1 题目
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
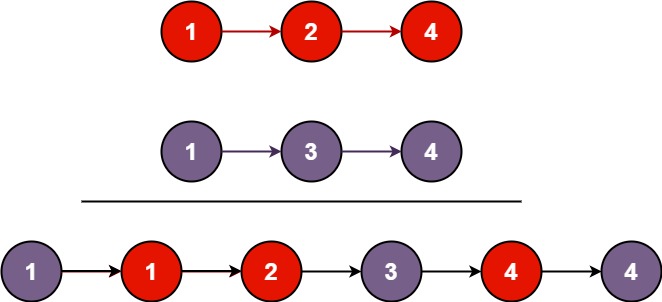
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]示例 2:
输入:l1 = [], l2 = []
输出:[]示例 3:
输入:l1 = [], l2 = [0]
输出:[0]提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
2 代码实现(c)
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
ListNode * head = (ListNode*)malloc(sizeof(ListNode));
ListNode * p= head;
while(list1 != NULL && list2 != NULL){
if(list1 -> val > list2 -> val){
p -> next = list2;
list2 = list2 -> next;
}else{
p -> next = list1;
list1 = list1 -> next ;
}
p = p -> next;
}
if(list1 != NULL){
p -> next = list1;
} else{
p -> next = list2;
}
ListNode *result = head -> next;
return result;
}不会用哑节点,遇到了困难。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
ListNode * head = (ListNode*)malloc(sizeof(ListNode));
ListNode * p= head;
while(list1 != NULL && list2 != NULL){
if(list1 -> val > list2 -> val){
p -> next = list2;
list2 = list2 -> next;
}else{
p -> next = list1;
list1 = list1 -> next ;
}
}
if(list1 == NULL){
while(list2 != NULL){
p-> next = list2;
list2 = list2 -> next;
}
}
if(list2 == NULL){
while(list1 != NULL){
p-> next = list1;
list1 = list1 -> next;
}
}
return head;
}你的代码思路是对的,但在使用哑节点(dummy node)时存在一个小问题,导致返回结果不正确。我们来分析并修正:
问题所在:未正确处理哑节点的「头指针偏移」
你创建了哑节点 head 作为临时头节点(这是正确的做法),但最终直接返回了 head,而实际上 head 是我们手动创建的「空节点」,真正的合并后链表的头节点应该是 head->next。
此外,你的代码中拼接剩余节点的逻辑可以简化,不需要用 while 循环(因为链表本身是连续的,直接把剩余链表的头接过来即可)。
修正后的代码(正确使用哑节点):
cpp
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
// 创建哑节点(临时头节点),避免处理空链表的特殊情况
ListNode* dummy = (ListNode*)malloc(sizeof(ListNode));
ListNode* p = dummy; // p 作为当前节点的指针,用于拼接链表
// 当两个链表都不为空时,比较节点值并拼接
while (list1 != NULL && list2 != NULL) {
if (list1->val <= list2->val) {
p->next = list1; // 拼接 list1 的当前节点
list1 = list1->next; // list1 指针后移
} else {
p->next = list2; // 拼接 list2 的当前节点
list2 = list2->next; // list2 指针后移
}
p = p->next; // 当前指针后移,准备拼接下一个节点
}
// 拼接剩余的节点(如果有)
// 当一个链表为空时,直接把另一个链表的剩余部分接过来
if (list1 != NULL) {
p->next = list1;
} else {
p->next = list2;
}
// 哑节点的 next 才是合并后链表的真正头节点
ListNode* result = dummy->next;
free(dummy); // 释放哑节点的内存(可选,刷题时可省略)
return result;
}哑节点的作用详解:
-
统一边界处理 :当
list1或list2为空时(比如list1 = NULL,list2 = [1,2,3]),不需要单独判断「如何设置头节点」,因为哑节点dummy已经提供了一个临时的头,直接拼接即可。 -
简化指针操作 :不需要纠结「第一个节点该选谁」,无论两个链表是否为空,都可以通过
p->next来拼接节点,最后返回dummy->next即可得到正确的头节点。
关键修正点:
- 原代码中
p指针在拼接节点后没有后移(p = p->next),导致后续拼接会覆盖之前的节点,修正后通过p = p->next保证指针始终指向当前链表的末尾。 - 原代码用
while循环拼接剩余节点是多余的,因为链表是连续的,直接p->next = list1(或list2)即可把剩余所有节点接过来。 - 最终返回
dummy->next而不是dummy,因为dummy是我们手动创建的临时节点,本身不存储有效数据。
测试用例验证:
- 输入
list1 = [1,2,4],list2 = [1,3,4]→ 输出[1,1,2,3,4,4](正确)。 - 输入
list1 = [],list2 = []→ 输出[](正确)。 - 输入
list1 = [],list2 = [0]→ 输出[0](正确)。
这样修改后,哑节点的作用就体现出来了,代码更简洁且边界情况处理更优雅。
【为什么剩余拼接可以直接这么写?】
cpp
// 当一个链表为空时,直接把另一个链表的剩余部分接过来
if (list1 != NULL) {
p->next = list1;
} else {
p->next = list2;
}这么做的核心原因是链表的连续性 ------ 链表节点通过next指针串联成一个整体,只要拿到剩余链表的「头节点」,将其赋值给当前链表末尾节点的next,就能把整个剩余链表完整接过来,无需逐个节点循环拼接。
为什么可以直接这么写?
我们可以通过一个具体例子理解:假设 list1 = [1,2,4],list2 = [1,3,4]。
- 循环比较拼接阶段结束后,
list1会指向4(已拼接完1,2),list2会指向NULL(已拼接完1,3,4)。 - 此时判断
list1 != NULL,执行p->next = list1。 - 由于
list1指向的4节点,其next本身就指向NULL(原链表的末尾),所以赋值后,新链表的末尾会自动接上4,无需额外处理后续节点。
简单来说,剩余链表本身就是一个完整的、连接好的结构 ,我们只需要 "搭一根线"(即赋值p->next),就能把它整体接入,不需要逐个 "搬运" 节点。
和原代码中 while 循环的对比
你的原代码用while循环逐个拼接剩余节点,虽然结果正确,但完全没必要,属于 "多做了无用功"。
两种方式的对比:
| 实现方式 | 核心逻辑 | 时间复杂度 | 效率 |
|---|---|---|---|
直接赋值p->next |
利用链表连续性,一次赋值接入整个剩余链表 | O(1) | 高效 |
| while 循环拼接 | 逐个遍历剩余节点,重复赋值p->next |
O (k)(k 为剩余节点数) | 冗余 |
特殊场景验证
这种写法能覆盖所有剩余节点的场景,包括:
list1剩余,list2为空:直接接list1剩余部分。list2剩余,list1为空:直接接list2剩余部分。- 两者都为空:
p->next赋值为NULL,最终返回的链表也为空,符合预期。
所以放心用这种写法,它是合并有序链表问题中处理剩余节点的最优解。