CosyVoice是一个功能强大的多语言语音生成模型,由阿里巴巴的通义实验室(FunAudioLLM团队)开发。它不仅能将文本合成为高度拟人的自然语音,还具备零样本语音克隆、跨语言合成等前沿能力。
- 支持的语言: 中文、英文、日文、韩文、中文方言(粤语、四川话、上海话、天津话、武汉话等)
- 跨语言 & 混合语言: 支持零样本跨语言和代码切换场景的语音克隆。
实测效果很不错,4G显存就能跑。
克隆并安装
-
克隆仓库
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git # If you failed to clone submodule due to network failures, please run following command until success cd CosyVoice git submodule update --init --recursive
-
安装 Conda: 请参阅 https://docs.conda.io/en/latest/miniconda.html
-
创建 Conda 环境:
conda create -n cosyvoice python=3.10 conda activate cosyvoice # pynini is required by WeTextProcessing, use conda to install it as it can be executed on all platform. conda install -y -c conda-forge pynini==2.1.5 pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com # If you encounter sox compatibility issues # ubuntu sudo apt-get install sox libsox-dev # centos sudo yum install sox sox-devel
SDK模型下载 from modelscope import snapshot_download snapshot_download('iic/CosyVoice2-0.5B', local_dir='iic/CosyVoice2-0.5B')
python
import sys
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice2('iic/CosyVoice2-0.5B', load_jit=False, load_trt=False, fp16=False)
# NOTE if you want to reproduce the results on https://funaudiollm.github.io/cosyvoice2, please add text_frontend=False during inference
# zero_shot usage
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)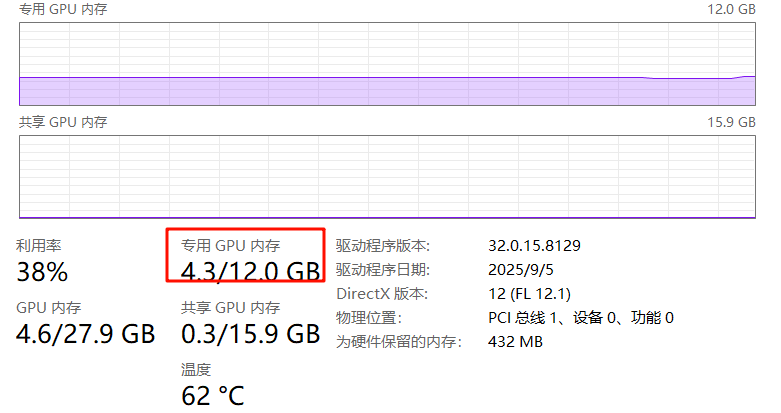
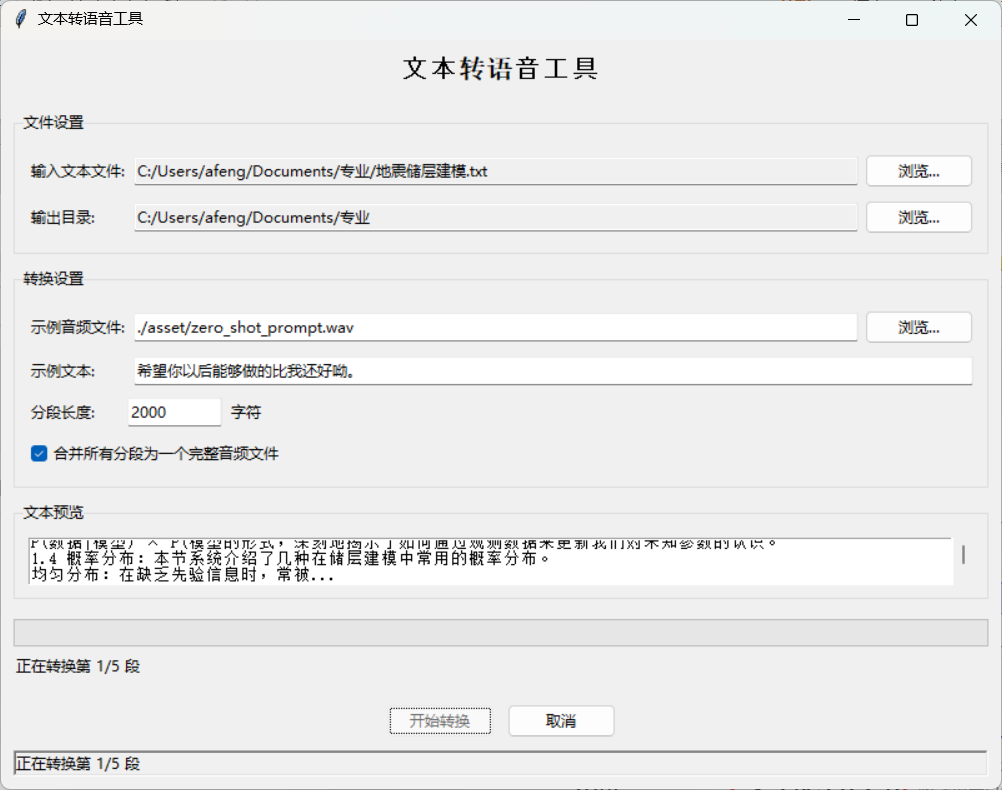
下面是设计了界面,方便使用这个功能
python
import sys
import os
import tkinter as tk
from tkinter import filedialog, messagebox, ttk
from tqdm import tqdm
import re
import threading
import torch
import torchaudio
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
class TextToSpeechApp:
def __init__(self, root):
self.root = root
self.root.title("文本转语音工具")
self.root.geometry("800x600")
self.root.resizable(True, True)
# 模型变量
self.cosyvoice = None
self.prompt_speech_16k = None
# 状态变量
self.is_processing = False
self.setup_ui()
def setup_ui(self):
"""设置用户界面"""
# 主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 配置网格权重
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1)
main_frame.columnconfigure(1, weight=1)
# 标题
title_label = ttk.Label(main_frame, text="文本转语音工具", font=("Arial", 16, "bold"))
title_label.grid(row=0, column=0, columnspan=3, pady=(0, 20))
# 文件选择区域
file_frame = ttk.LabelFrame(main_frame, text="文件设置", padding="10")
file_frame.grid(row=1, column=0, columnspan=3, sticky=(tk.W, tk.E), pady=(0, 10))
file_frame.columnconfigure(1, weight=1)
# 输入文件选择
ttk.Label(file_frame, text="输入文本文件:").grid(row=0, column=0, sticky=tk.W, pady=5)
self.input_file_var = tk.StringVar()
ttk.Entry(file_frame, textvariable=self.input_file_var, state="readonly").grid(row=0, column=1, sticky=(tk.W, tk.E), padx=(5, 5), pady=5)
ttk.Button(file_frame, text="浏览...", command=self.select_input_file).grid(row=0, column=2, pady=5)
# 输出目录选择
ttk.Label(file_frame, text="输出目录:").grid(row=1, column=0, sticky=tk.W, pady=5)
self.output_dir_var = tk.StringVar()
ttk.Entry(file_frame, textvariable=self.output_dir_var, state="readonly").grid(row=1, column=1, sticky=(tk.W, tk.E), padx=(5, 5), pady=5)
ttk.Button(file_frame, text="浏览...", command=self.select_output_dir).grid(row=1, column=2, pady=5)
# 设置区域
settings_frame = ttk.LabelFrame(main_frame, text="转换设置", padding="10")
settings_frame.grid(row=2, column=0, columnspan=3, sticky=(tk.W, tk.E), pady=(0, 10))
settings_frame.columnconfigure(1, weight=1)
# 示例音频文件选择
ttk.Label(settings_frame, text="示例音频文件:").grid(row=0, column=0, sticky=tk.W, pady=5)
self.prompt_file_var = tk.StringVar(value="./asset/zero_shot_prompt.wav")
ttk.Entry(settings_frame, textvariable=self.prompt_file_var).grid(row=0, column=1, sticky=(tk.W, tk.E), padx=(5, 5), pady=5)
ttk.Button(settings_frame, text="浏览...", command=self.select_prompt_file).grid(row=0, column=2, pady=5)
# 示例文本
ttk.Label(settings_frame, text="示例文本:").grid(row=1, column=0, sticky=tk.W, pady=5)
self.prompt_text_var = tk.StringVar(value="希望你以后能够做的比我还好呦。")
ttk.Entry(settings_frame, textvariable=self.prompt_text_var).grid(row=1, column=1, columnspan=2, sticky=(tk.W, tk.E), padx=(5, 0), pady=5)
# 文本分段长度
ttk.Label(settings_frame, text="分段长度:").grid(row=2, column=0, sticky=tk.W, pady=5)
self.chunk_size_var = tk.StringVar(value="2000")
chunk_size_frame = ttk.Frame(settings_frame)
chunk_size_frame.grid(row=2, column=1, columnspan=2, sticky=(tk.W, tk.E), pady=5)
ttk.Entry(chunk_size_frame, textvariable=self.chunk_size_var, width=10).grid(row=0, column=0, sticky=tk.W)
ttk.Label(chunk_size_frame, text="字符").grid(row=0, column=1, sticky=tk.W, padx=(5, 0))
# 文本预览区域
preview_frame = ttk.LabelFrame(main_frame, text="文本预览", padding="10")
preview_frame.grid(row=3, column=0, columnspan=3, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(0, 10))
preview_frame.columnconfigure(0, weight=1)
preview_frame.rowconfigure(0, weight=1)
main_frame.rowconfigure(3, weight=1)
# 文本预览文本框
self.text_preview = tk.Text(preview_frame, height=10, wrap=tk.WORD)
text_scrollbar = ttk.Scrollbar(preview_frame, orient="vertical", command=self.text_preview.yview)
self.text_preview.configure(yscrollcommand=text_scrollbar.set)
self.text_preview.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
text_scrollbar.grid(row=0, column=1, sticky=(tk.N, tk.S))
# 进度区域
progress_frame = ttk.Frame(main_frame)
progress_frame.grid(row=4, column=0, columnspan=3, sticky=(tk.W, tk.E), pady=(0, 10))
progress_frame.columnconfigure(0, weight=1)
self.progress_var = tk.DoubleVar()
self.progress_bar = ttk.Progressbar(progress_frame, variable=self.progress_var, maximum=100)
self.progress_bar.grid(row=0, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=5)
self.progress_label = ttk.Label(progress_frame, text="就绪")
self.progress_label.grid(row=1, column=0, columnspan=2, sticky=tk.W)
# 按钮区域
button_frame = ttk.Frame(main_frame)
button_frame.grid(row=5, column=0, columnspan=3, pady=10)
self.start_button = ttk.Button(button_frame, text="开始转换", command=self.start_conversion)
self.start_button.grid(row=0, column=0, padx=(0, 10))
self.cancel_button = ttk.Button(button_frame, text="取消", command=self.cancel_conversion, state="disabled")
self.cancel_button.grid(row=0, column=1)
# 状态栏
self.status_var = tk.StringVar(value="就绪")
status_bar = ttk.Label(main_frame, textvariable=self.status_var, relief=tk.SUNKEN)
status_bar.grid(row=6, column=0, columnspan=3, sticky=(tk.W, tk.E))
def select_input_file(self):
"""选择输入文本文件"""
file_path = filedialog.askopenfilename(
title="选择文本文件",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")]
)
if file_path:
self.input_file_var.set(file_path)
self.load_text_preview(file_path)
def select_output_dir(self):
"""选择输出目录"""
output_dir = filedialog.askdirectory(title="选择输出目录")
if output_dir:
self.output_dir_var.set(output_dir)
def select_prompt_file(self):
"""选择示例音频文件"""
file_path = filedialog.askopenfilename(
title="选择示例音频文件",
filetypes=[("音频文件", "*.wav"), ("所有文件", "*.*")]
)
if file_path:
self.prompt_file_var.set(file_path)
def load_text_preview(self, file_path):
"""加载文本预览"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 只显示前1000个字符作为预览
preview_content = content[:1000] + ("..." if len(content) > 1000 else "")
self.text_preview.delete(1.0, tk.END)
self.text_preview.insert(1.0, preview_content)
self.status_var.set(f"已加载文件: {os.path.basename(file_path)}")
except Exception as e:
messagebox.showerror("错误", f"读取文件失败: {str(e)}")
def start_conversion(self):
"""开始转换"""
if not self.input_file_var.get():
messagebox.showwarning("警告", "请选择输入文本文件")
return
if not self.output_dir_var.get():
messagebox.showwarning("警告", "请选择输出目录")
return
if not os.path.exists(self.prompt_file_var.get()):
messagebox.showwarning("警告", "示例音频文件不存在")
return
# 禁用开始按钮,启用取消按钮
self.start_button.config(state="disabled")
self.cancel_button.config(state="normal")
self.is_processing = True
# 在新线程中运行转换过程
thread = threading.Thread(target=self.run_conversion)
thread.daemon = True
thread.start()
def cancel_conversion(self):
"""取消转换"""
self.is_processing = False
self.status_var.set("转换已取消")
def run_conversion(self):
"""运行转换过程"""
try:
self.status_var.set("正在初始化模型...")
self.progress_label.config(text="正在初始化模型...")
# 初始化模型
if not self.initialize_model():
return
# 处理文本文件
self.process_text_file()
except Exception as e:
messagebox.showerror("错误", f"转换过程出错: {str(e)}")
finally:
# 恢复按钮状态
self.root.after(0, self.reset_ui)
def initialize_model(self):
"""初始化模型"""
try:
# 加载示例音频
self.prompt_speech_16k = load_wav(self.prompt_file_var.get(), 16000)
# 初始化模型
self.cosyvoice = CosyVoice2(
'pretrained_models/CosyVoice2-0.5B',
load_jit=False,
load_trt=False,
load_vllm=False,
fp16=False
)
return True
except Exception as e:
messagebox.showerror("错误", f"初始化模型失败: {str(e)}")
return False
def process_text_file(self):
"""处理文本文件"""
file_path = self.input_file_var.get()
output_dir = self.output_dir_var.get()
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 读取文本文件
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
except Exception as e:
messagebox.showerror("错误", f"读取文件失败: {str(e)}")
return
# 预处理文本
text = re.sub(r'\s+', ' ', text).strip()
# 分段处理
chunk_size = int(self.chunk_size_var.get())
chunks = self.split_text_into_chunks(text, chunk_size)
total_chunks = len(chunks)
self.root.after(0, lambda: self.progress_bar.config(maximum=total_chunks))
# 处理每个文本块
total_files = 0
for i, chunk in enumerate(chunks):
if not self.is_processing:
break
# 更新进度
progress_text = f"正在转换第 {i+1}/{total_chunks} 段"
self.root.after(0, lambda txt=progress_text: self.update_progress(i, txt))
try:
# 处理单个文本块,直接输出所有音频文件
files_count = self.process_single_chunk(chunk, i+1)
total_files += files_count
except Exception as e:
error_msg = f"转换第 {i+1} 段时出错: {str(e)}"
self.root.after(0, lambda msg=error_msg: self.status_var.set(msg))
continue
if self.is_processing:
self.root.after(0, lambda: messagebox.showinfo("完成",
f"转换完成!共生成 {total_files} 个音频文件。\n输出目录: {output_dir}"))
def split_text_into_chunks(self, text, chunk_size):
"""将文本分割成块"""
if len(text) <= chunk_size:
return [text]
sentences = re.split(r'[。!?!?]', text)
sentences = [s.strip() for s in sentences if s.strip()]
chunks = []
current_chunk = ""
for sentence in sentences:
if len(current_chunk) + len(sentence) + 1 <= chunk_size or not current_chunk:
if current_chunk:
current_chunk += "。" + sentence
else:
current_chunk = sentence
else:
chunks.append(current_chunk + "。")
current_chunk = sentence
if current_chunk:
chunks.append(current_chunk + "。")
return chunks
def process_single_chunk(self, chunk, chunk_index):
"""处理单个文本块,直接输出所有音频文件"""
files_count = 0
try:
# 使用零样本推理,直接保存每个生成的音频片段
for j, result in enumerate(self.cosyvoice.inference_zero_shot(
chunk,
self.prompt_text_var.get(),
self.prompt_speech_16k,
stream=False
)):
# 为每个片段生成单独的文件
output_filename = os.path.join(self.output_dir_var.get(), f'audio_{chunk_index:03d}_{j+1:03d}.wav')
torchaudio.save(output_filename, result['tts_speech'], self.cosyvoice.sample_rate)
files_count += 1
except Exception as e:
raise Exception(f"处理文本块时出错: {str(e)}")
return files_count
def update_progress(self, value, text):
"""更新进度条"""
self.progress_var.set(value)
self.progress_label.config(text=text)
self.status_var.set(text)
def reset_ui(self):
"""重置UI状态"""
self.start_button.config(state="normal")
self.cancel_button.config(state="disabled")
self.progress_var.set(0)
self.progress_label.config(text="就绪")
self.is_processing = False
def main():
root = tk.Tk()
app = TextToSpeechApp(root)
root.mainloop()
if __name__ == "__main__":
main()