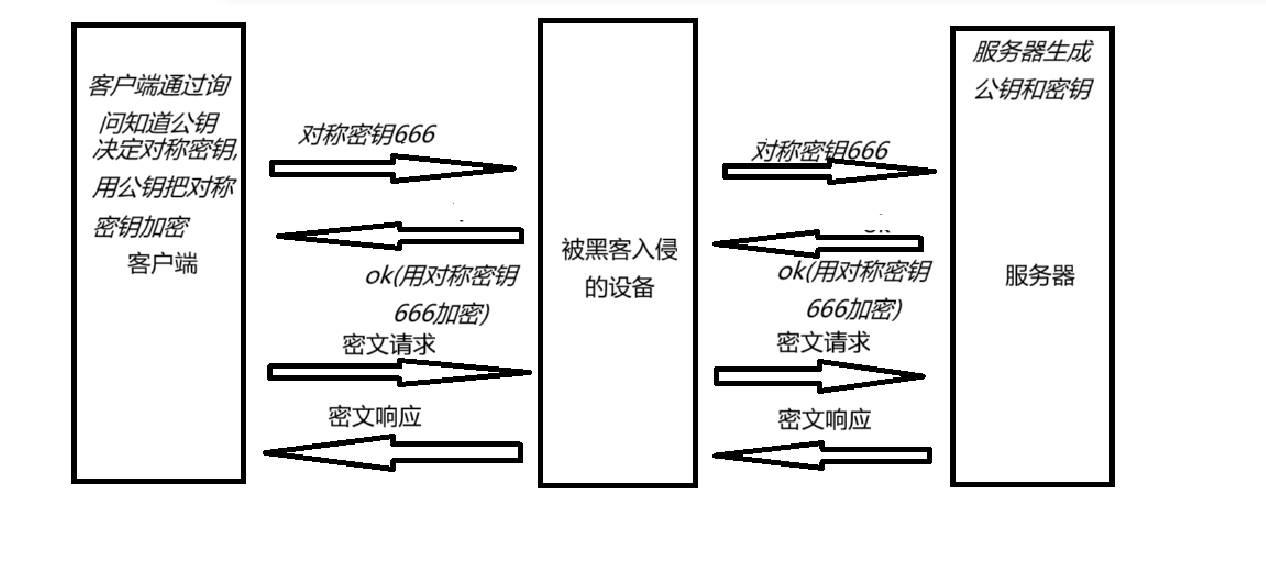
非对称密钥
有两个密钥,假设分别为key1,key2,如果key1加密,那么key2就解密,如果key1解密,那么key就加密
一个密钥公开就是"公钥",另一个自己保存就是"私钥"
引入对称加密
引入非对称加密
中间人攻击
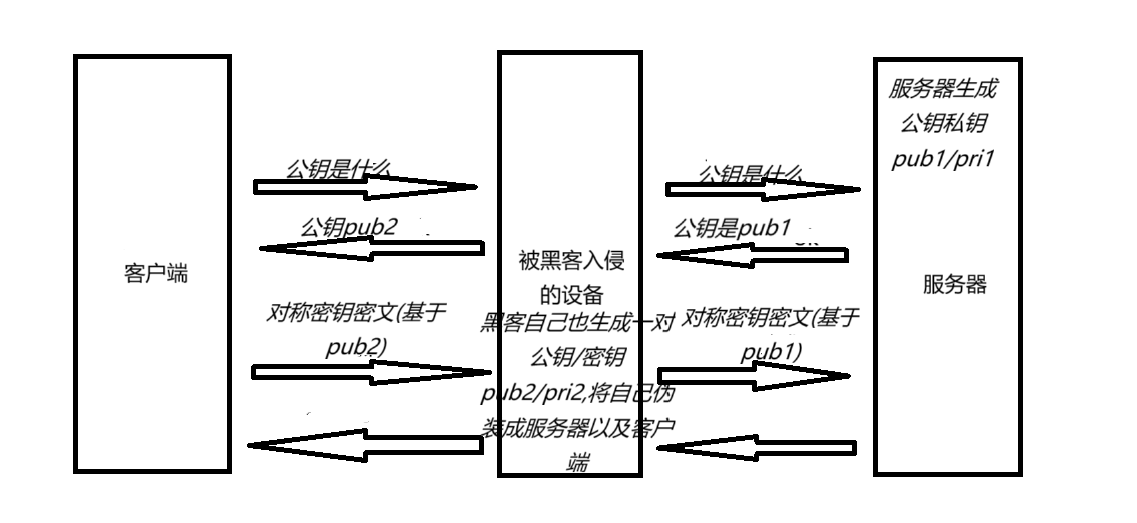
应对中间人攻击
引入证书
证书里面的内容:证书发布的机构,证书的有效期,公钥pub1,证书的所有者........以及签名
证书里面的签名相当于加密的校验和,就是先计算校验和,然后用公证机构自己生成的对称密钥pub3/pri3,pri3对校验和进行加密,得到签名
客户端验证证书的真实性:
1.客户端使用相同算法计算校验和,得到check1
2.客户端用pub3对签名进行解密,得到check2
3.若check1=check2则证书有效