1 概述
内核是操作系统的核心部分,它负责管理系统的资源、进程调度、设备驱动程序等核心功能。
内核是操作系统的核心,具有很多最基本功能,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。
Linux 内核是操作系统的核心,作为一个模块化、分层的软件层,是硬件和用户空间应用程序的关键桥梁。设计目标是提供一个高效、稳定、可扩展的操作系统环境。
从技术层面讲,内核是硬件与软件之间的一个中间层。作用是将应用层序的请求传递给硬件,并充当底层驱动程序,对系统中的各种设备和组件进行寻址。
Linux 内核在整个计算机系统中处于核心位置,它通过虚拟化将计算机硬件抽象为一台虚拟机,供用户进程使用。进程运行时完全不需要知道硬件是如何工作的,只要调用 Linux kernel 提供的虚拟接口即可。同时,Linux 内核还负责多任务处理,实际上是多个任务在并行使用计算机硬件资源,内核的任务是仲裁对资源的使用,制造每个进程都以为自己是独占系统的错觉。进程上下文切换需要换掉程序状态字、换掉页表基地址寄存器的内容、换掉 current 指向的 task_struct 实例、换掉 PC,也就换掉了进程打开的文件和进程内存的执行空间。
2 架构
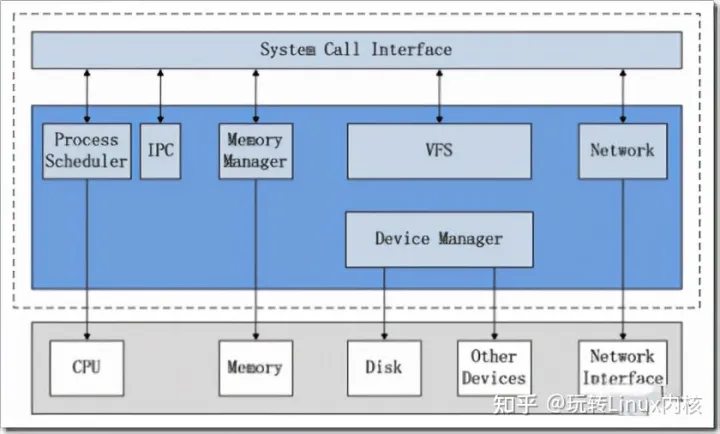
Linux 内核主要由 5 部分组成,分别为:进程管理子系统,内存管理子系统,文件子系统,网络子系统,设备子系统。,应用层通过系统调用层的函数接口与内核进行交互,用户应用程序执行的地方是用户空间,用户空间之下则是内核空间,Linux 内核正是位于内核空间中。
2.1 进程管理子系统
进程管理负责处理进程的创建、调度、终止以及进程间通信(IPC)。
- 进程描述符 (
task_struct) :内核使用一个名为task_struct的数据结构来维护每个进程的所有信息(状态、优先级、资源占用等)。 - 调度器 (Scheduler) :决定哪个进程何时使用 CPU。Linux 默认采用 完全公平调度器 (CFS) 算法,力求在所有可运行进程之间公平地分配 CPU 时间。同时也支持实时调度策略(如
SCHED_FIFO和SCHED_RR)以满足低延迟需求。 - 进程间通信 (IPC):提供了多种机制供进程之间交换数据和同步操作,包括管道、消息队列、共享内存、信号量和套接字等。
负责管理CPU资源,以便让各个进程可以以尽量公平的方式访问CPU。
此外内核通过系统调用提供了应用程序编程接口,例如:创建新进程(fork,exec),结束进程(kill,exit),并且提供了控制进程,同步进程和进程间通信的接口。
在 Linux2.6 版本之后,进程调度器使用新的进程调度算法------Completely Fair Scheduler,简称 CFS,即完全公平调度算法。该算法会按所需分配的计算能力,向系统中每个进程提供最大的公正性,它负责将 CPU 资源,分配给正在执行的进程,目标在于最大化程式互动效能,最小化整体 CPU 的运用,这个算法使用红黑树来实现,算法效率为 O(log(n))。
2.1.1 进程
2.1.1.1 进程的四要素:
有一段程序供其执行,这段程序不一定是某个进程所专有,可以与其他进程共用。
有进程专有的系统堆栈空间(也可以称之为内核堆栈空间)。
在内核中有一个 task_struct 数据结构,即进程控制块。有了这个数据结构,进程才能被内核调度器识别并参与内核调度,除此之外它还记录着进程所占有的各项资源。
除上述的专有的系统堆栈空间外,进程还需要有独立的用户堆栈空间,这就是 mm_struct 数据结构,该数据结构位于 task_struct 结构中,字段名称为 mm。
// Linux内核中进程描述符(部分代码)
struct task_struct {
volatile long state; // 进程状态
void *stack; // 进程内核栈
unsigned int flags; // 进程标志
// 进程标识
pid_t pid; // 进程ID
pid_t tgid; // 线程组ID
// 进程关系
struct task_struct __rcu *parent; // 父进程
struct list_head children; // 子进程列表
struct list_head sibling; // 兄弟进程
// 内存管理
struct mm_struct *mm; // 内存描述符
// 调度相关
int prio; // 动态优先级
int static_prio; // 静态优先级
struct sched_entity se; // 调度实体
// 文件系统
struct fs_struct *fs; // 文件系统信息
struct files_struct *files; // 打开文件表
};2.1.1.2 进程的堆栈
内核在创建一个新的进程(创建进程控制块 task_struct) 时,为进程创建堆栈。
一个进程有 2 个堆栈,即用户堆栈和系统堆栈;用户堆栈的空间指向用户地址空间,内核堆栈的空间指向内核地址空间。
当进程在用户态运行时,CPU 堆栈指针寄存器指向用户堆栈地址,使用用户堆栈。
当进程运行在内核态时,CPU 堆栈指针寄存器指向的是内核堆栈空间地址,使用内核堆栈。
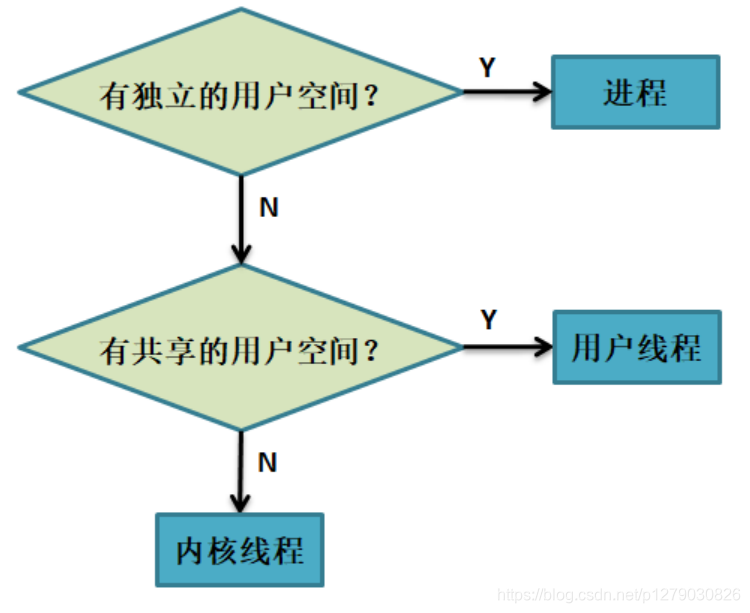
2.1.1.3 进程与线程的区分
- 进程:四个要素是必要条件
- 用户线程:有共享的用户空间
- 内核线程:没有用户空间,即 mm_struct 为 NULL
- 简单区分如图所示:
2.1.1.4 进程状态
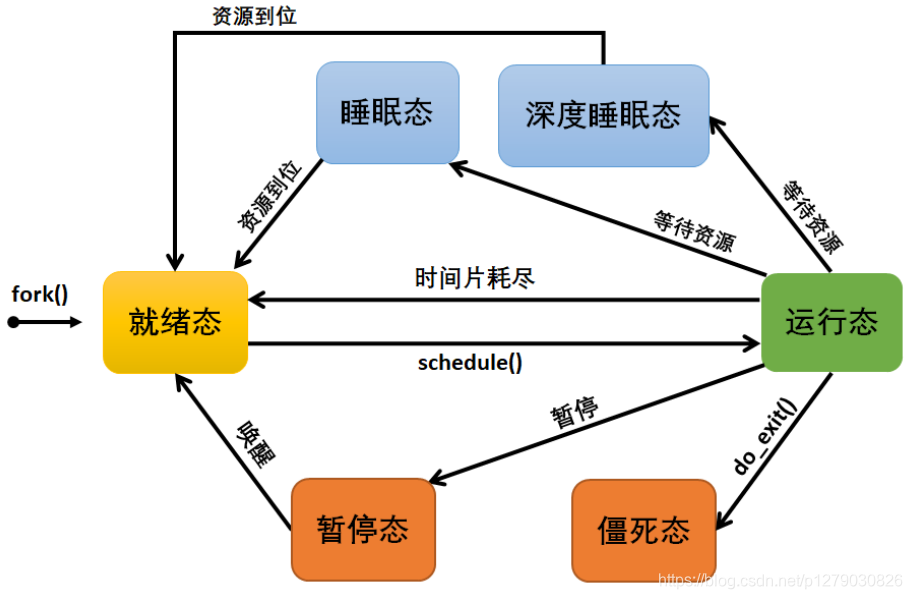
|--------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 就绪态 R (TASK_RUNNING) (可执行状态) | 该状态的进程才能被允许参与调度器调度并且使用 CPU 资源,而同一时刻可能有多个进程处于就绪态,这些进程的 task_struct 结构(进程控制块)被放入对应 CPU 的可执行队列中(一个进程最多只能出现在 一个 CPU 的可执行队列中)。 进程调度器的任务就是从各个 CPU 的可执行队列中分别选择一个进程在该 CPU 上运行。 |
| 运行态 R (TASK_RUNNING) | 进程正在使用 CPU 资源。 提示:很多操作系统的书将正在 CPU 上执行的进程定义为 RUNNING 状态、而将可执行但是尚未被调度执行的进程定义为 READY 状态,这两种状态在 linux 下统一为 TASK_RUNNING 状态 |
| 暂停态 T (TASK_STOPPED or TASK_TRACED) | 向进程发送 SIGSTOP 信号,进入 TASK_STOPPED 状态 向进程发送 SIGCONT 信号,从 TASK_STOPPED 状态恢复到 TASK_RUNNING 状态,当进程正在被跟踪时,它处于 TASK_TRACED 这个特殊的状态。 "正在被跟踪"指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在 gdb 中对被跟踪的进程下一个断点,进程在 断点 处停下来的时候就处于 TASK_TRACED 状态。 |
| 可中断睡眠态 S (TASK_INTERRUPTIBLE) (睡眠态) | 因为等待某些事件的发生而进入睡眠状态(比如等待 socket 连接、等待信号量等)。 当这些事件发生的时候进程将被唤醒,如产生一个硬件中断、释放进程正在等待的系统资源或是传递一个信号都可以是唤醒进程的条件。 系统的大多数进程都是处于这个状态,在终端可以通过 ps --aux 命令查看系统进程状态。 |
| 不可中断睡眠状态 D (TASK_UNINTERRUPTIBLE) (深度睡眠态) | 把信号传递到这种睡眠状态的进程不能改变它的状态,也就是说它不响应信号的唤醒,这种状态一般由 IO 引起, 同步 IO 在做读或写操作 时(比如进程对某些硬件设备进行操作,等待磁盘 IO ,等待网络 IO ),此时 CPU 不能做其它事情,只能处于这种状态进行等待,这样一来就能保证进程执行期间不被外部信号打断。 |
| 僵死态 Z (TASK_DEAD - EXIT_ZOMBIE) (僵尸态或者退出态) | 进程退出 的过程中,除了 task_struct 数据结构(以及少数资源)以外,进程所占有的资源将被系统回收,此时进程没法继续运行了,但它还有 task_struct 数据结构,所以被称为僵死态。 之所以保留 task_struct 数据结构,是因为 task_struct 中保存了进程的退出码、以及一些其他的信息,而其父进程很可能会关心这些信息,因此会暂时被保留下来。 |
2.1.1.5 Linux 内核3 个系统调用创建新的进程:
-
fork(分叉):子进程是父进程的一个副本,采用写时复制技术。
-
vfork:用于创建子进程,之后子进程立即调用 execve 以装载新程序的情况,为了避免复制物理页,父进程会睡眠等待子进程装载新程序。现在 fork 采用了写时复制技术,vfork 失去了速度优势,已经被废弃。
-
clone(克隆):可以精确地控制子进程和父进程共享哪些资源。这个系统调用的主要用处是可供 pthread 库用来创建线程。
clone 是功能最齐全的函数,参数多、使用复杂,fork 是 clone 的简化函数。(kernel/fork.c)
2.1.1.6 用户虚拟地址空间布局
进程的用户虚拟地址空间的起始地址是 0,长度是 TASK_SIZE,由每种处理器架构定义自己的宏 TASK_SIZE。ARM64 架构定义宏 TASK_SIZE 如下所示:
-
32 位用户空间程序:TASK_SIZE 的值是 TASK_SIZE_32,即 0x10000000,等于 4GB。
-
64 位用户空间程序:TASK_SIZE 的值是 TASK_SIZE_64,即 2 的 VA_BITS 次方字节,VA_BITS 是编译内核时选择的虚拟地址位数。
(arch/arm64/include/asm/memory.h)
一个进程的用户虚拟地址空间包括区域:代码段、动态库的代码段、数据段、未初始化数据段、代码段、未初始化代码段、存放在栈底部的环境变量、参数字符串等等。
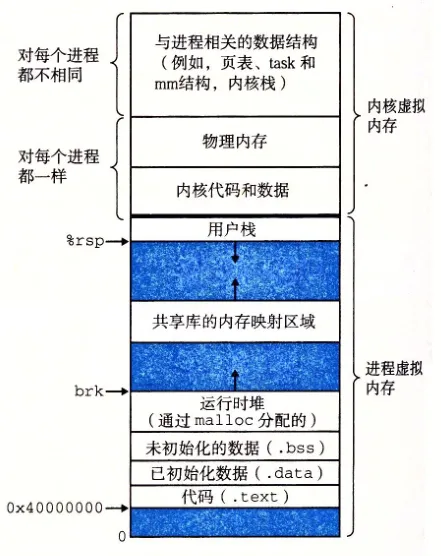
进程的进程描述和内存描述符关系:
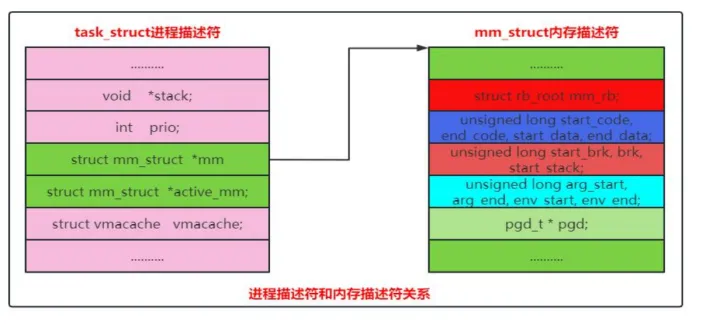
2.1.1.7 内核地址空间布局
ARM64 处理器架构的内核地址空间布局如下:

用户空间(256T)、内核空间(256T)、module区域(128M)、PCI I/O区域(16M)、vmalloc区域(123T左右)、vmemmap区域(4096G)。
KASAN影子区域:内核地址的消毒,是一个动态内存错误的检查工具。
2.1.2 进程调度
进程调度包含4个子模块
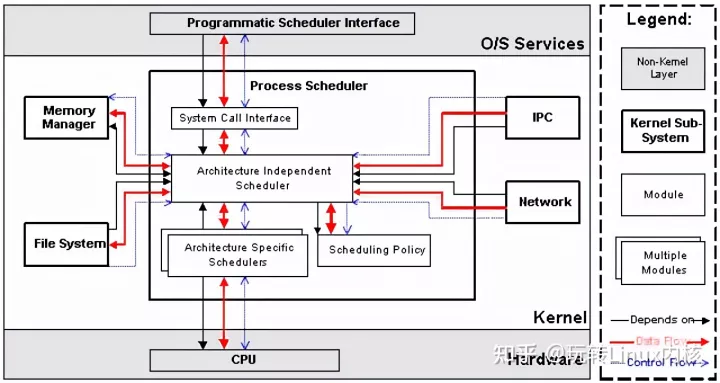
2.1.2.1 Scheduling Policy
实现进程调度的策略,它决定哪个(或哪几个)进程将拥有CPU。
2.1.2.2 Architecture-specific Schedulers
体系结构相关的部分,用于将对不同CPU的控制,抽象为统一的接口。这些控制主要在suspend和resume进程时使用,牵涉到CPU的寄存器访问、汇编指令操作等。
2.1.2.3 Architecture-independent Scheduler
体系结构无关的部分。它会和"Scheduling Policy模块"沟通,决定接下来要执行哪个进程,然后通过"Architecture-specific Schedulers模块"resume指定的进程。
2.1.2.4 System Call Interface
系统调用接口。进程调度子系统通过系统调用接口,将需要提供给用户空间的接口开放出去,同时屏蔽掉不需要用户空间程序关心的细节。
2.2 内存管理(Memory Manager, MM)
负责管理Memory(内存)资源,以便让各个进程可以安全地共享设备的内存资源。另外,内存管理会提供虚拟内存的机制,该机制可以让进程使用多于系统可用Memory的内存,不用的内存会通过文件系统保存在外部非易失存储器中,需要使用的时候,再取回到内存中。
主要作用是保证系统安全访问内存区域,且绝大部分 CPU 都是支持内存管理单元的(Memory Management Unit,MMU)
内存管理子系统负责管理每个进程完成从虚拟内存到物理内存的转换,以及系统可用内存空间。
内存管理的硬件按照分页方式管理内存,分页就是把系统的物理内存按照相同大小等分,每个内存分片称作内存页,通常内存页大小是 4KB。内存管理子系统要管理的不仅是 4KB 缓冲区,它提供了对 4KB 缓冲区的抽象,例如 slab 分配器。这种内存管理模式使用 4KB 缓冲区为基数,然后从中分配管理结构,并跟踪内存页使用情况。系统就支持动态调整内存使用情况。
Linux 还支持内存交换,因为 Linux 中使用的是虚拟内存,当物理内存不足时,内存管理子系统会将内存暂时移到磁盘中,在物理内存充裕时又将内存页从磁盘移到物理内存中。
在 32 位的系统上,每个进程都最大享有 4GB 的内存空间,因为由于 32 位的系统寻址空间只有4G,当然这是虚拟内存,0~3GB 是属于用户内存空间,3~4GB 是属于系统内存空间,实际上用户的程序几乎使用不完那么大的用户空间,一旦超出将无法正常运行,当然系统内存空间与用户内存空间是可以调整的。
在内存管理中,虚拟内存是一项重要的技术。虚拟内存技术允许进程使用比实际物理内存更大的地址空间,它将物理内存和硬盘空间结合起来,为进程提供一个连续的、虚拟的内存空间 。每个进程都有自己独立的虚拟地址空间,这使得进程之间的内存相互隔离,一个进程的内存操作不会影响到其他进程,提高了系统的安全性和稳定性。虚拟内存通过页表机制实现虚拟地址到物理地址的映射。当进程访问虚拟地址时,内核会根据页表查找对应的物理地址,如果该页在物理内存中,则直接访问;如果不在,则会触发缺页中断,内核从硬盘的交换空间中将该页读取到物理内存中,并更新页表。
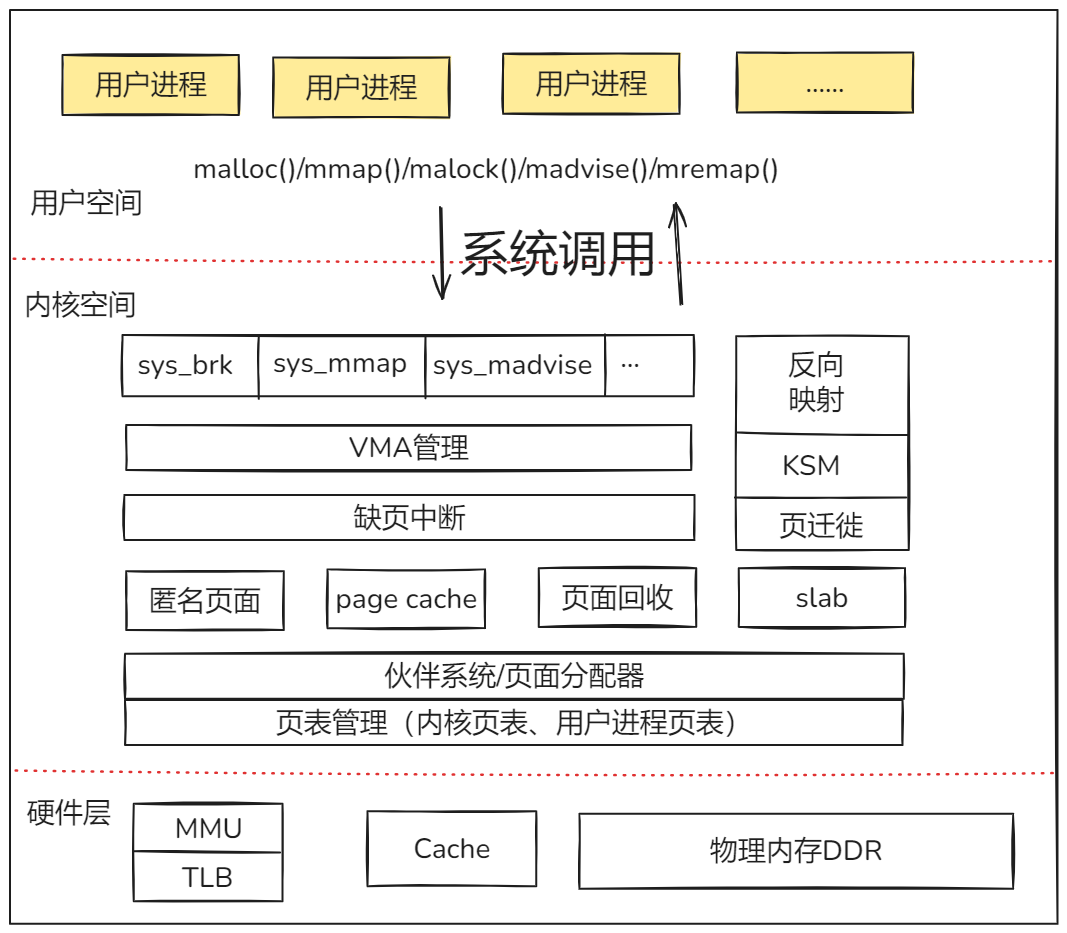
- 虚拟内存:为每个进程提供一个统一的、独立的虚拟地址空间(32位系统通常为4GB),通过页表映射到物理内存。这起到了隔离和保护进程的作用。
- 物理内存分配 : - 伙伴系统 (Buddy System) :负责管理大块的连续物理内存页,解决外部碎片问题。 - Slab 分配器 :在伙伴系统之上工作,用于高效分配内核中常用的小对象(如
inode,task_struct),通过对象缓存机制减少内部碎片和提高分配速度。 - 页面回收 :当物理内存不足时,内核会通过 LRU (最近最少使用) 等算法将不常用的内存页交换到磁盘上的交换空间(SWAP),以释放物理内存。
内存管理子系统包括3个子模块(见下图),它们的功能如下:
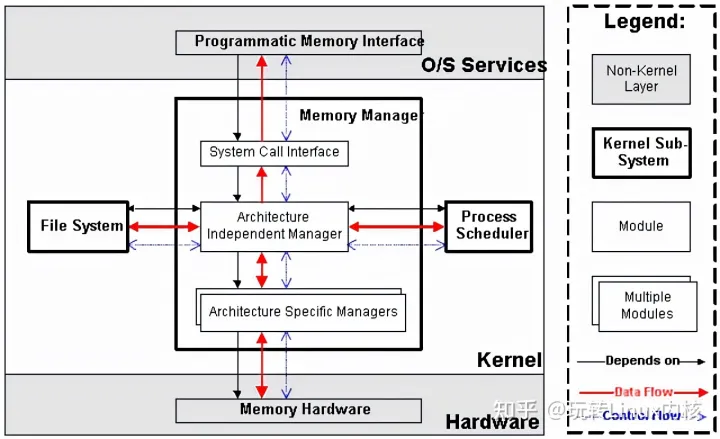
2.2.1 Architecture Specific Managers
体系结构相关部分。提供用于访问硬件Memory的虚拟接口。
2.2.2 Architecture Independent Manager
体系结构无关部分。提供所有的内存管理机制,包括:以进程为单位的memory mapping;虚拟内存的Swapping。
2.2.3 System Call Interface
系统调用接口。通过该接口,向用户空间程序应用程序提供内存的分配、释放,文件的map等功能。
2.3 VFS(Virtual File System)虚拟文件系统。
Linux内核将不同功能的外部设备,例如Disk设备(硬盘、磁盘、NAND Flash、Nor Flash等)、输入输出设备、显示设备等等,抽象为可以通过统一的文件操作接口(open、close、read、write等)来访问。这就是Linux系统"一切皆是文件"的体现(其实Linux做的并不彻底,因为CPU、内存、网络等还不是文件,如果真的需要一切皆是文件,还得看贝尔实验室正在开发的"Plan 9"的)。
文件系统子系统提供了对存储设备上数据的组织、存储和访问能力。
VFS 的实现依赖于几个关键的数据结构,包括超级块、索引节点和目录项 。超级块是 VFS 中极为重要的数据结构,它描述了一个文件系统的整体信息。每个被挂载的文件系统都有一个对应的 VFS 超级块,该超级块在文件系统挂载时被读取到内存中,并一直存在于内存中,直到文件系统被卸载。超级块包含了诸如文件系统的类型、块大小、空闲块数量、inode 数量、挂载点等重要信息 。此外,超级块还包含了指向一些函数指针,这些函数用于操作该文件系统的 inode 和超级块本身。例如,对于 ext2 文件系统的超级块,它会包含指向 ext2 特定的 inode 读取函数的指针。通过这些函数指针,VFS 可以调用具体文件系统的特定函数来完成各种操作。
索引节点(Inode)也是 VFS 中的重要组成部分,VFS 中的每个文件和目录都由一个 inode 来表示。inode 存储了文件的元数据信息,如文件的权限、所有者、大小、修改时间、创建时间等 。同时,inode 还包含了指向文件数据块的指针,通过这些指针可以找到文件在磁盘上存储的数据。与超级块类似,inode 也有一组函数指针,这些函数用于对 inode 进行各种操作,如创建文件、删除文件、读取文件内容等 。当应用程序对文件进行操作时,VFS 会根据文件对应的 inode 找到相应的操作函数,并调用这些函数来完成具体的操作。需要注意的是,VFS inode 与具体文件系统的 inode 是不同的概念,但 VFS inode 中的信息是通过调用具体文件系统的相关例程从底层文件系统的 inode 中获取并填充的。
目录项(Dentry)则是 VFS 用于表示目录结构的一种数据结构,它主要用于建立文件名与 inode 之间的映射关系。在 Linux 的目录树中,每个目录都是由一系列的目录项组成,每个目录项对应一个文件或子目录。目录项包含了文件名以及指向对应 inode 的指针 。当我们在 Linux 中通过路径来访问文件时,VFS 会根据路径中的目录名依次查找对应的目录项,从而找到目标文件的 inode,进而对文件进行操作。例如,当我们要访问 "/home/user/Documents/file.txt" 这个文件时,VFS 首先会根据根目录 "/" 的 inode 找到根目录的目录项,然后在根目录的目录项中查找 "home" 目录的目录项,以此类推,直到找到 "file.txt" 文件对应的目录项,并通过该目录项找到其对应的 inode。
通过这些关键数据结构和统一的接口,VFS 成功地隐藏了各种硬件设备的不同实现细节,使得用户和应用程序可以以相同的方式操作不同的文件系统,无论是本地硬盘、U 盘,还是网络文件系统等 。它为 Linux 系统的文件管理提供了高度的灵活性和可扩展性,是 Linux 内核中不可或缺的重要组成部分。
- 虚拟文件系统 (VFS) :作为一层抽象接口,它屏蔽了底层不同文件系统(如 Ext4, XFS, Btrfs, NTFS)的具体差异,向上层应用提供统一的文件操作API(如
open,read,write,close)。 - 具体文件系统:VFS 之下是各种具体文件系统的实现,它们真正定义了数据在块设备上的组织格式。
- 页缓存 (Page Cache):内核会将磁盘上的文件数据缓存在内存中,大幅减少了直接访问磁盘的次数,从而提高了文件读写的性能。
在 Linux 系统中一切皆文件,它把一切资源都看作是文件,包括硬件设备,通常称为设备文件。
Linux 的文件管理子系统主要实现了虚拟文件系统(Virtual File System,VFS),虚拟文件系统屏蔽了各种硬件上的差异以及具体实现的细节,为所有的硬件设备提供统一的接口,即实现了设备无关性,同时文件管理系统还为应用层提供统一的 API 接口。
Linux 的文件系统体系结构是对一个对复杂系统进行了抽象化,通过使用一组通用的 API 函数,Linux 可以在许多种存储设备上支持多种文件系统,如 NTFS、EXT2、EXT3、EXT4 、FAT 等等;而用户空间包含一些应用程序和 GNU C 库(glibc),它们使用的 API 接口是由系统调用层提供(如打开、读、写和关闭等)。
框架如图所示:
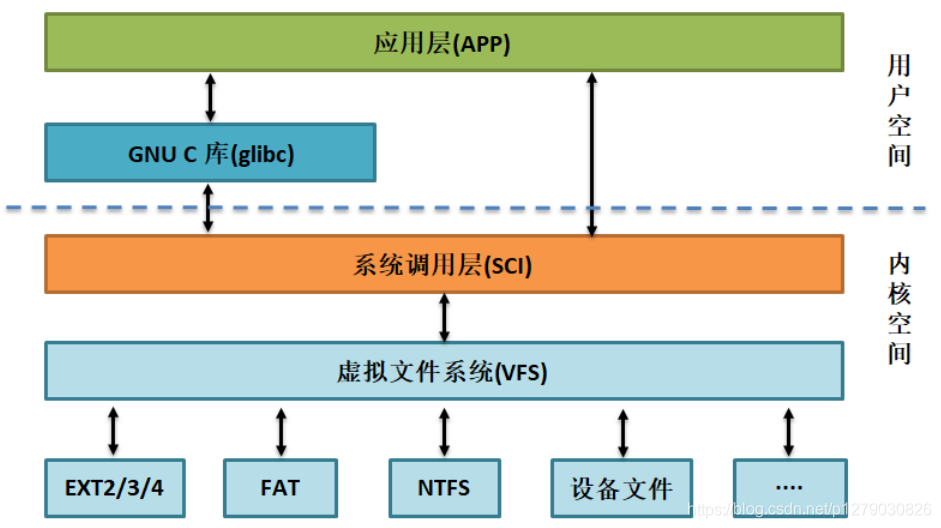
VFS隐藏了各种硬件的具体细节,把文件系统操作和不同文件系统的具体实现细节分离了开来,为所有的设备提供了统一的接口,VFS提供了多达数十种不同的文件系统。虚拟文件系统可以分为逻辑文件系统和设备驱动程序。逻辑文件系统指Linux所支持的文件系统,如ext2,fat等,设备驱动程序指为每一种硬件控制器所编写的设备驱动程序模块。
虚拟文件系统(VFS)是 Linux 内核中非常有用的一个方面,因为它为文件系统提供了一个通用的接口抽象。VFS 在 SCI 和内核所支持的文件系统之间提供了一个交换层。即VFS 在用户和文件系统之间提供了一个交换层。
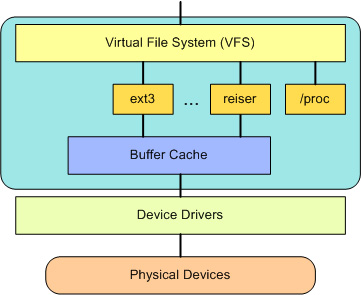
在 VFS 上面,是对诸如 open、close、read 和 write 之类的函数的一个通用 API 抽象。在 VFS 下面是文件系统抽象,它定义了上层函数的实现方式。它们是给定文件系统(超过 50 个)的插件。文件系统的源代码可以在 ./linux/fs 中找到。 文件系统层之下是缓冲区缓存,它为文件系统层提供了一个通用函数集(与具体文件系统无关)。这个缓存层通过将数据保留一段时间(或者随即预先读取数据以便在需要是就可用)优化了对物理设备的访问。缓冲区缓存之下是设备驱动程序,它实现了特定物理设备的接口。 因此,用户和进程不需要知道文件所在的文件系统类型,而只需要象使用 Ext2 文件系统中的文件一样使用它们。
VFS子系统包括6个子模块(见下图),它们的功能如下:
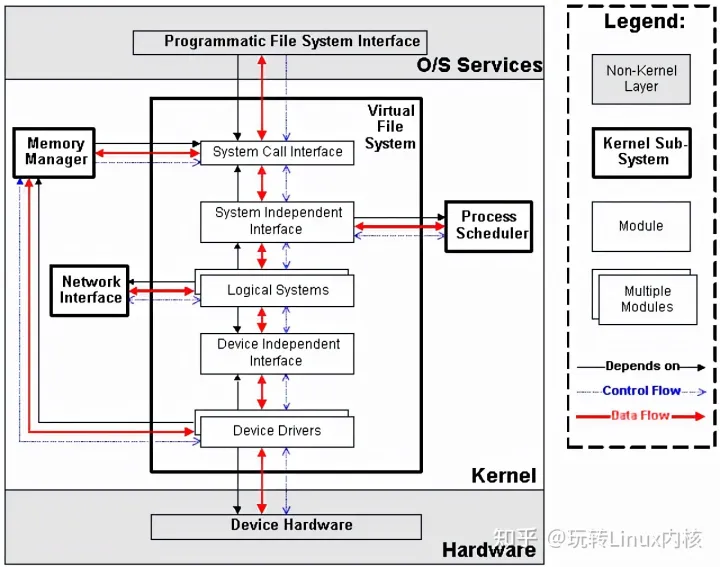
2.3.1 Device Drivers
设备驱动,用于控制所有的外部设备及控制器。由于存在大量不能相互兼容的硬件设备(特别是嵌入式产品),所以也有非常多的设备驱动。因此,Linux内核中将近一半的Source Code都是设备驱动,大多数的Linux底层工程师(特别是国内的企业)都是在编写或者维护设备驱动,而无暇估计其它内容(它们恰恰是Linux内核的精髓所在)。
2.3.2 Device Independent Interface
该模块定义了描述硬件设备的统一方式(统一设备模型),所有的设备驱动都遵守这个定义,可以降低开发的难度。同时可以用一致的形式向上提供接口。
2.3.3 Logical Systems
每一种文件系统,都会对应一个Logical System(逻辑文件系统),它会实现具体的文件系统逻辑。
2.3.4 System Independent Interface
该模块负责以统一的接口(快设备和字符设备)表示硬件设备和逻辑文件系统,这样上层软件就不再关心具体的硬件形态了。
2.3.5 System Call Interface
系统调用接口,向用户空间提供访问文件系统和硬件设备的统一的接口。
2.4 Network,网络子系统
负责管理系统的网络设备,并实现多种多样的网络标准。
网络子系统实现了各种网络协议,使Linux能够进行网络通信。
- 网络协议栈 :Linux 实现了完整的 TCP/IP 协议栈(包括应用层、传输层、网络层、链路层),支持 Socket 编程接口。
- 网络设备驱动:负责与物理网络设备(如网卡)交互,处理数据包的发送和接收。
- Netfilter/IPtables:提供了强大的数据包过滤、网络地址转换(NAT)和连接跟踪功能,是 Linux 防火墙的基础。
在 Linux 内核中,与网络相关的代码被 Linux 独立开,形成一个相对独立的子系统,称为网络子系统,网络子系统是一个层次化的结构,可分为以下几个层次:
Socket 层(也可以称之为协议无关层):Linux 在发展过程中,采用 BSD Socket API 作为自己的网络相关的 API 接口。同时,Linux 的目标又要能支持各种不同的协议族,而且这些协议族都可以使用 BSD Socket API 作为应用层的编程接口,这样一来将 Socket 层抽象出来就能屏蔽不同协议族之间的差异,不会对应用层的使用产生影响。
协议层:Linux 网络子系统功能上相当完备,它不仅支持 INET 协议族(也就是通常所说的 TCP/IP 协议族),而且还支持其它很多种协议族,如 INET6、DECnet,ROSE,NETBEUI 等,对于 INET 、INET6 协议族来说,又会进一步将协议族划分为传输层和网络层以及链路层等。
网络设备层:网络设备其实是设备驱动层的内容了,它抽象了网卡数据结构,在一个系统中可能存在多种网卡,屏蔽了不同硬件上的差异,这一层提供了一组通用函数供底层网络设备驱动程序使用。
框架如图所示:
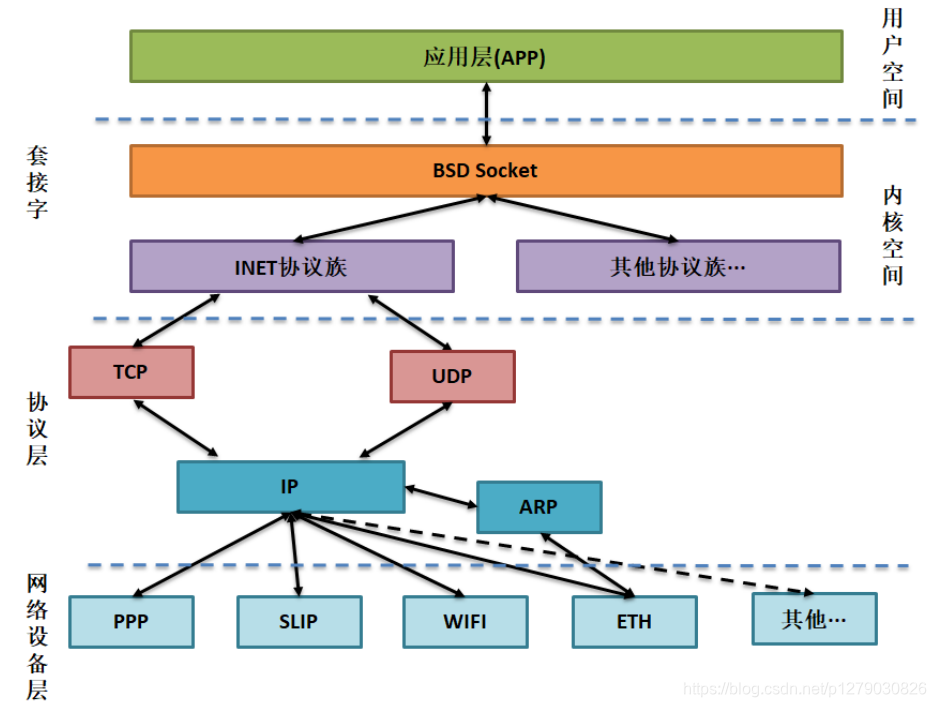
它包括5个子模块(见下图),它们的功能如下:
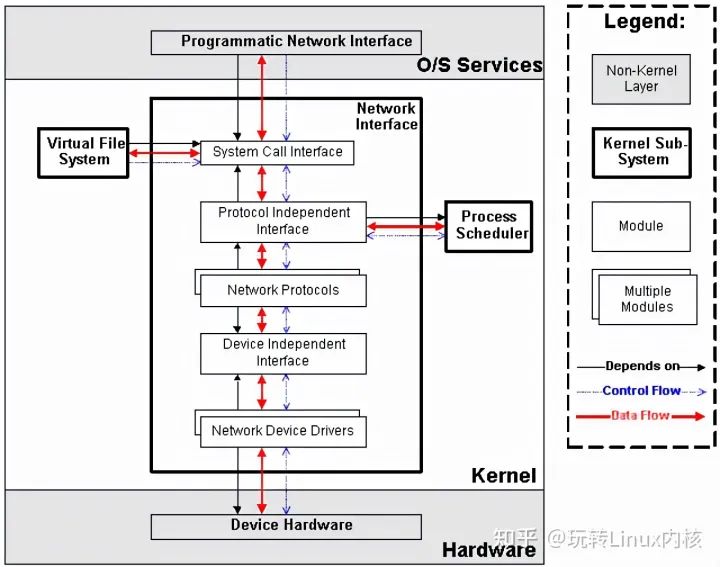
-
Network Device Drivers,网络设备的驱动,和VFS子系统中的设备驱动是一样的。
-
Device Independent Interface,和VFS子系统中的是一样的。
-
Network Protocols,实现各种网络传输协议,例如IP, TCP, UDP等等。
-
Protocol Independent Interface,屏蔽不同的硬件设备和网络协议,以相同的格式提供接口(socket)。
-
System Call interface,系统调用接口,向用户空间提供访问网络设备的统一的接口。
2.5 设备子系统
设备子系统又被称之为设备驱动,如 LCD、摄像头、USB、音频等都是属于设备,且设备的厂商不同其驱动程序也是不同的,但是对于 Linux 来说,不可能去将每个设备都包含到内核,它只能抽象去描述某种设备。
系统调用层是 Linux 内核与应用程序之间的接口,而设备驱动则是 Linux 内核与硬件之间的接口,设备驱动程序为应用程序屏蔽了硬件的细节,在应用程序看来,硬件设备只是一个设备文件,应用程序可以象操作普通文件一样对硬件设备进行操作(打开、读、写和关闭)。
设备驱动程序是内核的一部分
2.5.1 主要功能:
对设备初始化和释放
把数据从内核传送到硬件和从硬件读取数据
读取应用程序传送给设备文件的数据和回送应用程序请求的数据
检测和处理设备出现的错误
2.5.2 设备分类:
字符设备、块设备、网络设备
字符设备,是以字节为单位传输的 IO 设备,可以提供连续的数据流,应用程序可以顺序读取,通常不支持随机存取。这种字符传输的效率通常是比较低的,如鼠标、键盘、串口等都是字符设备。
块设备,是以块为单位进行传输的设备,应用程序可以随机访问块设备中的数据,程序可以指定读取数据的位置。磁盘就是一种常见的块设备,应用程序可以寻址磁盘上的任何位置,并在这个位置读取数据。块设备读取的数据只能以块为单位的倍数进行(通常是 512Byte 的整数倍),而不能与字符设备一样以字节为单位读取。块设备的传输速度是比较高的。
网络设备,其实就是网络子系统中描述的网络设备层,统一描述了不同的网卡设备,如 WIFI、以太网等。因为网络设备存在协议栈(协议族),它涉及了网络层协议,所以 Linux 将网络设备单独分层一类设备。传输速率通常很高。
框架如图所示:
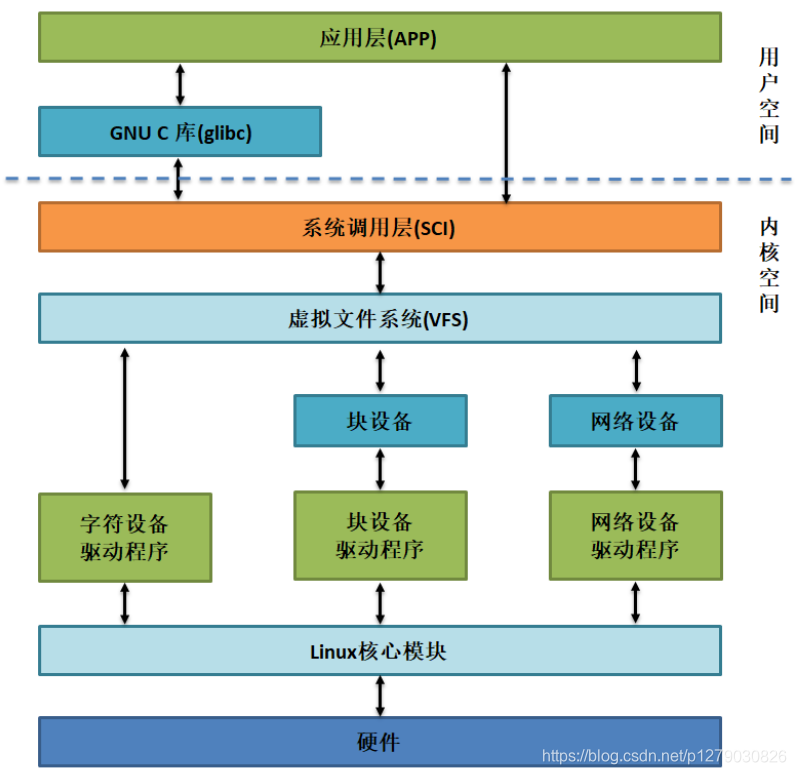
设备驱动: 控制和管理硬件设备,如打印机、图形卡、网络适配器等。
文件系统驱动: 提供对不同文件系统的支持,例如 FAT、NTFS、ext4 等。
虚拟设备驱动: 创建虚拟设备,如虚拟磁盘、虚拟网络设备等。
字符设备驱动和块设备驱动: 用于字符设备(如终端)和块设备(如硬盘)的控制。
网络设备驱动: 管理网络接口卡和网络协议栈的通信。
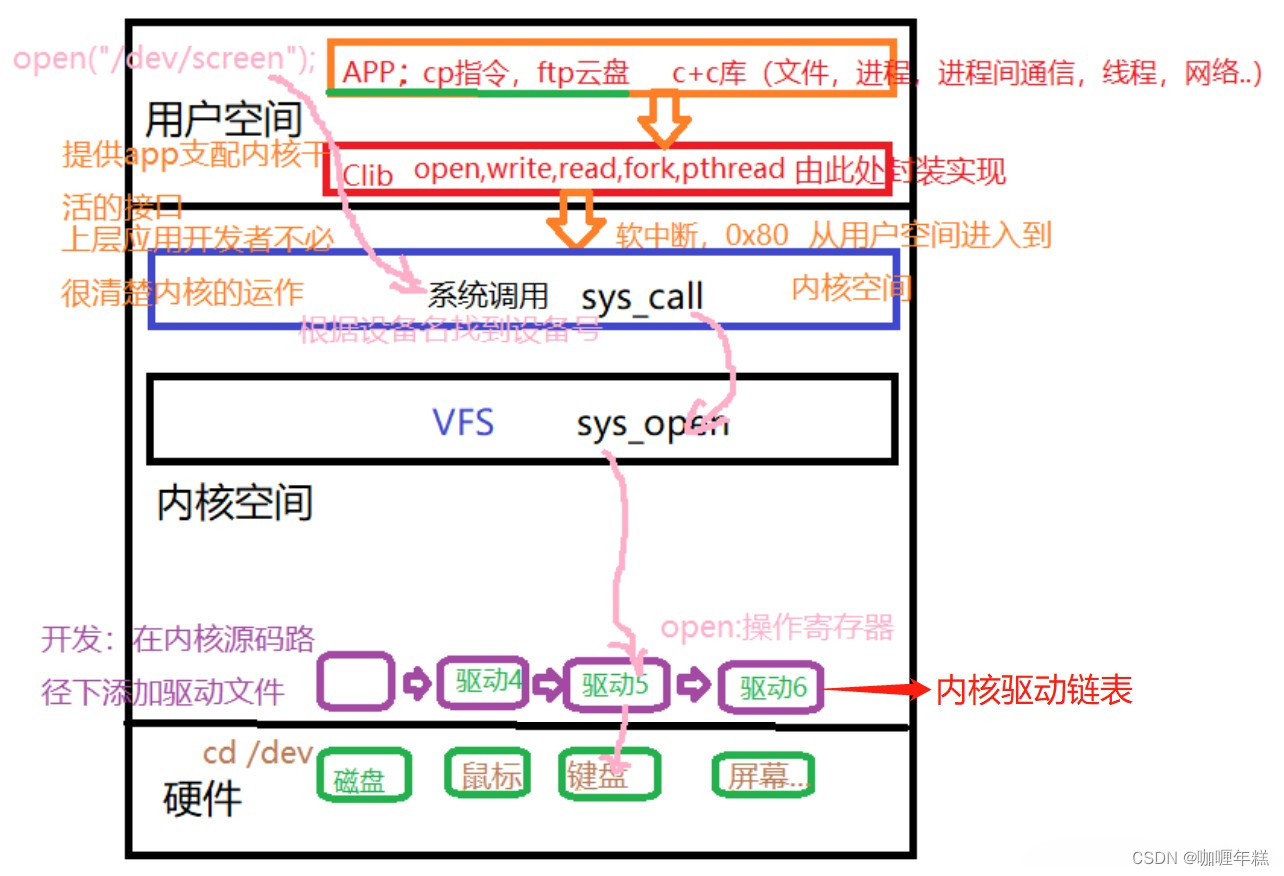
2.5.3 open调用流程
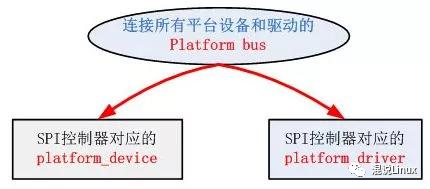
2.5.4 Linux驱动的platform机制
Linux的这种platform driver机制和传统的device_driver机制相比,一个十分明显的优势在于platform机制将本身的资源注册进内核,由内核统一管理,在驱动程序中使用这些资源时通过platform_device提供的标准接口进行申请并使用。这样提高了驱动和资源管理的独立性,并且拥有较好的可移植性和安全性。下面是SPI驱动层次示意图,Linux中的SPI总线可理解为SPI控制器引出的总线:
和传统的驱动一样,platform机制也分为三个步骤:
1、总线注册阶段:
内核启动初始化时的main.c文件中的
kernel_init()→do_basic_setup()→driver_init()→platform_bus_init()→bus_register(&platform_bus_type),注册了一条platform总线(虚拟总线,platform_bus)。
2、添加设备阶段:
设备注册的时候
Platform_device_register()→platform_device_add()→(pdev→dev.bus = &platform_bus_type)→device_add(),就这样把设备给挂到虚拟的总线上。
3、驱动注册阶段:
Platform_driver_register()→driver_register()→bus_add_driver()→driver_attach()→bus_for_each_dev(), 对在每个挂在虚拟的platform bus的设备作__driver_attach()→driver_probe_device(),判断drv→bus→match()是否执行成功,此时通过指针执行platform_match→strncmp(pdev→name , drv→name , BUS_ID_SIZE),如果相符就调用really_probe(实际就是执行相应设备的platform_driver→probe(platform_device)。)开始真正的探测,如果probe成功,则绑定设备到该驱动。
从上面可以看出,platform机制最后还是调用了bus_register() , device_add() , driver_register()这三个关键的函数。
下面看几个结构体:
struct platform_device
(/include/linux/Platform_device.h)
{
const char *name;
int id;
struct device dev;
u32 num_resources;
struct resource *resource;
};Platform_device结构体描述了一个platform结构的设备,在其中包含了一般设备的结构体struct device dev;设备的资源结构体struct resource *resource;还有设备的名字const char *name。(注意,这个名字一定要和后面platform_driver.driver àname相同,原因会在后面说明。)
该结构体中最重要的就是resource结构,这也是之所以引入platform机制的原因。
struct resource
( /include/linux/ioport.h)
{
resource_size_t start;
resource_size_t end;
const char *name;
unsigned long flags;
struct resource *parent, *sibling, *child;
};其中 flags位表示该资源的类型,start和end分别表示该资源的起始地址和结束地址(/include/linux/Platform_device.h):
struct platform_driver
{
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*suspend_late)(struct platform_device *, pm_message_t state);
int (*resume_early)(struct platform_device *);
int (*resume)(struct platform_device *);
struct device_driver driver;
};Platform_driver结构体描述了一个platform结构的驱动。其中除了一些函数指针外,还有一个一般驱动的device_driver结构。
名字要一致的原因:
上面说的驱动在注册的时候会调用函数bus_for_each_dev(), 对在每个挂在虚拟的platform bus的设备作__driver_attach()→driver_probe_device(),在此函数中会对dev和drv做初步的匹配,调用的是drv->bus->match所指向的函数。platform_driver_register函数中drv->driver.bus = &platform_bus_type,所以drv->bus->match就为platform_bus_type→match,为platform_match函数,该函数如下:
static int platform_match(struct device * dev, struct device_driver * drv)
{
struct platform_device *pdev = container_of(dev, struct platform_device, dev);
return (strncmp(pdev->name, drv->name, BUS_ID_SIZE) == 0);
}是比较dev和drv的name,相同则会进入really_probe()函数,从而进入自己写的probe函数做进一步的匹配。所以dev→name和driver→drv→name在初始化时一定要填一样的。
不同类型的驱动,其match函数是不一样的,这个platform的驱动,比较的是dev和drv的名字,还记得usb类驱动里的match吗?它比较的是Product ID和Vendor ID。
2.5. IPC(Inter-Process Communication)
进程间通信。IPC不管理任何的硬件,它主要负责Linux系统中进程之间的通信。
3 用户态和内核态
Linux系统将自身划分为两部分,一部分为核心软件,即是kernel,也称作内核空间,另一部分为普通应用程序,这部分称为用户空间。
区分用户空间和内核空间的目的是为确保系统安全。在CPU的所有指令中,有一些指令是非常危险的,如果错用,将导致整个系统崩溃。比如:清内存、设置时钟等。因为如果应用程序和内核在同一个保护级别,那么应用程序就有可能有意或者不小心进入了内核空间,破坏了内核空间的代码和数据,系统崩溃就不足为奇。所以CPU将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通的应用程序只能使用那些不会造成灾难的指令。Intel的CPU将特权级别分为4个级别:RING0,RING1,RING2,RING3, 内核空间级别为"RING0", 用户空间级别为RING3。
linux的内核是一个有机的整体。每一个用户进程运行时都好像有一份内核的拷贝,每当用户进程使用系统调用时,都自动地将运行模式从用户级转为内核级,此时进程在内核的地址空间中运行。
当应用程序进程执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。此时处理器处于特权级最高的(RING0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(RING3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。
内核态与用户态是操作系统的两种运行级别,跟intel cpu没有必然的联系, 如上所提到的intel cpu提供Ring0-Ring3四种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为 内核态,没有使用Ring1和Ring2。
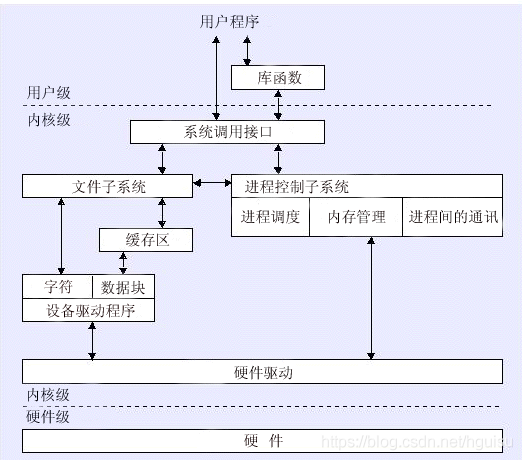
内核态与用户态
用户态Ring3状态不能访问内核态Ring0的地址空间,包括代码和数据。(例如32位Linux进程的4GB地址空间,3G-4G部 分大家是共享的,是内核态的地址空间,这里存放在整个内核的代码和所有的内核模块,以及内核所维护的数据)。用户运行一个程序,该程序所创建的进程开始是运行在用户态的,如果要执行文件操作,网络数据发送等操作,必须通过write,send等系统调用,这些系统调用会调用内核中的代码来完成操作,这时,必 须切换到Ring0,然后进入内核地址空间去执行这些代码完成操作,完成后,切换回Ring3,回到用户态。这样,用户态的程序就不能 随意操作内核地址空间,具有一定的安全保护作用。
处理器总处于以下状态中的一种:
1、内核态,运行于进程上下文,内核代表进程运行于内核空间;
2、内核态,运行于中断上下文,内核代表硬件运行于内核空间;
3、用户态,运行于用户空间。
从用户空间到内核空间有两种触发手段:
1.系统调用: 用户空间的应用程序,通过系统调用,进入内核空间。这个时候用户空间的进程要传递很多变量、参数的值给内核,内核态运行的时候也要保存用户进程的一些寄存器值、变量等。所谓的"进程上下文",可以看作是用户进程传递给内核的这些参数以及内核要保存的那一整套的变量和寄存器值和当时的环境等。
2.中断: 硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。例如网卡发送一个数据包或硬盘驱动器提供一次 IO 请求等。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的"中断上下文",其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被打断执行的进程环境)。
参考文档
https://blog.csdn.net/m0_50662680/article/details/127710851
https://blog.csdn.net/p1279030826/article/details/105998601
深度:一文看懂Linux内核!Linux内核架构和工作原理详解-腾讯云开发者社区-腾讯云
Linux系统结构详解-腾讯云开发者社区-腾讯云Linux 内核内存管理:虚拟地址空间、伙伴系统和块分配器-腾讯云开发者社区-腾讯云Linux系统结构详解-腾讯云开发者社区-腾讯云