Spark SQL 的自动加盐优化核心用于解决数据倾斜场景下的聚合 / Join 性能问题 ,其源码逻辑主要分散在 Catalyst 优化器(逻辑计划优化) 和 Adaptive Query Execution (AQE) 执行引擎(运行时优化) 中,且针对 普通聚合(sum/count) 和 count(distinct) 的处理逻辑存在差异。以下从源码架构、核心模块、关键逻辑三方面拆解说明。
一、源码核心架构与关键模块
自动加盐的本质是动态修改物理执行计划 :通过给倾斜的 Key 附加随机盐值,将大 Key 拆分为多个子 Key 分散到不同任务,再通过二次聚合还原结果。核心涉及以下源码模块(基于 Spark 3.3+ 版本):
| 模块层级 | 核心类 / 对象 | 作用 |
|---|---|---|
| 逻辑计划优化 | org.apache.spark.sql.catalyst.optimizer.AggregateOptimizer |
静态优化:预处理聚合逻辑,为加盐做准备(如拆分 count(distinct) 为两次聚合) |
| AQE 倾斜检测 | org.apache.spark.sql.execution.adaptive.SkewDetectUtil |
运行时检测:判断分区是否倾斜(基于分区大小、数据量阈值) |
| AQE 计划调整 | org.apache.spark.sql.execution.adaptive.SkewJoinOptimizer |
运行时优化:针对 Join 倾斜触发加盐拆分;聚合倾斜需依赖 AggregateSkewOptimizer(部分版本需手动开启) |
| 物理执行 | org.apache.spark.sql.execution.aggregate.AggregateExec |
聚合执行:处理加盐后的局部 / 全局聚合逻辑 |
| Shuffle 分区 | org.apache.spark.shuffle.ShuffleDependency |
分区控制:基于加盐后的 Key 重新分配分区 |
二、核心源码逻辑拆解
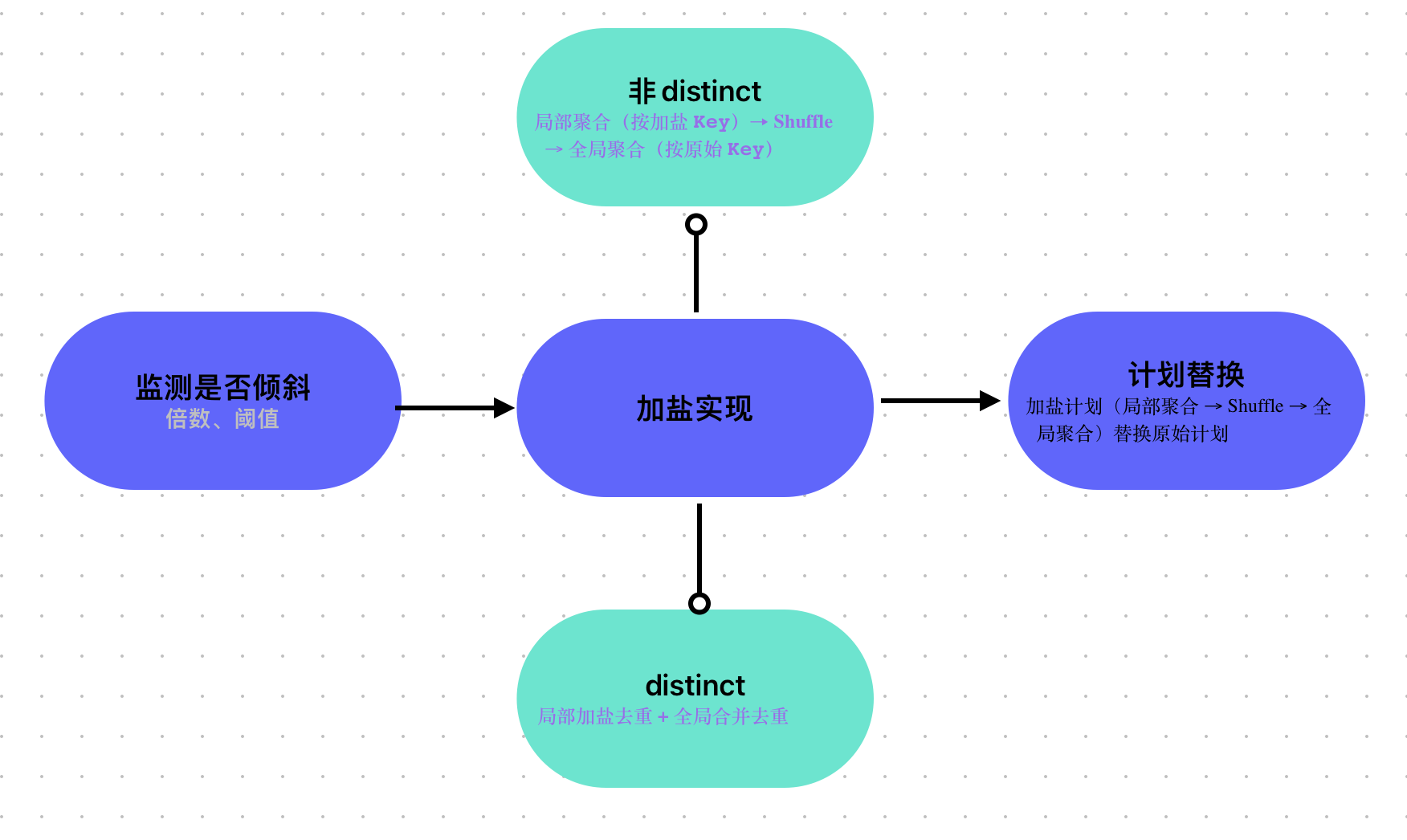
1. 第一步:倾斜检测(Skew Detection)------ 加盐的前提
自动加盐的触发依赖运行时倾斜检测 ,源码核心在 SkewDetectUtil 类中,逻辑如下:
Scala
// 核心方法:判断一个分区是否为倾斜分区
def isSkewed(
partitionSize: Long,
medianSize: Long,
skewedPartitionFactor: Double,
skewedPartitionThresholdInBytes: Long): Boolean = {
// 两个条件满足其一即判定为倾斜:
// 1. 分区大小 > 中位数大小 * 倾斜因子(默认 skewedPartitionFactor=5)
// 2. 分区大小 > 倾斜阈值(默认 skewedPartitionThresholdInBytes=10GB)
(partitionSize > medianSize * skewedPartitionFactor) &&
(partitionSize > skewedPartitionThresholdInBytes)
}- 触发流程 :
- AQE 执行时,
AdaptiveSparkPlanExec会收集 Shuffle 后的分区统计信息(大小、数据量)。 - 调用
SkewDetectUtil.isSkewed计算分区中位数,对比每个分区是否满足倾斜条件。 - 若检测到倾斜分区,触发后续加盐 / 拆分逻辑。
- AQE 执行时,
2. 第二步:加盐策略实现(核心逻辑)
加盐的核心是修改 Key 的编码逻辑,并调整聚合计划为 "局部聚合 + 全局聚合"。根据聚合类型(普通聚合 /count(distinct)),源码逻辑不同:
(1)普通聚合(sum/count)的加盐源码
针对 group by key + sum(xxx) 这类可拆分聚合,加盐逻辑较直接,核心在 AggregateSkewOptimizer 中:
Scala
// 简化逻辑:给倾斜的 Key 附加随机盐值(如 key → key_salt)
def addSaltToSkewedKey(
keyExpr: Expression,
skewedKeys: Set[Any],
saltCount: Int): Expression = {
// 判断当前 Key 是否为倾斜 Key
val isSkewed = If(
In(keyExpr, Literal.create(skewedKeys.toSeq, keyExpr.dataType)),
// 倾斜 Key:附加随机盐值(0 ~ saltCount-1)
Concat(keyExpr, Literal("_"), Rand(saltCount).cast(IntegerType)),
// 非倾斜 Key:保持不变
keyExpr
)
isSkewed
}
// 调整聚合计划:局部聚合 → 加盐 Shuffle → 全局聚合
def optimizeAggregateSkew(plan: SparkPlan): SparkPlan = plan match {
case agg: AggregateExec =>
// 1. 检测倾斜 Key(从 skewedKeys 中获取)
val skewedKeys = getSkewedKeys(agg)
if (skewedKeys.nonEmpty) {
// 2. 生成加盐后的 Key 表达式
val saltedKey = addSaltToSkewedKey(agg.groupingExpressions.head, skewedKeys, 10)
// 3. 构建局部聚合计划(按加盐 Key 聚合)
val partialAgg = agg.copy(
groupingExpressions = Seq(saltedKey),
aggregateExpressions = agg.aggregateExpressions.map(_.copy(mode = Partial))
)
// 4. 构建全局聚合计划(按原始 Key 聚合)
val globalAgg = agg.copy(
groupingExpressions = agg.groupingExpressions,
aggregateExpressions = agg.aggregateExpressions.map(_.copy(mode = Final))
)
// 5. 组装新计划:局部聚合 → Shuffle → 全局聚合
ShuffleExchangeExec(..., partialAgg) → globalAgg
} else {
agg
}
case _ => plan
}- 关键逻辑 :
- 倾斜
Key附加随机盐值(如user1 → user1_3),非倾斜Key不变; - 聚合计划拆分为 "局部聚合(按加盐
Key)→ Shuffle → 全局聚合(按原始Key)",保证 sum/count 结果正确。
- 倾斜
(2)count (distinct) 的加盐源码(更复杂)
count(distinct) 需保证全局去重,加盐后需额外处理 "局部加盐去重 + 全局合并去重",核心在 AggregateOptimizer 的 OptimizeCountDistinct 规则中:
Scala
// 简化逻辑:将 count(distinct col) 拆分为两次聚合
object OptimizeCountDistinct extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan.transformDown {
case agg: Aggregate if hasCountDistinct(agg) =>
// 1. 提取 count(distinct) 相关表达式(如 count(distinct order_id))
val (distinctAggs, otherAggs) = splitCountDistinctAggs(agg)
// 2. 第一次聚合:加盐 + 局部去重(用 CollectSet 收集局部唯一值)
val partialAgg = Aggregate(
// 分组 Key:原始 Key + 盐值(随机数)
agg.groupingExpressions :+ Rand(10).cast(IntegerType) as "salt",
// 聚合表达式:CollectSet(distinct_col) → 局部去重
distinctAggs.map(agg => CollectSet(agg.child) as agg.name) ++ otherAggs,
agg.child
)
// 3. 第二次聚合:去盐 + 全局去重(展开 CollectSet 并计数)
val globalAgg = Aggregate(
agg.groupingExpressions, // 恢复原始 Key(去掉盐值)
// 全局去重:展开局部 CollectSet,再用 Count(Distinct) 统计
distinctAggs.map(agg =>
Count(Distinct(Explode(agg.name))) as agg.name
) ++ otherAggs,
partialAgg
)
globalAgg
}
}- 关键逻辑 :
- 第一次聚合:按 "原始 Key + 盐值" 分组,用
CollectSet收集局部唯一的distinct字段(如order_id),实现局部去重; - 第二次聚合:去掉盐值,按原始 Key 分组,通过
Explode展开局部CollectSet,再用Count(Distinct)实现全局去重; - 核心是通过
CollectSet保证 "局部去重后全局合并",避免直接拆分导致的结果错误。
- 第一次聚合:按 "原始 Key + 盐值" 分组,用
3. 第三步:执行计划的动态替换
AQE 会将优化后的加盐计划(局部聚合 → Shuffle → 全局聚合)替换原始计划,核心在 AdaptiveSparkPlanExec 的 optimizePlan 方法:
Scala
override def optimizePlan(plan: SparkPlan): SparkPlan = {
var optimized = plan
// 1. 检测倾斜分区
val skewedPartitions = detectSkewedPartitions(optimized)
if (skewedPartitions.nonEmpty) {
// 2. 针对聚合倾斜,应用加盐优化
optimized = new AggregateSkewOptimizer(session, skewedPartitions).optimize(optimized)
// 3. 针对 Join 倾斜,应用拆分优化(SkewJoinOptimizer)
optimized = new SkewJoinOptimizer(session, skewedPartitions).optimize(optimized)
}
// 4. 返回优化后的计划
optimized
}- 运行时,
AdaptiveSparkPlanExec会动态生成加盐后的物理计划,并提交任务执行,用户无需感知底层细节。
三、关键配置与源码关联
自动加盐的触发和行为由以下配置参数控制,配置参数如下:
| 配置参数 | 源码默认值 | 作用 |
|---|---|---|
spark.sql.adaptive.enabled |
false |
开启 AQE(必须开启,否则无法触发自动加盐) |
spark.sql.adaptive.skewJoin.enabled |
true(AQE 开启时) |
开启 Join 倾斜的加盐 / 拆分 |
spark.sql.adaptive.skewedPartitionFactor |
5.0 |
倾斜判断因子(分区大小 > 中位数 * 5 则判定为倾斜) |
spark.sql.adaptive.skewedPartitionThresholdInBytes |
10GB |
倾斜分区大小阈值(超过则判定为倾斜) |
spark.sql.optimizer.aggregateSkew.enabled |
false(部分版本) |
开启聚合倾斜的自动加盐(需手动开启) |
验证自动加盐是否生效
可通过 Spark UI 验证:
- 进入 SQL 页面 ,查看优化后的物理计划(
AdaptiveSparkPlan)。 - 若出现 "PartialAggregate"→"ShuffleExchange"→"FinalAggregate" 结构,且 Shuffle 分区数比原始多(对应加盐拆分),说明自动加盐已触发。
四、局限性
- 自动化程度有限 :
count(distinct)的自动加盐在 Spark 3.3+ 中仍需手动开启spark.sql.optimizer.aggregateSkew.enabled,且++仅支持单个 distinct 字段++; - 依赖 AQE 倾斜检测 :若倾斜分区未被
SkewDetectUtil检测到(如阈值配置不合理),则无法触发加盐; - 盐值数量固定 :源码中盐值数量(拆分后的子分区数)默认由
Rand(saltCount)控制(通常为 10),无法动态调整。 - 对于多字段
count(distinct)(如count(distinct a), count(distinct b)),AggregateOptimizer会避免将多个distinct挤压到单个聚合阶段(可能导致数据倾斜或低效),而是通过拆分逻辑计划,为每个distinct字段生成独立的局部聚合逻辑,再在全局聚合中合并结果。
五、实施示例
Scala
-- 1. 开启 AQE 框架(自动加盐的基础)
SET spark.sql.adaptive.enabled = true;
-- 2. 开启聚合倾斜自动优化(部分版本默认关闭,需手动开启)
SET spark.sql.optimizer.aggregateSkew.enabled = true;
-- 3. 倾斜分区判定阈值(根据业务调整,默认 5 倍中位数、10GB)
-- 分区大小 > 中位数*5 且 >10GB → 判定为倾斜
SET spark.sql.adaptive.skewedPartitionFactor = 5.0;
SET spark.sql.adaptive.skewedPartitionThresholdInBytes = 10737418240; -- 10GB
-- 4. (可选)Join 倾斜的自动加盐(若涉及 Join+聚合倾斜)
SET spark.sql.adaptive.skewJoin.enabled = true;手动加盐示例
sql
-- 第一步:加盐+局部去重(按 user_id+盐值 分组,收集局部唯一订单)
WITH partial_agg AS (
SELECT
user_id,
-- 给倾斜 Key 加随机盐值(0-9,拆分为10个子分区)
FLOOR(RAND() * 10) AS salt,
COLLECT_SET(order_id) AS partial_orders -- 局部去重,避免重复
FROM orders
GROUP BY user_id, salt
),
-- 第二步:去盐+全局去重(展开局部结果,统计全局唯一值)
global_agg AS (
SELECT
user_id,
-- 展开 CollectSet 结果,再做全局 count(distinct)
COUNT(DISTINCT order_id) AS unique_order_count
FROM partial_agg
LATERAL VIEW EXPLODE(partial_orders) AS order_id -- 展开局部唯一订单
GROUP BY user_id
)
SELECT * FROM global_agg;总结
Spark SQL 自动加盐的源码逻辑围绕 "倾斜检测 → 加盐改造 → 计划替换" 三个核心步骤,通过 Catalyst 优化器静态拆分聚合逻辑,结合 AQE 运行时动态调整执行计划,实现大 Key 分散处理。对于 count(distinct),源码通过 "两次聚合 + CollectSet 局部去重" 绕开全局去重的限制,保证结果正确的同时提升性能。
| 场景 | 配置要求 | SQL 写法特点 | 适用版本 |
|---|---|---|---|
| 普通聚合自动加盐 | 通用配置(AQE + 聚合倾斜开启) | 常规 SQL,无特殊写法 | Spark 3.2+ |
| count (distinct) 自动 | 通用配置 + count (distinct) 优化开启 | 常规 SQL,无特殊写法 | Spark 3.4+ 推荐 |
| count (distinct) 手动 | 无需额外配置(依赖常规 Shuffle 配置) | 显式加盐 + 两次聚合 + EXPLODE | 所有版本 |
(欢迎订阅、讨论、转载)
推荐内容:
大数据计算引擎-全阶段代码生成(Whole-stage Code Generation)与火山模型(Volcano)对比