在检索增强生成(RAG)技术的落地过程中,架构的扩展性与数据存储的高效性是决定系统能否适配复杂场景的关键。此前我们已梳理过 RAG 基础流程与本地文档处理逻辑,而实际应用中,单一文本处理已无法满足图文混合、多格式文件交互的需求。本篇将聚焦多模态 RAG 架构的设计逻辑,结合 Milvus 向量数据库的实战落地,拆解从架构规划到代码实现的全流程,帮助开发者掌握企业级 RAG 系统的核心技术要点。
一、先搞懂:多模态 RAG 架构的核心逻辑
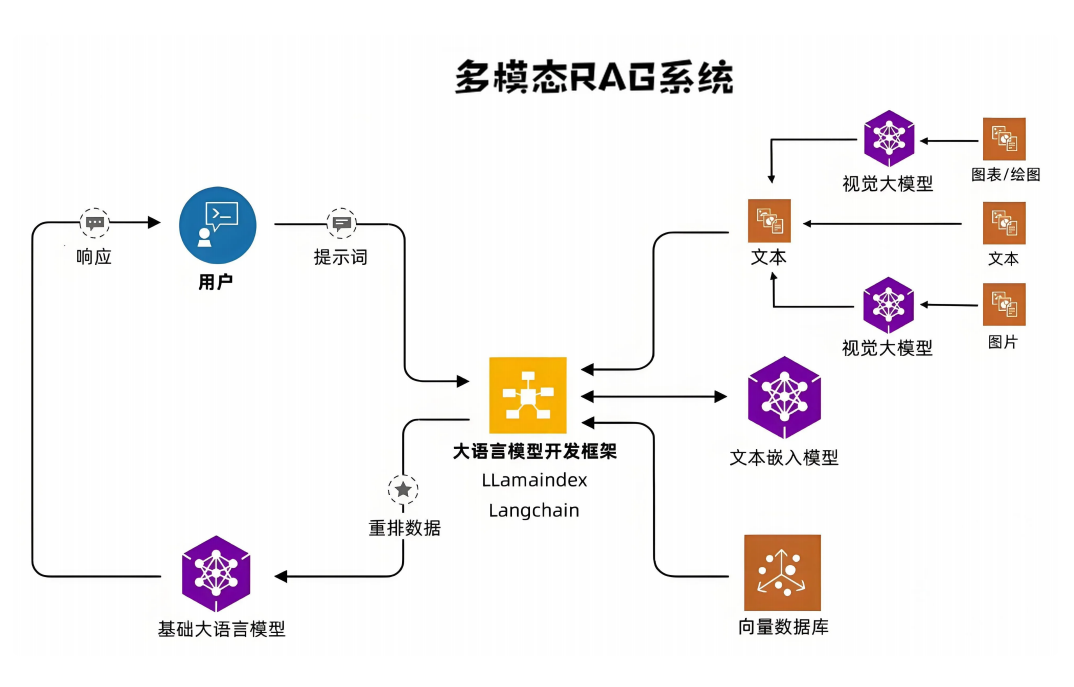
传统 RAG 系统多聚焦于文本数据处理,但实际场景中往往需要处理图片、图表、音频等多模态内容。根据多模态 RAG 架构设计,我们先明确其核心组成与数据流向,为后续开发奠定基础。
1.1 多模态 RAG 架构的核心组件
多模态 RAG 系统在传统文本 RAG 基础上,新增了视觉大模型 与多模态数据处理模块,整体由五大核心部分构成:
- 数据输入层:支持非结构化数据(文本、图片、图表、音频、视频)、结构化数据(数据库表)、半结构化数据(Excel、JSON),覆盖实际场景中绝大多数数据类型;
- 模态处理层:文本数据通过 "文本嵌入模型" 转化为向量,图片 / 图表通过 "视觉大模型"(如课件中提及的图表解析模型)提取语义特征,音频 / 视频则需先转文字再进行嵌入处理;
- 向量存储层:采用 Milvus 向量数据库存储各类数据的嵌入向量,支持高速相似性检索与百亿级向量扩展,解决传统数据库无法高效处理向量数据的问题;
- 检索与生成层:结合 LlamaIndex 框架的重排功能与 Langchain 工具链,先从 Milvus 检索相关向量,再通过大语言模型(如 DeepSeek、Moonshot)生成符合上下文的回答;
- 交互层:通过 Chainlit 构建自定义前端界面,支持文件上传、多模态内容预览、问答交互,同时兼容本地部署与远程服务调用,满足不同使用场景需求。
1.2 多模态 vs 传统 RAG:核心差异在哪?
| 对比维度 | 传统 RAG 系统 | 多模态 RAG 系统 |
|---|---|---|
| 数据类型 | 仅支持文本数据 | 文本、图片、图表、音频、视频等多模态数据 |
| 处理模块 | 文本分割 + 文本嵌入 | 新增视觉大模型、音频转文字等模态处理模块 |
| 应用场景 | 纯文本问答(如文档问答) | 图文结合问答(如图表解析)、多文件混合问答 |
| 技术依赖 | 文本嵌入模型 + 基础向量存储 | 多模态模型(视觉 / 音频)+ 高性能向量数据库 |
从课件中 "现有平台 RAG 系统架构" 可知,多模态 RAG 并非完全替代传统 RAG,而是在其基础上扩展能力 ------ 传统 RAG 的文本处理逻辑可直接复用,只需新增多模态数据的专属处理链路,降低开发成本的同时保证系统兼容性。
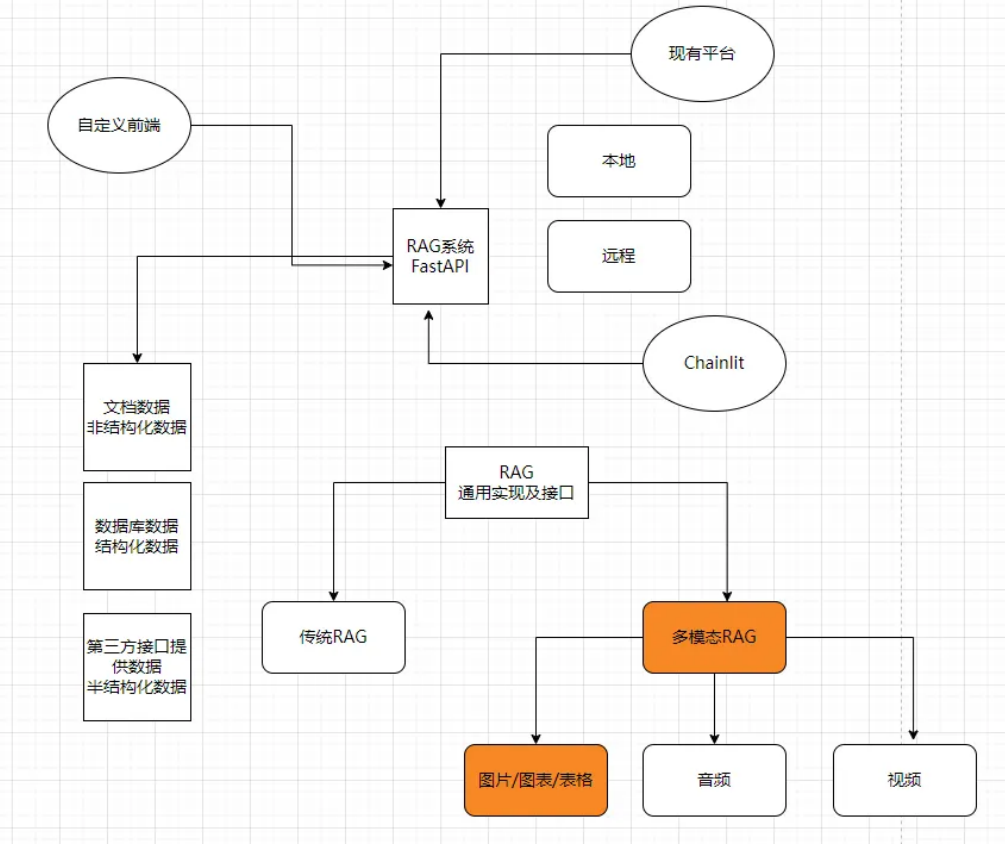
二、实战准备:开发环境与核心依赖配置
在进入 Milvus 向量存储实践前,需先完成开发环境搭建与核心依赖安装。以下配置完全基于课件源码,确保读者可直接复现。
2.1 环境依赖清单
多模态 RAG 系统的开发依赖涵盖向量数据库客户端、嵌入模型库、前端框架等,建议使用 Python 3.9+ 版本(确保兼容性),关键依赖与安装方式如下:
| 工具 / 库 | 用途 | 安装命令 |
|---|---|---|
| Milvus | 向量数据库,存储多模态数据嵌入向量 | 参考 Milvus 官网 或使用 Docker 快速部署 |
| pymilvus | Milvus Python 客户端,实现数据库交互 | pip install pymilvus |
| llama-index-vector-stores-milvus | LlamaIndex 与 Milvus 对接插件 | pip install llama-index-vector-stores-milvus |
| llama-index-core | LlamaIndex 核心框架,处理 RAG 流程 | pip install llama-index-core |
| llama-index-embeddings-huggingface | 本地嵌入模型(如 BAAI/bge-small-zh-v1.5) | pip install llama-index-embeddings-huggingface |
| chainlit | 构建 RAG 系统前端界面 | pip install chainlit |
| python-dotenv | 加载环境变量(如 API Key、数据库地址) | pip install python-dotenv |
2.2 环境变量配置(.env 文件)
为避免将 API Key、数据库地址等敏感信息硬编码到代码中,需通过 .env 文件统一管理环境变量,后续系统将自动加载这些配置,确保安全性与可维护性。典型的 .env 文件配置如下:
bash
CHAINLIT_AUTH_SECRET="kD8Z=sWjUkJU8AqB/*Qe/IcZj02yqWYRjK4eM1SwuZ,@B~6^fP%UHqj2>R?Ih=VZ"
DEEPSEEK_API_KEY="sk-"
MOONSHOT_API_KEY="sk-"
QIANWEN_API_KEY="sk-"
MINIO_ENDPOINT="127.0.0.1:9000"
MINIO_ACCESS_KEY="DRMYw4R1VfXEIjOs"
MINIO_SECRET_KEY="uOy5qzQFMQplNQEZTe2ZZRIgfnj4bgbg"
MINIO_BUCKET_NAME="zzy"
MILVUS_URI="http://127.0.0.1:19530"
MILVUS_DIM=512
PG_CONNECTION_STRING="postgresql+asyncpg://postgres:123456@localhost/chainit_db1"三、Milvus 向量存储实战:从配置到索引落地
Milvus 作为多模态 RAG 系统的 "向量仓库",其核心作用是高效存储多模态数据的嵌入向量,并支持快速相似性检索。以下将从配置连接、索引创建、索引加载三个核心环节,拆解 Milvus 在 RAG 系统中的落地实现。
3.1 为什么选择 Milvus?核心优势解析
在众多向量数据库中,Milvus 成为多模态 RAG 系统的首选,源于其对大规模多模态数据场景的深度适配:
- 高性能检索:支持毫秒级向量检索,即使数据量扩展到百亿级,性能损失仍控制在极小范围,满足多模态数据的快速匹配需求;
- 开源易用性:提供简洁的 Python 客户端 API,配合 LlamaIndex 插件可快速集成到 RAG 流程中,降低开发门槛;
- 多模态兼容:支持任意维度的向量存储,无论是文本嵌入向量(如 512 维)还是图片特征向量(如 1024 维),均可灵活适配;
- 高扩展性:支持分布式部署,可根据数据量动态扩展节点,满足企业级系统的长期演进需求。
3.2 核心代码拆解:Milvus 索引的创建与加载
Milvus 在 RAG 系统中的应用,核心是实现 "数据向量化存储" 与 "索引高效调用",需通过配置管理、基类封装、多模态数据适配三层代码逻辑实现。

步骤 1:配置统一管理 ------ 集中化处理核心参数
为确保系统中各模块使用一致的配置(如 Milvus 地址、嵌入向量维度),需创建配置类统一管理参数,同时通过环境变量加载敏感信息(避免硬编码):
python
import os
from pydantic import BaseModel, Field
class RAGConfig(BaseModel):
"""RAG 系统核心配置类,管理数据库、大模型等关键参数"""
# Milvus 数据库连接地址(从环境变量加载)
milvus_uri: str = Field(default=os.getenv("MILVUS_URI"), description="Milvus 服务地址")
# 嵌入模型维度(如 BAAI/bge-small-zh-v1.5 输出 512 维向量)
embedding_model_dim: int = Field(default=512, description="嵌入向量维度")
# DeepSeek 大模型 API Key(从环境变量加载)
deepseek_api_key: str = Field(default=os.getenv("DEEPSEEK_API_KEY"), description="DeepSeek API 密钥")
# Moonshot 大模型 API Key(从环境变量加载,用于 OCR 处理)
moonshot_api_key: str = Field(default=os.getenv("MOONSHOT_API_KEY"), description="Moonshot API 密钥")
# 单例模式:确保全局仅一个配置实例,避免参数不一致
RagConfig = RAGConfig()此处采用 Pydantic 的 BaseModel 做参数校验,确保配置值的合法性;同时通过 os.getenv 读取 .env 文件中的环境变量,兼顾安全性与配置灵活性。
步骤 2:基类封装 ------ 定义 Milvus 操作统一接口
为简化 Milvus 索引的创建与加载逻辑,需封装基类定义核心接口,后续多模态数据处理类可直接继承并复用这些逻辑:
python
from abc import abstractmethod
from llama_index.core import VectorStoreIndex
from llama_index.core.storage.storage_context import StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
from .config import RagConfig
class RAGBase:
def __init__(self, file_paths: list[str]):
"""初始化:接收待处理的文件路径列表(支持多格式文件)"""
self.file_paths = file_paths
@abstractmethod
async def load_and_process_data(self):
"""抽象方法:多模态数据加载与预处理(子类需实现具体逻辑)
返回:统一格式的文档对象列表(便于后续嵌入处理)
"""
pass
async def create_milvus_index(self, collection_name: str = "default") -> VectorStoreIndex:
"""
创建 Milvus 向量索引:将预处理后的数据转化为向量并写入 Milvus
:param collection_name: Milvus 集合名(类似数据库中的"表",可自定义)
:return: 构建完成的向量索引对象
"""
# 1. 调用子类实现的方法,加载并预处理多模态数据
processed_docs = await self.load_and_process_data()
# 2. 初始化 Milvus 向量存储:建立与 Milvus 的连接
milvus_store = MilvusVectorStore(
uri=RagConfig.milvus_uri, # 从配置获取 Milvus 地址
collection_name=collection_name, # 自定义集合名,避免数据冲突
dim=RagConfig.embedding_model_dim, # 嵌入向量维度(与模型匹配)
overwrite=False # 禁止覆盖已有索引(生产环境建议设为 False)
)
# 3. 创建存储上下文:关联 Milvus 向量存储
storage_context = StorageContext.from_defaults(vector_store=milvus_store)
# 4. 构建向量索引:将文档转化为向量并写入 Milvus
index = VectorStoreIndex.from_documents(
documents=processed_docs,
storage_context=storage_context
)
return index
@staticmethod
async def load_existing_milvus_index(collection_name: str = "default") -> VectorStoreIndex:
"""
加载已存在的 Milvus 索引:从 Milvus 中读取指定集合的向量数据
:param collection_name: 待加载的集合名
:return: 已加载的向量索引对象
"""
# 1. 连接 Milvus 并获取指定集合的向量存储
milvus_store = MilvusVectorStore(
uri=RagConfig.milvus_uri,
collection_name=collection_name
)
# 2. 从向量存储加载索引
index = VectorStoreIndex.from_vector_store(vector_store=milvus_store)
return index基类设计的核心思路是 "定义接口,隐藏细节"------load_and_process_data 作为抽象方法,由子类实现多模态数据的具体处理逻辑(如文本读取、图片 OCR),而 create_milvus_index 与 load_existing_milvus_index 则封装了 Milvus 索引的创建与加载细节,确保各模块调用逻辑统一。
步骤 3:多模态数据适配 ------ 实现文件处理逻辑
继承基类并实现 load_and_process_data 方法,完成多模态数据的预处理(如图片 OCR 转文本、文本文件读取),最终输出统一格式的文档对象:
python
import asyncio
import os
from datetime import datetime
from pathlib import Path
from llama_index.core import SimpleDirectoryReader, Document
from .base import RAGBase
from .utils import ocr_extract_text # 自定义 OCR 工具函数
from .llms import get_moonshot_client # 自定义 Moonshot 客户端获取函数
class MultiModalRAG(RAGBase):
async def load_and_process_data(self) -> list[Document]:
"""
多模态数据加载与预处理:支持文本文件直接读取、图片 OCR 转文本
返回:LlamaIndex 兼容的 Document 对象列表
"""
processed_docs = []
for file_path in self.file_paths:
file_ext = Path(file_path).suffix.lower() # 获取文件后缀(小写统一格式)
# 1. 处理图片文件(.jpg、.png、.jpeg):OCR 提取文本
if file_ext in [".jpg", ".png", ".jpeg"]:
# 调用 OCR 工具函数提取图片中的文本
ocr_text = ocr_extract_text(file_path=file_path)
doc_content = ocr_text
# 2. 处理文本类文件(.txt、.pdf):直接读取内容
elif file_ext in [".txt", ".pdf"]:
# 使用 LlamaIndex 工具读取文件内容
reader = SimpleDirectoryReader(input_files=[file_path])
raw_docs = reader.load_data()
# 合并文档内容(处理多页 PDF 场景)
doc_content = "\n\n".join([doc.text for doc in raw_docs])
# 3. 其他格式暂不支持(可根据需求扩展)
else:
raise ValueError(f"暂不支持 {file_ext} 格式文件,请上传图片或文本类文件")
# 4. 创建 Document 对象(添加元数据,便于后续追溯)
doc = Document(
text=doc_content,
metadata={
"file_path": file_path,
"file_type": file_ext,
"process_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
)
processed_docs.append(doc)
return processed_docs
# 测试:创建图片文件的 Milvus 索引
if __name__ == "__main__":
# 待处理的图片文件路径
test_files = ["../test_data/sample_image.jpg"]
# 实例化多模态 RAG 类
rag_handler = MultiModalRAG(file_paths=test_files)
# 异步创建 Milvus 索引(指定集合名,便于后续查找)
asyncio.run(rag_handler.create_milvus_index(collection_name="image_test_collection"))
print("图片文件 Milvus 索引创建完成!")此处的关键是 "统一数据格式"------ 无论输入是图片还是文本,最终都转化为包含文本内容与元数据的 Document 对象,确保后续嵌入处理与向量存储流程可复用,无需为不同模态单独编写逻辑。
步骤 4:OCR 工具函数 ------ 实现图片文本提取
图片文件的文本提取依赖 OCR 技术,此处基于 Moonshot 大模型实现高效提取,工具函数逻辑如下:
python
from .llms import get_moonshot_client # 从大模型配置模块获取客户端
def ocr_extract_text(file_path: str) -> str:
"""
基于 Moonshot 大模型的 OCR 文本提取:处理图片中的文字内容
:param file_path: 图片文件路径
:return: 提取的文本内容(字符串)
"""
# 1. 获取 Moonshot 大模型客户端(从配置加载 API Key)
moonshot_client = get_moonshot_client()
# 2. 上传图片文件到 Moonshot 服务(指定处理目的为"文件提取")
with open(file_path, "rb") as f:
file_obj = moonshot_client.files.create(
file=f,
purpose="file-extract" # 服务端指定处理类型为文件内容提取
)
# 3. 获取 OCR 提取结果(JSON 格式)
extract_result = moonshot_client.files.content(file_id=file_obj.id).json()
# 4. 提取文本内容(处理空结果场景)
return extract_result.get("content", "")该函数的核心是调用 Moonshot 大模型的文件提取接口,实现图片文本的高效提取;若需处理 PDF 中的图片,可先将 PDF 拆分为单张图片,再调用此函数完成文本提取。
四、系统集成:多模态 RAG 问答流程串联
完成 Milvus 向量存储的核心逻辑后,需将 "数据处理 - 索引创建 - 问答交互" 串联成完整流程,通过前端界面实现用户可操作的多模态问答系统。
4.1 前端交互逻辑:基于 Chainlit 构建可视化界面
前端界面需支持文件上传、PDF 预览、实时问答等核心功能,此处使用 Chainlit 框架实现轻量化开发,核心逻辑如下:
python
import chainlit as cl
from dotenv import load_dotenv
from llama_index.core.chat_engine import SimpleChatEngine
from llama_index.core.chat_engine.types import ChatMode
from .rag.multi_modal import MultiModalRAG
# 加载环境变量(初始化时执行)
load_dotenv()
@cl.on_chat_start
async def init_chat():
"""聊天初始化:创建基础聊天引擎,发送欢迎消息"""
# 1. 创建基础聊天引擎(无检索功能,用于初始交互)
base_chat_engine = SimpleChatEngine.from_defaults()
# 2. 保存到用户会话(后续可复用,避免重复创建)
cl.user_session.set("chat_engine", base_chat_engine)
# 3. 发送欢迎消息,引导用户操作
await cl.Message(
author="AI 助手",
content="您好!我支持图片、文本等多模态文件的问答,您可以上传文件后提出具体问题~"
).send()
@cl.on_message
async def handle_user_message(message: cl.Message):
"""处理用户消息:文件上传→索引创建→问答回复"""
# 1. 从会话获取当前聊天引擎
current_chat_engine = cl.user_session.get("chat_engine")
# 2. 初始化助手回复消息(流式输出用)
assistant_reply = cl.Message(author="AI 助手", content="")
# 3. 预览用户上传的 PDF 文件(提升交互体验)
await preview_pdf(elements=message.elements)
# 4. 提取用户上传的文件路径(支持图片、文本类文件)
uploaded_files = []
for elem in message.elements:
# 判断文件类型:Chainlit 的 File 或 Image 类型
if isinstance(elem, cl.File) or isinstance(elem, cl.Image):
uploaded_files.append(elem.path)
# 5. 若有上传文件,创建 Milvus 索引并更新聊天引擎
if uploaded_files:
# 实例化多模态 RAG 处理类
rag_processor = MultiModalRAG(file_paths=uploaded_files)
# 自定义 Milvus 集合名(结合用户 ID,避免多用户数据冲突)
user_id = cl.user_session.get("user_id", "default_user")
collection_name = f"user_{user_id}_collection"
# 异步创建 Milvus 索引
milvus_index = await rag_processor.create_milvus_index(collection_name=collection_name)
# 更新聊天引擎:基于 Milvus 索引实现"检索增强生成"
retrieval_chat_engine = milvus_index.as_chat_engine(chat_mode=ChatMode.CONTEXT)
# 保存更新后的聊天引擎到会话
cl.user_session.set("chat_engine", retrieval_chat_engine)
# 告知用户索引创建完成
await assistant_reply.stream_token("文件处理完成,已为您创建检索索引,现在可以提问啦!\n\n")
# 6. 基于 Milvus 检索结果生成回复(流式输出,避免用户等待)
response = await cl.make_async(current_chat_engine.stream_chat)(message.content)
for token in response.response_gen:
await assistant_reply.stream_token(token)
# 7. 发送最终回复
await assistant_reply.send()
async def preview_pdf(elements: list):
"""辅助函数:预览用户上传的 PDF 文件"""
pdf_elements = []
pdf_names = []
for elem in elements:
if elem.name.endswith(".pdf"):
# 创建 Chainlit PDF 预览对象(侧边显示)
pdf_preview = cl.Pdf(name=elem.name, display="side", path=elem.path)
pdf_elements.append(pdf_preview)
pdf_names.append(elem.name)
# 若有 PDF 文件,发送预览消息
if pdf_elements:
await cl.Message(
author="文件预览",
content=f"已识别 PDF 文件:{','.join(pdf_names)}",
elements=pdf_elements
).send()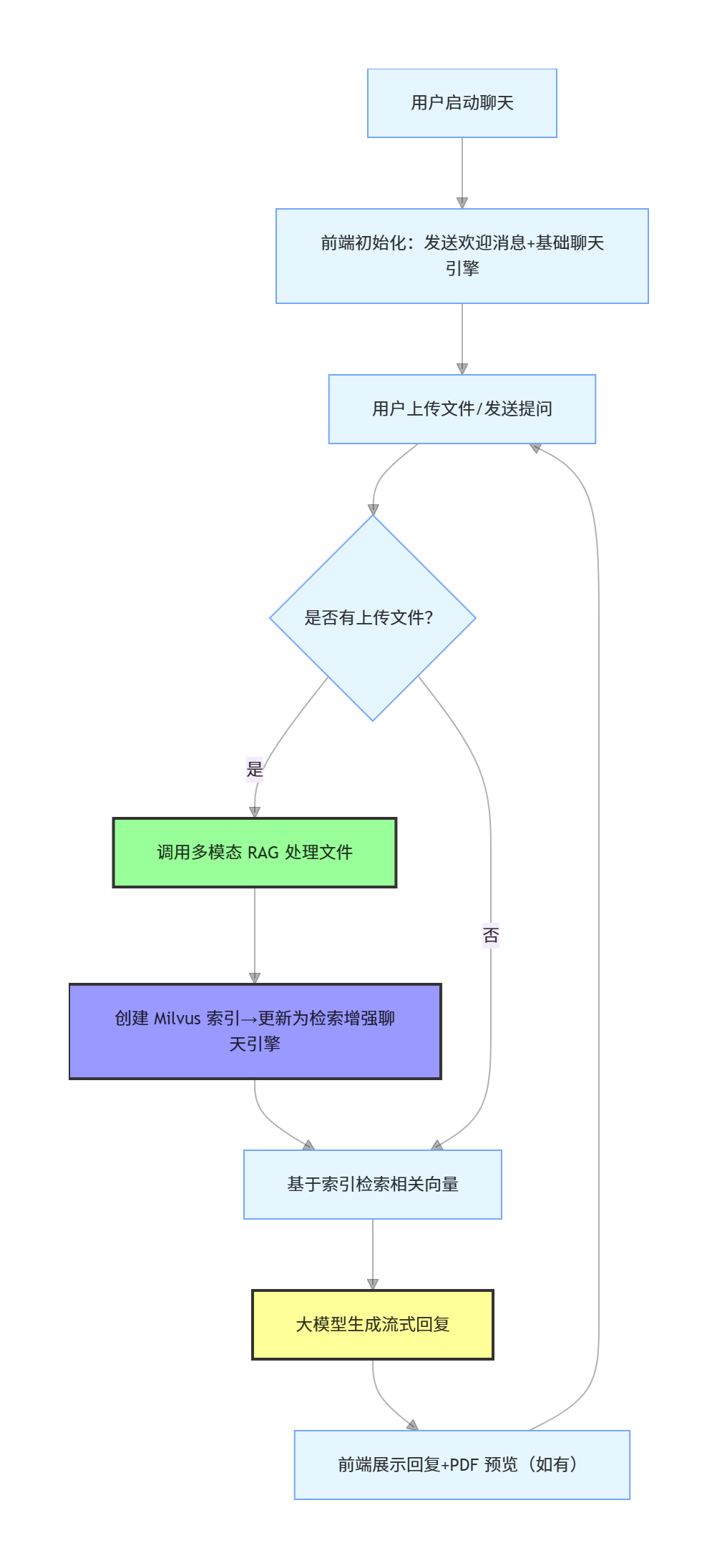
4.2 完整问答流程演示
以 "图片问答" 场景为例,用户与系统的交互流程如下:
- 用户操作 :运行
chainlit run ui.py启动前端界面,上传一张包含文字的图片(如sample_image.jpg); - 系统处理 :
- 调用
MultiModalRAG.load_and_process_data()方法,通过 OCR 提取图片中的文本; - 调用
create_milvus_index()方法,将文本嵌入为向量并写入 Milvus(集合名如user_default_user_collection); - 更新聊天引擎为 "检索增强模式",后续回答将基于 Milvus 中的向量检索结果;
- 调用
- 用户提问:在输入框中发送 "图片中的核心信息是什么?";
- 系统回复 :
- 聊天引擎从 Milvus 检索与问题最相关的向量数据;
- 结合检索到的文本内容,通过 DeepSeek 大模型生成自然语言回答;
- 以流式输出方式展示回复,同时保留 PDF 预览功能(若用户上传 PDF 文件)。
五、常见问题与优化建议
在多模态 RAG 与 Milvus 实践过程中,开发者可能遇到连接失败、检索效率低等问题,结合实际开发经验给出解决方案与优化方向:
5.1 Milvus 连接失败
- 常见原因:Milvus 服务未启动、连接地址 / 端口错误、网络不通;
- 解决方案 :
- 检查 Milvus 服务状态(Docker 部署可通过
docker ps | grep milvus查看); - 确认
.env文件中MILVUS_URI与 Milvus 实际地址一致(本地部署默认http://localhost:19530); - 若为远程 Milvus,需确保服务端开放 19530 端口(TCP 协议),并验证网络连通性(如
ping服务端 IP)。
- 检查 Milvus 服务状态(Docker 部署可通过
5.2 向量维度不匹配
- 常见原因 :
RAGConfig.embedding_model_dim与实际嵌入模型输出维度不一致(如模型输出 768 维,配置设为 512 维); - 解决方案 :
- 查看嵌入模型官方文档,确认输出维度(如 BAAI/bge-small-zh-v1.5 为 512 维,Sentence-BERT 部分模型为 768 维);
- 修改
RAGConfig中embedding_model_dim的默认值,或通过环境变量覆盖配置。
5.3 检索速度慢
- 常见原因:Milvus 未建立索引、数据量过大、硬件资源不足;
- 解决方案 :
- 为 Milvus 集合创建索引(推荐 HNSW 索引,适用于高维向量快速检索,参考 Milvus 官方文档);
- 增加 Milvus 服务的内存资源(向量检索对内存要求较高,建议至少 8GB 内存);
- 优化检索参数(如设置
top_k=5,仅检索前 5 个最相关结果,平衡效率与准确性)。
5.4 OCR 提取文本不准确
- 常见原因:图片模糊、文字颜色与背景对比度低、大模型 OCR 能力有限;
- 解决方案 :
- 预处理图片(如使用图像工具增强对比度、裁剪无关区域,聚焦文字部分);
- 替换 OCR 工具(如改用 Tesseract OCR 本地部署,或调用百度、阿里云等第三方 OCR API,根据场景选择);
- 优化 OCR 提示词(如向 Moonshot 大模型补充 "提取图片中的所有文字,包括小字体注释",提升提取完整性)。
六、总结与后续规划
本篇聚焦多模态 RAG 架构设计与 Milvus 向量存储实战,核心收获包括:
- 理解多模态 RAG 的核心逻辑 ------ 通过扩展模态处理能力,实现对多格式数据的兼容,同时复用传统 RAG 的文本处理流程;
- 掌握 Milvus 在 RAG 中的落地方法 ------ 从配置管理、索引创建到索引加载,形成完整的向量存储链路;
- 实现多模态问答系统的端到端集成 ------ 通过前端框架构建可视化界面,串联 "数据处理 - 索引 - 问答" 全流程。
后续系列将进一步深入多模态 RAG 的性能优化与场景扩展,包括:
- 检索结果重排:引入 Cross-Encoder 等模型优化检索结果排序,提升回答准确性;
- Milvus 分布式部署:讲解如何通过多节点部署,满足大规模多模态数据的存储与检索需求;
- 实际场景落地:以企业知识库、智能客服为例,讲解多模态 RAG 在具体业务中的应用与适配。
若在实践过程中遇到问题,可参考 Milvus 与 LlamaIndex 官方文档,或通过代码注释中的配置说明排查问题,确保系统稳定运行。