当我们构建人工智能系统时,无需完全复刻人脑的生物细节------正如飞机不必模仿鸟类振翅也能飞行。核心在于通过逆向工程,将大脑的认知功能抽象为可计算的信息处理流程,从而在功能层面实现智能的等效。
具体而言,人脑通过感知器接收视觉、听觉、触觉等信号,经由神经系统进行思考与整合,最终输出指令来调动生物机体。对应地,计算机接收以浮点数数组(向量或张量)表示的输入数据,通过神经网络进行处理------其中短期记忆体现为当前上下文信息,长期记忆则固化于模型权重参数中,还可借助外部记忆如RAG、知识图谱等外挂知识库进行增强------最终输出相应的浮点数数组(向量或张量)。
这种从生物机制到计算模型的抽象,使我们能够将复杂的认知过程转化为计算机可理解与执行的算法。下面是对相关人工智能算法的汇总,供快速浏览与参考。
sklearn官方的机器学习算法引导图:
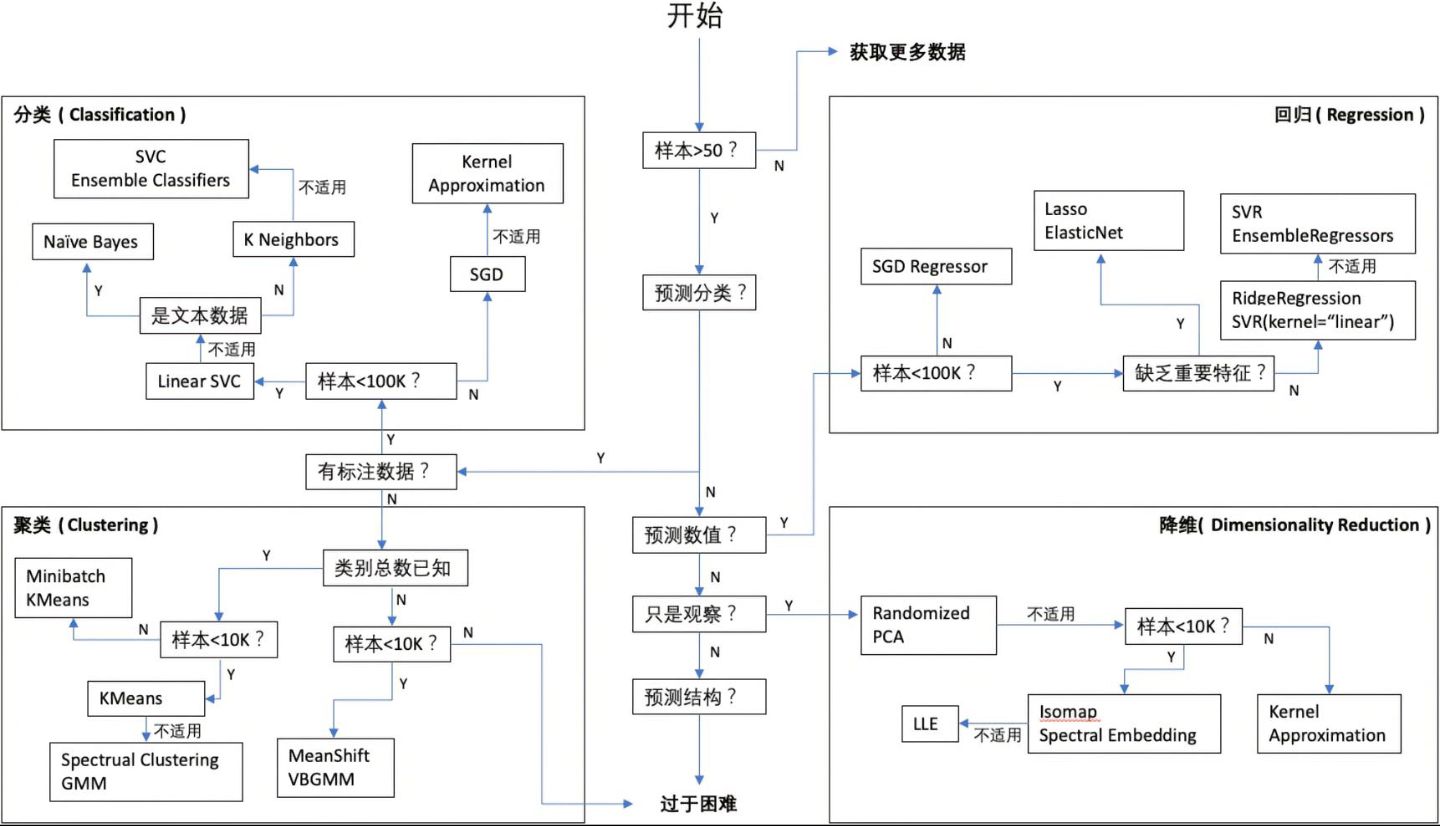
-
按学习范式分类
class LearningParadigms:
"""学习范式分类------解决问题的不同思路""" class SupervisedLearning: """监督学习:有老师指导的学习""" 特点: "使用带标签的数据进行训练", 适用场景: "分类、回归等有明确目标的任务", 代表算法: ["线性模型", "决策树", "随机森林", "神经网络"] class UnsupervisedLearning: """无监督学习:自主发现数据中的模式""" 特点: "数据无标签,算法自行发现结构", 适用场景: "聚类、降维、异常检测", 代表算法: ["K均值", "DBSCAN", "PCA", "自编码器"] class SemiSupervised: """半监督学习:少量标签+大量无标签数据的智慧结合""" 核心思想: "利用大量无标签数据增强少量有标签数据的效果", 方法: ["自训练", "协同训练", "标签传播"] class SelfSupervised: """自监督学习:自己创造学习任务""" 创新点: "从数据本身生成监督信号,无需人工标注", 典型方法: ["掩码语言模型(BERT)", "对比学习(CLIP)", "预测下一帧"] -
算法的发展历程------时间脉络
第一代:基于规则与统计(1960s-1990s)
├── 线性模型家族:线性回归、逻辑回归、LDA
├── 近邻方法:KNN、K均值聚类
└── 贝叶斯方法:朴素贝叶斯、高斯混合模型
特点:理论基础扎实,可解释性强,适合小规模数据
第二代:核方法与集成学习(1990s-2010s)
├── 支持向量机:SVM、SVR,通过核函数处理非线性
├── 决策树:CART、C4.5,直观的可解释性
├── 集成方法:随机森林、AdaBoost,1+1>2的效果
└── 概率图模型:贝叶斯网络、隐马尔可夫模型
特点:处理非线性问题,泛化能力提升
第三代:表示学习与深度学习(2010s-)
├── 神经网络:MLP、CNN、RNN,自动学习特征
├── 嵌入学习:Word2Vec、Node2Vec,学习语义表示
├── 梯度提升:XGBoost、LightGBM、CatBoost,高效集成
└── 注意力机制:Transformer,并行处理序列
特点:端到端学习,特征工程自动化
第四代:大模型与多模态(2020s-)
├── 大语言模型:GPT系列、BERT、T5,通用能力
├── 多模态模型:CLIP、DALL-E,跨模态理解
├── 生成模型:扩散模型、GAN,创造内容
└── 基础模型:通用AI能力,few-shot学习
特点:规模效应,通用智能,上下文学习
-
算法选择
def select_algorithm(problem_type, data_info, constraints):
"""算法选择决策树------系统化的选择策略""" # 第一步:确定问题类型------明确要解决什么问题 if problem_type == "分类": if data_info["样本量"] < 1000: candidates = ["逻辑回归", "决策树", "SVM", "朴素贝叶斯", "KNN"] elif data_info["样本量"] < 100000: candidates = ["随机森林", "梯度提升", "XGBoost", "LightGBM", "神经网络"] else: candidates = ["深度学习", "梯度提升", "线性模型+L1"] elif problem_type == "回归": if "时间序列" in data_info["特性"]: candidates = ["ARIMA", "LSTM", "Prophet", "TCN"] else: candidates = ["线性回归", "决策树回归", "随机森林回归", "梯度提升回归"] elif problem_type == "聚类": if data_info.get("已知簇数", False): candidates = ["K均值", "高斯混合", "谱聚类"] else: candidates = ["DBSCAN", "HDBSCAN", "OPTICS", "MeanShift"] # 第二步:考虑数据特性------数据决定算法上限 if "类别特征多" in data_info["特性"]: candidates = [c for c in candidates if c in ["CatBoost", "LightGBM", "目标编码+任意模型"]] if "缺失值多" in data_info["特性"]: candidates = [c for c in candidates if c in ["XGBoost", "LightGBM", "决策树", "深度学习"]] if "高维稀疏" in data_info["特性"]: candidates = [c for c in candidates if c in ["线性模型+L1", "FM", "深度FM"]] # 第三步:考虑约束条件------现实世界的限制 if constraints["延迟"] < 100: # 实时要求 candidates = [c for c in candidates if c in ["线性模型", "决策树", "轻量神经网络"]] if constraints["可解释性"] == "高": candidates = [c for c in candidates if c in ["线性模型", "决策树", "朴素贝叶斯"]] return candidates -
算法细化权衡
class AlgorithmTradeoffs:
"""算法选择的四个核心权衡""" # 维度1:偏差-方差权衡------过拟合与欠拟合的平衡 BIAS_VARIANCE = { "高偏差算法": ["线性回归", "朴素贝叶斯", "KNN(k小)"], "特点": "简单,容易欠拟合,训练快", "高方差算法": ["深度神经网络", "未剪枝决策树", "SVM(复杂核)"], "特点": "复杂,容易过拟合,需要大量数据", "平衡算法": ["随机森林", "梯度提升树", "弹性网络"], "特点": "在偏差和方差间取得较好平衡" } # 维度2:可解释性-性能权衡------透明度与准确率的取舍 INTERPRETABILITY_PERFORMANCE = { "高可解释性": ["线性模型", "决策树", "规则学习", "贝叶斯网络"], "适用场景": "金融风控、医疗诊断、法律决策等需要解释的领域", "中等可解释性": ["随机森林", "XGBoost", "注意力机制"], "特点": "部分可解释,通过特征重要性、注意力权重等提供洞见", "黑箱高性能": ["深度神经网络", "大语言模型", "复杂集成模型"], "适用场景": "图像识别、自然语言处理等性能优先的任务" } # 维度3:计算资源权衡------时间与空间的交换 COMPUTATION_RESOURCES = { "训练快/推理快": ["线性模型", "K均值", "朴素贝叶斯"], "适用": "实时系统、边缘计算、大规模服务", "训练慢/推理快": ["随机森林", "梯度提升树", "SVM(训练后)"], "特点": "一次训练,多次快速推理,适合线上服务", "训练慢/推理慢": ["深度神经网络", "大语言模型"], "适用": "对延迟不敏感,但对准确率要求高的场景" } # 维度4:数据需求权衡------数据质量与数量的要求 DATA_REQUIREMENTS = { "小样本算法": ["KNN", "决策树", "贝叶斯方法"], "特点": "数据少时也能工作,但可能欠拟合", "中等样本算法": ["SVM", "随机森林", "传统神经网络"], "特点": "需要一定数据量才能发挥优势", "大样本算法": ["深度学习", "自监督学习", "对比学习"], "特点": "数据越多效果越好,小数据容易过拟合" } -
数据预处理
原始数据 → 数据清洗 → 特征提取 → 特征选择 → 模型输入
↓ ↓ ↓ ↓ ↓不同类型 处理缺失值 向量化方法 过滤/包装/嵌入 统一向量
├── 数值型 填充/删除 ├── 统计特征 ├── 方差阈值 └── 浮点数
├── 类别型 编码转换 ├── 文本特征 ├── 互信息 张量
├── 文本型 分词/嵌入 ├── 图像特征 ├── 递归消除
├── 图像型 卷积特征 ├── 时序特征 └── L1正则化
└── 时序型 滑动窗口 └── 图特征
数据清洗是第一步,处理缺失值、异常值和不一致性。
特征提取将原始数据转换为有意义的特征,这是决定模型性能的关键。
特征选择去除冗余和不相关特征,提高效率和泛化能力。
class FeatureEngineeringHierarchy:
"""特征工程的三层体系------从基础到高级""" class Level1_Basic: """基础转换:数据准备的基本功""" 标准化: ["MinMax缩放", "Z-Score标准化", "鲁棒缩放"], 编码: ["One-Hot编码", "标签编码", "目标编码", "嵌入编码"], 特点: "通用性强,几乎每个项目都需要" class Level2_DomainSpecific: """领域特定特征:专家知识的体现""" 文本特征: ["TF-IDF(词重要性)", "Word2Vec(词向量)", "BERT嵌入(上下文语义)"], 图像特征: ["HOG(边缘纹理)", "SIFT(关键点)", "CNN特征(深度学习)", "ViT特征(视觉Transformer)"], 时序特征: ["滑动窗口统计", "傅里叶变换(频域特征)", "小波变换(时频分析)"], 图特征: ["Node2Vec(节点嵌入)", "GCN特征(图神经网络)", "图核方法"], 特点: "需要领域知识,效果提升明显" class Level3_Advanced: """高级特征工程:自动化和智能化的前沿""" 特征交叉: ["多项式特征(显式交叉)", "FM特征(因子分解机)", "深度交叉网络"], 自动特征工程: ["自动编码器(无监督特征学习)", "神经架构搜索(自动设计网络)", "元学习特征"], 元特征: ["模型预测作为特征(堆叠集成)", "图特征(关系特征)", "时间序列特征"], 特点: "自动化程度高,适合复杂问题和大数据" -
人工智能的记忆演进
class StateEvolution:
"""模型记忆演进------从独立样本到连续思考""" class StatelessModels: """无状态模型:传统机器学习的基石""" 特点: "每个样本独立处理,无记忆功能", 代表算法: ["线性模型", "决策树", "SVM", "随机森林"], 适用场景: "IID(独立同分布)数据,无时序依赖", 局限性: "无法处理序列依赖,对话等连续任务" class SequenceModels: """序列模型:处理时序依赖的突破""" 特点: "通过隐藏状态传递信息,具有短期记忆", 代表算法: ["RNN(简单循环网络)", "LSTM(长短期记忆)", "GRU(门控循环单元)", "TCN(时序卷积)", "Transformer"], 记忆机制: "隐藏状态作为短期工作记忆", 应用: "机器翻译、语音识别、股票预测" class MemoryAugmented: """记忆增强模型:显式记忆存储""" 特点: "引入外部记忆模块,可读写存储", 代表算法: ["神经图灵机", "记忆网络", "知识增强的Transformer"], 记忆类型: ["键值记忆(检索式)", "矩阵记忆(矩阵存储)", "图记忆(结构化存储)"], 优势: "可存储大量信息,支持复杂推理" class WorldModels: """世界模型:内部模拟环境的能力""" 特点: "学习状态转移模型,能预测未来状态", 代表算法: ["世界模型(World Models)", "Dreamer", "MuZero(AlphaZero扩展)"], 能力: "想象推理、规划未来、反事实思考", -
算法的复杂度和能力范围
低复杂度 中等复杂度 高复杂度
↓ ↓ ↓线性模型 决策树/SVM 深度神经网络
| | |KNN/朴素贝叶斯 随机森林/GBDT Transformer
| | |K均值/层次聚类 谱聚类/DBSCAN 图神经网络
| | |Apriori/FP-Growth 矩阵分解 生成对抗网络
| | |ARIMA/SARIMA Prophet/LSTM 扩散模型
↓ ↓ ↓简单快速 平衡性能 强大复杂
易于解释 部分可解释 黑箱模型
小数据适用 中等数据 大数据需求
计算高效 适中计算 高计算成本
-
按场景选择算法
QUICK_SELECTION_GUIDE = {
# 按数据规模选择------数据量决定算法选择 "小数据场景(<1K样本)": { "分类任务": ["逻辑回归", "决策树", "朴素贝叶斯", "SVM", "KNN"], "选择理由": "简单模型防止过拟合,可解释性强", "回归任务": ["线性回归", "决策树回归", "SVR(支持向量回归)"], "选择理由": "参数少,避免过拟合", "聚类任务": ["K均值", "层次聚类", "DBSCAN"], "选择理由": "计算量小,结果直观" }, "中等数据场景(1K-100K样本)": { "分类任务": ["随机森林", "XGBoost", "LightGBM", "神经网络"], "选择理由": "集成方法发挥优势,深度学习开始有效", "回归任务": ["梯度提升回归", "随机森林回归", "神经网络回归"], "选择理由": "能捕捉非线性,效果稳定", "聚类任务": ["K均值++", "高斯混合模型", "谱聚类"], "选择理由": "能处理更复杂的聚类结构" }, "大数据场景(>100K样本)": { "分类任务": ["深度学习", "分布式梯度提升", "线性模型+特征工程"], "选择理由": "深度学习需要大量数据,分布式处理必要", "回归任务": ["深度学习", "分布式梯度提升"], "选择理由": "复杂模式需要大模型和大数据", "聚类任务": ["MiniBatch K-means", "BIRCH", "流式聚类"], "选择理由": "需要可扩展的聚类算法" }, # 按特殊需求选择------功能导向的选择 "需要强解释性": ["决策树", "线性模型", "规则学习", "贝叶斯网络"], "适用领域": "金融风控、医疗诊断、法律合规", "需要高性能": ["深度学习", "XGBoost", "LightGBM", "集成模型"], "适用领域": "图像识别、广告推荐、搜索排序", "需要实时推理": ["线性模型", "决策树", "轻量神经网络", "KNN"], "适用领域": "自动驾驶、高频交易、实时推荐", "需要在线学习": ["在线梯度下降", "感知机", "贝叶斯更新"], "适用领域": "数据流处理、用户行为建模、动态系统" -
阶段划分
开发阶段 → 部署阶段 → 运维阶段
↓ ↓ ↓算法选择 → 模型优化 → 性能监控
数据准备 → 服务封装 → 漂移检测
特征工程 → 接口设计 → 自动更新
模型训练 → 压力测试 → A/B测试
模型评估 → 版本控制 → 日志分析
开发阶段:关注算法效果和实验的可复现性。使用交叉验证确保泛化能力,记录所有实验参数和结果。
部署阶段:关注效率和稳定性。进行模型压缩(剪枝、量化、蒸馏)减少资源消耗,设计清晰的API接口,进行压力测试确保可靠性。
运维阶段:关注长期价值。监控模型性能衰减,检测数据分布漂移,建立自动化的模型更新流程,通过A/B测试验证改进效果。
-
总结
-
理解问题本质
↓
-
分析数据特性
↓
-
选择算法范式(监督/无监督/强化学习)
↓
-
确定算法家族(线性/树/神经网络/集成)
↓
-
考虑约束条件(计算/延迟/解释性)
↓
-
实验验证(交叉验证/超参数调优)
↓
-
部署优化(模型压缩/服务化/监控)
-
简单优先原则:能用线性模型解决的问题,不要用神经网络。复杂模型不仅计算成本高,维护难度也大。
-
数据驱动思维:让数据特性指导算法选择,而不是盲目追求最新技术。数据质量和数量决定了算法的限。
-
可解释性权衡:在业务敏感领域优先考虑可解释性,在性能优先领域可以接受黑箱模型。
-
一点思考:
看完这些算法,其实,我们会发现,当前人工智能的核心运行范式,本质上是建立在统计相关性与概率预测的数学基础之上,其工作实质可归结对海量数据中模式的识别与概率分布的拟合。
尽管现代AI系统能够生成流畅自然的文本、完成复杂的分类任务,甚至在特定条件下展现出类似推理的行为,但有一个问题,AI缺乏元认知能力(对自身认知过程的觉察、监控与调控的高级心智功能)。由于不具备自我意识,AI无法区分"自我"与"外部世界",也没有内在的机制来判断信息的重要性、意义或真实性。
它的所有输出,都源于对训练数据中统计规律的编码与再现:系统将输入映射到高维向量空间中的某个区域,并激活与之在训练过程中建立强关联的模式响应。这一过程虽然在工程上极其复杂与精密,本质上仍是一种高度优化的**数学拟合与模式重组**,而非非我们所设想的那种基于意图、理解与反思之上的真正认知。
比如,当我们思考"AI是否具有想象力"时,便可以感知到这一点。AI可以生成前所未见的文本组合或图像风格,但这并非源于自主的、有目的的创造性想象,而是对其所学分布之外插值或已有元素的统计重构。它无法像人类一样,在想象时伴随对想象内容本身的觉察、评价与意图调节。这正是缺乏元认知与自我意识所导致的能力缺失。
目前,只能人输入指令,它就输出,输出完就停止了,等待下一次的输入来触发AI的思考,它不能像人一样自发地思考,而且并不认为AI有想象力,当人的指令里有它没有接触过,也搜索不到的信息,它只是会把空间里相近的信息整合后都输出,我们看到它在答非所问,输出虚假信息,也就是出现幻觉,这不是想象力的表现。所以,后续算法的发展有一部分应该是解决AI缺乏元认知能力的问题。
对自身推理过程的"觉察"与"监控":让AI能评估自身思考的可靠性、置信度或进展。基于此觉察进行"调节"与"优化":动态调整策略,例如决定是否需要更深度思考,或复用有效推理模式。
搜了一下,2025年的这方面算法和架构:
| 名称 | 核心思路 (如何实现"类元认知") |
|---|---|
| SOFAI 架构 | 构建三层系统:快AI (直觉反应)、慢AI (深度推理)、元认知层(监督者)。元认知层像"项目经理",评估快AI的答案质量,决定是否需启动慢AI。 |
| 元认知复用机制 | 让AI在解决问题后,回顾并提炼推理步骤中的通用"套路",存入"行为手册"。遇到同类问题时直接调用,避免重复推导。 |
| 元能力对齐训练框架 | 基于心理学"推理三元组"(演绎、归纳、溯因),自动化生成三类推理的训练数据。让AI系统化地学习和融合这些基础推理元能力。 |
| Meta-R1 | 受认知科学启发,将推理过程分解为对象级 (解决问题)和元级(管理过程)。元级负责主动规划、在线调节和自适应早期停止。 |
ok,结束。