ReAcTable: Enhancing ReAct for TableQuestion Answering
论文:ReAcTable: Enhancing ReAct for Table Question Answering、 项目代码、Proceedings of the VLDB Endowment,CCF-A
时间:2023.11
ReAcTable框架是一种基于ReAct范式的表格问答解决方案,通过融合大语言模型的逐步推理能力、SQL/Python代码执行器的外部工具支持,以及多数投票机制,在无需模型微调的前提下,实现了TQA任务性能的显著提升。
一、研究背景与问题
1. TQA任务定义与价值
- 任务本质:表格问答(TQA)是自然语言处理(NLP)与数据分析的交叉任务,需基于表格数据(如维基表格、Excel表、关系表)回答自然语言问题,核心要求包括逻辑推理、数据语义理解和基础分析能力。
- 核心价值:让无查询语言(如SQL)和数据分析基础的用户通过自然语言与数据交互,提升数据可访问性,支持多领域决策(如商业分析、科研数据解读)。
2. 现有研究缺口
现有TQA解决方案分为两类,但存在明显不足:
| 解决方案类别 | 代表方法 | 核心局限 |
|---|---|---|
| 训练/微调专用模型 | Tapas、Tapex、Tacube、OmniTab | 需大量标注数据,训练成本高,泛化性受限 |
| 基于预训练LLM | Binder、Dater(生成代码操作表格) | 未充分利用LLM的增量推理+外部工具协作能力(如ReAct范式),难以应对TQA的独特挑战 |
TQA任务的三大独特挑战:
- 复杂数据语义解读:数据信息常嵌入字符串(如"骑行者(国家缩写)"),需提取隐藏语义;
- 数据噪声与不一致:表格可能存在缺失值、格式混乱,导致代码执行错误;
- 复杂数据转换需求:多步推理需多次数据格式调整(如筛选→提取→统计),单一工具难以完成。
二、核心解决方案:ReAcTable框架
ReAcTable是ReAct范式在TQA任务的定制化增强版本,核心逻辑是**"LLM逐步推理+外部代码执行器生成中间表+多数投票优化结果"**,通过迭代将原始表格逐步转化为可直接回答问题的格式。
1. 框架核心组件
| 组件 | 功能描述 |
|---|---|
| 输入模块 | 原始表格((T_0))+ 自然语言问题(N) |
| LLM决策中心 | 每轮迭代执行3种操作之一:生成SQL代码、生成Python代码、直接输出答案 |
| 外部代码执行器 | - SQL executor:处理结构化数据操作(筛选、分组、统计,如"筛选Top-10骑行者") - Python executor:处理复杂数据转换(字符串提取、格式清洗,如"从骑行者列提取国家缩写") |
| 中间表生成器 | 执行代码后生成中间表格((T_1, T_2, ..., T_n)),逐步优化数据结构,为后续推理提供清晰上下文 |
| 多数投票机制 | 解决LLM输出不确定性,提供3种投票策略(简单多数投票、树探索投票、基于执行结果的投票) |
2. 核心工作流程
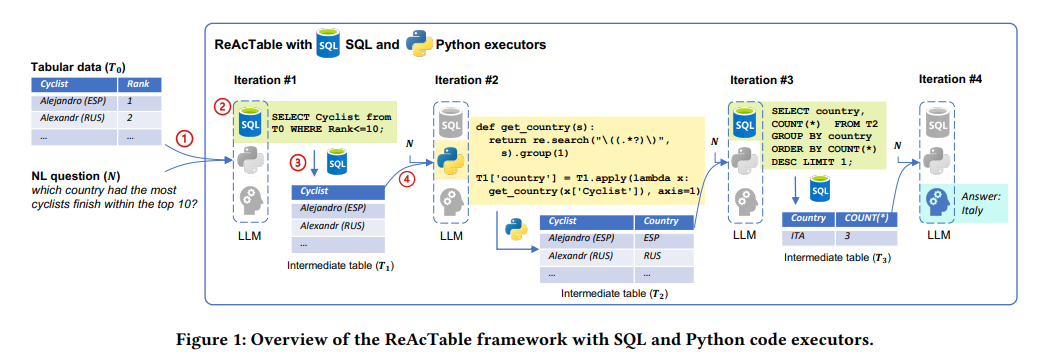
示例问题:"Which country had the most cyclists finish in the top-10?"(哪个国家有最多骑行者进入前十名?),原始表格含"Cyclist(骑行者+国家缩写)"和"Rank(排名)"两列,流程分4轮迭代:
- 迭代1(SQL执行) :生成
SELECT Cyclist from T0 WHERE Rank<=10;,筛选Top-10骑行者,得到中间表(T_1)(仅含Cyclist列); - 迭代2(Python执行) :生成正则表达式函数
get_country(s),提取(T_1)中Cyclist列的国家缩写,新增Country列,得到中间表(T_2)(Cyclist+Country); - 迭代3(SQL执行) :生成
SELECT Country, COUNT(*) FROM T2 GROUP BY Country ORDER BY COUNT(*) DESC LIMIT 1;,统计各国Top-10人数,得到中间表(T_3)(Country+COUNT(*)); - 迭代4(直接回答):基于(T_3)结果,输出自然语言答案"Answer: Italy"。
3. 关键优化设计
- 工具分工适配:SQL负责"结构化查询",Python负责"非结构化转换",贴合数据科学家操作习惯,避免单一工具局限性;
- 异常处理机制 :
- SQL异常:若查询列不存在,反向重试历史中间表,同时归一化列名(移除空格、特殊字符);
- Python"模块缺失":实时安装缺失库并重新执行;
- 其他异常:强制LLM输出答案(在prompt末尾追加"Answer:");
- 提示工程(Prompting) :
- 初始prompt含原始表格、问题、CoT(逐步推理)指令和少量示例(few-shot);
- 每轮迭代更新prompt:追加前一轮的代码+中间表,确保LLM掌握完整推理上下文。
4.投票机制
原文另有伪代码解释,有需要请查看原文
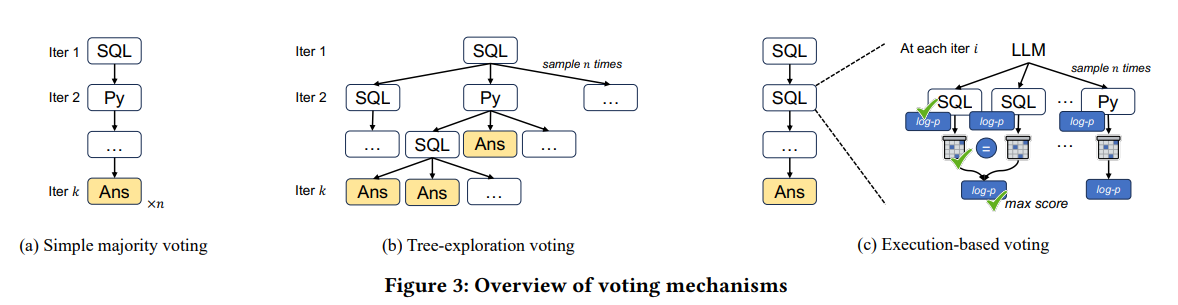
| 投票机制名称 | 原理 | 优势 | 不足 | 适用场景 |
|---|---|---|---|---|
| 简单多数投票(Simple majority voting) | 对LLM设置较高温度,多次执行ReAcTable迭代求解过程,获取多个预测答案,将出现次数最多的答案作为最终预测结果 。过程中以链条表示问题解决步骤,节点代表LLM预测的程序或答案。 | 能探索多种可能的解决方案路径,充分利用LLM在高温设置下产生的多样化输出 。 | LLM在高温设置下不确定性增加,可能导致预测质量下降,进而影响最终性能 。 | 任务相对简单,对计算资源要求不高,希望快速获取多个不同可能性答案并从中选择的场景 。 |
| 树探索投票(Tree - exploration voting) | 允许LLM在得出最终答案前探索多个中间步骤,每次预测时让LLM进行多次采样,在推理树中产生多个分支。遍历推理树所有分支,直至每个分支得出答案,选择出现次数最多的答案作为最终预测 。 | 能更全面、深入地探索问题的解决方案,考虑多种推理路径和中间步骤,提高预测的准确性和可靠性 。 | 计算复杂度相对较高,需要更多的计算资源和时间来遍历推理树的各个分支 。 | 问题较为复杂,需要考虑多种可能推理路径和中间步骤,对结果准确性要求较高的场景 。 |
| 基于执行的投票(Execution - based voting) | 在推理的每个步骤,让LLM进行多次预测。若预测是程序,则执行该程序并获取结果表,若产生等效结果表,通过选择最大对数概率合并日志概率,选择得分最高的代码或答案作为推理链中的下一步 。 | 优先选择执行时更可能产生语义正确结果的代码段,强调生成代码的实用性和正确性,有效利用代码执行的中间结果进行决策 。 | 需要对代码执行结果进行评估和比较,增加了一定的计算和判断成本 。 | 对生成代码的正确性和实用性要求较高,数据可能存在噪声或不一致性,需要通过执行结果来验证和筛选的场景 。 |
三、实验评估
1. 实验设置
| 维度 | 具体配置 |
|---|---|
| 基准数据集 | 3个主流TQA数据集: - WikiTQ(14k训练/4.3k测试,答案含单值、列表、分析结果) - TabFact(1.9k测试,二进制答案"是/否",事实核查任务) - FeTaQA(7.3k训练/2k测试,自由格式自然语言答案) |
| 基线方法 | - 需训练:Tapex、TaCube、OmniTab、T5系列(Small/Base/Large) - 无需训练:Binder、Dater |
| LLM与参数 | 默认LLM为Code-Davinci-002(Codex),多数投票时温度设为0.6(探索多样性),无投票时设为0(确定性输出) |
| 评估指标 | - WikiTQ/TabFact:准确率(Accuracy) - FeTaQA:ROUGE-1/ROUGE-2/ROUGE-L(自然语言答案相似度) |
2. 核心实验结果
(1)性能对比:超越主流基线
| 数据集 | 关键结果 |
|---|---|
| WikiTQ | ReAcTable(s-vote,简单多数投票)准确率68.0%,超越最佳基线(Lever,62.9%)5.1%,且无需微调;无投票时仍达65.8%,优于无训练基线Dater(65.9%) |
| TabFact | ReAcTable(s-vote)准确率86.1%,超越所有无训练基线(Dater,85.6%),但低于需训练的最佳基线PASTA(90.8%)4.7% |
| FeTaQA | ReAcTable的ROUGE-1达0.71,高于最佳基线Dater(0.66),在自由格式答案生成上表现最优 |
(2)消融实验:关键组件的贡献
- 中间表的价值:移除中间表的对比方法Codex-CoT(仅单次代码生成)在WikiTQ准确率仅49.4%,而ReAcTable达65.8%,提升16.4%,证明"逐步优化数据上下文"是性能核心;
- Python执行器的必要性:仅保留SQL执行器时,WikiTQ准确率从65.8%降至62.5%,TabFact从83.1%降至75.4%,说明Python对复杂数据转换的不可替代性;
- 迭代次数的影响:70%以上问题可在2轮迭代内解决,2轮迭代时WikiTQ准确率达65.1%(1轮仅49.2%),但限制迭代次数(如强制≤2轮)会降低复杂问题准确率,需保留迭代灵活性。
(3)LLM适配性:兼容多种模型
ReAcTable可与不同GPT系列模型协作,但性能受模型类型影响:
| LLM模型 | WikiTQ最高准确率 | TabFact最高准确率 | 特点 |
|---|---|---|---|
| Code-Davinci-002(默认) | 68.0%(s-vote) | 86.1%(s-vote) | 代码生成专用模型,适配性最佳 |
| Text-Davinci-003 | 65.0%(e-vote) | 83.6%(e-vote) | 文本生成模型,需依赖"基于执行结果的投票"筛选正确代码 |
| GPT-3.5-Turbo | 52.5%(t-vote) | 74.4%(t-vote) | 聊天模型,答案格式非标准化(如结构化答案生成自然句),准确率最低 |
四、研究结论与未来方向
1. 核心结论
- 性能优势:ReAcTable在无模型微调的前提下,超越多数TQA基线,尤其在WikiTQ(68.0%)和FeTaQA上表现突出,验证了"LLM+外部工具+中间表"范式的有效性;
- 关键组件:中间表的逐步生成是性能提升核心,Python执行器对复杂数据转换不可或缺,多数投票可进一步优化LLM输出不确定性;
- 灵活性:兼容多种LLM和代码执行器,无需训练即可部署,降低TQA任务的技术门槛。
2. 局限性与未来方向
-
基础理论依赖:ReAct范式(LLM与外部工具交互)、CoT提示(逐步推理)、多数投票机制
-
局限性:依赖人工设计的few-shot示例,未支持多表格问答,最佳投票策略需人工匹配LLM类型;
-
未来方向 :
-
自动prompt优化与few-shot示例选择;
-
扩展多表格TQA场景;
-
设计自适应投票策略(自动匹配LLM能力)。
-