网络基础与 HTTP 协议
文章目录
- [网络基础与 HTTP 协议](#网络基础与 HTTP 协议)
-
- 一、网络爬虫的"底层通信"
- 二、URL:统一资源定位符
-
- [1. URL 的定义](#1. URL 的定义)
- [2. URL的组成部分](#2. URL的组成部分)
- [3. URL编码](#3. URL编码)
- [三、HTTP 协议](#三、HTTP 协议)
-
- [1. HTTP 请求与响应模型](#1. HTTP 请求与响应模型)
- [2. HTTP请求报文结构](#2. HTTP请求报文结构)
- [3. 常见请求方法](#3. 常见请求方法)
- [4. HTTP 响应结构](#4. HTTP 响应结构)
- [5. 常见HTTP状态码](#5. 常见HTTP状态码)
- 四、HTML:超文本标记语言
-
- [1. 基本结构](#1. 基本结构)
- [2. 网页的层次结构](#2. 网页的层次结构)
- 五、User-Agent用户代理
-
- [1. 定义](#1. 定义)
- [2. 常见UA](#2. 常见UA)
- [3. 爬虫中伪装UA](#3. 爬虫中伪装UA)
一、网络爬虫的"底层通信"
网络爬虫的本质就是:
模拟浏览器向服务器发送请求 → 获取网页内容 → 提取有用数据
这个过程主要依靠下面的机制实现:
- 网络协议(TCP/IP)
- HTTP(超文本传输协议)
- HTML 网页结构
- User-Agent 浏览器标识
二、URL:统一资源定位符
1. URL 的定义
URL是互联网上资源的地址,就像网页的"门牌号"。
格式结构:
协议://主机名:端口/路径?参数#锚点案例:

http
https://blog.csdn.net/qq_64736204?type=blogColumn解读
- 协议 :https,是一种通过SSL/TLS对传输的数据进行加密的安全通信协议;
- 主机名:blog.csdn.net,主机名即服务器的域名,浏览器需要通过DNS域名解析协议把域名转为服务器的IP,才能与服务器进行通信;
- 端口 :没有显示指定,此时使用https协议的默认端口443,完整的访问地址应该是
blog.csdn.net:443; - 路径 :/qq_64736204,指明了在服务器上要访问的特定资源位置,
qq_64736204是用户的ID,应着CSDN博客平台上的个人博客主页; - 参数 :type=blogColumn,以?开头,这里有一个参数对: 参数名 : type,参数值: blogColumn,该参数告诉CSDN服务器需要访问用户qq_64736204的"博客专栏";
- 锚点 :无,锚点以**#开头,用于指向网页内部的某个特定片段或标题**。由于它不存在,浏览器会默认显示该页面的顶部。
2. URL的组成部分
| 部分 | 含义 | 如下案例 |
|---|---|---|
| 协议 | 使用的通信方式 | http, https, ftp |
| 主机名 | 服务器域名或IP地址 | www.douban.com |
| 端口号 | 网络服务接口(默认80/443) | :443 |
| 路径 | 服务器资源的路径 | /search |
| 参数 | 请求携带的键值对 | q=python |
| 锚点 | 网页内部定位(不会发给服务器) | #result |
3. URL编码
某些特殊字符如空格、中文等在URL中不能直接使用,必须进行URL编码。
案例:
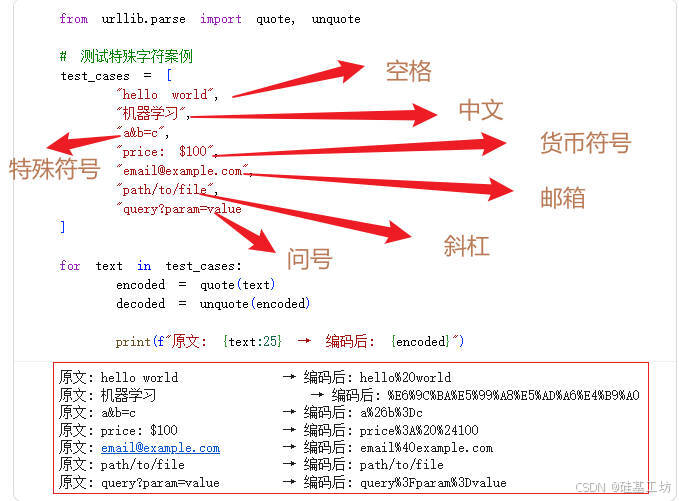
注意:当请求的URL中有中文参数时(如"电影/小说/天气"),必须使用
urllib.parse.quote()编码后再请求。
三、HTTP 协议
HTTP是客户端与服务器之间通信的规则。爬虫中,我们使用Python构建HTTP客户端,通过模拟浏览器的请求头、会话管理和协议交互,遵循HTTP规范向目标服务器发起请求并处理响应,实现网页数据的自动化采集。
1. HTTP 请求与响应模型
通信流程图:
客户端(浏览器 / 爬虫) 服务器(Web Server) 建立TCP连接(三次握手) HTTP 请求(Request) 包含:URL、Headers、Body 服务器接收请求并进行处理 例如:读取数据库、生成网页内容 HTTP 响应(Response) 包含:状态码、响应头、HTML内容 客户端解析HTML并渲染网页或提取数据 关闭TCP连接(四次挥手) 客户端(浏览器 / 爬虫) 服务器(Web Server)
2. HTTP请求报文结构
一个完整的请求主要包括如下:
说明
GET:请求方法,表示客户端要获取资源;
/1.png?..:请求路径与查询参数URL。表明客户端要访问服务器的 /1.png 文件;
HTTP/1.1:表示使用的 HTTP 协议版本;
Accept :表示客户端能接收的响应类型,这里表示浏览器支持多种图片格式(avif、webp、apng、svg+xml),*/* 表示可以接受任何类型;
Accept-Encoding:支持的压缩格式。服务器可以用这些算法压缩响应体以减少传输体积。gzip是最常见的压缩方式,br是Google推出的压缩方法,zstd是Facebook开发的压缩算法;
Accept-Language:浏览器首选语言是中文;
Connection: keep-alive,表示建立持续的TCP连接,避免重复建立连接;
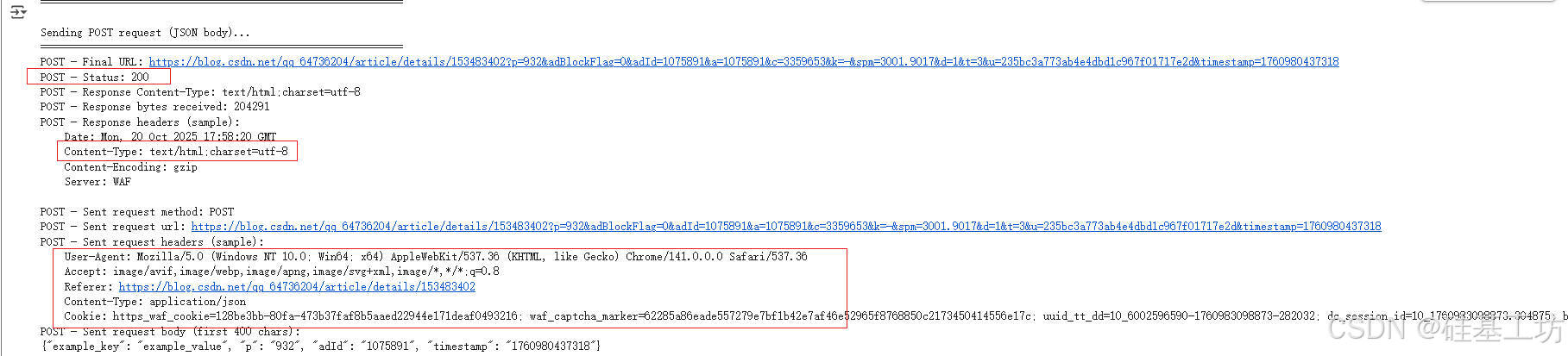
Cookie :存储了 用户身份信息、登录状态;作用是让服务器识别你是谁;
Host:目标服务器域名,在HTTP/1.1是必需字段;
User-Agent:标识客户端信息,浏览器类型、操作系统,服务器用它判断请求来自浏览器、爬虫还是移动设备。
| 部分 | 说明 |
|---|---|
| 请求行 | 请求方法 + 路径 + 协议版本 |
| 请求头 | 浏览器标识、接收类型、cookie |
| 请求体 | 一般在POST请求中携带数据 |
3. 常见请求方法
| 方法 | 功能 | 说明 |
|---|---|---|
| GET | 获取资源 | 获取网页、图片、API数据 |
| POST | 提交数据 | 表单登录、搜索提交 |
| PUT | 更新资源 | 更新数据库数据 |
| DELETE | 删除资源 | 删除记录 |
| HEAD | 获取响应头 | 检查网页是否存在 |
get请求
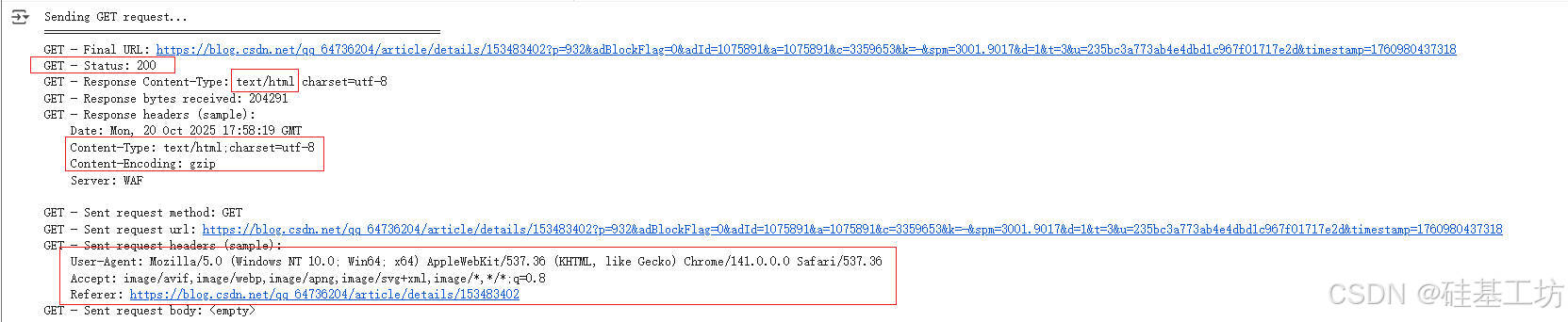
渲染并打印 HTML 内容
原文对比
post请求
4. HTTP 响应结构
响应头结构

响应体结构
网页主体内容
html
<body class="nodata " style="">
<div id="toolbarBox" style="min-height: 48px;"></div>
...
</body><body>:承载网页主要可见内容;- 工具栏 、正文区域 、广告栏 、评论区内容均在此定义;
- CSDN博客的页面是动态加载的,部分内容由 JavaScript 渲染
汇总表
| 部分 | 含义 | 案例 |
|---|---|---|
| 状态行 | 协议版本 + 状态码 + 状态描述 | HTTP/1.1 200 OK |
| 响应头 | 服务器类型、内容格式、缓存策略 | Date: Tue, 21 Oct 2025 17:26:29 GMT |
| 响应体 | 实际网页内容 | ... |
5. 常见HTTP状态码
| 状态码 | 类型 | 含义 |
|---|---|---|
| 200 | 成功 | 请求成功 |
| 301 / 302 | 重定向 | 页面跳转 |
| 403 | 禁止访问 | IP封禁、无权限 |
| 404 | 未找到 | URL错误 |
| 500 | 服务器错误 | 程序异常 |
在爬虫中,我们需要用状态码判断爬取是否成功。
四、HTML:超文本标记语言
HTML 是网页的结构语言,爬虫要"提取数据",必须理解它的标签层级。
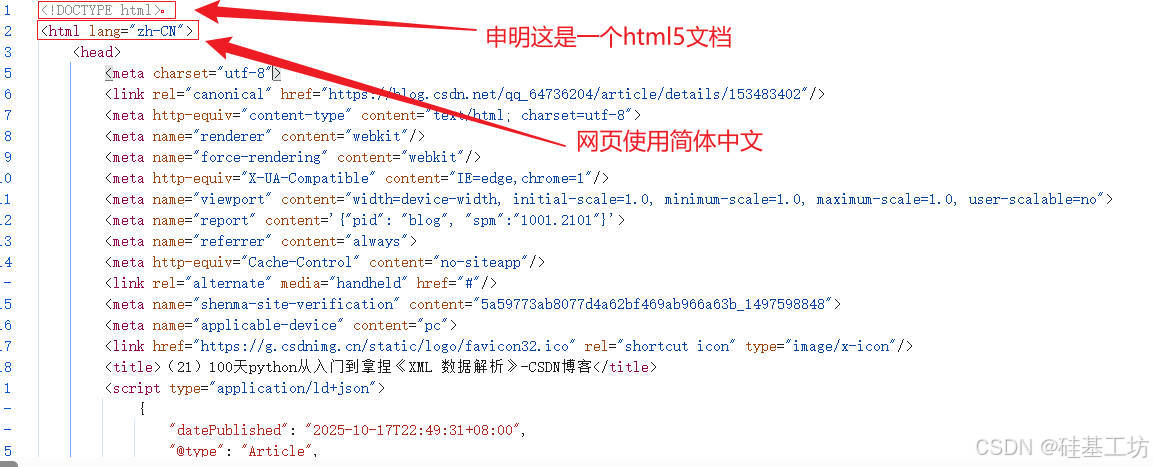
1. 基本结构
html
<!DOCTYPE html>
<html>
<head>
<title>(21)100天python从入门到拿捏《XML 数据解析》-CSDN博客</title>
</head>
<body>
<h1 class="title-article" id="articleContentId">(21)100天python从入门到拿捏《XML 数据解析》</h1>
<p>
<strong>YAML</strong>
:缩进表示层级 ,支持简短语法、序列及锚点 ,允许注释。
</p>
<a href="https://blog.csdn.net/qq_64736204/article/details/153224770">100天python从入门到拿捏《JSON 数据解析》
</a>
</body>
</html>| 标签 | 含义 |
|---|---|
<head> |
元信息如标题、编码 |
<body> |
页面主体 |
<h1>~<h6> |
标题 |
<p> |
段落 |
<a> |
超链接 |
<img> |
图片 |
<div> / <span> |
区块 / 内联容器 |
2. 网页的层次结构
HTML被浏览器解析成"文档对象模型,即DOM树":
DOM层级图:
html
<html> ← 根节点(整个HTML文档)
├── <head> ← 文档头部(元数据、标题、样式)
│ ├── <meta charset="utf-8"> ← 指定字符编码
│ ├── <title>网页标题</title> ← 显示在浏览器标签页上
│ ├── <link rel="stylesheet" href="style.css"> ← 外部CSS
│ └── <script src="main.js"></script> ← 外部JavaScript文件
│
└── <body> ← 网页主体内容(用户可见部分)
├── <header> ← 页眉,通常包含LOGO或导航栏
│ └── <h1>网站主标题</h1>
│
├── <nav> ← 导航栏
│ ├── <a href="#home">首页</a>
│ ├── <a href="#about">关于</a>
│ └── <a href="#contact">联系</a>
│
├── <main> ← 主体内容区域
│ ├── <section> ← 内容区块
│ │ ├── <h2>章节标题</h2>
│ │ └── <p>正文段落内容......</p>
│ └── <article> ← 单篇文章或独立内容
│ ├── <h2>文章标题</h2>
│ ├── <p>文章内容......</p>
│ └── <a href="#">阅读更多</a>
│
├── <aside> ← 侧边栏,可放广告、推荐链接等
│ └── <p>侧栏内容</p>
│
└── <footer> ← 页脚,包含版权信息
└── <p>© 2025 MyWebsite. All rights reserved.</p>爬虫提取数据的本质:在 DOM 树中找到目标节点,读取标签属性或文本内容。
五、User-Agent用户代理
1. 定义
User-Agent 是HTTP请求头的一部分,用于向服务器表明客户端身份。
如:
http
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/121.0服务器会根据 UA:
- 判断你是 PC、手机还是爬虫
- 返回对应版本网页
- 有时用来识别和封禁爬虫
2. 常见UA
| 类型 | 例子 |
|---|---|
| Chrome 浏览器 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/121.0 |
| iPhone Safari | Mozilla/5.0 (iPhone; CPU iPhone OS 15_0) AppleWebKit/605.1.15 |
| 爬虫工具 | Python-urllib/3.9, Scrapy/2.9 |
3. 爬虫中伪装UA
案例:
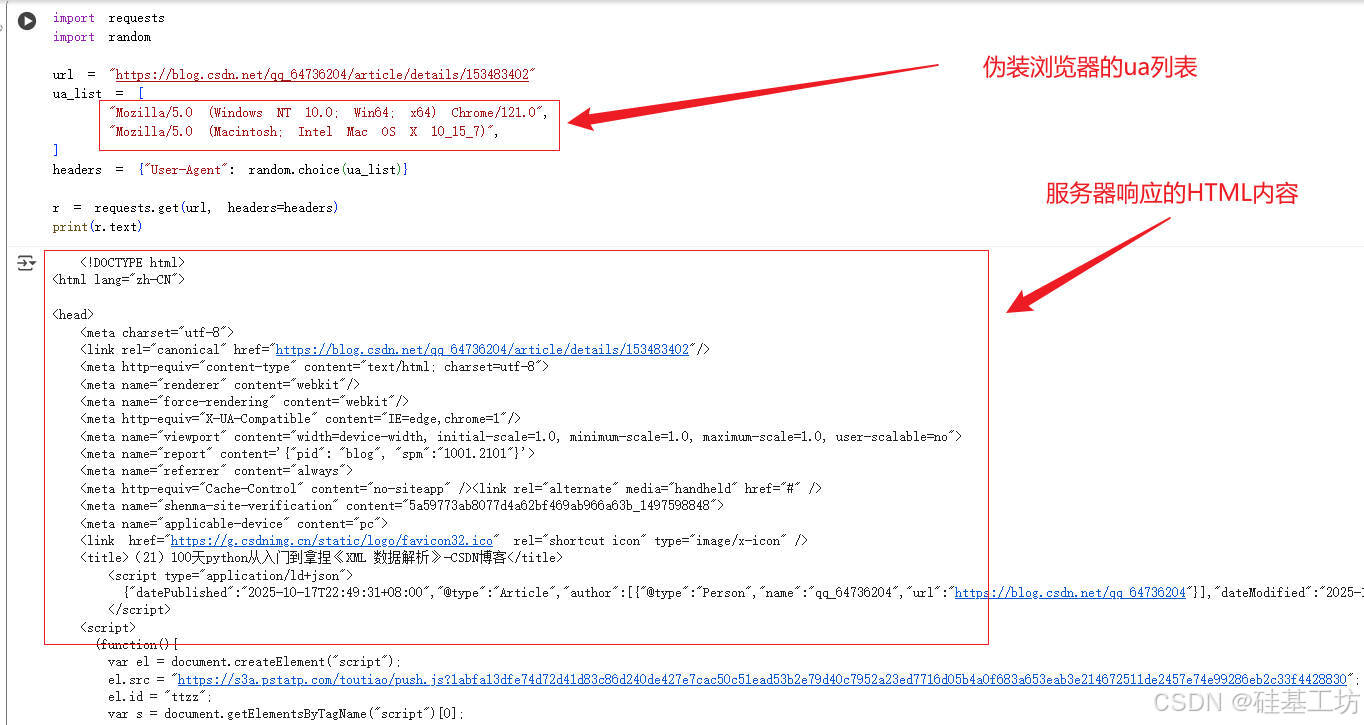
py
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)",
]这里的伪装UA列表中第一个是Windows系统,第二个是Mac OS系统
为什么要伪装?
- 防止被网站识别为爬虫,Python默认UA容易被封
- 模拟真实浏览器访问行为
python学习专栏导航
(1)100天python从入门到拿捏《Python 3简介》
(2)100天python从入门到拿捏《python应用前景》
(3)100天python从入门到拿捏《数据类型》
(4)100天python从入门到拿捏《运算符》
(5)100天python从入门到拿捏《流程控制语句》
(6)100天python从入门到拿捏《推导式》
(7)100天python从入门到拿捏《迭代器和生成器》
(8)100天python从入门到拿捏《函数和匿名函数》
(9)100天python从入门到拿捏《装饰器》
(10)100天python从入门到拿捏《Python中的数据结构与自定义数据结构》
(11)100天python从入门到拿捏《模块》
(12)100天python从入门到拿捏《文件操作》
(13)100天python从入门到拿捏《目录操作》
(14)100天python从入门到拿捏《Python的错误与异常机制》
(15)100天python从入门到拿捏《面向对象编程》
(16)100天python从入门到拿捏《标准库》
(17)100天python从入门到拿捏《正则表达式》
(18)100天python从入门到拿捏《网络编程》
(19)100天python从入门到拿捏《多线程》
(20)100天python从入门到拿捏《JSON 数据解析》
(21)100天python从入门到拿捏《XML 数据解析》