使用Pytorch实现transformer文本分类
安装前置包
python
import torch
import torchtext # pip install torchdata
import numpy as np
from torch import nn, Tensor
import torch.nn.functional as F
from torch.utils import data
import math
from torch.nn import TransformerEncoder, TransformerEncoderLayer可能报错
ImportError: /opt/conda/lib/python3.8/site-packages/torchtext/_torchtext.so: undefined symbol: _ZNK3c104Type14isSubtypeOfExtERKSt10shared_ptrIS0_EPSo
这个错误表明 torchtext 与当前 PyTorch 版本存在兼容性问题。undefined symbol 错误通常是由于不同版本的 C++ ABI 不匹配导致的。解决方法是安装兼容的torch 和 torchtext比如
torch==2.0.0
torchtext==0.15.1或者
torch==2.1.2
torchtext==0.16.2
TorchText文本分类数据集
这里我们使用imdb数据集作为演示
获取数据
python
train_iter, test_iter = torchtext.datasets.IMDB()文本处理
我们在做自然语言处理有两步是必不可少的,一个是分词,一个是词表
python
from torchtext.data.utils import get_tokenizer # 分词工具
from torchtext.vocab import build_vocab_from_iterator # 创建词表工具
tokenizer = get_tokenizer('basic_english') # 分词工具做初始化
def yield_tokens(data):
for _, text in data:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<pad>", "<unk>"])
vocab.set_default_index(vocab["<unk>"]) #当查询词表中不存在的词时,返回 <unk> 的索引,避免因遇到未知词而报错验证词表
python
vocab(['this', 'is', 'a', 'book', 'about', 'pytorch'])输出
[18, 110, 56, 216, 57, 21]
定义collate_batch方法
collate_batch 就像一个"数据装配工",负责将一批杂乱无章的原始数据,整理成整齐划一的、神经网络可以直接"食用"的格式。
python
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: int(x == 2)
def collate_batch(batch):
label_list, text_list = [], []
for (_label, _text) in batch:
label_list.append(label_pipeline(_label))
precess_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(precess_text)
label_list = torch.tensor(label_list) # 标签列表直接转换为张量
text_list = torch.nn.utils.rnn.pad_sequence(text_list) # 文本序列填充到相同长度
return label_list.to(device), text_list.to(device)创建DataLoader
python
train_dataloader = DataLoader(train_iter, batch_size=128,
shuffle=True, collate_fn=collate_batch)
test_dataloader = DataLoader(test_iter, batch_size=128,
shuffle=True, collate_fn=collate_batch)DataLoader可视化流程
原始数据流 train_iter
↓ 每次next()获取一个样本
┌─────────────────────────────────┐
│ 样本1: (标签1, 文本1) │
│ 样本2: (标签2, 文本2) │→ DataLoader收集batch_size个
│ 样本3: (标签3, 文本3) │
│ ... │
└─────────────────────────────────┘
↓ 收集完成后
传递给 collate_batch() 函数
↓
进行预处理:
- 标签转换(label_pipeline)
- 文本转换(text_pipeline)
- 序列填充(pad_sequence)
↓
返回整理好的批次:
(标签张量, 文本张量)
创建模型
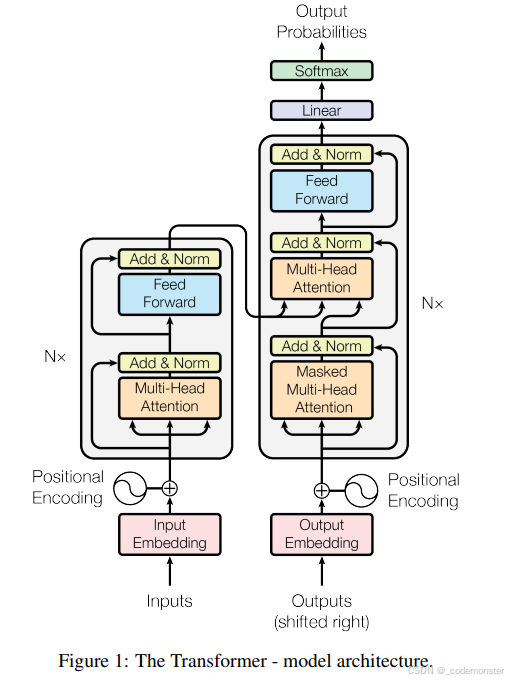
这里给出Attention is all you need 原文中的模型示意图,所有的代码都是基于这个图片创建的。
位置编码
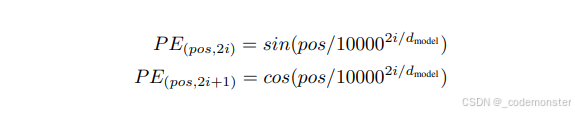
python
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout: float=0.1, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1) # (length, 1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model) # (length, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x: Tensor, max_len=1000) -> Tensor:
"""
Arguments:
x: Tensor, shape ``[seq_len, batch_size, embedding_dim]``
"""
x = x[:max_len, :, :] + self.pe[:x.size(0), :]
return self.dropout(x)上面代码中div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))巧妙使用幂运算转为乘法运算。这里的位置编码属于固定编码。
-> Tensor类似于这种类型的都属于类型注解,代表返回值的类型应该是个 Tensor。
定义Transformer模型
python
class TransformerModel(nn.Module):
def __init__(self, ntoken: int, d_model: int, nhead: int, d_hid: int,
nlayers: int, dropout: float = 0.5):
super().__init__()
self.model_type = 'Transformer'
self.pos_encoder = PositionalEncoding(d_model, dropout)
encoder_layers = TransformerEncoderLayer(d_model, nhead, d_hid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.embedding = nn.Embedding(ntoken, d_model)
self.d_model = d_model
self.linear = nn.Linear(d_model, 2) # 2 class: pos, reg
self.init_weights()
def init_weights(self) -> None:
initrange = 0.1
self.embedding.weight.data.uniform_(-initrange, initrange)
self.linear.bias.data.zero_()
self.linear.weight.data.uniform_(-initrange, initrange)
def forward(self, src: Tensor, src_mask: Tensor = None) -> Tensor:
"""
Arguments:
src: Tensor, shape ``[seq_len, batch_size]``
src_mask: Tensor, shape ``[seq_len, seq_len]``
Returns:
output Tensor of shape ``[seq_len, batch_size, ntoken]``
"""
# Embeding层输出shape:((sequece_length,batchsize, d_model))
src = self.embedding(src) * math.sqrt(self.d_model)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, src_mask)
# print("output:", output.size()) # 输出shape:((sequece_length,batchsize, d_hid))
output = output[0, :, :]
output = self.linear(output)
return output output = output[0, :, :]之所以用第0个来代表整体的分类,是因为这里的第0个数据已经和所有的特征都进行了交互,所以用第0个就行。其实也可以改成 output = output[1, :, :]或者 output = output[2, :, :]...因为本质上这些位置的数据都和所有的数据实现了交互,所以有的模型中直接用开头cls来进行整体的分类也是合理的。
定义初始参数
python
ntokens = len(vocab) # size of vocabulary
d_model = 200 # embedding dimension
d_hid = 2048 # dimension of the feedforward network model in ``nn.TransformerEncoder``
nlayers = 2 # number of ``nn.TransformerEncoderLayer`` in ``nn.TransformerEncoder``
nhead = 2 # number of heads in ``nn.MultiheadAttention``
dropout = 0.2 # dropout probability
model = TransformerModel(ntokens, d_model, nhead, d_hid, nlayers, dropout).to(device)定义损失函数
python
loss_fn = nn.CrossEntropyLoss()
from torch.optim import lr_scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=60, gamma=0.1)定义训练函数
python
def train(dataloader):
total_acc, total_count, total_loss, = 0, 0, 0
model.train()
for label, text in dataloader:
predicted_label = model(text)
loss = loss_fn(predicted_label, label)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
total_loss += loss.item()*label.size(0)
return total_loss/total_count, total_acc/total_count定义测试函数
python
def test(dataloader):
model.eval()
total_acc, total_count, total_loss, = 0, 0, 0
with torch.no_grad():
for label, text in dataloader:
predicted_label = model(text)
loss = loss_fn(predicted_label, label)
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
total_loss += loss.item()*label.size(0)
return total_loss/total_count, total_acc/total_count开始训练
python
def fit(epochs, train_dl, test_dl):
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc = train(train_dl)
epoch_test_loss, epoch_test_acc = test(test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
exp_lr_scheduler.step()
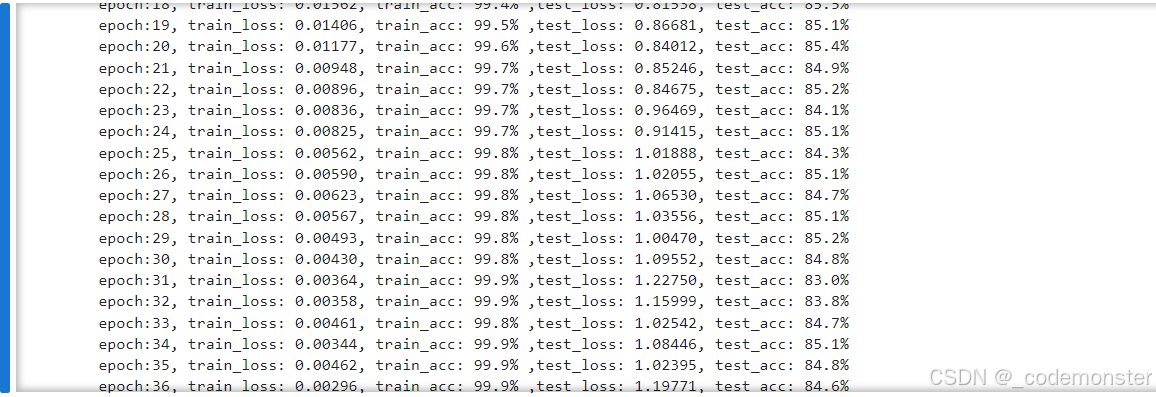
template = ("epoch:{:2d}, train_loss: {:.5f}, train_acc: {:.1f}% ,"
"test_loss: {:.5f}, test_acc: {:.1f}%")
print(template.format(
epoch, epoch_loss, epoch_acc*100, epoch_test_loss, epoch_test_acc*100))
print("Done!")
return train_loss, test_loss, train_acc, test_acc
train_loss, test_loss, train_acc, test_acc = fit(50,
train_dataloader,
test_dataloader)输出