Mixture-of-RAG: Integrating Text and Tables with Large Language Models
论文:Mixture-of-RAG: Integrating Text and Tables with Large Language Models、项目代码暂无
时间:2025.8.11
mixRAG针对文本+表格组成的混合文档问题进行改进,检索阶段分为文本分块+表行列级摘要、检索阶段在混合检索之后让LLM再次筛选文档、生成阶段分析问题类型,融合文本推理和符号推理。。
一、论文动机
现有检索增强生成(RAG)系统虽能结合大语言模型(LLMs)的生成能力与外部检索信息,但在处理文本 - 表格混合的异质文档(如年度报告、科研论文、临床指南)时存在显著缺陷:
结构丢失:传统文本 RAG 无法捕捉表格的层级结构(如跨行 / 列表头定义的数据关系),关键数值(如每股收益、剂量限制)的语义关联易断裂;
检索偏差:基于语义相似性的检索可能遗漏关键历史数据(如查询 2014 年数据却需 2012-2013 年趋势);
推理困难:复杂计算任务(如多步数值推导)中,文本与表格信息难以协同,且现有数据集缺乏文本 - 表格混合的高质量标注。
为此,研究提出异质文档 RAG 任务,需实现文本与层级表格数据的联合检索与推理,并针对性开发 MixRAG 框架及 DocRAGLib 数据集。
二、核心架构
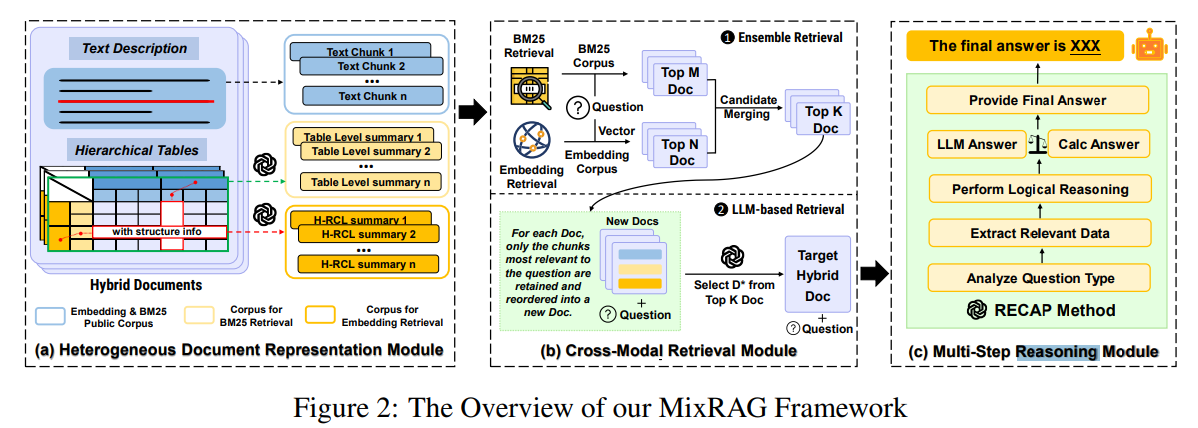
这是MixRAG(Mixture - of - RAG)框架的整体架构图,分为三个核心模块,用于解决异质文档(文本与层级表格混合)的检索增强生成任务,以下是各模块的详细讲解:
(a)异质文档表示模块(Heterogeneous Document Representation Module)
该模块负责对混合文档(包含文本描述和层级表格)进行预处理与表示,为后续检索和推理提供基础:
-
文本处理:将文本拆分为多个文本块(Text Chunk),便于后续基于文本块的检索操作。
-
表格处理:
- 生成表格级摘要(Table Level summary),对表格整体内容进行概括性描述。
- 生成H - RCL(Hierarchical Row - Column - Level,层级行列级)摘要,这种摘要保留了表格的层级结构信息(比如跨行、列表头所定义的数据关系等),能更精准地捕捉表格数据的语义关联,避免传统表格表示丢失结构信息的问题。
表格级摘要提供了一个概览,但丢失了细粒度的结构信息。过度抽象降低了检索时的区分能力,导致在区分相似表格时精度下降且模糊性增加。
单元格级摘要提供了高度具体和详细的描述,捕捉到了单元格级的语义,这些语义对于检索往往很有用。然而,这种精细的粒度是以冗余和低检索效率为代价的,因为单元格之间的重复表达会增加输入长度,并在检索过程中淡化相关性。由于单元格级摘要成本高且计算开销大,在实验设计中没有包含它。
论文专注于行和列级(RCL)摘要,这种摘要通过在标题级别对内容进行总结,在结构保留和表达简洁性之间取得了平衡。为了进一步减少噪声,还对表格单元格中的非语义数值进行了掩码处理。RCL这种中间立场的表示保留了表格的层次结构,并保留了检索所必需的标题级语义。这种设计能够使表格内容和问题之间实现更有效的对齐,为异构文档中的检索奠定了基础。
-
语料库构建:分别为嵌入检索(Embedding Retrieval)和BM25检索构建对应的语料库(Corpus for Embedding & BM25、Corpus for H - RCL Retrieval),使不同检索方式能基于合适的文档表示开展工作。
(b)跨模态检索模块(Cross - Modal Retrieval Module)
此模块通过两种检索方式的结合,从异质文档语料库中检索出与问题相关的文档:
- 集成检索(Ensemble Retrieval) :
- BM25检索:基于BM25语料库,利用关键词匹配的方式,检索出与问题相关的Top - M个候选文档。
- 嵌入检索(Embedding Retrieval):基于嵌入语料库,通过计算文本嵌入向量的语义相似度,检索出Top - N个候选文档。
- 候选合并(Candidate Merging):将BM25检索和嵌入检索得到的候选文档去重后,合并得到Top - K个候选文档,这样能同时覆盖关键词相关和语义相关的潜在证据文档。
- 基于LLM的检索(LLM - based Retrieval) :
- 对于集成检索得到的每个候选文档,筛选出与问题语义最相关的文本块,重新组合成"新文档(New Docs)",减少冗余噪声。
- 将问题和新文档输入大语言模型(LLM),由LLM从Top - K个候选文档中筛选出最相关的目标混合文档(Target Hybrid Doc)。
(c)多步推理模块(Multi - Step Reasoning Module)
该模块基于检索到的目标混合文档,通过多步推理生成最终答案,采用了RECAP方法:
- 分析问题类型(Analyze Question Type):明确问题的需求和类型,比如是数值计算、事实问答还是逻辑推理等。
- 提取相关数据(Extract Relevant Data):从目标混合文档中提取推理所需的关键数据。
- 执行逻辑推理(Perform Logical Reasoning):大语言模型(LLM)生成推理步骤,若涉及数值计算,还会结合外部计算器等工具。
- 生成答案(Provide Final Answer):同时获取LLM直接生成的答案(LLM Answer)和经过计算得到的答案(Calc Answer),并通过一定规则选择更优的最终答案(The final answer is XXX)。
三、实验验证
1. 实验设置
- 模型与工具 :检索用
text-embedding-3-large,推理用GPT-4o/4o mini、Qwen2.5-32B、Mistral-Nemo-2407、Llama-3.1-8B; - 评价指标:检索用HiT@K(K=1,3,5,10),问答用EM(精确匹配);
- 基线方法:Standard RAG、LangChain、Self-RAG、Table Retrieval(表格专用检索)。
2. 核心结果
(1)检索性能对比(表1)
| 方法 | HiT@1 | HiT@3 | HiT@5 | HiT@10 | EM |
|---|---|---|---|---|---|
| Standard RAG | 0.0159 | 0.0339 | 0.0538 | 0.1255 | 0.0092 |
| LangChain | 0.2390 | 0.4104 | 0.4821 | 0.5219 | 0.1301 |
| Self-RAG | 0.2829 | 0.4502 | 0.5000 | 0.5598 | 0.2141 |
| Table Retrieval | 0.3705 | 0.5299 | 0.5996 | 0.6494 | 0.2541 |
| MixRAG | 0.5410 | 0.7244 | 0.7603 | 0.8689 | 0.3228 |
MixRAG的HiT@1达0.541,较最强基线(Table Retrieval)提升46%;EM分数0.3228,较其提升27.1%。
(2)消融实验
- 表格表示策略影响:H-RCL总结较表格级总结,HiT@1提升47%,EM提升28%,验证层级结构保留的必要性;
- 检索模块影响:仅用BM25/嵌入检索时,HiT@1降至0.3545/0.2787;移除LLM重排序后,HiT@1进一步下降0.19-0.20,证明两阶段检索的优势;
- 推理模块影响:禁用RECAP的外部计算器后,EM从0.3238降至0.2838,凸显精确计算的重要性。
(3) scalability分析
随文档 corpus 规模扩大(从280到2178份),MixRAG的HiT@K下降速率显著低于基线(如HiT@10仍保持0.8以上),证明其在大规模文档库中的稳定性。
四、局限性与未来方向
- 多文档证据聚合:当前仅基于Top-1检索文档生成答案,无法处理需多文档联合推理的任务,未来需扩展多文档检索与信息融合能力;
- 多模态扩展:未覆盖图像、示意图等视觉模态,需将视觉信息纳入RAG框架;
- 效率优化:LLM重排序与多步推理的计算成本较高,未来可探索轻量级模型替代或蒸馏策略。
五、核心价值
MixRAG首次系统性解决文本-表格混合异质文档的RAG问题,其H-RCL表示、两阶段检索、RECAP推理的设计思路,为金融报告分析、科研文献问答、临床指南解读等实际场景提供了可行方案;DocRAGLib数据集也填补了异质文档RAG领域的基准空白,推动相关研究发展。