RAG(检索增强生成)管道在很大程度上依赖于你如何分割文档(分块)。在这篇文章中,我将介绍RAG工作流程,突出分块在其中的作用,然后深入探讨固定、递归、语义、基于结构和后期分块技术,包括定义、权衡和伪代码,以便你能采用适合自己用例的方法。
检索增强生成(RAG)工作流程(高级)
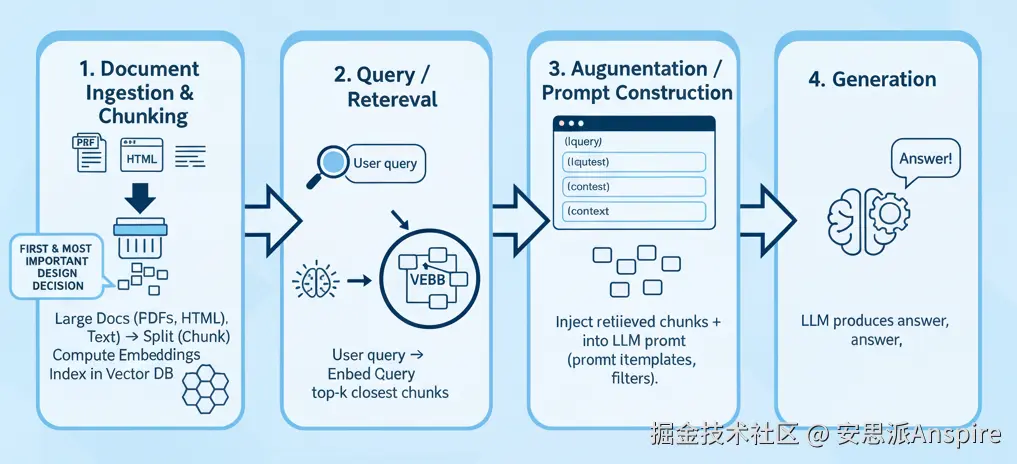
以下是标准流程:
按回车键或点击以查看全尺寸图像
-
文档摄取与分块 处理大型文档(PDF、HTML、原始文本)→ 分割("分块")→ 计算嵌入向量 → 在向量DB中建立索引。
-
查询 / 检索 用户查询 → 嵌入查询 → 检索最接近的前 k 个块(通过余弦相似度)
-
增强 / 提示构建将检索到的文本块(加上元数据)注入到大语言模型提示中,通常会使用模板和过滤器。
-
生成 大语言模型(LLM)基于检索到的上下文和模型先验生成答案。
由于生成器只能看到你提供给它的内容,因此你的检索质量起着主导作用。如果文本块格式错误或不相关,即使是最好的大语言模型也无法挽救。这就是为什么很多人说检索增强生成(RAG)大约70%在于检索,30%在于生成。
在我们深入探讨技巧之前,先来了解一下为什么良好的组块化是必不可少的:
-
嵌入和大语言模型(LLM)有上下文窗口限制;你不能直接处理大型文档。
-
文本块需要语义连贯。如果在句子中间或想法中间进行分割,嵌入结果将产生噪声或具有误导性。
-
如果你的数据块太大,系统可能会遗漏细粒度的相关信息。
-
相反,如果数据块太小或重叠过多,就会存储冗余内容,浪费计算/存储资源。
让我们来探索五种突出的组块技术,从最简单到最先进。
1. 固定分块
将文本分割成大小相等的块(按标记、单词或字符),块之间通常有重叠。
它是您的RAG项目的良好起点,在文档结构未知时是不错的基线,或者适用于统一/枯燥的文本(日志、纯文本)。
实现代码示例:
ini
def fixed_chunk(text, max_tokens=512, overlap=50):
tokens = tokenize(text)
chunks = []
i = 0
while i < len(tokens):
chunk = tokens[i : i + max_tokens]
chunks.append(detokenize(chunk))
i += (max_tokens - overlap)
return chunks2. 递归分块
首先在高层次边界(例如段落或章节)处进行分割。如果分割后的块仍然太大(超过限制),则递归地进一步分割(例如按句子),直到所有块都在限制范围内。
适用于半结构化文档(包含章节、段落),在这类文档中,你既希望保留语义边界,又要限制篇幅。
它尽可能保留逻辑单元(段落),避免跨越不自然的界限,并且你会得到一组适合内容变化的混合尺寸
递归分块示例(LangChain)
ini
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Sample text
text = """
Input text Placeholder...
"""
# Define a RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # target size of each chunk
chunk_overlap=50, # overlap between chunks for context continuity
separators=["\n\n", "\n", " ", ""] # order of recursive splitting
)
# Split the text
chunks = text_splitter.split_text(text)
# Display results
for i, chunk in enumerate(chunks, 1):
print(f"Chunk {i}:\n{chunk}\n{'-'*40}")这样可以确保在你嵌入和稍后检索文本块时,不会在边界处丢失重要的上下文信息。
3.语义分块
按语义转换对文本进行分段。使用嵌入(例如句子嵌入)来确定一个段落的结束位置和下一个段落的起始位置。如果相邻的段落非常相似,则将它们合并;当相似度降低时,则进行分割。
当检索精度至关重要时(法律文本、科学文章、支持文档)效果最佳,但你需要留意嵌入和相似度计算成本,同时定义阈值(相似度下降)需要仔细调整
实现代码示例
ini
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
def semantic_chunk(text, sentence_list, sim_threshold=0.7):
embeddings = model.encode(sentence_list)
chunks = []
current = [sentence_list[0]]
for i in range(1, len(sentence_list)):
sim = util.cos_sim(embeddings[i-1], embeddings[i]).item()
if sim < sim_threshold:
chunks.append(" ".join(current))
current = [sentence_list[i]]
else:
current.append(sentence_list[i])
chunks.append(" ".join(current))
return chunks4. 基于结构的分块
使用文档的固有结构,如标题、副标题、HTML标签、表格、列表项等,作为自然的分块边界。 例如,每个章节或标题成为一个分块(或进一步递归分块)。 最适合HTML页面、技术文档、类似维基百科的内容或任何带有语义标记的内容。
根据我的个人经验,这种策略能取得最佳效果,尤其是与递归分块结合使用时。
然而,它需要解析和理解文档格式,对于大篇幅内容可能会超出令牌限制,因此可能需要采用递归拆分的混合方法。
实施提示
-
使用 HTML / Markdown / PDF 结构库进行解析
-
使用章节 /
、
等作为块根
-
如果一个部分太大,则回退到递归拆分
-
对于表格/图像,要么将它们视为单独的部分,要么对其进行总结
5. 延迟分块(又称动态/查询时分块)
定义
延迟分块意味着将文档的分割方式推迟到查询时。不是预先将所有内容分割,而是存储较大的片段或整个文档。当查询到来时,只有相关的片段才会被动态分割(或过滤)。这样做的目的是在嵌入过程中保留完整的上下文,只在必要时进行分解。
将延迟分块描述为"
颠倒嵌入和分块的传统顺序
"。
-
首先使用长上下文模型嵌入整个文档(或大段内容)。
-
然后进行合并并创建分块嵌入(基于标记跨度或边界线索)。
概念流程
-
在索引中存储大段内容或整个文档。
-
查询时,检索1 - 2个顶级片段。
-
在这些内容中,围绕与查询匹配的部分动态分割(例如语义分割或重叠分割)成细粒度的片段。
-
过滤或排序块以提供给生成器。
按回车键或点击以查看全尺寸图像
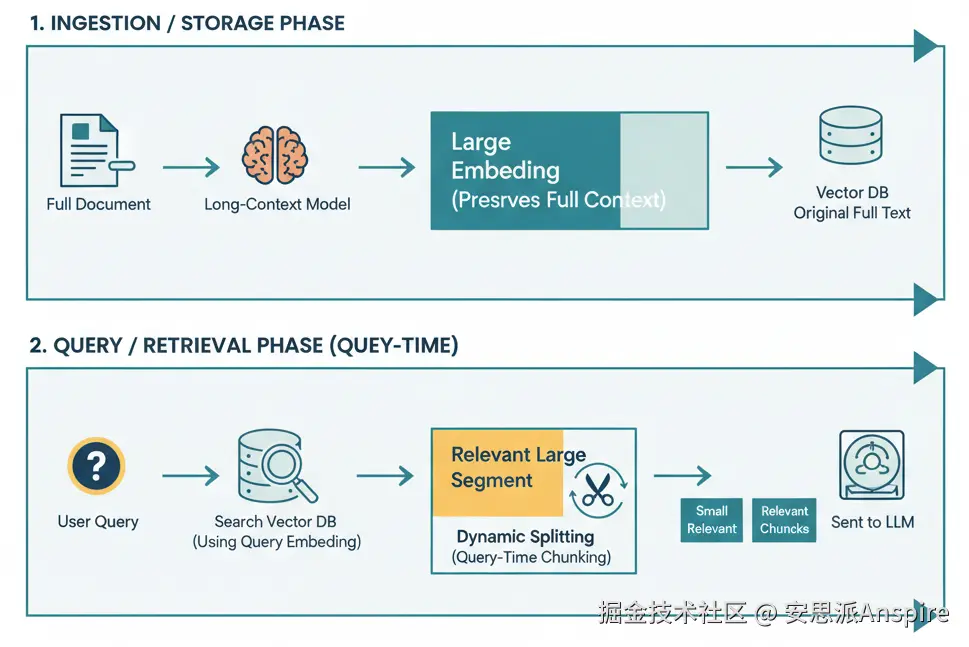
这种方法类似于编程中的延迟绑定,直到有更多上下文时再进行处理。
用例
-
大文档集(技术报告、长篇内容),其中段落间的上下文关系很重要。
-
在**文档内容经常变化的系统中,**避免完全重新分块可以节省时间。
-
高风险或对精度敏感的检索增强生成(RAG)应用(法律、医疗、监管领域),在这些应用中,对代词或指代的误解可能代价高昂。
这听起来很高级,但也有代价。嵌入整个文档(或大篇幅内容)的计算成本很高,可能需要具有长标记限制的模型。 它还会增加查询时的成本,包括计算成本和潜在的延迟。